Devo observar que um mês depois de me familiarizar com essa tecnologia, comecei a usar antidepressivos. Não se sabe ao certo se o NiFi foi o gatilho ou a gota d'água, bem como seu envolvimento neste fato. Mas, como me propus a delinear tudo o que aguarda um potencial iniciante neste caminho, devo ser o mais franco possível.
Numa altura em que, tecnicamente, o Apache NiFi é um elo poderoso entre vários serviços (troca dados entre eles, permitindo que sejam enriquecidos e modificados ao longo do caminho), vejo- o do ponto de vista de um analista . Isso ocorre porque o NiFi é uma ferramenta ETL muito útil. Em particular, como uma equipe, nos concentramos na construção de sua arquitetura SaaS.
A experiência de automatizar um dos meus workflows, nomeadamente a formação e distribuição de relatórios semanais no Jira Software , quero divulgar neste artigo. A propósito, também descreverei e publicarei a metodologia de análise do rastreador de tarefas, que responde claramente à pergunta - o que os funcionários estão fazendo?
Apesar da dedicação deste artigo aos iniciantes, acho correto e útil que arquitetos mais experientes (gurus, por assim dizer) o revisem em comentários ou compartilhem seus casos de uso de NiFi em vários campos de atividade. Muitos caras, inclusive eu, vão agradecer.
O conceito Apache NiFi em resumo.
Apache NiFi é um produto de código aberto para automatizar e gerenciar fluxos de dados entre sistemas. Para começar, é importante perceber imediatamente duas coisas.
A primeira é a zona de código baixo. O que eu quero dizer? Supõe-se que todas as manipulações com dados, desde o momento em que entram no NiFi até a extração, podem ser realizadas com ferramentas (processadores) padrão. Para casos especiais, existe um processador para a execução de scripts do bash.
Isso sugere que fazer algo no NiFi é errado - é bastante difícil (mas consegui! - esse é o segundo ponto). Difícil porque qualquer processador irá chutá-lo imediatamente - E para onde enviar os erros? O que fazer com eles? Quanto tempo de espera? E aqui você me deu um pouco de espaço! Você leu a documentação com atenção? etc.

A segunda (chave) é o conceito de programação de streaming e nada mais. Aqui, eu pessoalmente, não entendi imediatamente (por favor, não julgue). Tendo experiência em programação funcional em R, eu, sem saber, modelei funções em NiFi. No final das contas - refaça - meus colegas me disseram quando viram minhas tentativas inúteis de tornar essas "funções" amigas.
Acho que a teoria é o suficiente por hoje, vamos aprender tudo da prática melhor. Vamos formular uma similaridade de especificações técnicas para análises semanais de Jira.
- Obtenha o log de trabalho e o histórico de alterações da gordura da semana.
- Exiba as estatísticas básicas para este período e responda à pergunta: o que a equipe estava fazendo?
- Envie um relatório ao chefe e aos colegas.
Para trazer mais benefícios ao mundo, não parei no período semanal e desenvolvi um processo com capacidade de baixar uma quantidade muito maior de dados.
Vamos descobrir.
Os primeiros passos. Buscando dados da API
O Apache NiFi não tem um projeto separado. Temos apenas um espaço de trabalho comum e a capacidade de formar grupos de processos nele. Isso é o bastante.
Encontre o Grupo de processos na barra de ferramentas e crie o grupo Jira_report. Vá até o grupo e comece a construir o fluxo de trabalho. A maioria dos processadores a partir dos quais ele pode ser montado requer uma conexão upstream. Em palavras simples, este é um gatilho no qual o processador irá disparar. Portanto, é lógico que todo o fluxo começará com um acionador regular - em NiFi, este é o processador GenerateFlowFile. O que ele faz. Cria um arquivo de streaming que consiste em um conjunto de atributos e conteúdo. Atributos são pares de chave / valor de string associados ao conteúdo.
