O Tensorflow, embora perca terreno no ambiente de pesquisa, ainda é popular no desenvolvimento prático. Um dos pontos fortes do TF que o mantém à tona é a capacidade de otimizar modelos para implantação em ambientes com recursos limitados. Existem estruturas especiais para isso: Tensorflow Lite para dispositivos móveis e Tensorflow Servingpara uso industrial. Existem tutoriais suficientes sobre seu uso na Web (e até no Habré). Neste artigo, coletamos nossa experiência na otimização de modelos sem usar essas estruturas. Veremos alguns dos métodos e bibliotecas que realizam a tarefa, descreveremos como você pode economizar espaço em disco e RAM, os pontos fortes e fracos de cada abordagem e alguns efeitos inesperados que encontramos.
Em que condições trabalhamos
Uma das tarefas clássicas da PNL é a classificação temática de textos curtos. Classificadores são representados por muitas arquiteturas diferentes, variando de métodos clássicos como SVC a arquiteturas de transformador como BERT e seus derivados. Estaremos olhando para CNN - modelos convolucionais.
Uma limitação importante para nós é a necessidade de treinar e usar modelos (como parte do produto) em máquinas sem GPU. Isso afeta principalmente a velocidade de aprendizagem e inferência.
Outra condição é que os modelos de classificação sejam treinados e utilizados em conjuntos de várias peças. Um conjunto de modelos, mesmo os mais simples, pode usar muitos recursos, principalmente RAM. Usamos nossa própria solução para servir modelos, no entanto, se você precisar operar com conjuntos de modelos, dê uma olhada no Tensorflow Serving .
Fomos confrontados com a necessidade de otimizar o modelo no TF versão 1.x, que agora é oficialmente considerado obsoleto. Para TF 2.x, muitas das técnicas discutidas são irrelevantes ou integradas à API padrão e, portanto, o processo de otimização é bastante simples.
Vamos dar uma olhada na estrutura de nosso modelo primeiro.
Como funciona o modelo TF
Considere a chamada Shallow CNN - uma rede com uma camada convolucional e vários filtros. Este modelo funcionou bem o suficiente para classificação de texto em representações de palavras vetoriais.

Para simplificar, usaremos um conjunto fixo pré-treinado de representações vetoriais de dimensão v x k , onde v é o tamanho do dicionário, k é a dimensão dos embeddings.
:
- Embedding-, .
- w x k. , (1, 1, 2, 3) 4 , 1 , 2 3 , .
- Max-pooling .
