
Algumas palavras sobre sistemas de recomendação
Certamente, todos os conheceram mais de uma vez. Os sistemas de recomendação são programas e serviços que tentam prever o que pode ser interessante / necessário / útil para um determinado usuário e mostrar isso a ele. “Você gosta desses tênis de corrida? Você também pode precisar de um corta-vento, monitor de frequência cardíaca e mais 15 itens esportivos . " Nos últimos anos, as marcas têm sido muito ativas na introdução de sistemas de recomendação em seu trabalho, uma vez que tanto o vendedor quanto o comprador "se beneficiam" dessa decisão. O consumidor recebe uma ferramenta que o ajuda a fazer uma escolha em uma variedade infinita de bens e serviços em um curto espaço de tempo, e o negócio aumenta as vendas e a audiência.
O que nos foi dado?
Trabalhei em um projeto para uma grande empresa global que fornece aos seus clientes uma solução de bolsa de carga SaaS ou uma plataforma de bolsa de carga.
Parece incompreensível, mas como realmente acontece: por um lado, são cadastrados na plataforma os usuários que possuem cargas e que precisam enviá-las para algum lugar. Eles colocam um aplicativo como "Há um lote de cosméticos decorativos, precisa ser levado amanhã de Amsterdã para Antuérpia"e estão esperando uma resposta. Por outro lado, temos pessoas ou empresas com caminhões - transportadores de carga. Digamos que eles já tenham feito seu voo semanal padrão, entregando iogurtes de Paris a Bruxelas. Eles precisam voltar e, para não ir com o caminhão vazio, encontrar algum tipo de carga para transportar na volta. Para isso, os transportadores vão até a plataforma do meu cliente e fazem uma pesquisa (da pesquisa em inglês), indicando a direção e, possivelmente, o tipo de carga (ou frete, do frete em inglês), adequada para um caminhão. O sistema coleta os aplicativos dos remetentes e os mostra às transportadoras.
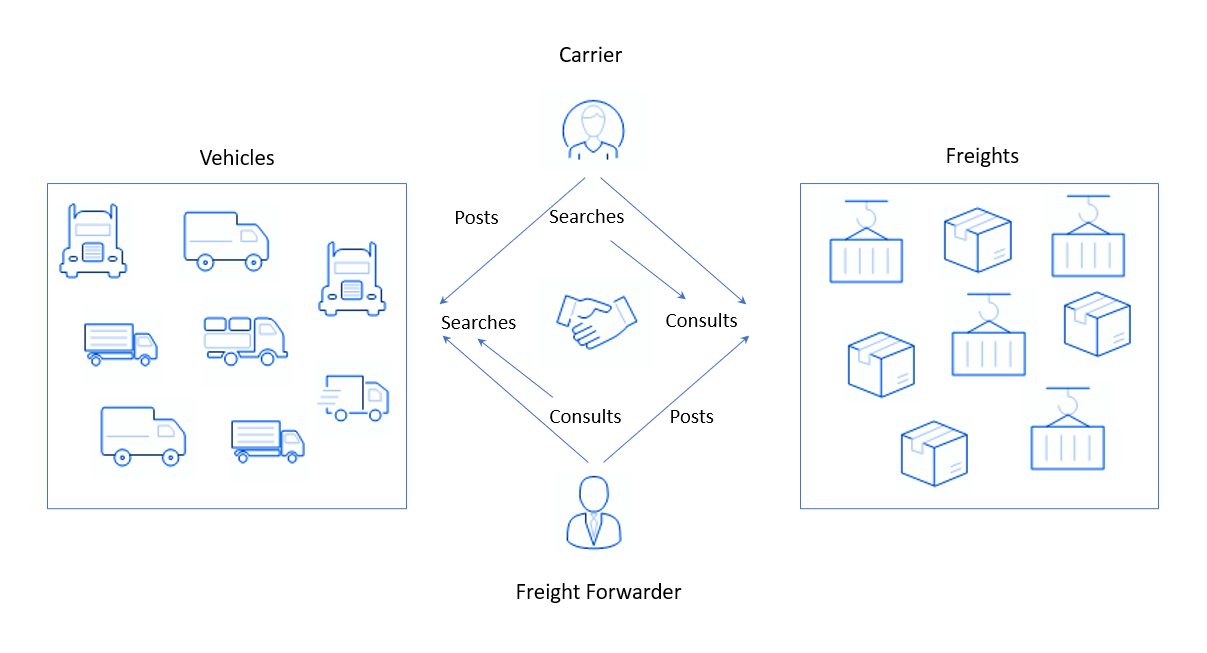
Nessas plataformas, o equilíbrio entre oferta e demanda é importante. Aqui, as mercadorias são procuradas por transportadores de carga e caminhões de transportadores e, como oferta, o oposto é verdadeiro: carros de transportadores e mercadorias de empresas. O equilíbrio é difícil de manter por uma série de razões, por exemplo:
- Comunicação fechada entre a operadora e o cliente. Quando um driver geralmente funciona apenas com um cliente específico, ele não funciona bem na plataforma. Se o embarcador sair do mercado, o serviço também pode perder o transportador, pois ele passa a ser cliente de outra empresa de logística.
