- Olá! Eu direi quais problemas você deve resolver quando precisar preparar seu serviço para várias centenas de gigabits, ou mesmo terabits por segundo. Encontramos esse problema pela primeira vez em 2018, quando nos preparávamos para as transmissões da Copa do Mundo FIFA.
Vamos começar com o que são protocolos de streaming e como funcionam - a opção de visão geral mais superficial.

Qualquer protocolo de streaming é baseado em um manifesto ou lista de reprodução. É um pequeno arquivo de texto que contém metainformações sobre o conteúdo. Descreve o tipo de conteúdo - transmissão ao vivo ou transmissão VoD (vídeo sob demanda). Por exemplo, no caso de um jogo ao vivo é uma partida de futebol ou uma conferência online, como temos agora com você, e no caso do VoD, seu conteúdo é preparado com antecedência e fica nos seus servidores, pronto para distribuição aos usuários. O mesmo arquivo descreve a duração do conteúdo, informações sobre DRM.

Ele também descreve variações de conteúdo - faixas de vídeo, faixas de áudio, legendas. As trilhas de vídeo podem ser representadas em diferentes codecs. Por exemplo, o H.264 universal é compatível com qualquer dispositivo. Com ele, você pode reproduzir vídeos em qualquer ferro da sua casa. Ou há codecs HEVC e VP9 mais modernos e eficientes que permitem o streaming de imagens HDR 4K.
As trilhas de áudio também podem ser apresentadas em diferentes codecs com diferentes taxas de bits. E pode haver vários deles - a faixa de áudio original do filme em inglês, tradução para o russo, intershum ou, por exemplo, uma gravação de um evento esportivo diretamente do estádio sem comentaristas.

O que o jogador faz com tudo isso? A tarefa do jogador é, em primeiro lugar, escolher as variações de conteúdo que pode reproduzir, simplesmente porque nem todos os codecs são universais, nem todos podem ser reproduzidos em um dispositivo específico.
Depois disso, ele precisa selecionar a qualidade de vídeo e áudio a partir da qual ele começará a tocar. Ele pode fazer isso com base nas condições da rede, se as conhecer, ou com base em alguma heurística muito simples. Por exemplo, comece a jogar com baixa qualidade e, se a rede permitir, aumente lentamente a resolução.
Também nesta fase, ele escolhe a faixa de áudio a partir da qual começará a tocar. Suponha que você tenha inglês em seu sistema operacional. Em seguida, ele pode selecionar a faixa de áudio em inglês padrão. Talvez seja mais conveniente para você.
Depois disso, ele começa a gerar links para segmentos de vídeo e áudio. Na verdade, esses são links HTTP regulares, iguais a todos os outros cenários da Internet. E ele começa a baixar segmentos de vídeo e áudio, colocando-os no buffer um após o outro e reproduzindo perfeitamente. Esses segmentos de vídeo geralmente têm 2, 4, 6 segundos de duração, talvez 10 segundos, dependendo do seu serviço.

Quais são os pontos importantes sobre os quais precisamos pensar quando projetamos nosso CDN? Em primeiro lugar, temos uma sessão de usuário.
Não podemos simplesmente fornecer um arquivo a um usuário e esquecer esse usuário. Ele constantemente volta e baixa segmentos novos e novos em seu buffer.
É importante entender aqui que o tempo de resposta do servidor também é importante. Se estivermos exibindo algum tipo de transmissão ao vivo em tempo real, não podemos criar um buffer grande simplesmente porque o usuário deseja assistir ao vídeo o mais próximo possível do tempo real. Em princípio, seu buffer não pode ser grande. Da mesma forma, se o servidor não tiver tempo para responder enquanto o usuário tem tempo para visualizar o conteúdo, o vídeo simplesmente congelará em algum ponto. Além disso, o conteúdo é muito pesado. A taxa de bits padrão para Full HD 1080p é de 3-5 Mbps. Da mesma forma, em um servidor gigabit, você não pode atender a mais de 200 usuários ao mesmo tempo. E essa é uma imagem ideal, porque, via de regra, os usuários não seguem suas solicitações de maneira uniforme ao longo do tempo.