- , dropout- softmax- .
Adam, .
: .
, , 128 c w = 2 k = 300 () [filter_height, filter_width, in_channels, output_channels] — , 2*300*1*128 = 76800 float32, , 76800*(32/8) = 307200 .
? ( 220 . ) 300 265 . , .
TF . ( ), , , — ( ), . (). :
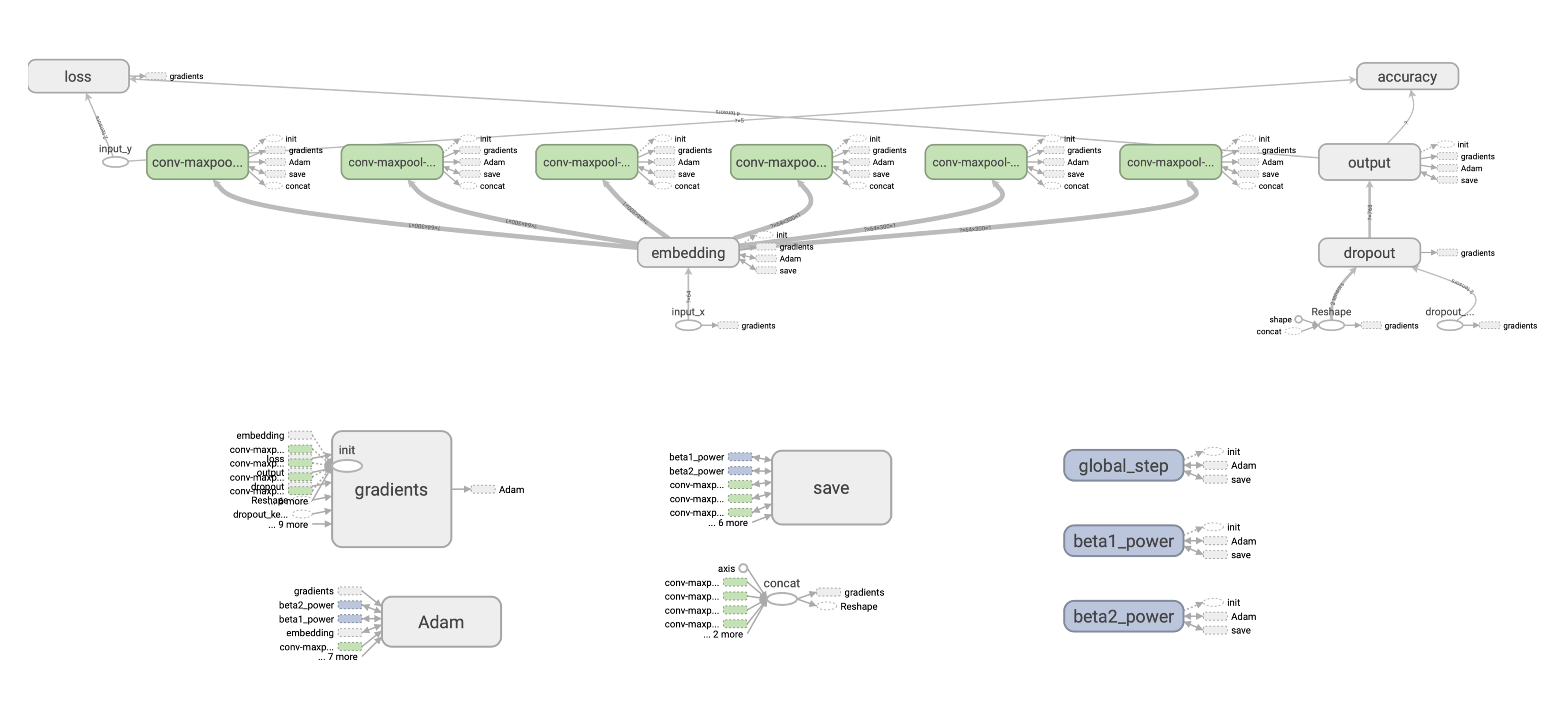
. , : SavedModel. , .
Checkpoint
, Saver API:
saver = tf.train.Saver(save_relative_paths=True)
ckpt_filepath = saver.save(sess, "cnn.ckpt"), global_step=0)global_step , , — cnn-ckpt-0.
<model_path>/cnn_ckpt :

checkpoint — . , TF . , .
.data , . , — 800 . , (≈265 ). ( ). , .
.index .
.meta — , (, , ), GraphDef, . , . — .meta , ? , TF - embedding-. , , , , , . , , :
with tf.Session() as sess:
saver = tf.train.import_meta_graph('models/ckpt_model/cnn_ckpt/cnn.ckpt-0.meta') # load meta
for n in tf.get_default_graph().as_graph_def().node:
print(n.name, n['attr'].shape)SavedModel
, . . API tf.saved_model. tf.saved_model, TF- (TFLite, TensorFlow.js, TensorFlow Serving, TensorFlow Hub).
:
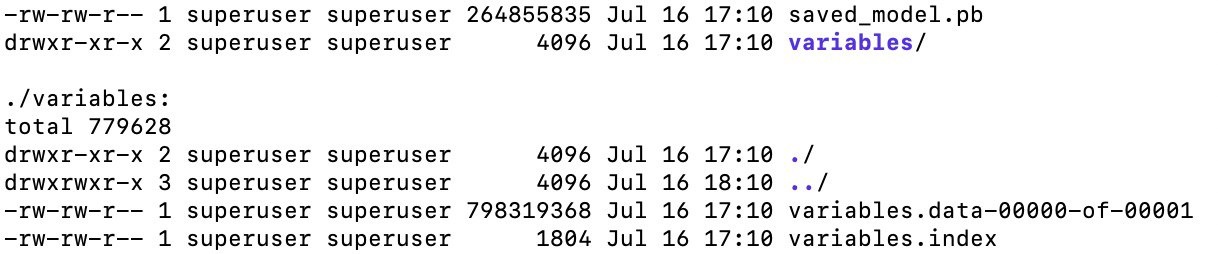
saved_model.pb, , , .meta , (, ), API, ( CLI, ).
SavedModel — , . “” . , , - — , .
, CNN-, TF 1.x, . .
, 1 , :
-
. , , ( tools.optimize_for_inference ). -
. , , — , tf.trainable_variables(). -
, . , (. BERT). -
. , . .
, , . , forward pass, . , . 1 265 .
TF 1.x , .
( ) GraphDef:
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def() . : tf.python.tools.freeze_graph tf.graph_util.convert_variables_to_constants. ( ) (, ['output/predictions']), , , . .
output_graph_def = graph_util.convert_variables_to_constants(self.sess, input_graph_def, output_node_names), .
freeze_graph() ( , , ). graph_util.convert_variables_to_constants() :
with tf.io.gfile.GFile('graph.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())266 , :
# GraphDef
with tf.io.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
#
self.input_x = tf.placeholder(tf.int32, [None, self.properties.max_len], name="input_x")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# graph_def
input_map = {'input_x': self.input_x, 'dropout_keep_prob': self.dropout_keep_prob}
tf.import_graph_def(graph_def, input_map), import:
predictions = graph.get_tensor_by_name('import/output/predictions:0'):
feed_dict = {self.input_x: encode_sentence(sentence), self.dropout_keep_prob: 1.}
sess.run(self.predictions, feed_dict), :
- . ,
sess.run(...). , CPU 20 ms, ~2700 ms. , . SavedModel . - RAM. RAM, . ~265 , . , TF GraphDef .