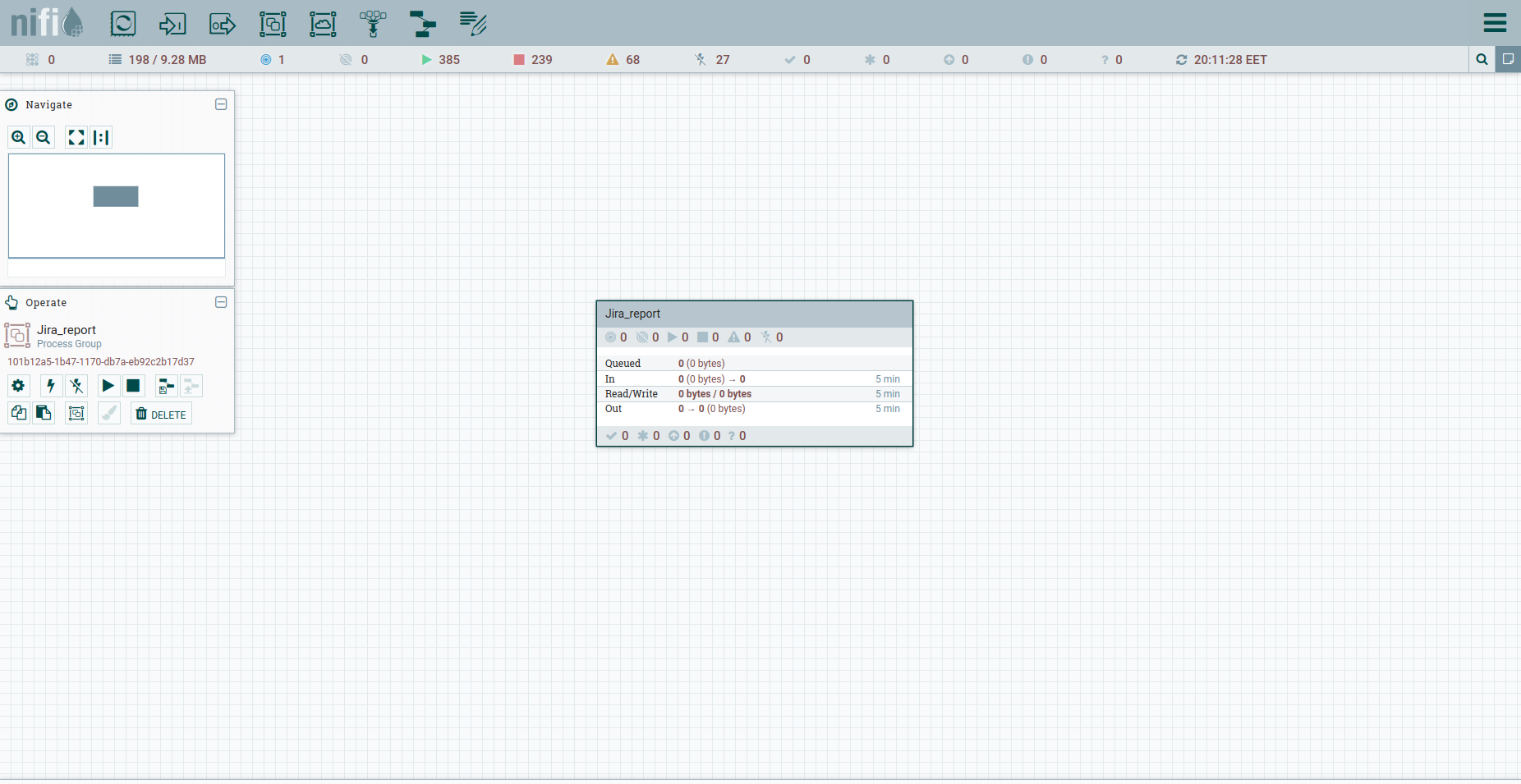
O conteúdo é um arquivo normal, um conjunto de bytes. Imagine que o conteúdo é um anexo a um FlowFile.
