
Por exemplo, você tem uma biblioteca de documentos do SharePoint. Quando você adiciona um arquivo a esta biblioteca, geralmente fornece adicionalmente o arquivo com certos metadados. Crie vários campos e escreva neles alguma informação para classificar os arquivos desta biblioteca. Mas isso é feito manualmente e para cada arquivo você precisa inserir dados repetidamente. O SharePoint Syntex foi projetado para automatizar esse processo, extraindo dados importantes de um arquivo de acordo com um modelo personalizado e salvando esses dados nos campos da biblioteca. Isso soa bem. Vamos ver como isso funciona?
Como eu ativo o SharePoint Syntex?
Como o SharePoint Syntex vem sob uma licença separada, precisamos obter essa licença. Vá para o site da Microsoft, encontre o produto SharePoint Syntex e clique em "Teste Grátis".

Após entrar em sua conta do Microsoft 365 e confirmar a ativação da licença de teste, vá para o centro de administração do Microsoft 365. Em seguida, vá para a seção "Configuração" no menu à esquerda e selecione o item Automatizar Entendimento do Conteúdo. No caso de uma localidade russa, como a minha, soará como “Automação de compreensão de conteúdo”.
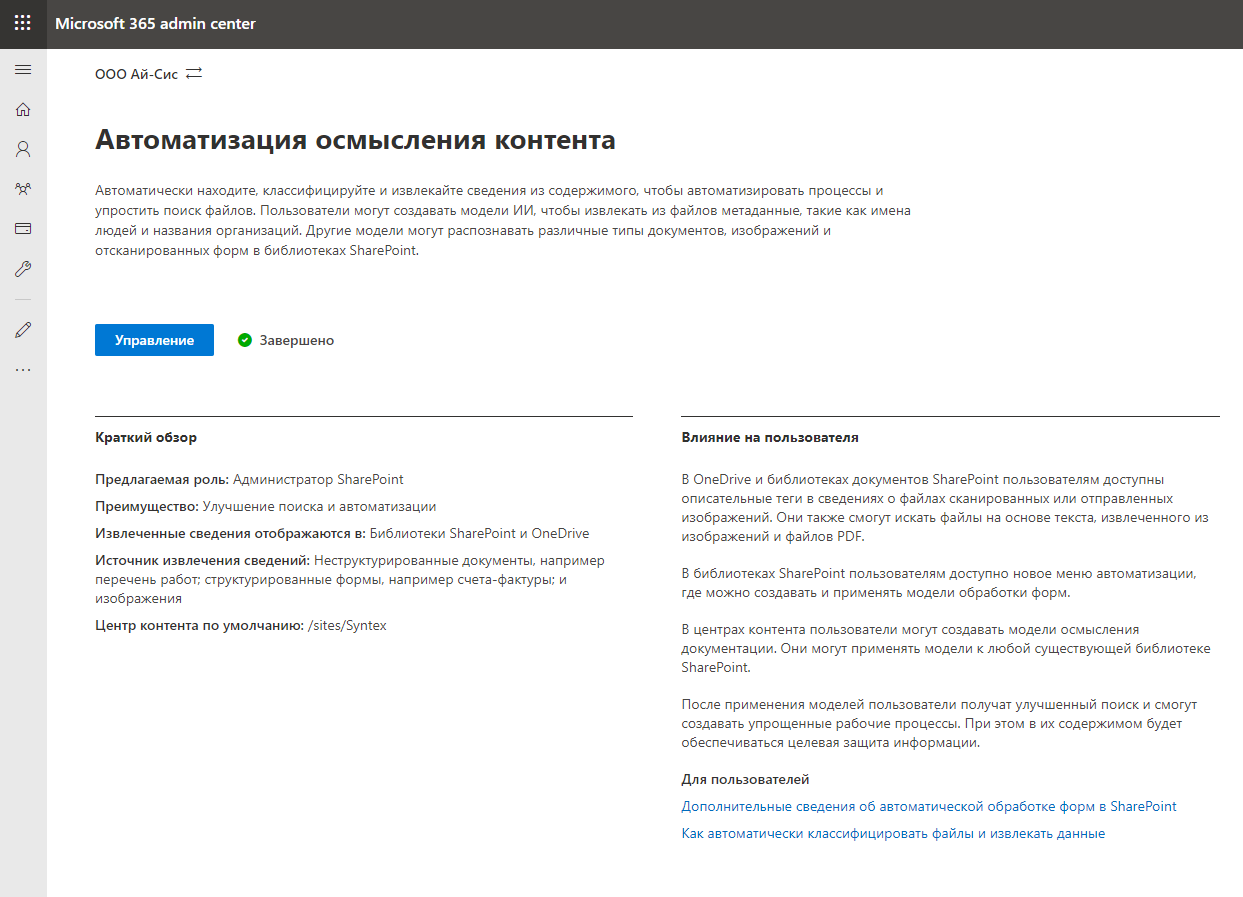
Vamos a "Gestão" e procedemos à configuração do serviço. Em primeiro lugar, é necessário indicar quais bibliotecas oferecerão suporte aos recursos do SharePoint Syntex. Você pode selecionar bibliotecas específicas ou permitir todas as bibliotecas. Vamos quebrar.