Em que ponto um usuário realmente interage com seu CDN? A interação ocorre principalmente em dois lugares: quando o player baixa o manifesto (lista de reprodução) e quando ele baixa segmentos.
Já falamos sobre manifestos, são pequenos arquivos de texto. Não há problemas específicos com a distribuição de tais arquivos. Se desejar, distribua-os de pelo menos um servidor. E se forem segmentos, eles constituem a maior parte do seu tráfego. Vamos falar sobre eles.
A tarefa de todo o nosso sistema se resume ao fato de que queremos formar o link correto para esses segmentos e substituir o domínio correto de algum de nosso host CDN ali. Neste ponto, usamos a seguinte estratégia: imediatamente na lista de reprodução, damos o host CDN desejado, para onde o usuário irá. Essa abordagem não tem muitas desvantagens, mas tem uma nuance importante. Você precisa garantir que tenha um mecanismo para levar o usuário de um host para outro perfeitamente durante a reprodução, sem interromper a visualização. Na verdade, todos os protocolos de streaming modernos têm essa capacidade, tanto HLS quanto DASH suportam. Nuance: muitas vezes, mesmo em bibliotecas de código aberto muito populares, essa possibilidade não é implementada, embora exista pelo padrão. Nós mesmos tivemos que enviar pacotes para a biblioteca de código aberto Shaka,é javascript, usado para web player, para jogar DASH.
Existe mais um esquema - esquema anycast, quando você usa um único domínio e o fornece em todos os links. Nesse caso, você não precisa pensar em nenhuma nuance - você doa um domínio e todos ficam felizes. (...)
Agora vamos falar sobre como vamos formar nossos links.
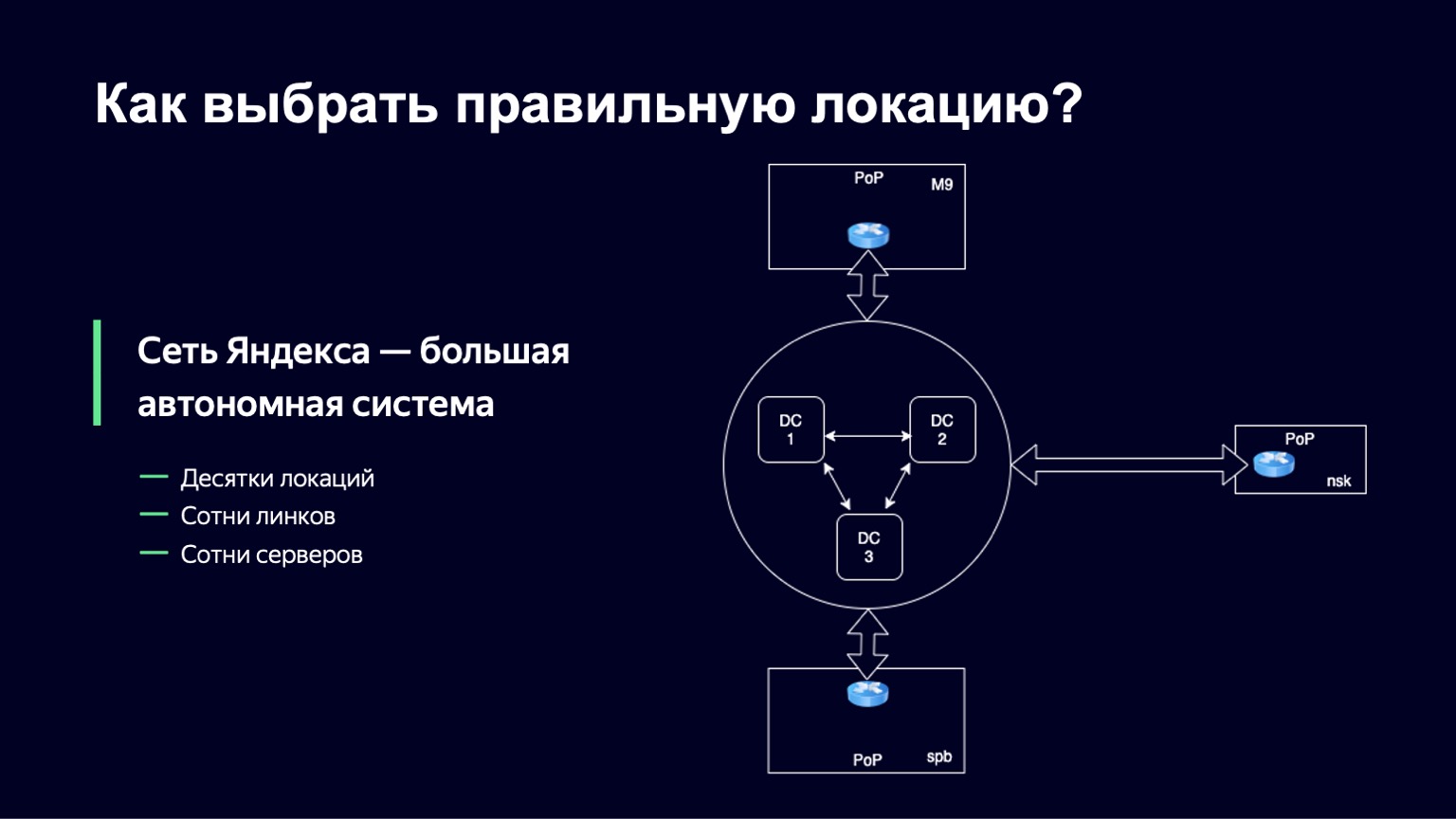
Do ponto de vista da rede, qualquer grande empresa é organizada como um sistema autônomo, e muitas vezes nem mesmo um. Na verdade, um sistema autônomo é um sistema de redes IP e roteadores que são controlados por uma única operadora e fornecem uma única política de roteamento com a rede externa, com a Internet. Yandex não é exceção. A rede Yandex também é um sistema autônomo e a comunicação com outros sistemas autônomos ocorre fora dos data centers Yandex em pontos de presença. Cabos físicos da Yandex, cabos físicos de outras operadoras chegam a esses pontos de presença e são trocados no local, em equipamentos de ferro. É nesses pontos que temos a oportunidade de colocar vários de nossos servidores, discos rígidos, SSDs. É para onde direcionaremos o tráfego do usuário.
Chamaremos esse conjunto de servidores de local. E em cada um desses locais, temos um identificador único. Vamos usá-lo como parte do nome de domínio de hosts neste site e apenas para identificá-lo de forma única.
Existem várias dezenas desses sites no Yandex, várias centenas de servidores neles e links de várias operadoras para cada local, portanto, também temos cerca de várias centenas de links.
Como escolheremos para qual local enviar um determinado usuário?

