Monitorar endpoints internos e APIs do Kubernetes pode ser problemático, especialmente se o objetivo for aproveitar a infraestrutura automatizada como serviço. Nós da Smarkets ainda não atingimos essa meta, mas, felizmente, já estamos bem próximos dela. Espero que nossa experiência nesta área ajude outras pessoas a implementar algo semelhante.
Sempre sonhamos que os desenvolvedores seriam capazes de monitorar qualquer aplicativo ou serviço pronto para uso. Antes de mudar para o Kubernetes, essa tarefa era realizada usando métricas do Prometheus ou usando estatísticasd, que enviava estatísticas para o host subjacente, onde eram convertidas em métricas do Prometheus. À medida que continuamos a aproveitar o Kubernetes, começamos a separar os clusters e queríamos fazer com que os desenvolvedores pudessem exportar métricas diretamente para o Prometheus por meio de anotações de serviço. Infelizmente, essas métricas estavam disponíveis apenas no cluster, ou seja, não podiam ser coletadas globalmente.
Essas limitações foram o gargalo de nossa configuração pré-Kubernetes. No final das contas, eles forçaram a repensar a arquitetura e a forma de monitorar os serviços. Essa jornada será discutida a seguir.
O ponto de partida
Para métricas relacionadas ao Kubernetes, usamos dois serviços que fornecem métricas:
-
kube-state-metricsgera métricas para objetos Kubernetes com base nas informações dos servidores K8s API; -
kube-eagleexporta métricas do Prometheus para pods: suas solicitações, limites, uso.
É possível (e já faz algum tempo) expor serviços com métricas fora do cluster ou abrir uma conexão proxy para a API, mas ambas as opções não eram ideais, pois tornavam o trabalho lento e não forneciam a necessária independência e segurança dos sistemas.
Normalmente, uma solução de monitoramento foi implantada, consistindo em um cluster central de servidores Prometheus em execução dentro do Kubernetes e coletando métricas da própria plataforma, bem como métricas internas do Kubernetes desse cluster. O principal motivo pelo qual escolhemos essa abordagem foi que, durante a transição para o Kubernetes, coletamos todos os serviços no mesmo cluster. Depois de adicionar clusters Kubernetes adicionais, nossa arquitetura ficou assim:
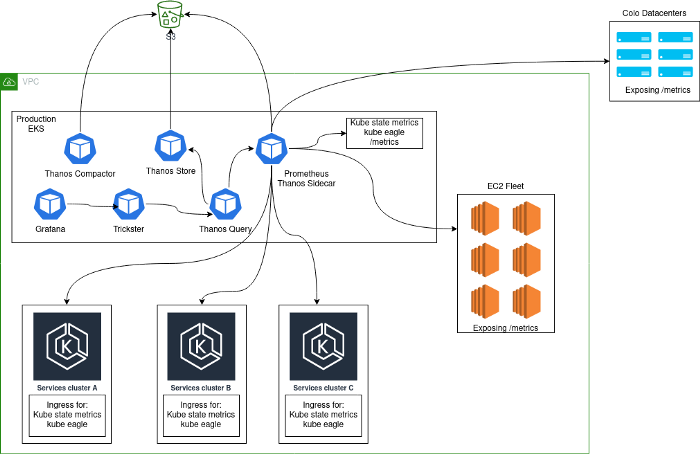
Problemas
Essa arquitetura não pode ser chamada de estável, eficiente ou produtiva: afinal, os usuários podiam exportar métricas estatísticas de aplicativos, o que gerava uma cardinalidade incrivelmente alta de algumas métricas. Você pode estar familiarizado com problemas como este se a ordem de magnitude abaixo lhe parecer familiar.
Ao analisar um bloco Prometheus de 2 horas:
- 1,3 milhão de métricas;
- 383 nomes de etiquetas;
- a cardinalidade máxima por métrica é 662.000 (a maioria dos problemas é exatamente por causa disso).
Essa alta cardinalidade é principalmente devido à exposição de temporizadores statsd que incluem caminhos HTTP. Sabemos que isso não é ideal, mas essas métricas são usadas para rastrear bugs críticos em implantações de canário.