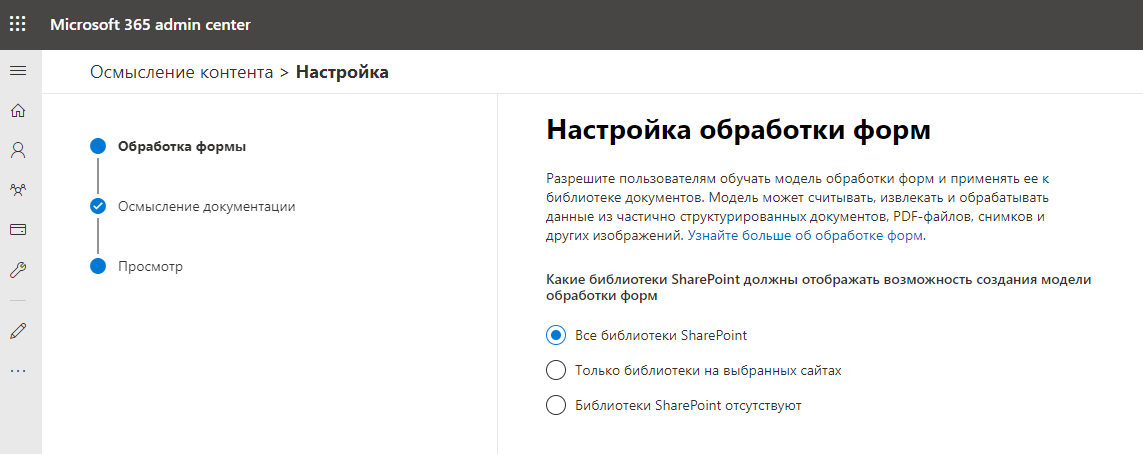
A seguir, indicamos o nome e endereço do site, que será o centro de conteúdo e armazenará os modelos de dados treinados. Parece que um novo site de coleção do SharePoint Online está sendo criado. No entanto, é exatamente isso que está acontecendo.
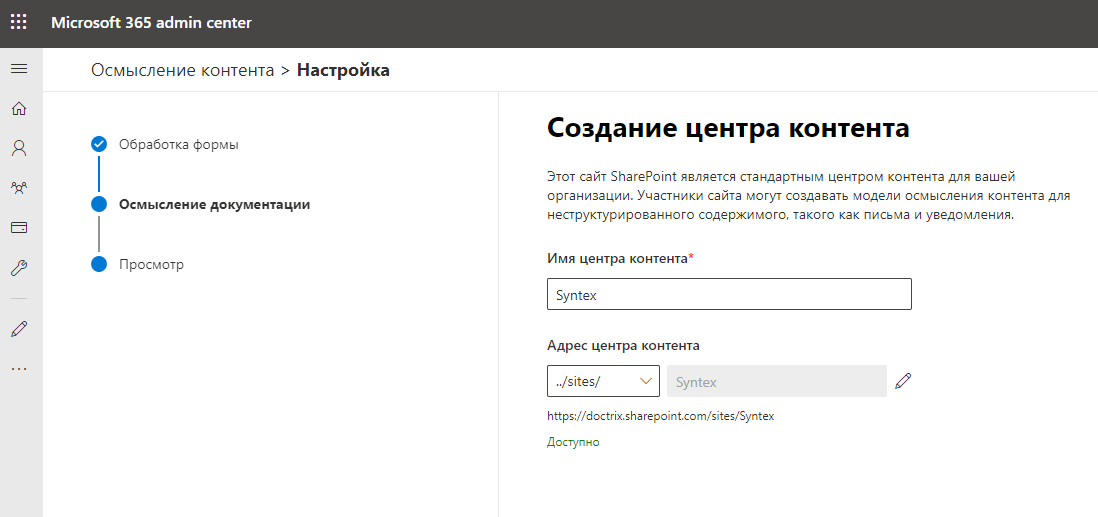
Demora alguns minutos para criar um site de centro de conteúdo. Levei cerca de 5 minutos, só consegui me servir um pouco de chá. Eu venho, e aqui a compreensão do conteúdo já foi ativada, enfim, nossa.