Não há muitas opções nesta fase. Só podemos usar o endereço IP para tomar decisões. Uma equipe de tráfego separada da Yandex nos ajuda nisso, que sabe tudo sobre o funcionamento do tráfego e da rede na empresa, e é ela quem coleta as rotas de outras operadoras para que possamos usar esse conhecimento no processo de balanceamento de usuários.
Ele coleta um conjunto de rotas usando BGP. Não falaremos sobre o BGP em detalhes, é um protocolo que permite aos participantes da rede nas fronteiras de seus sistemas autônomos anunciar quais rotas seu sistema autônomo pode servir. A Traffic Team coleta todas essas informações, agrega, analisa e constrói um mapa completo de toda a rede, que utilizamos para o balanceamento.
Recebemos da Traffic Team um conjunto de redes IP e links através dos quais podemos atender clientes. Em seguida, precisamos entender qual sub-rede IP é adequada para um determinado usuário.
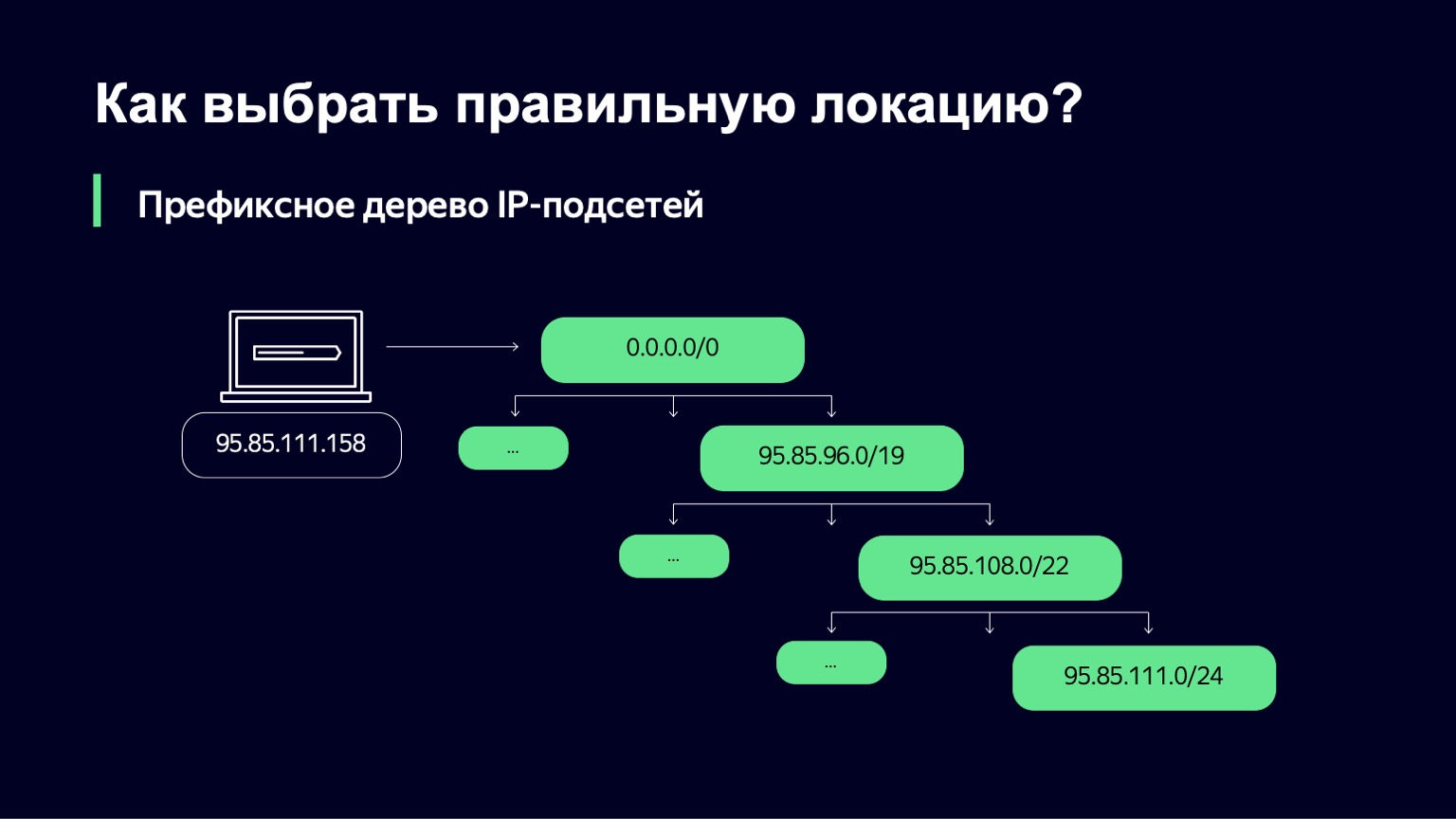
Fazemos isso de uma maneira bastante simples - construímos uma árvore de prefixos. E, em seguida, nossa tarefa é usar o endereço IP do usuário como uma chave para descobrir qual sub-rede mais se aproxima desse endereço IP.
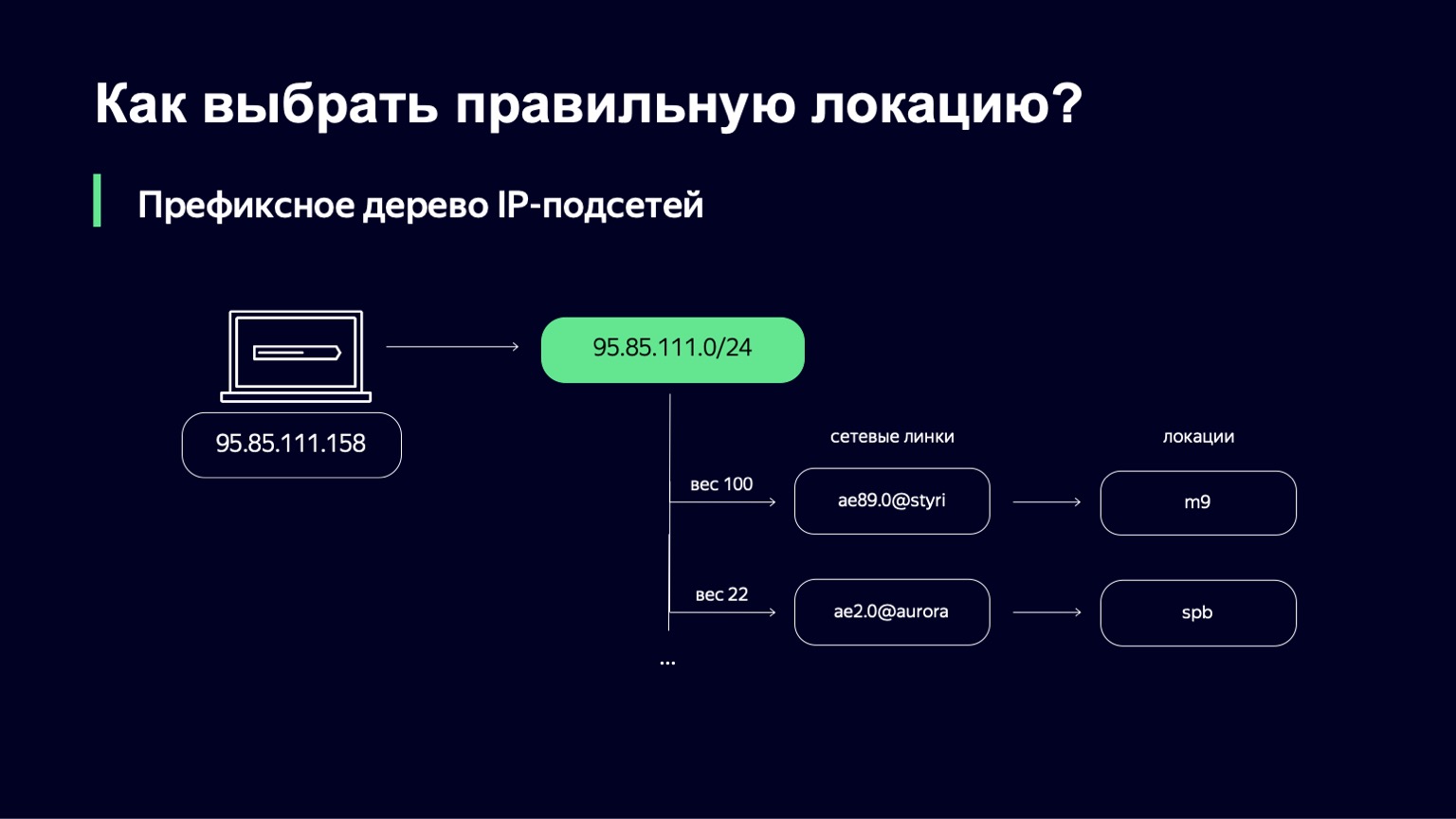
Quando o encontramos, temos uma lista de links, seus pesos, e por links podemos determinar de maneira única o local para onde enviaremos o usuário.

Qual é o peso neste lugar? Esta é uma métrica que permite gerenciar a distribuição de usuários em diferentes locais. Podemos ter links, por exemplo, de diferentes capacidades. Podemos ter um link de 100 gigabit e um link de 10 gigabit no mesmo site. Obviamente, queremos enviar mais usuários ao primeiro link, porque é mais amplo. Esse peso leva em consideração a topologia da rede, pois a Internet é um gráfico complexo de equipamentos de rede interconectados, seu tráfego pode percorrer caminhos diferentes, e essa topologia também deve ser levada em consideração.
Certifique-se de observar como os usuários realmente baixam os dados. Isso pode ser feito no lado do servidor e do cliente. No servidor, estamos coletando ativamente as conexões do usuário nos logs de informações do TCP, observando o tempo de ida e volta. Do lado do usuário, coletamos ativamente os logs de desempenho do navegador e do jogador. Esses logs de desempenho contêm informações detalhadas sobre como os arquivos foram baixados de nosso CDN.
Se analisarmos tudo isso de forma agregada, então com a ajuda desses dados podemos melhorar os pesos que foram escolhidos na primeira etapa pela Equipe de Tráfego.

Digamos que selecionamos um link. Podemos enviar usuários para lá neste estágio? Não podemos, porque o peso é bastante estático por um longo período de tempo e não leva em consideração nenhuma dinâmica real da carga. Queremos determinar em tempo real se agora podemos usar um link que está, digamos, 80% carregado, quando há um link de prioridade ligeiramente mais baixa próximo que está apenas 10% carregado. Muito provavelmente, neste caso, queremos apenas usar o segundo.