- A presença de mercadorias que ninguém quer transportar. Isso acontece quando as pequenas empresas fazem pedidos de transporte, e então não são atualizadas e, por isso, saem rapidamente do número de pedidos ativos.
A empresa queria melhorar a funcionalidade de sua plataforma de bolsa de cargas e aumentar a experiência do usuário dos usuários para que pudessem ver todas as capacidades do sistema e uma ampla gama de mercadorias, e também não perdessem a fidelidade. Isso pode impedir que o público-alvo mude para um serviço competitivo e mostrar às transportadoras de carga que os pedidos adequados podem ser encontrados não apenas nas empresas com as quais estão acostumados.
Atendendo a todos os desejos, deparei-me com a tarefa de desenvolver um sistema de recomendação que, imediatamente à entrada da plataforma, mostre aos transportadores a carga relevante disponível atualmente e adivinhe o que pretendem transportar e para onde. Este sistema deveria ser integrado à plataforma de bolsa de carga existente.
Como iremos “adivinhar”?
Nosso sistema de recomendação, como outros, trabalha na análise de dados do usuário. E existem várias fontes nas quais você pode operar:
- Em primeiro lugar, abra as informações sobre os pedidos de transporte de mercadorias.
- Em segundo lugar, a plataforma fornece dados sobre a operadora. Quando o usuário celebra um contrato com nossos clientes, ele pode indicar quantos caminhões possui e de que tipo. Mas, infelizmente, depois que esses dados não são atualizados. E a única coisa em que podemos confiar é o país da operadora, pois provavelmente não mudará.
- Em terceiro lugar, o sistema armazena o histórico de pesquisas do usuário por vários anos: as solicitações mais recentes e um ano atrás.
Na aplicação em que decidiram implementar o sistema de recomendação, já existia um mecanismo de procura de mercadorias por pedidos anteriores. Portanto, decidimos nos concentrar na identificação de padrões ou padrões pelos quais o usuário procura por mercadorias para transporte. Ou seja, não recomendamos o carregamento, mas selecionamos a direção que é mais adequada para este usuário hoje. E já vamos encontrar os produtos usando o mecanismo de busca padrão.
Em geral, as pesquisas populares são baseadas em informações geográficas e parâmetros adicionais, como o tipo de caminhão ou o item sendo transportado. Isso é fácil de rastrear, porque essas preferências quase não mudam. Abaixo eu forneci os dados de solicitação de um dos usuários por 3 dias. A ordem de enchimento é a seguinte: 1 coluna - país de partida, 2 - país de destino, 3 - região de partida, 4 - região de destino.