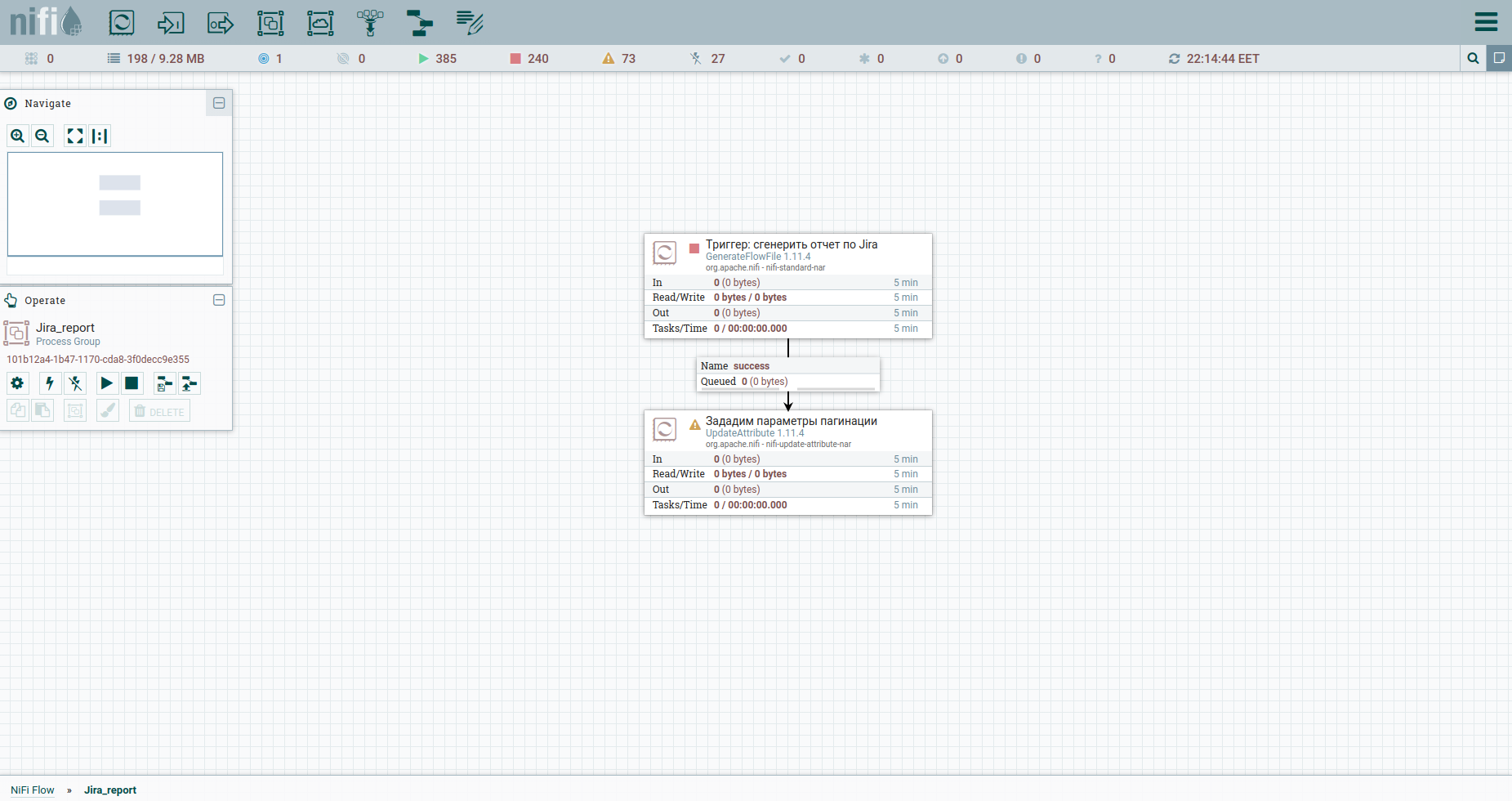
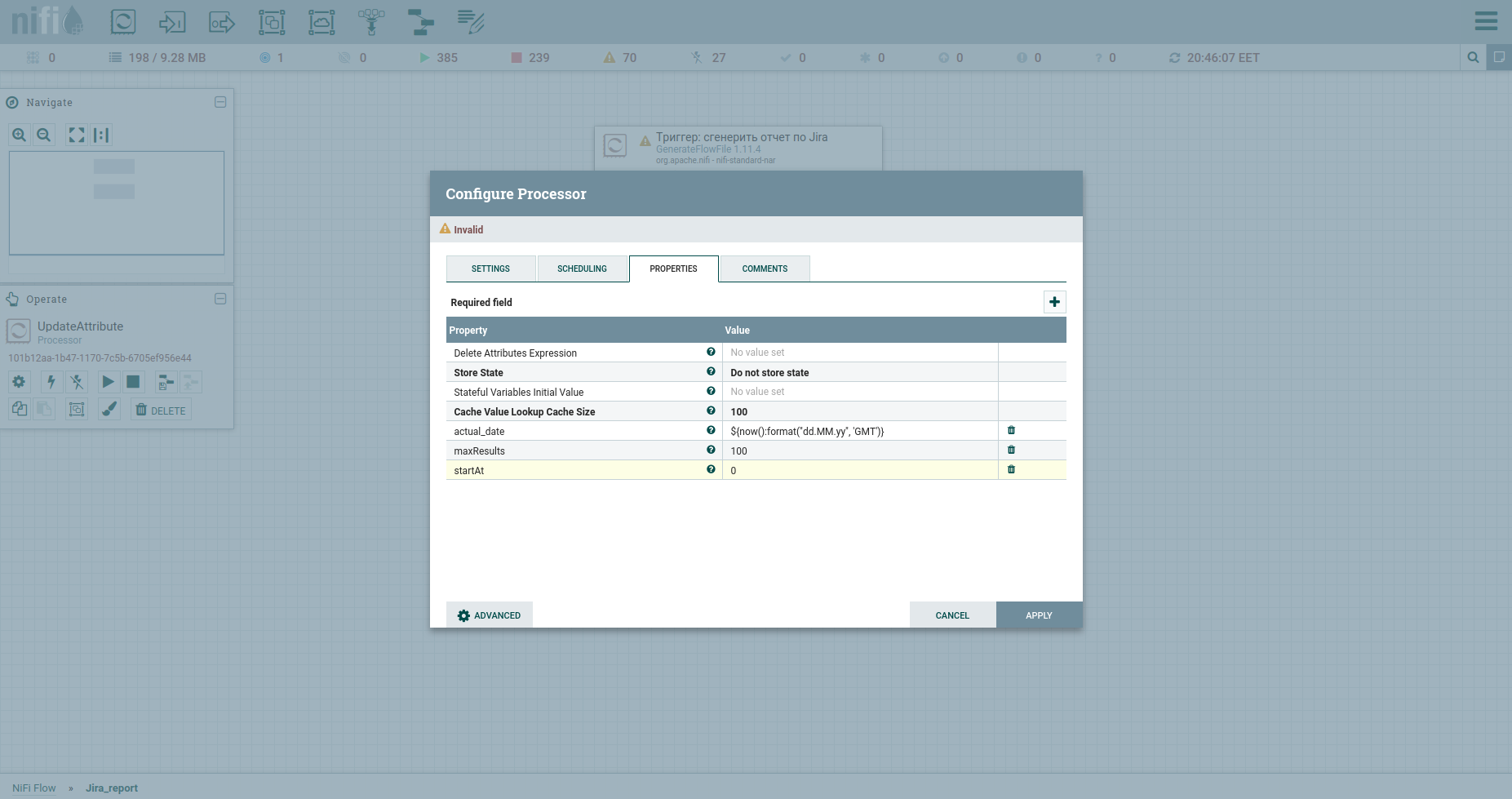
Fazemos Adicionar Processador → GenerateFlowFile. Nas configurações, em primeiro lugar, eu recomendo fortemente definir o nome do processador (este é um bom tom) - a guia Configurações. Outro ponto: por padrão, GenerateFlowFile gera arquivos de fluxo continuamente. É improvável que você precise disso. Aumentamos imediatamente a programação de execução, por exemplo, para 60 segundos - a guia Programação. Além disso, na guia Propriedades, indicaremos a data de início do período do relatório - o atributo report_from com um valor no formato - aaaa / mm / dd. De acordo com a documentação da API Jira, temos um limite de problemas de descarregamento - não mais que 1000. Portanto, para obter todas as tarefas, teremos que formar uma solicitação JQL, que especifica os parâmetros de paginação: startAt e maxResults.

Vamos defini-los com atributos usando o processador UpdateAttribute. Ao mesmo tempo, fixaremos a data de geração do relatório. Precisamos disso mais tarde. Você provavelmente notou o atributo actual_date. Seu valor é definido usando Expression Language. Pegue uma folha de cola legal sobre ele. Isso é tudo, podemos formar JQL para fat - vamos indicar os parâmetros de paginação e os campos obrigatórios. Posteriormente, será o corpo da solicitação HTTP, portanto, iremos enviá-lo para o conteúdo. Para fazer isso, usamos o processador ReplaceText e especificamos seu valor de substituição mais ou menos assim:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}Observe como os links de atributos são escritos.