O que mais precisa ser levado em consideração neste lugar? Devemos levar em consideração a largura de banda do link, entender seu estado atual. Pode funcionar ou estar com defeito técnico. Ou, talvez a gente queira levar para o serviço para não deixar os usuários lá e servir, expandir, por exemplo. Devemos sempre levar em consideração a carga atual deste link.
Existem algumas nuances interessantes aqui. Você pode coletar informações sobre o carregamento do link em vários pontos - por exemplo, em equipamentos de rede. Esta é a forma mais precisa, mas o problema é que no equipamento de rede você não consegue um período de atualização rápida para este download. Por exemplo, em Yandex, o equipamento de rede é bastante diversificado e não podemos coletar esses dados mais do que uma vez por minuto. Se o sistema for razoavelmente estável em termos de carga, isso não é um problema. Tudo vai funcionar muito bem. Mas assim que você tem influxos repentinos de carga, você simplesmente não tem tempo para reagir, e isso leva, por exemplo, a embalar quedas.
Por outro lado, você sabe quantos bytes foram enviados ao usuário. Você pode coletar essas informações nas próprias máquinas distribuidoras, fazer um contador de bytes diretamente. Mas não será tão preciso. Por quê?
Existem outros usuários em nosso CDN. Não somos o único serviço a utilizar estas máquinas dispensadoras. E no contexto de nossa carga, a carga de outros serviços não é tão significativa. Mas, mesmo em nosso contexto, pode ser bastante perceptível. A distribuição deles não passa pelo nosso circuito, portanto não podemos controlar esse tráfego.
Outro ponto: mesmo que você pense na máquina emissora que você enviou tráfego para um link específico, isso está longe de ser verdade, porque o BGP como protocolo não lhe dá essa garantia. E há maneiras de aumentar a probabilidade de você adivinhar, mas isso é assunto para outra discussão.

Digamos que calculamos as métricas, coletamos tudo. Agora precisamos de um algoritmo para tomar uma decisão durante o balanceamento. Deve ter quatro propriedades importantes:
- Fornece a largura de banda do link.
- Evite a sobrecarga do link, simplesmente porque se você carregou um link a 95% ou 98%, os buffers no equipamento de rede começam a estourar, pacotes descartados, retransmissões começam e os usuários não obtêm nada de bom com isso.
- Para avisar que “bebeu” cargas, falaremos sobre isso um pouco mais tarde.
“Em um mundo ideal, seria ótimo se pudéssemos aprender a reciclar um link para um determinado nível que consideramos correto. Por exemplo, 85% de download.