Você pode ver que este usuário tem preferências específicas em países e províncias. Mas não é o caso de todos e nem sempre. Muitas vezes, o transportador indica apenas o país de destino ou não indica a região de partida, por exemplo, está na Bélgica e pode vir a qualquer província para recolher a carga. Em geral, existem diferentes tipos de consultas: país para país, país para região, região para país ou região para região (a melhor opção).
Amostras de algoritmo
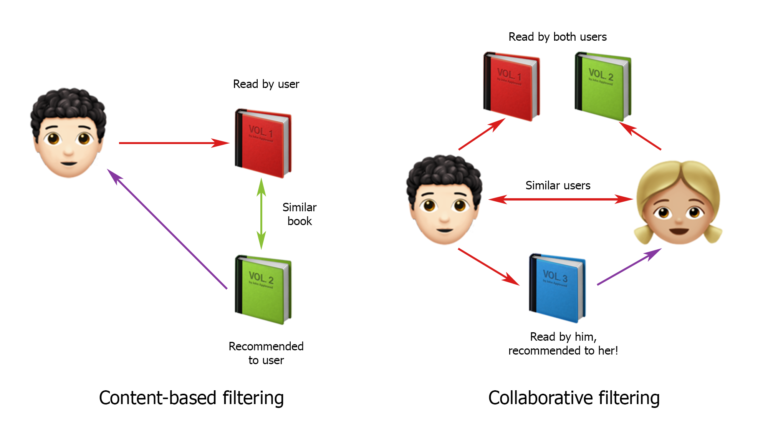
Como você sabe, as estratégias para criar sistemas de recomendação são divididas principalmente em filtragem baseada em conteúdo e filtragem colaborativa. Nessa classificação, comecei a construir soluções.
Tirei a foto de hub.forklog.com
Muitas fontes dizem que a filtragem colaborativa funciona melhor. É simples: estamos tentando encontrar usuários semelhantes aos nossos, com padrões de comportamento semelhantes, e recomendamos aos nossos usuários as mesmas solicitações que eles. Em geral, essa solução foi a primeira opção que apresentei aos clientes. Mas eles discordaram dele e disseram que não funcionaria. Afinal, tudo depende muito de onde o caminhão está agora, para onde levou a carga, para onde mora e para onde é mais conveniente ir. Não sabemos de tudo isso, por isso é tão difícil contar com o comportamento de outros usuários, mesmo que, à primeira vista, sejam semelhantes.
Agora, sobre os sistemas baseados em conteúdo. Funcionam assim: primeiro, é determinado e criado um perfil de usuário e, em seguida, é feita uma seleção de recomendações com base em suas características. Uma boa opção, mas no nosso caso existem algumas nuances. Em primeiro lugar, um usuário pode ocultar todo um grupo de pessoas que estão procurando cargas para muitos caminhões e fazer login a partir de diferentes IPs. Em segundo lugar, a partir dos dados exatos temos apenas o país da transportadora, e a informação sobre a quantidade de caminhões e seus tipos é aproximadamente "mostrada" apenas nas solicitações feitas pelo usuário. Ou seja, para construir um sistema baseado em conteúdo para nosso projeto, você precisa olhar as solicitações de cada usuário e tentar encontrar o mais popular entre eles.
Nosso primeiro sistema de recomendação não usava algoritmos complexos. Tentamos classificar as consultas e encontrar os melhores corações para recomendá-las. Para testar o conceito, nossa equipe trabalhou com usuários reais: enviou recomendações e, em seguida, coletou feedback. Em princípio, as operadoras gostaram do resultado. Em seguida, comparei nossas recomendações com o que as operadoras estavam procurando atualmente e vi que o sistema funcionava muito bem para usuários com padrões de comportamento estáveis. Mas, infelizmente para aqueles que fizeram uma gama mais ampla de solicitações, a precisão das recomendações não era muito alta - o sistema precisava ser melhorado.