- – RAM TF . 1.15, TF 1.x, 118 MiB, 1.14 – 3 MiB.
, . ? / TF- tf.train.Saver. , , , :
- MetaGraph
tf.train.Saver . , :
saver = tf.train.Saver(var_list=tf.trainable_variables())MetaGraph . , meta . MetaGraph save:
ckpt_filepath = saver.save(self.sess, filepath, write_meta_graph=False)1014 M 265 M ( , ).
, TF 1.x:
- Grappler: c tensorflow
- Pruning API: google-research
- Graph Transform Tool:
, — tensorflow, Grappler. Grappler . , set_experimental_options. , zip . , zip , . Grappler .
google-research mask threshold, . . , , mask threshold, , , . .
Grappler, . : ? , ? , 0.99 . , mc, hex :

, , . . -, . -, , , , . , .
CNN. .
, . Graph transform tool.
quantize_weights 8 . , 8- . , , - .
quantize_nodes 8- . .
, - . quantize_weights - , 4 .
, , TensorFlow Lite, .
— , . 64 (32) , .
RAM Ubuntu ( numpy int64) . 220 , int32, int16. .

tf-. float16. , , ( 10%), ( 10 ). , , epsilon learning_rate . , , .
RAM
, . , .
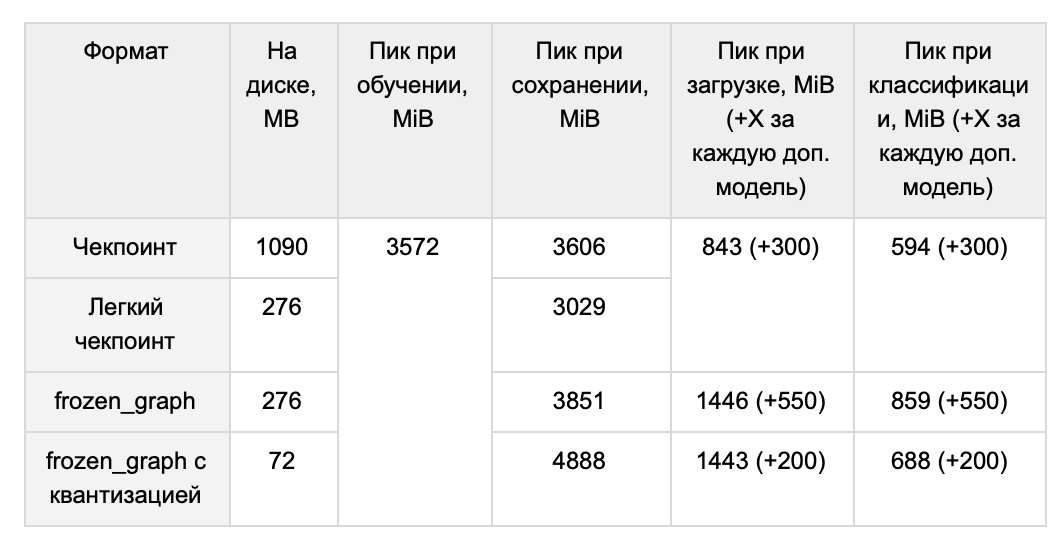
, . . .
QA-
Q: -, - ?
A: , . word2vec. ( , , min count, learning rate), 220 ( — 265 MB) CNN, 439 (510 MB).
- , , , - . , ( ). , . YouTokenToMe, , , .. , .., . . , , , . 30 (37 MB) , 3.7 CPU 2.6 GPU. ( ), OOV-.
Q: , , ?
A: , .
:
1. :
with tf.gfile.GFile(path_to_pb, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
return graph2. "" :
sess.run(restored_variable_names) 3. , .
4. , , :
tf.Variable(tensors_to_restore["output/W:0"], name="W"), .
, , .
Não tentamos retreinar os modelos comprimidos pelo resto dos métodos descritos, mas teoricamente não deveria haver problemas com isso.
P: Existem outras maneiras de reduzir a otimização que você não considerou?
R: Temos várias ideias que nunca percebemos. Em primeiro lugar, o dobramento constante é um “dobramento” de um subconjunto de nós do gráfico, pré-cálculo dos valores das partes do gráfico que são fracamente dependentes dos dados de entrada. Em segundo lugar, em nosso modelo, parece uma boa solução aplicar poda de embeddings.