Tomamos a seguinte ideia como base. Temos duas classes diferentes de sessões de usuário. A primeira aula é de novas sessões, quando o usuário acaba de abrir o filme, ainda não assistiu nada e estamos tentando descobrir para onde enviar. Ou a segunda classe, quando temos uma sessão atual, o usuário já está atendido no link, ocupa uma certa parte da banda, é atendido em um servidor específico.
O que vamos fazer com eles? Apresentamos um valor probabilístico para cada uma dessas classes da sessão. Teremos um valor denominado Lentidão, que determina a porcentagem de novas sessões que não permitiremos neste link. Se Slowdown for zero, então aceitamos todas as novas sessões, e se for 50%, então, grosso modo, a cada segunda sessão nos recusamos a servir neste link. Ao mesmo tempo, nosso algoritmo de balanceamento em um nível superior verificará alternativas para este usuário. Drop é o mesmo, apenas para sessões atuais. Podemos tirar algumas das sessões de usuário do site em outro lugar.
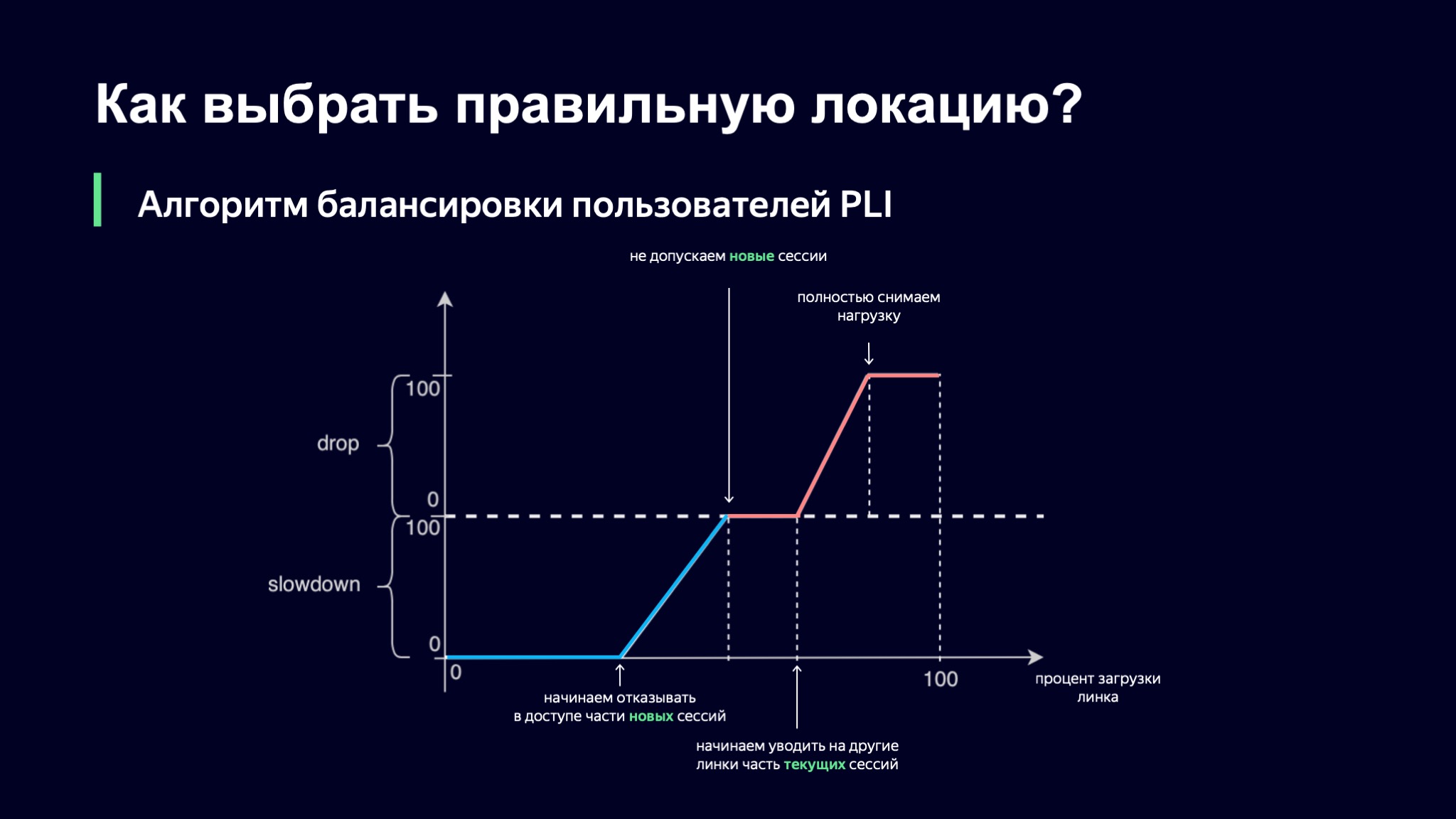
Como escolhemos qual será o valor de nossas métricas probabilísticas? Tomaremos a porcentagem de carregamento do link como base e, em seguida, nossa primeira ideia foi esta: vamos usar a interpolação linear por partes.
Pegamos essa função, que tem vários pontos de refração, e observamos o valor de nossos coeficientes usando-a. Se o nível de download do link for mínimo, está tudo bem, lentidão e queda são iguais a zero, permitimos a entrada de todos os novos usuários. Assim que o nível de carga ultrapassa um determinado limite, começamos a negar serviço a alguns usuários neste link. Em algum ponto, se a carga continuar crescendo, simplesmente paramos de lançar novas sessões.
Há uma nuance interessante aqui: as sessões atuais têm prioridade neste esquema. Acho que está claro por que isso está acontecendo: se o seu usuário já fornece um padrão de carga estável, você não quer levá-lo a lugar nenhum, porque assim você aumenta a dinâmica do sistema, e quanto mais estável for o sistema, mais fácil será para nós controlá-lo.
No entanto, o download pode continuar crescendo. Em algum momento, podemos começar a tirar algumas das sessões ou até mesmo remover completamente a carga deste link.
É dessa forma que lançamos esse algoritmo nas primeiras partidas da Copa do Mundo FIFA. Provavelmente é interessante ver a imagem que vimos. Ela era sobre o seguinte.
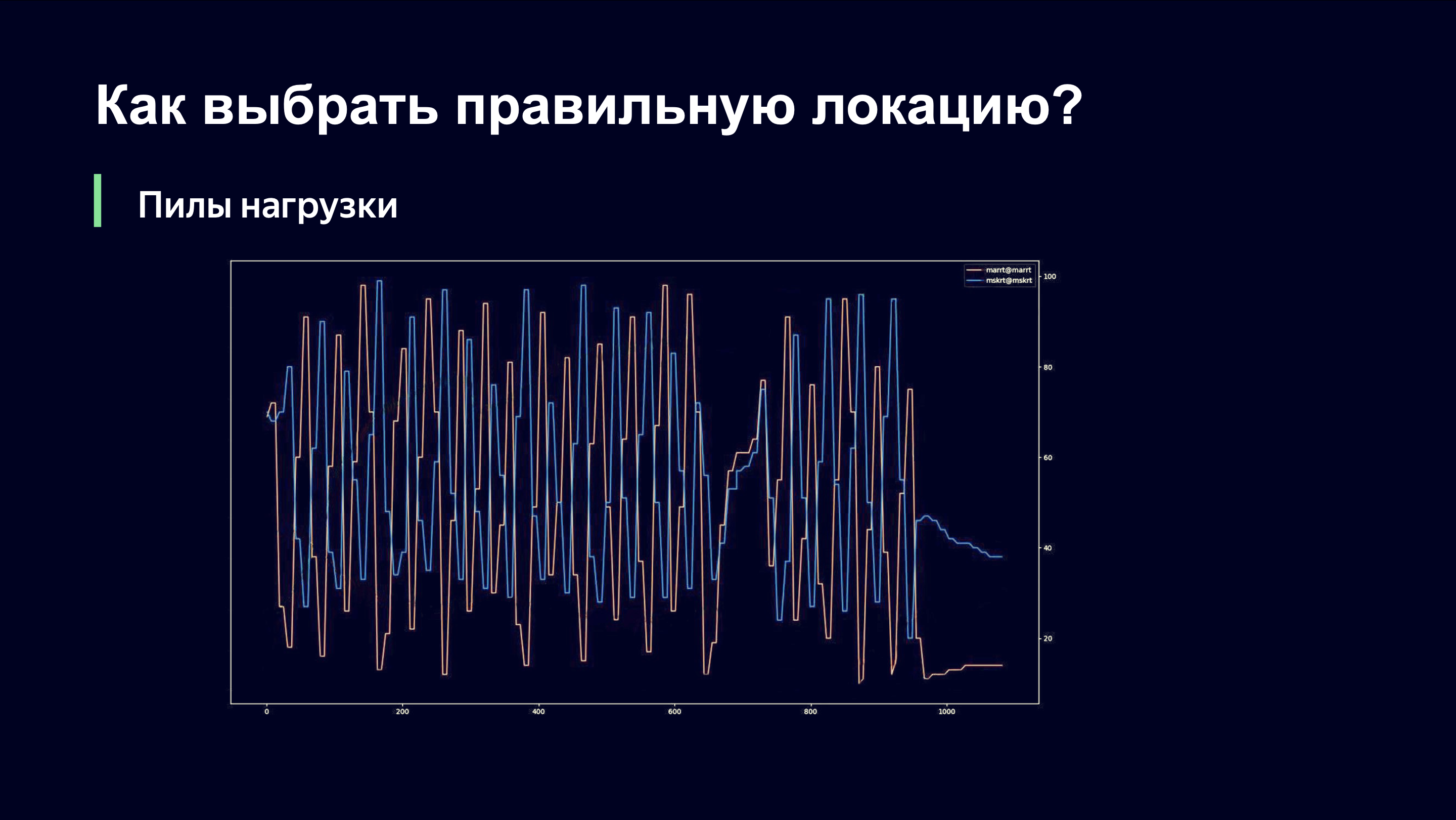
Mesmo a olho nu, um observador externo pode entender que provavelmente algo está errado aqui e me perguntar: "Andrey, você está indo bem?" E se você fosse meu chefe, você correria pela sala e gritaria: “Andrey, meu Deus! Role tudo de volta! Devolva tudo como estava! " Vamos contar o que está acontecendo aqui.
No eixo X, tempo, no eixo Y, observamos o nível de carga do link. Existem dois links que atendem ao mesmo site. É importante entender que neste momento usamos apenas o esquema de monitoramento de carga do link que é removido do equipamento da rede e, portanto, não conseguimos responder rapidamente à dinâmica de carga.