Continuei a descobrir com o que estamos lidando aqui. Na verdade, é um modelo de Markov oculto, onde um grupo de pessoas pode estar por trás de cada usuário. Além disso, os usuários podem estar em vários estados ocultos: não há dados sobre onde eles têm um caminhão no momento, quantas pessoas estão em uma conta e quando na próxima vez elas precisarão ir a algum lugar. Naquela época, eu não conhecia as soluções prontas para a produção do modelo oculto de Markov, então decidi encontrar algo mais simples.
Conheça o PageRank
Chamei então a atenção para o algoritmo PageRank, uma vez criado pelos fundadores do Google, Sergey Brin e Larry Page, que ainda é usado por este mecanismo de busca para recomendar sites aos usuários. O PageRank representa todo o espaço da Internet na forma de um gráfico, onde cada página da web é seu nó. Ele pode ser usado para calcular a "importância" (ou classificação) para cada nó. O PageRank é fundamentalmente diferente dos algoritmos de busca que existiam antes dele, pois não se baseia no conteúdo das páginas, mas nos links que estão dentro delas. Ou seja, a classificação de cada página depende do número e da qualidade dos links que apontam para ela. Brin e Page provaram a convergência desse algoritmo, o que significa que sempre podemos calcular a classificação de qualquer nó em um gráfico direcionado e chegar a valores que não mudarão.
Vejamos sua fórmula:
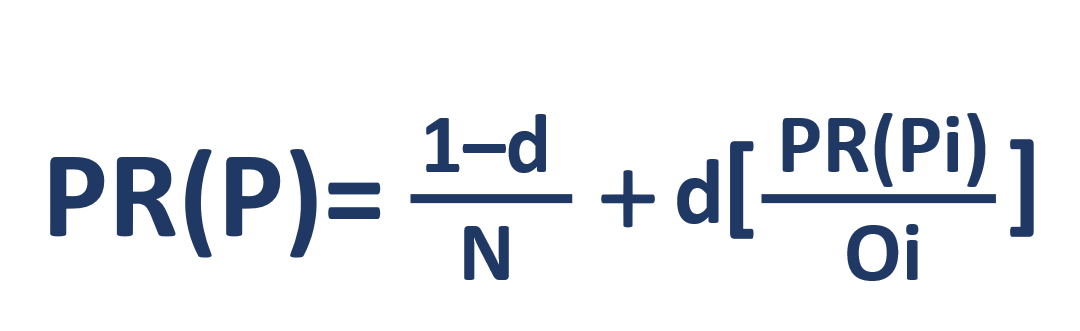
- PR(P) – rank
- N –
- i –
- O –
- d – . -, , - . , . 0 ≤ d ≤ 1 – d 0,85. .
E agora um exemplo simples de cálculo de PageRank para um gráfico simples que consiste em três nós. É importante lembrar que no início todos os nós recebem o mesmo peso igual a 1 / número de nós.