Configurando o SharePoint Syntex
Vá para o site do SharePoint Syntex. Exteriormente, parece um site regular do SharePoint Online, mas isso é apenas à primeira vista. Neste site, iremos configurar e treinar modelos de processamento e análise de dados.
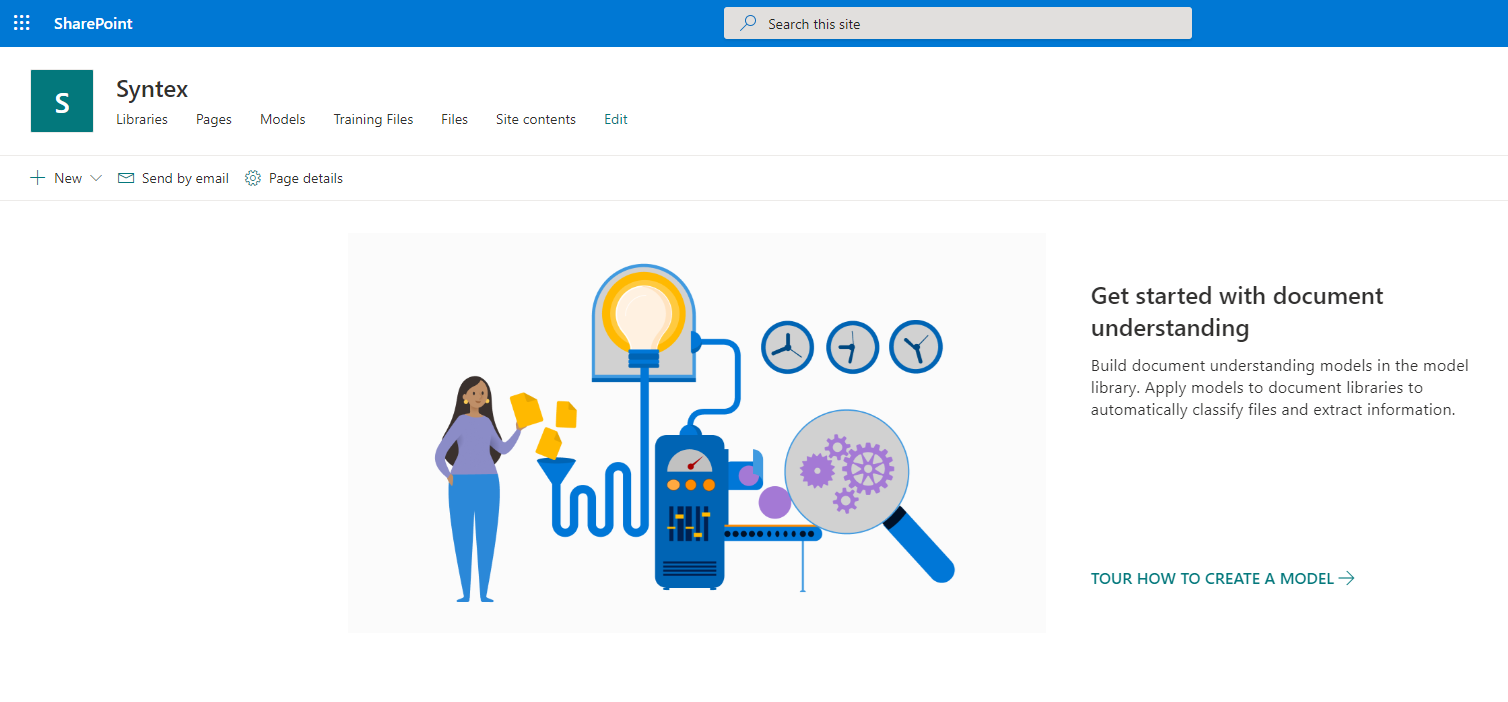
É hora de começar a ajustar o modelo. Clique em "Novo" e selecione o item "Modelo de compreensão do documento".