Em tempos de silêncio, cerca de 40.000 métricas eram coletadas por segundo, mas seu número poderia aumentar para 180.000 na ausência de problemas.
Algumas consultas específicas para métricas de alta cardinalidade fizeram com que o Prometheus (previsivelmente) ficasse sem memória - uma situação muito frustrante quando ele (o Prometheus) é usado para alertar e avaliar implantações de canário.
Outro problema era que, com três meses de dados armazenados em cada instância do Prometheus, o tempo de inicialização (replay do WAL) era muito alto e isso geralmente resultava no mesmo pedido sendo roteado para uma segunda instância do Prometheus e “ já caiu.
Para resolver esses problemas, implementamos Thanos e Trickster:
- Thanos permitiu que menos dados fossem armazenados no Prometheus e reduziu o número de incidentes causados pelo uso excessivo de memória. Ao lado do contêiner, Prometheus Thanos executa um contêiner secundário que armazena blocos de dados no S3, onde são compactados com thanos-compact. Assim, com a ajuda de Thanos, o armazenamento de dados de longo prazo fora do Prometheus foi implementado.
- O Trickster, por sua vez, atua como proxy reverso e cache para bancos de dados de séries temporais. Isso nos permitiu armazenar em cache até 99,53% de todas as solicitações. A maioria das solicitações vem de painéis executados em estações de trabalho / TVs, de usuários com painéis de controle abertos e de alertas. Um proxy capaz de mostrar apenas delta em séries temporais é ótimo para esse tipo de carga de trabalho.
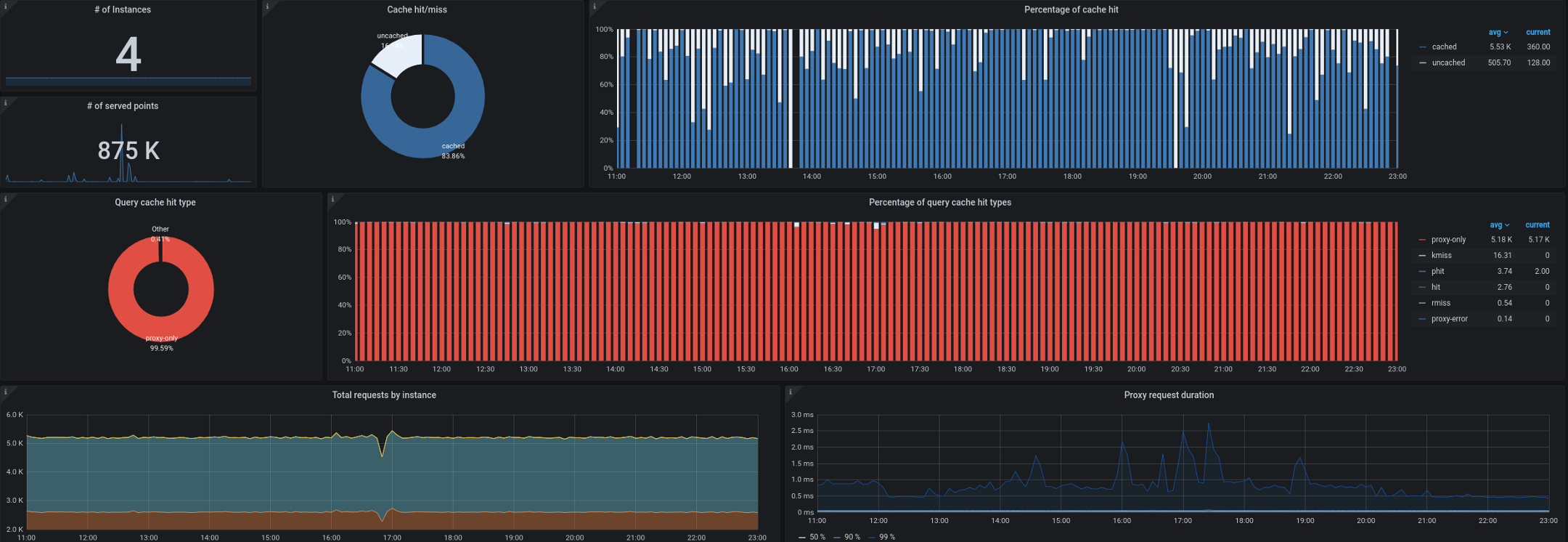
Também começamos a ter problemas para coletar métricas de estado de kube de fora do cluster. Como você se lembra, muitas vezes tínhamos que processar até 180.000 métricas por segundo, e a coleta ficava mais lenta, mesmo quando 40.000 métricas eram definidas em um único ingresso kube-state-metrics. Temos uma meta de intervalo de 10 segundos para coletar métricas e, durante os períodos de alta carga, esse SLA foi frequentemente violado pela coleta remota de métricas de estado de kube ou águia de kube.