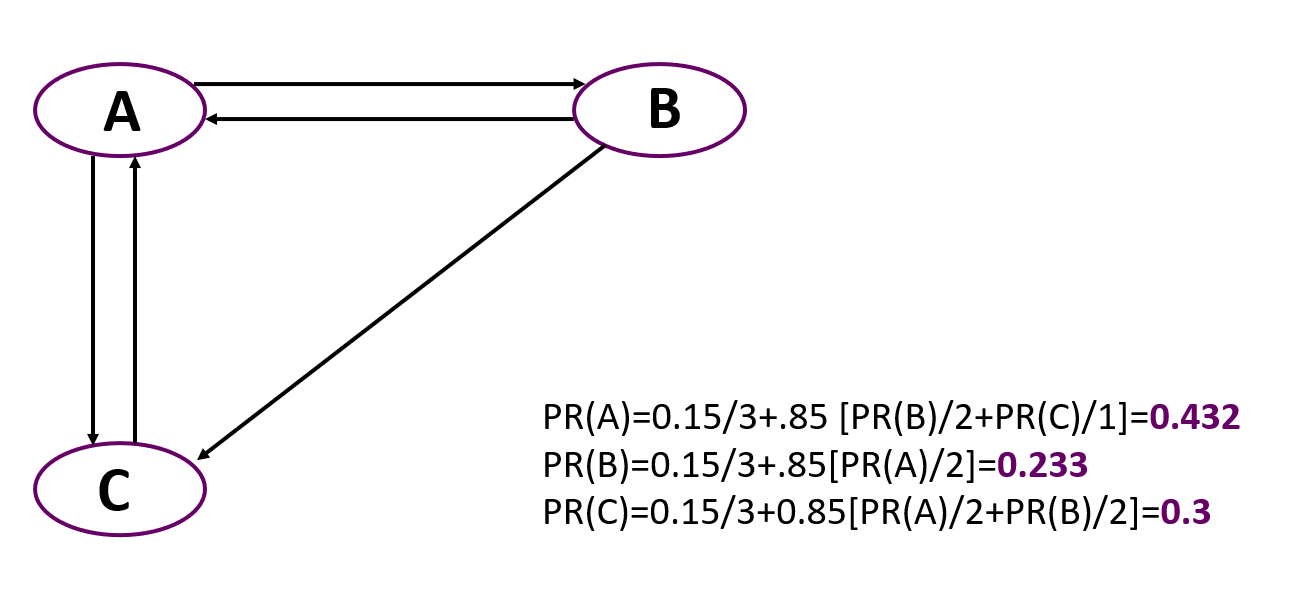
Você pode ver que o mais importante aqui é o nó A, apesar do fato de que apenas dois nós apontam para ele, como para C. Mas a classificação de nós apontando para A é mais alta do que a dos nós que levam a C.
Suposições e solução
Portanto, o PageRank descreve um processo de Markov sem estados ocultos. Usando-o, sempre encontraremos o peso final de cada nó, mas não seremos capazes de rastrear alterações no gráfico. O algoritmo é muito bom, conseguimos adaptá-lo e melhorar a precisão dos resultados. Para fazer isso, fizemos uma modificação do PageRank - o algoritmo Personalized PageRank, que difere do básico porque a transição é sempre realizada para um número limitado de nós. Ou seja, quando o usuário se cansa de “percorrer” os links, ele passa não para um nó aleatório, mas para um de um determinado conjunto.
Em nosso caso, os nós do gráfico serão solicitações do usuário. Como nosso algoritmo deve fornecer recomendações para o dia seguinte, analisei todas as solicitações de cada operadora por dia. Agora construímos um gráfico: o nó A conecta-se ao nó B, se a busca pelo tipo B seguir a busca pelo tipo A, ou seja, a busca pelo tipo A foi realizada pelo usuário antes do dia em que procurava a rota B. Por exemplo: "Paris - Bruxelas" na terça (A), e na quarta-feira “Bruxelas - Colônia” (B). E alguns usuários fazem muitas solicitações por dia, então vários nós são conectados uns aos outros ao mesmo tempo e, como resultado, obtemos gráficos bastante complexos.
Para adicionar informações sobre a importância de se mover de um coração para outro, adicionamos pesos das arestas do gráfico. O peso da aresta A-B é o número de vezes que o usuário pesquisou B depois de pesquisar A. Também é muito importante levar em consideração a idade das consultas, pois o usuário muda seu modelo: ele pode mover ou reorganizar o tipo principal de transporte, após o qual não quer ir com o caminhão vazio. Portanto, você precisa monitorar o histórico de rotas - adicionamos a variável de recorrência, que também afetará o peso do nó.
Vale a pena considerar a sazonalidade: podemos saber que, por exemplo, em setembro a operadora viaja com frequência para a França, e em outubro - para a Alemanha. Conseqüentemente, mais peso pode ser dado aos corações que são "populares" em um determinado mês. Além disso, contamos com informações sobre a última vez que o usuário pesquisou. Isso ajuda a adivinhar indiretamente onde o caminhão pode estar.