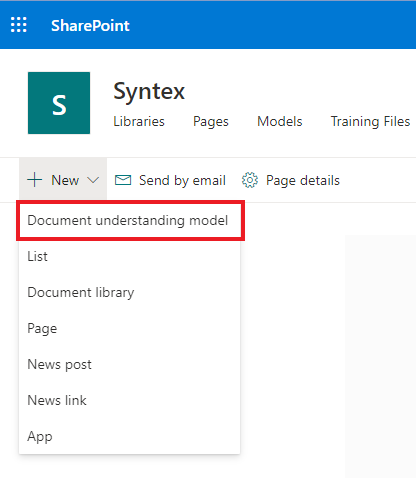
Escrevemos o nome do nosso futuro modelo e indicamos a necessidade de criar um novo tipo de conteúdo para ele. Já escolhi o caso, que provavelmente você já conhece de artigos anteriores, com o pedido de suporte técnico. Não desapareça o mesmo conjunto de modelos para tais recursos.
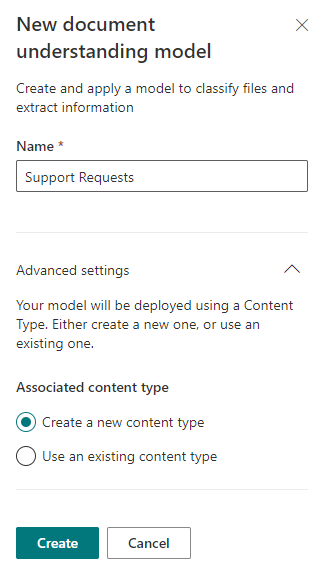
Em seguida, somos recebidos por uma página com instruções passo a passo descrevendo o que precisamos fazer para fazer o futuro modelo funcionar e, idealmente, funcionar corretamente. Portanto, primeiro você precisa carregar vários (pelo menos 5 é recomendado) arquivos, ajudar o SharePoint Syntex a classificá-los conforme necessário e configurar os chamados "Extratores" - modelos para extrair dados de arquivos. Depois de percorrer todo o caminho, você pode aplicar este modelo às bibliotecas do SharePoint necessárias.
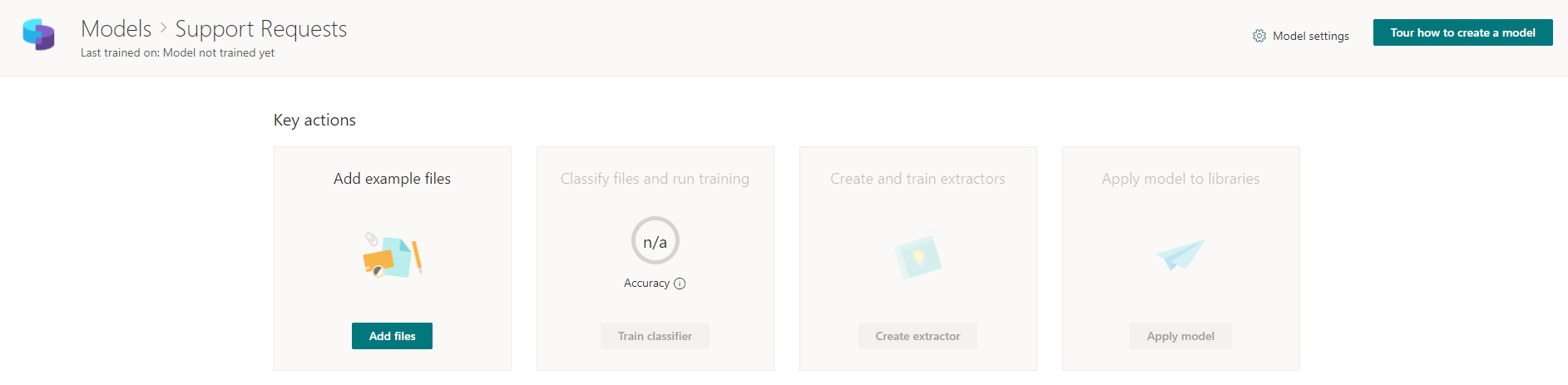
Adicionamos arquivos de modelo preparados que serão usados para classificar futuros arquivos reais.