Quando enviamos usuários para um dos links, há um aumento acentuado no tráfego nesse link. O link está sobrecarregado. Descarregamos e nos encontramos do lado direito da função que vimos no gráfico anterior. E começamos a eliminar usuários antigos e paramos de permitir a entrada de novos. Eles precisam ir a algum lugar e, é claro, vão para o próximo link. Da última vez, pode ter sido uma prioridade mais baixa, mas agora eles têm prioridade.
O segundo link repete a mesma imagem. Aumentamos drasticamente a carga, notamos que o link está sobrecarregado, removemos a carga, e esses dois links estão em antifase em termos de nível de carga.
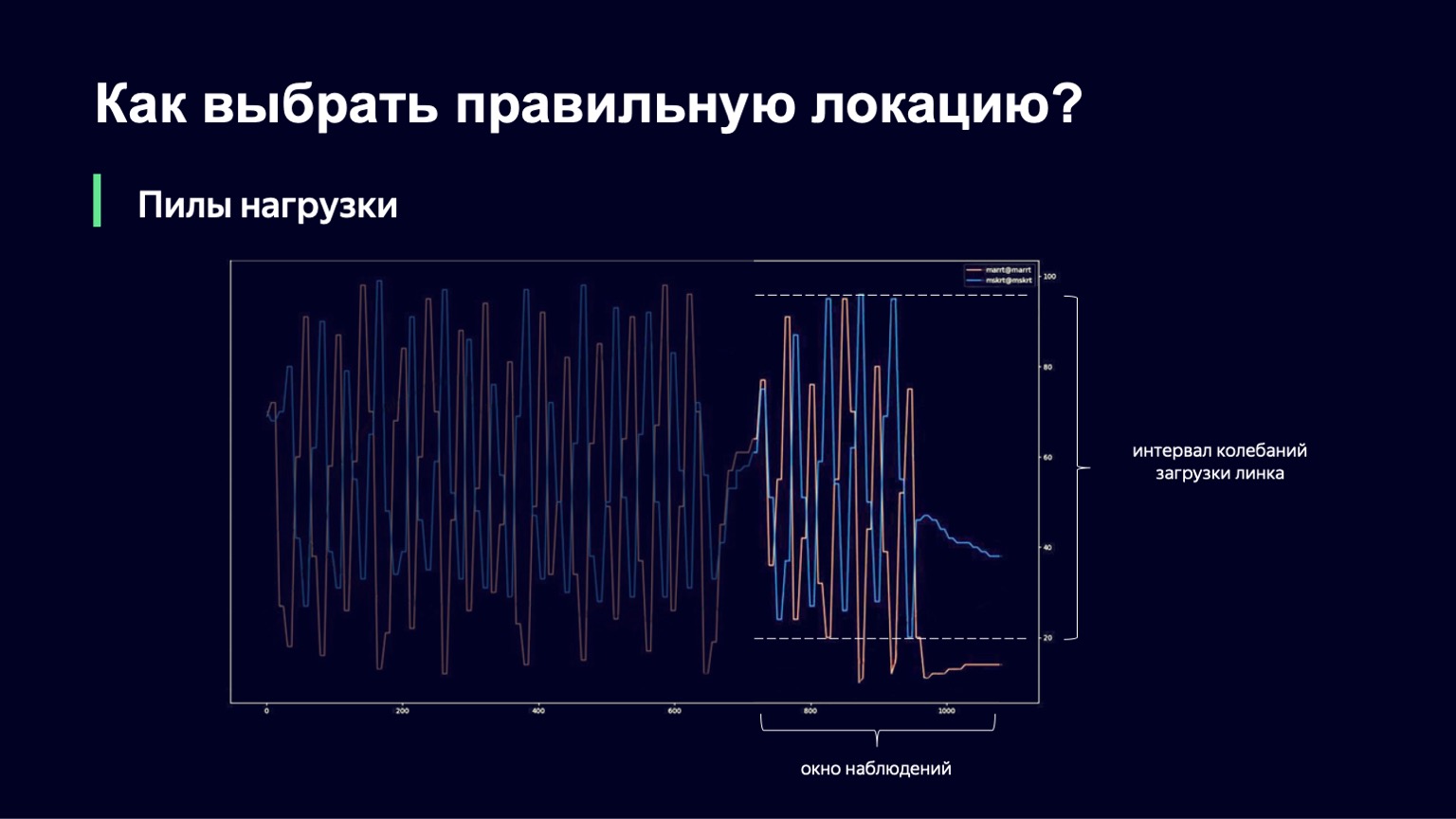
O que pode ser feito? Podemos analisar a dinâmica do sistema, perceber isso com um grande aumento da carga e umedecê-la um pouco. Isso é exatamente o que fizemos. Pegamos o momento atual, pegamos a janela de observação no passado por alguns minutos, por exemplo, 2-3 minutos, e vimos o quanto a carga do link muda nesse intervalo. A diferença entre os valores mínimo e máximo será chamada de intervalo de oscilação deste link. E se este intervalo de oscilação for grande, adicionaremos amortecimento, aumentando assim nossa desaceleração e começando a executar menos sessões.
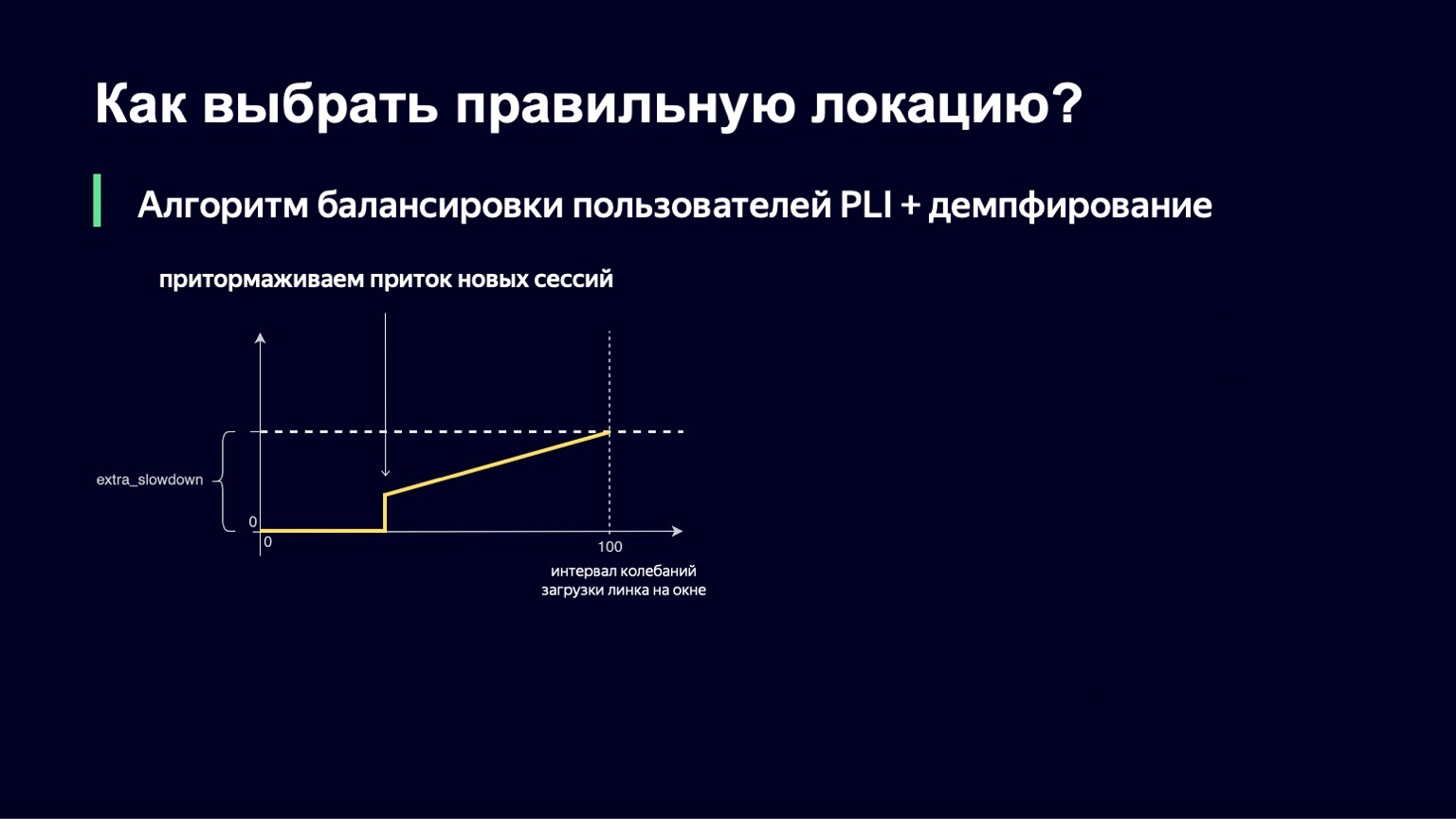
Esta função é quase igual à anterior, com um pouco menos de fraturas. Se tivermos um pequeno intervalo para baixar as oscilações, não adicionaremos nenhum extra_slowdown. E se o intervalo de oscilação começa a crescer, então extra_slowdown assume valores diferentes de zero, mais tarde iremos adicioná-lo ao Slowdown principal.
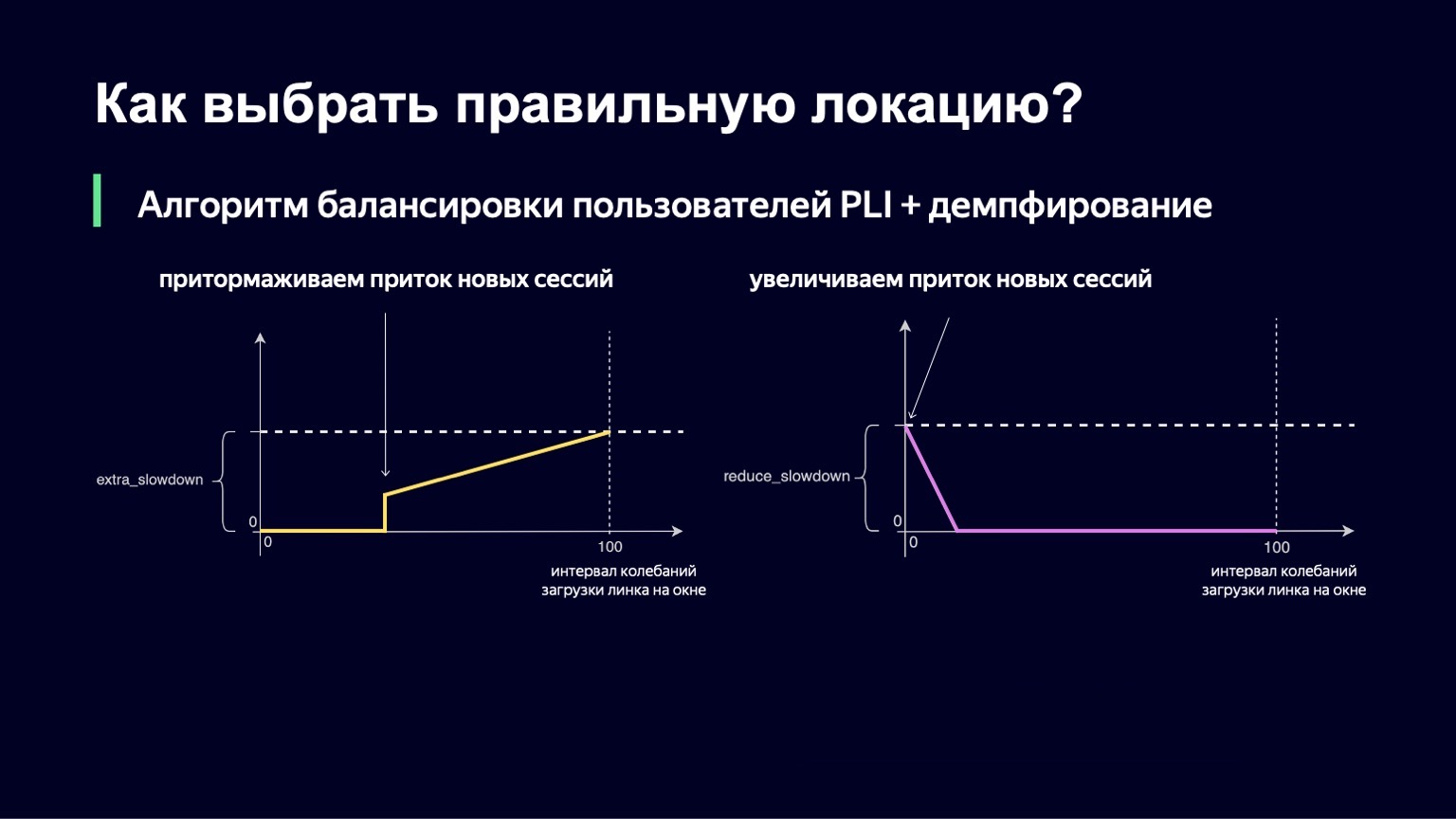
A mesma lógica funciona com valores baixos do intervalo de oscilação. Se você tiver flutuações mínimas no link, então, ao contrário, você deseja permitir a entrada de um pouco mais de usuários lá, reduzir a lentidão e, assim, utilizar melhor seu link.
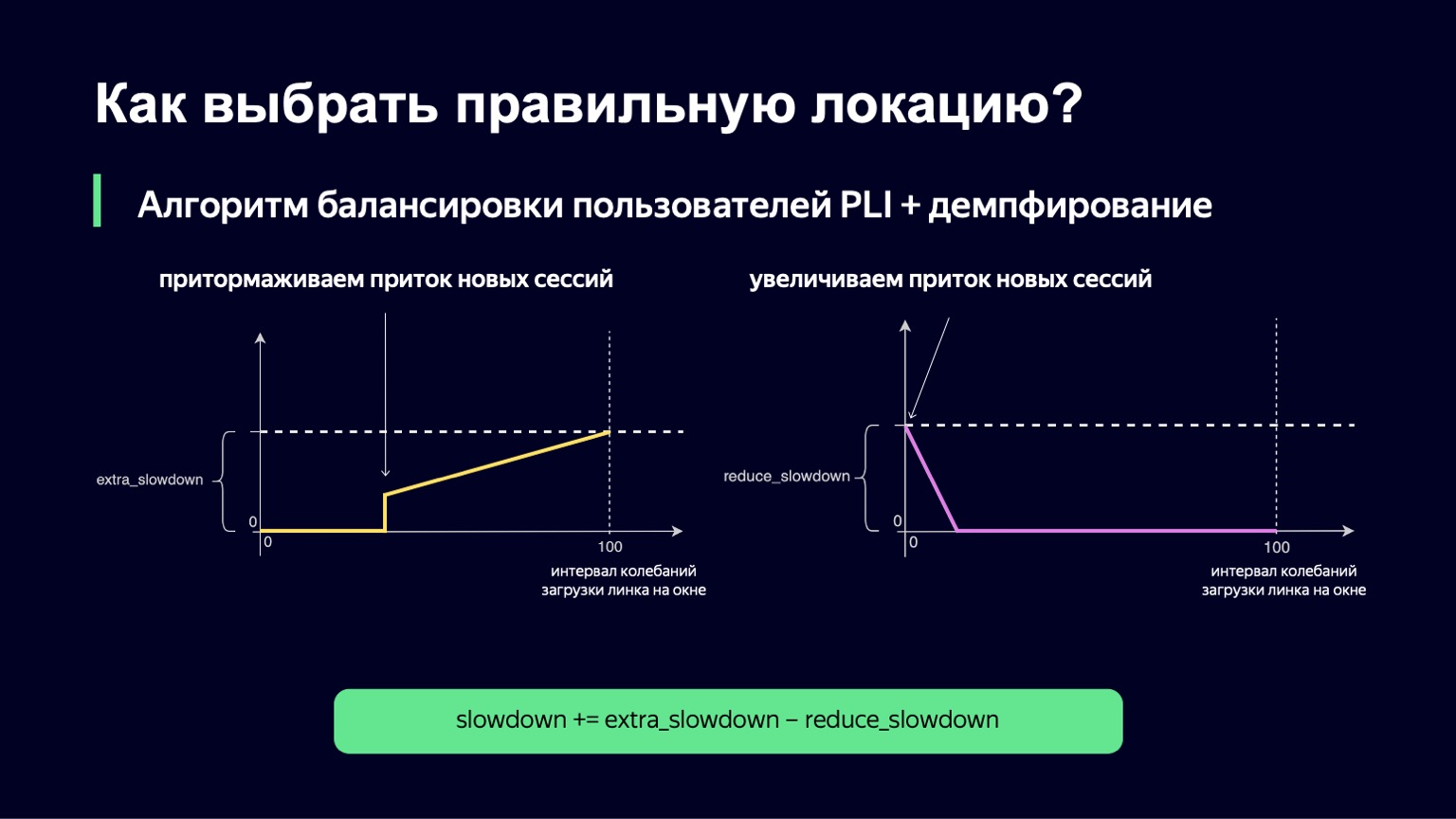
Também implementamos essa parte. A fórmula final é semelhante a esta. Ao mesmo tempo, garantimos que ambos os valores - extra_slowdown e reduce_slowdown - nunca tenham um valor diferente de zero ao mesmo tempo, portanto, apenas um deles funciona de forma eficaz. É dessa forma que essa fórmula de equilíbrio sobreviveu a todas as principais partidas da Copa do Mundo da FIFA. Mesmo nas partidas mais populares, ela trabalhou muito bem: estes são "Rússia - Croácia", "Rússia - Espanha". Durante essas partidas, distribuímos um recorde para os volumes de tráfego Yandex - 1,5 terabits por segundo. Nós passamos por isso com calma. Desde então, a fórmula não mudou em nada, porque não houve esse tráfego em nosso serviço desde então - até um determinado momento.
Então, uma pandemia nos atingiu. As pessoas foram enviadas para ficarem sentadas em casa, e em casa há boa internet, TV, tablet e muito tempo livre. O tráfego para nossos serviços começou a crescer organicamente, de forma bastante rápida e significativa. Agora esse tipo de carga, como foi durante a Copa, é o nosso dia a dia. Desde então, expandimos um pouco nossos canais com operadoras, mas mesmo assim começamos a pensar sobre a próxima iteração de nosso algoritmo, o que deve ser e como podemos utilizar melhor nossa rede.