Resultado
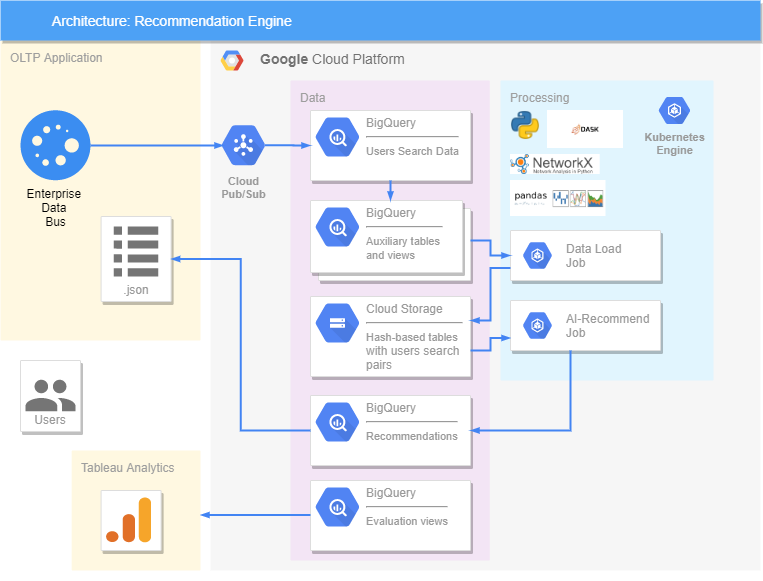
Tudo é implementado na plataforma Google. Temos um aplicativo OLTP, de onde os dados das consultas vêm e vão para o BigQuery, onde são formadas visualizações e tabelas adicionais contendo informações já processadas. A biblioteca DASK foi usada para acelerar e paralelizar o processamento de grandes quantidades de dados. Em nossa solução, todos os dados são transferidos para o Cloud Storage, porque o DASK só funciona com ele e não interage com o BigQuery. Dois jobs foram criados no Kubernetes, um dos quais transfere dados do BigQuery para o Cloud Storage e o segundo faz recomendações. Funciona assim: Job pega dados sobre pares de corações do Cloud Storage, os processa, gera recomendações para o dia seguinte e os envia de volta ao BigQuery. A partir daí, já no formato .json, podemos enviar recomendações para o aplicativo OLTP, onde os usuários as verão.A precisão das recomendações é avaliada no Tableau, onde nossas recomendações são comparadas com o que o usuário realmente procurou, bem como sua reação (gostando ou não).
Claro, eu gostaria de compartilhar os resultados. Por exemplo, aqui está um usuário que faz 14 corações de país-país todos os dias. Também recomendamos a mesma quantidade a ele:
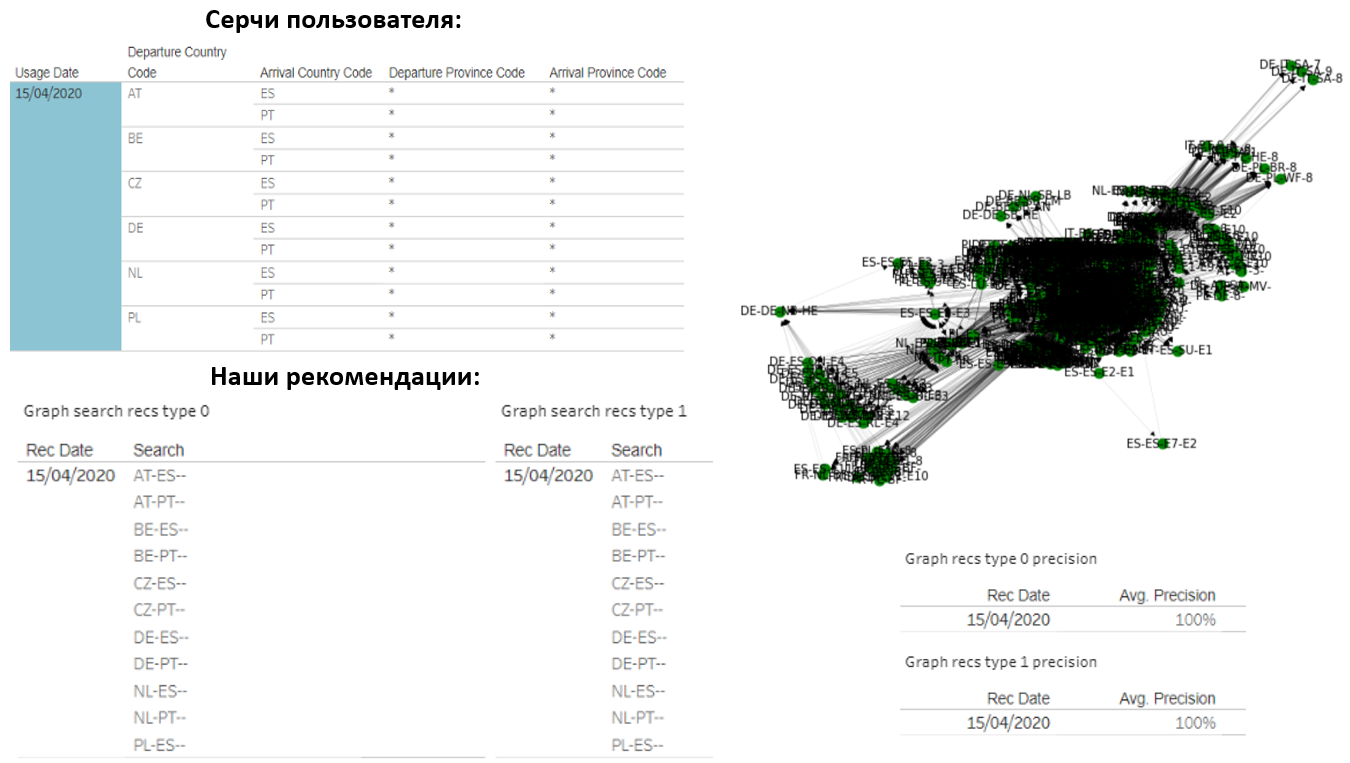
Acontece que nossas opções coincidiam completamente com o que ele estava procurando. O gráfico deste usuário consiste em cerca de 1000 consultas diferentes, mas conseguimos adivinhar com muita precisão o que o interessaria.