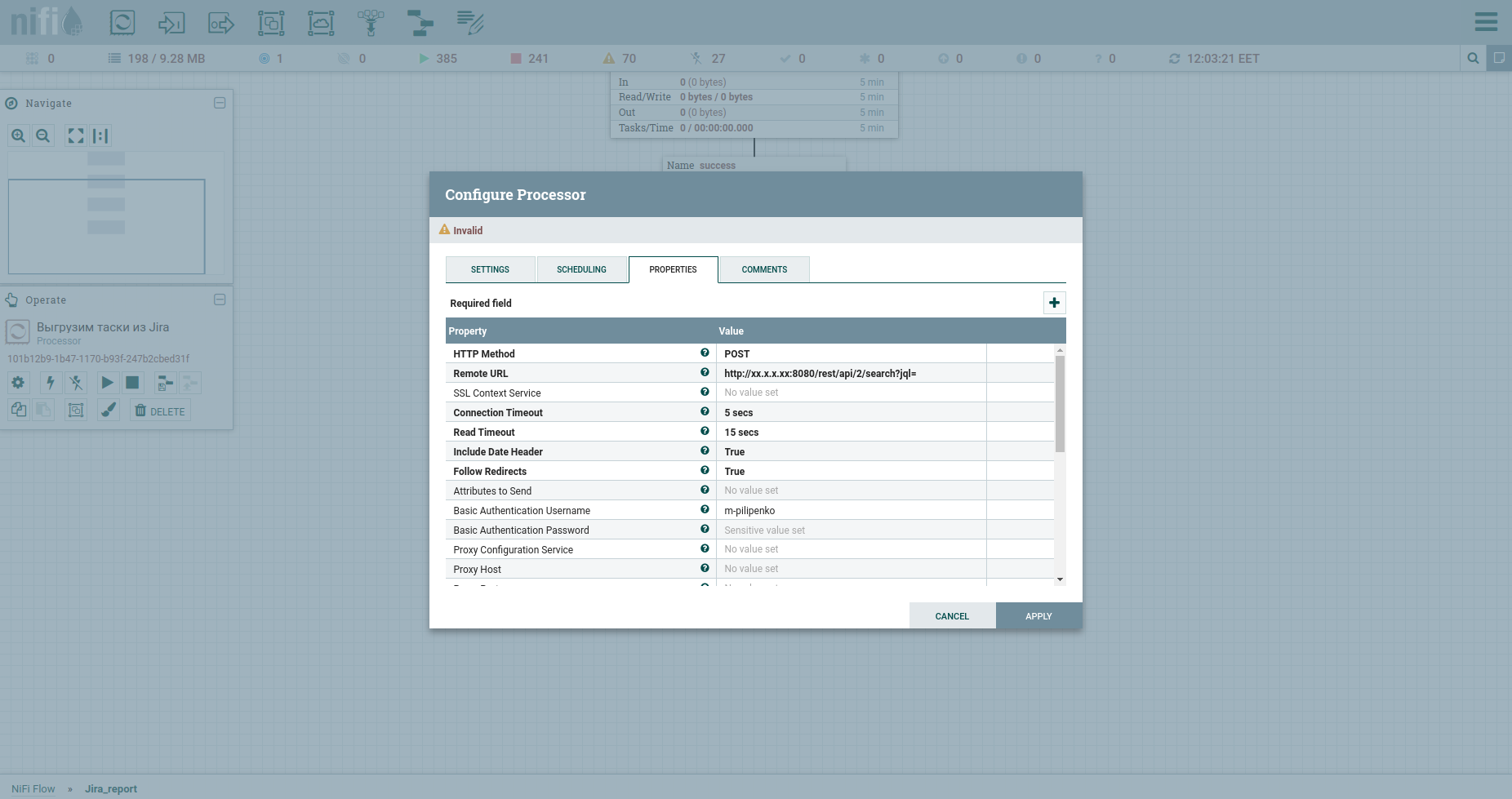
Parabéns, estamos prontos para fazer uma solicitação HTTP. O processador InvokeHTTP caberá aqui. A propósito, ele pode fazer qualquer coisa ... quero dizer os métodos GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Vamos modificar suas propriedades da seguinte maneira:
Método HTTP temos POST.
O URL remoto de nossa gordura inclui IP, porta e / rest / api / 2 / search? Jql =.
Nome de usuário de autenticação básica e Senha de autenticação básica são credenciais para fat.
Altere o Content-Type para application / json b coloque true no Send Message Body, o que significa enviar JSON que virá do processador anterior no corpo da solicitação.
APLIQUE.
A resposta do apish será um arquivo JSON que será incluído no conteúdo. Estamos interessados em duas coisas nele: o campo total contendo o número total de tarefas no sistema e a matriz de problemas, que já contém algumas delas. Vamos analisar a resposta e nos familiarizar com o processador EvaluateJsonPath.