Quais são as desvantagens de nosso algoritmo anterior? Não resolvemos dois problemas. Não nos livramos completamente das cargas de "serra". Melhoramos muito a imagem e a amplitude dessas oscilações é mínima, o período aumentou muito, o que também permite um melhor aproveitamento da rede. Mas mesmo assim eles aparecem de vez em quando, permanecem. Não aprendemos como utilizar a rede no nível que gostaríamos. Por exemplo, não podemos usar a configuração para definir o nível de carga de link máximo desejado de 80-85%.

Que pensamentos temos para a próxima iteração do algoritmo? Como podemos imaginar a utilização ideal da rede? Uma das áreas promissoras, ao que parece, é a opção quando você tem um único lugar para tomar decisões sobre o tráfego. Você coleta todas as métricas em um só lugar, uma solicitação do usuário para baixar segmentos chega lá, e a cada momento você tem um estado completo do sistema, é muito fácil para você tomar decisões.
Mas existem duas nuances aqui. Em primeiro lugar, não é costume em Yandex escrever “pontos de tomada de decisão comuns”, simplesmente porque com nossos níveis de carga, com nosso tráfego, tal lugar rapidamente se torna um gargalo.
Há mais uma nuance - em Yandex, também é importante escrever sistemas tolerantes a falhas. Freqüentemente, fechamos completamente os data centers, enquanto seu componente deve continuar a funcionar sem erros, sem interrupções. E desta forma, este único local torna-se, de fato, um sistema distribuído que você precisa controlar, e essa é uma tarefa um pouco mais difícil do que a que gostaríamos de resolver neste local.