Opções
Enquanto pensávamos em como melhorar a arquitetura, vimos três opções diferentes:
- Prometheus + Cortex ( https://github.com/cortexproject/cortex );
- Prometheus + Thanos Recebe ( https://thanos.io );
- Prometheus + VictoriaMetrics ( https://github.com/VictoriaMetrics/VictoriaMetrics ).
Informações detalhadas sobre eles e comparação de características podem ser encontradas na Internet. No nosso caso particular (e depois de testes em dados com alta cardinalidade) VictoriaMetrics foi a vencedora clara.
Decisão
Prometeu
Em um esforço para melhorar a arquitetura descrita acima, decidimos isolar cada cluster do Kubernetes como uma entidade separada e tornar o Prometheus parte dele. Agora, qualquer novo cluster vem com monitoramento incluído "fora da caixa" e métricas disponíveis em painéis globais (Grafana). Para isso, os serviços kube-eagle, kube-state-metrics e Prometheus foram integrados aos clusters do Kubernetes. O Prometheus foi então configurado com rótulos externos para identificar o cluster e
remote_writeapontado insertno VictoriaMetrics (veja abaixo).
VictoriaMetrics
VictoriaMetrics Time Series Database implementa os protocolos Graphite, Prometheus, OpenTSDB e Influx. Ele não apenas oferece suporte a PromQL, mas também adiciona novos recursos e modelos a ele, evitando a refatoração de consultas Grafana. Além disso, seu desempenho é incrível.
Implementamos VictoriaMetrics em modo de cluster e o dividimos em três componentes separados:
1. Armazenamento VictoriaMetrics (vmstorage)
Este componente é responsável por armazenar os dados importados
vminsert. Nós nos limitamos a três réplicas desse componente, combinadas em um StatefulSet Kubernetes.
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
Inserção VictoriaMetrics (vminsert)
Este componente recebe dados de implantações com o Prometheus e os encaminha para
vmstorage. O parâmetro replicationFactor=2replica dados para dois dos três servidores. Assim, se uma das instâncias vmstorageapresentar problemas ou reiniciar, ainda haverá uma cópia disponível dos dados.
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics select (vmselect)
Aceita solicitações PromQL de Grafana (Trickster) e solicita dados brutos de
vmstorage. Atualmente, desabilitamos o cache ( search.disableCache), pois a arquitetura contém o Trickster, que é o responsável pelo cache; portanto, deve vmselectsempre buscar os dados completos mais recentes.