No caso em que JsonPath aponta para um objeto, o resultado da análise será gravado no atributo de arquivo de fluxo. Aqui está um exemplo - o campo total e a tela a seguir. No caso em que JsonPath aponta para uma matriz de objetos, como resultado da análise, o arquivo de fluxo será dividido em um conjunto com conteúdo correspondente a cada objeto. Aqui está um exemplo - o campo de problema. Colocamos outro EvaluateJsonPath e escrevemos: Property - issue, Value - $ .issue.

Nosso fluxo agora consistirá não em um arquivo, mas em muitos. O conteúdo de cada um deles conterá JSON com informações sobre uma tarefa específica.
Ir em frente. Lembra que definimos maxResults como 100? Após a etapa anterior, teremos cem primeiras tarefas. Vamos obter mais e implementar a paginação.
Para fazer isso, vamos aumentar o número da tarefa inicial em maxResults. Vamos usar UpdateAttribute novamente: especificaremos o atributo startAt e atribuiremos a ele um novo valor $ {startAt: plus ($ {maxResults})}.
Bem, não podemos prescindir de uma verificação para atingir o número máximo de tarefas - o processador RouteOnAttribute. As configurações são as seguintes: E loop. No total, o ciclo será executado enquanto o número da tarefa inicial for menor que o número total de tarefas. Na saída dele - um fluxo de tasoks. É assim que o processo se parece agora:

Sim, amigos, eu sei - vocês estão cansados de ler meus comentários a cada quadrado. Você quer entender o próprio princípio. Não tenho nada contra isso.
Esta seção deve tornar mais fácil para um iniciante absoluto entrar em NiFi. Além disso, tendo em mãos um modelo generosamente apresentado por mim, não será difícil me aprofundar nos detalhes.
Galope pela Europa. Carregando um log de trabalho, etc.
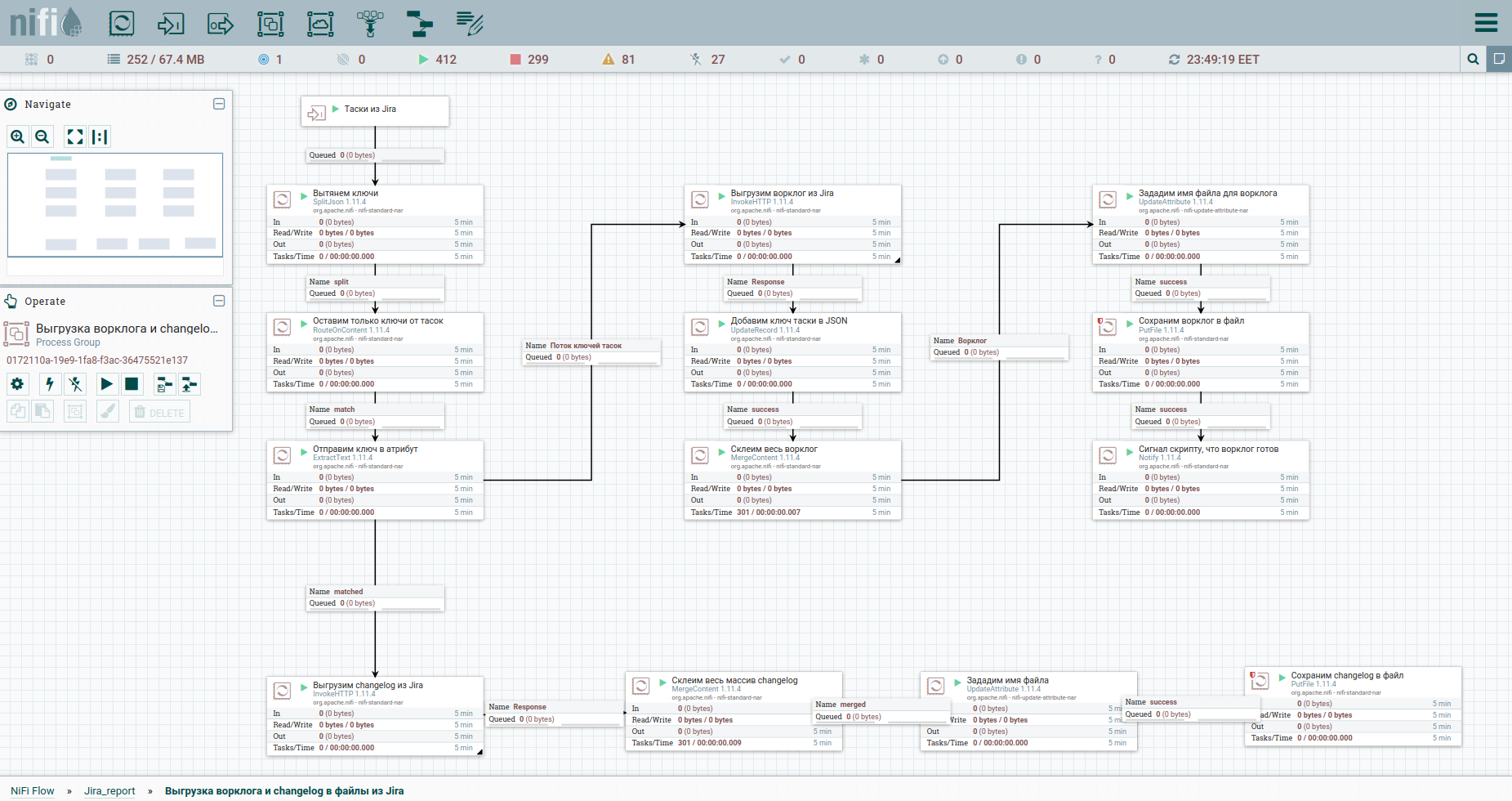