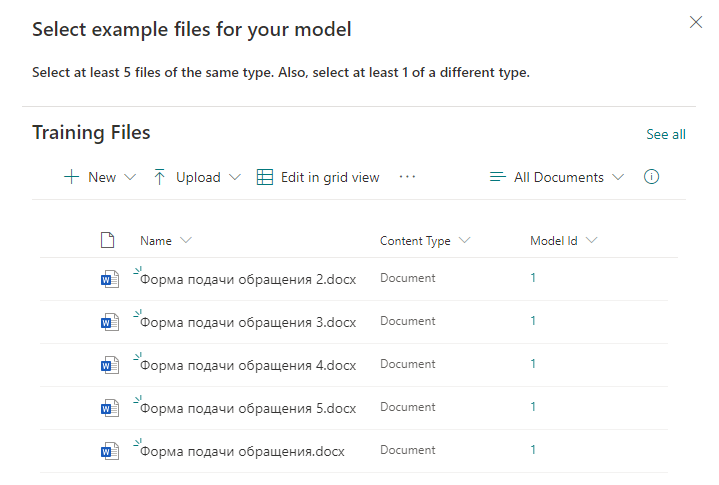
Em seguida, indicamos as palavras-chave pelas quais será feita a busca das informações no documento. Em cada linha, indicamos uma nova palavra ou frase que será utilizada para a pesquisa.
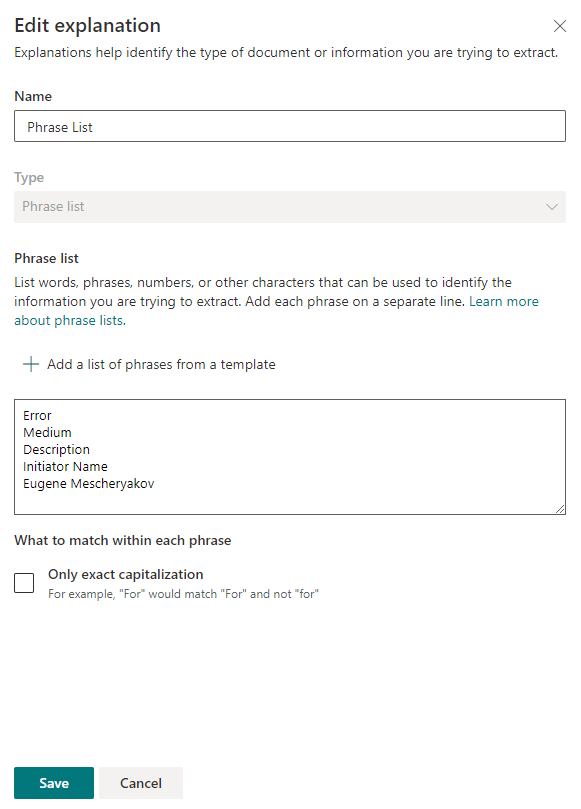
Depois de salvar as configurações, você pode tentar verificar se há frases-chave nos arquivos existentes. Se uma correspondência for encontrada, ao lado do arquivo estará "Corresponder".