O segundo usuário, em média, faz 8 solicitações diferentes a cada 2 dias, e faz buscas tanto no formato "país-país" quanto com indicação de região de saída específica. Além disso, os países de origem e de entrega são completamente diferentes. Portanto, não pudemos "adivinhar" tudo e a precisão dos resultados acabou sendo menor:

Observe que o usuário possui 2 gráficos com pesos diferentes. Em um, a precisão atingiu 38%, o que significa que em algum lugar 3 das 8 opções recomendadas por nós se mostraram relevantes. E, talvez, se encontrarmos cargas nessas direções, o usuário irá escolhê-las.
O último e mais simples exemplo. Uma pessoa faz cerca de 2 pesquisas por dia. Possui padrões muito estáveis, não muitas preferências e um gráfico simples. Como resultado, a precisão de nossas previsões é de 100%.

Desempenho em fatos
- Nossos algoritmos são executados em 4 CPUs padrão e 10 GB de memória.
- Os volumes de dados são de até 1 bilhão de registros.
- Demora 18 minutos para criar recomendações para todos os usuários de cerca de 20.000.
- A biblioteca DASK é usada para paralelização e a biblioteca NetworkX é usada para o algoritmo PageRank.
Posso dizer que nossas pesquisas e experimentos produziram resultados muito bons. A apresentação do comportamento dos usuários da plataforma de bolsa de cargas em forma de gráfico e o uso do PageRank nos permitem prever suas preferências futuras com grande precisão e, assim, construir sistemas de recomendação eficazes.