Bem, vamos acelerar. Como se costuma dizer, encontre as diferenças: Para uma percepção mais fácil, movi o processo de descarregar o log de trabalho e o histórico de mudanças em um grupo separado. Aqui está: Para contornar as limitações ao descarregar automaticamente um log de trabalho do Jira, é aconselhável consultar cada tarefa separadamente. É por isso que precisamos de suas chaves. A primeira coluna apenas converte o fluxo de tarefas em um fluxo de chaves. Em seguida, voltamos para o macaco e salvamos a resposta. Será conveniente para nós organizar o log de trabalho e o log de mudanças para todas as tarefas na forma de documentos separados. Portanto, usaremos o processador MergeContent e colaremos o conteúdo de todos os arquivos de fluxo com ele.
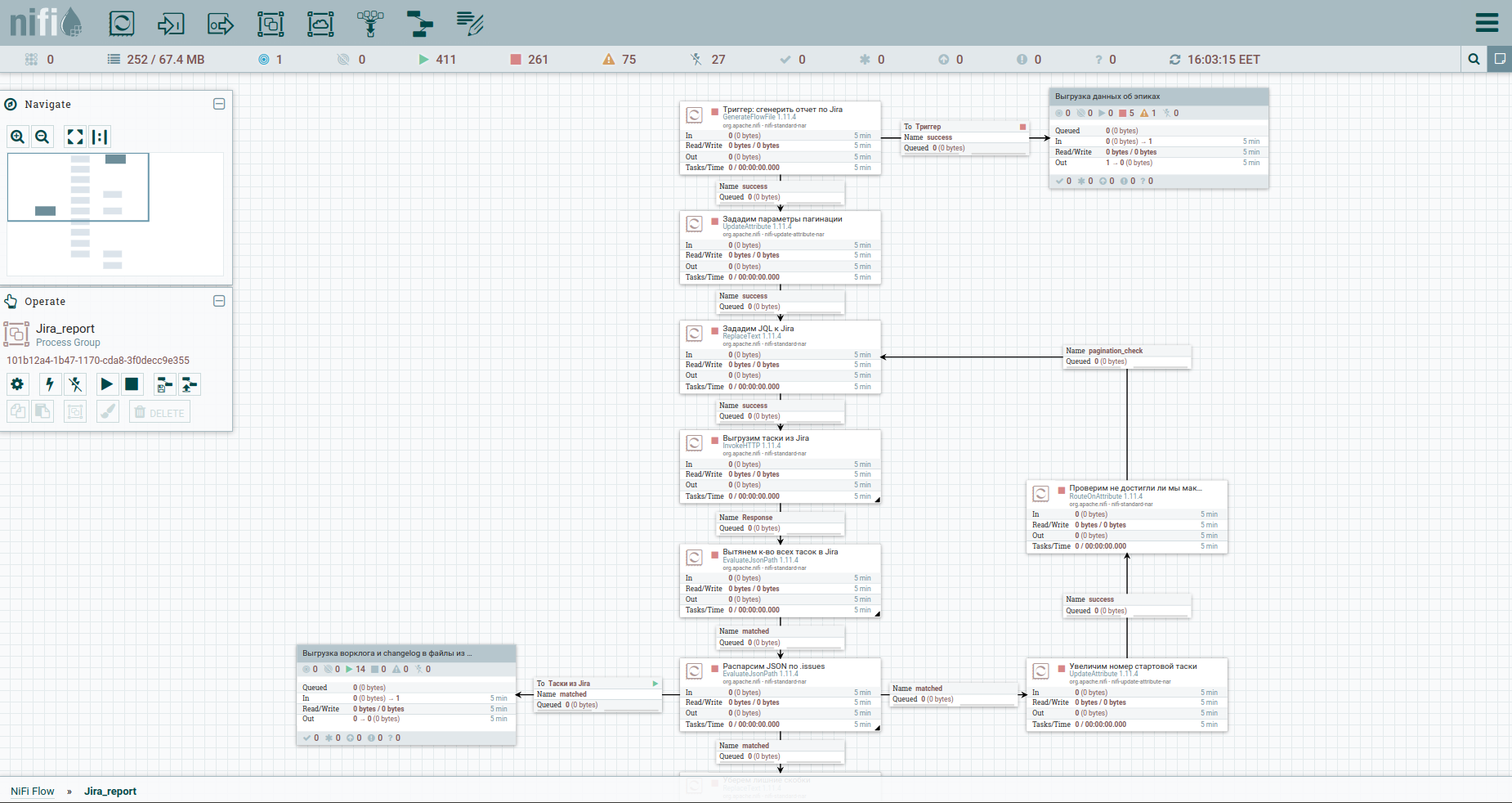
Também no modelo você notará um grupo para descarregar dados por epopeias. Um épico em Jira é uma tarefa comum à qual muitos outros se ligam. Este grupo será útil no caso em que apenas parte das tarefas seja minerada, para não perder informações sobre as epopéias de algumas delas.
A etapa final. Geração e envio de relatórios por e-mail
OK. Todos os pontos foram descarregados e seguiram de duas maneiras: para o grupo para descarregar o worklog e para o script para gerar o relatório. Por último, temos um STDIN, então precisamos coletar todas as tarefas em uma pilha. Vamos fazer isso em MergeContent, mas antes disso vamos ajustar um pouco o conteúdo para que o json final esteja correto. Há um processador Wait interessante na frente do quadrado de geração de script (ExecuteStreamCommand). Ele aguarda um sinal do processador Notify, que está no grupo de descarregamento do log de trabalho, de que tudo está pronto ali e você pode seguir em frente. Em seguida, executamos o script de bash-a - ExecuteStreamCommand. E enviamos o relatório via PutEmail para toda a equipe.