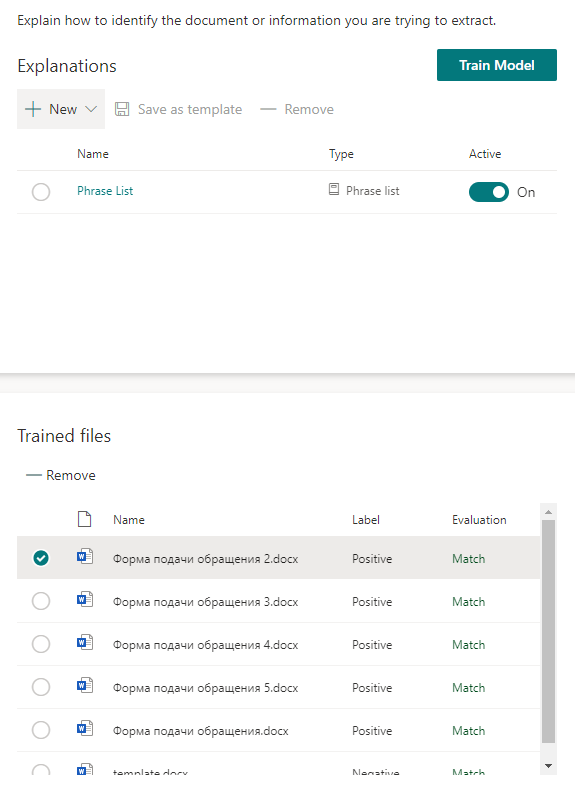
Começamos a treinar a modelo e vamos servir o chá. Vai levar algum tempo.
Após o treinamento do modelo, é necessário configurar os "Extratores" - modelos de extração de dados. Cada extrator é essencialmente um tipo específico de campo do SharePoint que será gerado automaticamente na biblioteca de destino. Após adicionar um arquivo a esta biblioteca, as informações extraídas do arquivo serão gravadas neste campo.
Ao criar um extrator, você precisa especificar seu nome e tipo. Atualmente, 4 tipos são suportados:
- Texto de linha única
- Texto multilinha
- data e hora
- Número
Você também pode usar campos existentes em uma biblioteca do SharePoint.
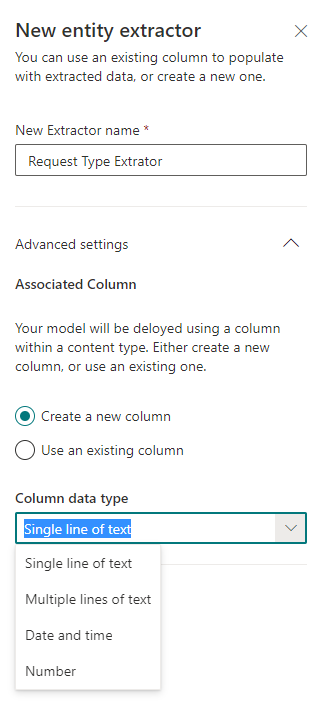
Ao configurar o extrator no template do arquivo carregado, dê um duplo clique sobre a informação que deseja extrair, reconhecida no passo anterior.
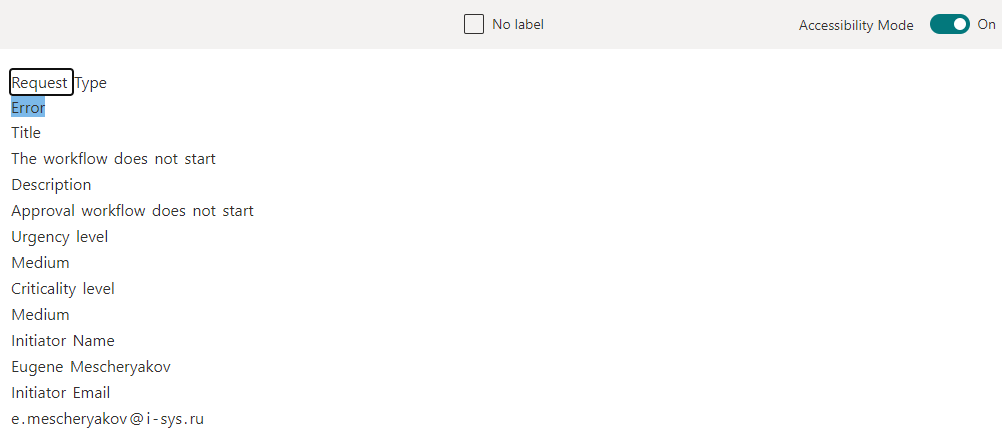
Criamos vários desses extratores, marcamos os dados necessários e, em seguida, passamos para a parte final - aplicando o modelo treinado na biblioteca do SharePoint e verificando se tudo funciona.