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
A grande imagem
A implementação atual é semelhante a esta:
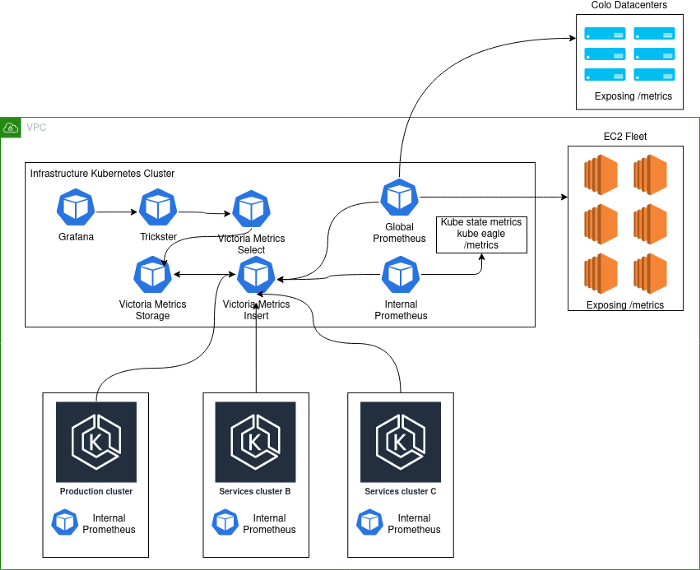
Notas de esquema:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
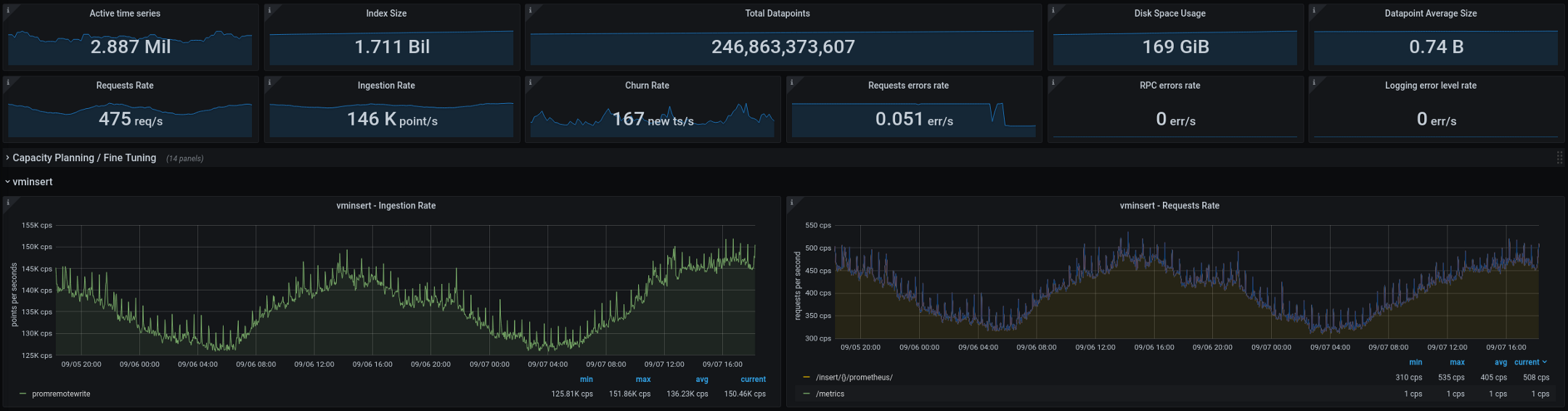
Abaixo estão as métricas atualmente sendo processadas pela VictoriaMetrics (totais de duas semanas, os gráficos mostram um intervalo de dois dias): A nova arquitetura teve um bom desempenho após ser transferida para a produção. Na configuração antiga, tínhamos duas ou três "explosões" de cardinalidade a cada duas semanas; na nova, seu número caiu para zero. Este é um ótimo indicador, mas há mais algumas coisas que planejamos melhorar nos próximos meses:
- Reduza a cardinalidade das métricas, melhorando a integração statsd.
- Compare o cache no Trickster e VictoriaMetrics - você precisa avaliar o impacto de cada solução na eficiência e no desempenho. Suspeita-se que o Trickster pode ser abandonado completamente sem perder nada.
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
Se você tiver alguma sugestão ou ideia para as melhorias descritas acima, entre em contato conosco . Se você está trabalhando para melhorar o monitoramento do Kubernetes, esperamos que este artigo, que descreve nossa difícil jornada, tenha sido útil.
PS do tradutor
Leia também em nosso blog:
- “ O futuro de Prometheus e o ecossistema do projeto (2020) ”;
- “ Monitoramento e Kubernetes ” (revisão e vídeo-relatório);
- " O dispositivo e o mecanismo do Operador Prometheus no Kubernetes ."