Contarei a vocês em detalhes sobre o script, bem como sobre a experiência de implementação do Jira Software analytics em nossa empresa em um artigo separado, que estará pronto outro dia.
Em suma, o relatório que desenvolvemos fornece uma visão estratégica do que uma unidade ou equipe está fazendo. E isso é inestimável para qualquer chefe, você deve concordar.
Posfácio
Por que se exaurir se você pode fazer tudo isso com um script de uma vez, você pergunta. Sim, concordo, mas parcialmente.
O Apache NiFi não simplifica o processo de desenvolvimento, ele simplifica a operação. Podemos interromper qualquer tópico a qualquer momento, fazer uma edição e começar de novo.
Além disso, o NiFi nos dá uma visão de cima para baixo dos processos pelos quais a empresa vive. No próximo grupo, terei outro script. Outro será o julgamento do meu colega. Você entendeu, certo? Arquitetura na palma da sua mão. Como nosso chefe brinca, estamos implementando o Apache NiFi para que possamos despedir todos vocês mais tarde, e eu era o único a apertar os botões. Mas isso é uma piada.
Bem, neste exemplo, os pãezinhos em forma de tarefa de agendamento para geração de relatórios e envio de cartas também são muito, muito agradáveis.
Confesso que estava planejando abrir minha alma e contar a vocês sobre o ancinho em que pisei no processo de estudar tecnologia - quantos deles. Mas aqui já é longa. Se o assunto for interessante, por favor me avise. Enquanto isso, amigos, obrigado e espero nos comentários.
Links Úteis
Um artigo engenhoso que cobre o Apache NiFi diretamente em seus dedos e por letras.
Um pequeno guia em russo.
Uma folha de dicas legal do Expression Language.
A comunidade Apache NiFi de língua inglesa está aberta a perguntas.
A comunidade Apache NiFi de língua russa no Telegram está mais viva do que todas as coisas vivas.