Selecione o site do SharePoint necessário e especifique a biblioteca de destino. Criei antecipadamente a biblioteca HelpDesk Requests e não fiz nenhuma alteração nela, deixando-a em sua forma original. Nós salvamos as configurações e vamos para a biblioteca. Depois de salvar as configurações do Syntex do SharePoint, novos campos do SharePoint aparecem na biblioteca, correspondendo por nome e tipo aos extratores criados.
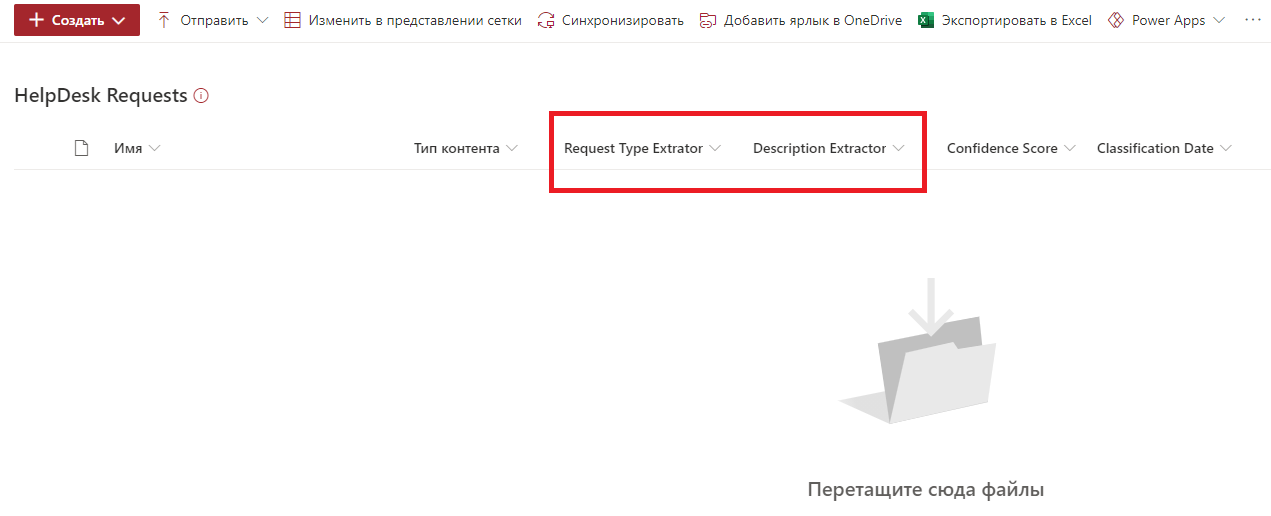
Resta adicionar o arquivo à biblioteca e verificar. Adicione outro arquivo de modelo de solicitação.

O SharePoint Syntex reconheceu o tipo e a descrição do caso. Os dados são armazenados nos campos. Tudo parece estar em ordem.
Total
Configurar o modelo de dados do SharePoint Syntex levou muito pouco tempo, tudo é bastante intuitivo e fácil de configurar e usar. No lado positivo, vejo uma capacidade realmente útil de extrair automaticamente informações importantes do conteúdo do arquivo e gravá-las nos campos do SharePoint. Este recurso pode agilizar significativamente o trabalho e remover etapas desnecessárias do trabalho do usuário, quando, após adicionar um arquivo, ainda é necessário preencher manualmente uma série de requisitos na biblioteca. Contras - Eu gostaria de mais tipos de campos para extratores e integração mais próxima com Microsoft Power Platform. Mas tenho certeza de que isso será adicionado em breve como parte das próximas atualizações.
Além disso, o SharePoint Syntex requer uma licença separada ($ 5 por usuário por mês) e, no momento, não está incluído nas licenças Enterprise do Microsoft 365. Mas no futuro, isso pode mudar e talvez o SharePoint Syntex se torne parte dos serviços básicos do Microsoft 365. Tente ativar a versão de teste por um mês e veja os recursos deste serviço. Tenham um bom dia, pessoal!