Definitivamente, precisamos de métricas rápidas. Sem eles, a única coisa que você pode fazer para evitar o sofrimento do usuário é subutilizar a rede. Mas isso também não nos convém.
Se você olhar nosso sistema em alto nível, ficará claro que ele é um sistema dinâmico com feedback. Temos uma carga personalizada, que é um sinal de entrada. Pessoas vêm e vão. Temos um sinal de controle - os dois valores que podemos alterar em tempo real. Para tais sistemas dinâmicos com feedback, a teoria do controle automático foi desenvolvida por um longo tempo, várias décadas. E são seus componentes que gostaríamos de usar para estabilizar nosso sistema.
Vimos o filtro de Kalman. Isso é tão legal que permite construir um modelo matemático do sistema e, com métricas barulhentas ou na ausência de algumas classes de métricas, melhorar o modelo usando seu sistema real. E então tome uma decisão sobre um sistema real baseado em um modelo matemático. Infelizmente, descobrimos que não temos muitas classes de métricas que possamos usar e esse algoritmo não pode ser aplicado.
Abordamos por outro lado, tomamos como base outro componente dessa teoria - o controlador PID. Ele não sabe nada sobre o seu sistema. Sua função é saber o estado ideal do sistema, ou seja, nosso nível de carga desejado e o estado atual do sistema, por exemplo, o nível de carga. Ele considera a diferença entre esses dois estados um erro e, usando seus algoritmos internos, controla o sinal de controle, ou seja, nossos valores de Slowdown e Drop. Seu objetivo é minimizar o erro no sistema.
Tentaremos este controlador PID em produção no dia a dia. Talvez em alguns meses possamos informá-lo sobre os resultados.
Nisto provavelmente terminaremos sobre a rede. Gostaria muito de falar sobre como distribuímos o tráfego dentro do próprio local, quando já o escolhemos entre os hosts. Mas não há tempo para isso. Este é provavelmente um tópico para um grande relatório separado.

Portanto, na próxima série, você aprenderá como descartar o cache de maneira ideal nos hosts, o que fazer com o tráfego quente e frio, bem como de onde vem o tráfego quente, como o tipo de conteúdo afeta o algoritmo para sua distribuição e qual vídeo dá o maior acerto de cache no serviço, e quem quem canta uma música.
Eu tenho outra história interessante. Na primavera, como você sabe, a quarentena começou. Yandex há muito tem uma plataforma educacional chamada Yandex.Tutorial, que permite aos professores fazer upload de vídeos e aulas. Os alunos vão lá e assistem ao conteúdo. Durante a pandemia, Yandex começou a apoiar escolas, convidando-as ativamente para sua plataforma para que os alunos pudessem estudar remotamente. E em algum ponto vimos um crescimento muito bom no tráfego, um quadro bastante estável. Mas em uma das noites de abril, vimos algo como o seguinte nas paradas.
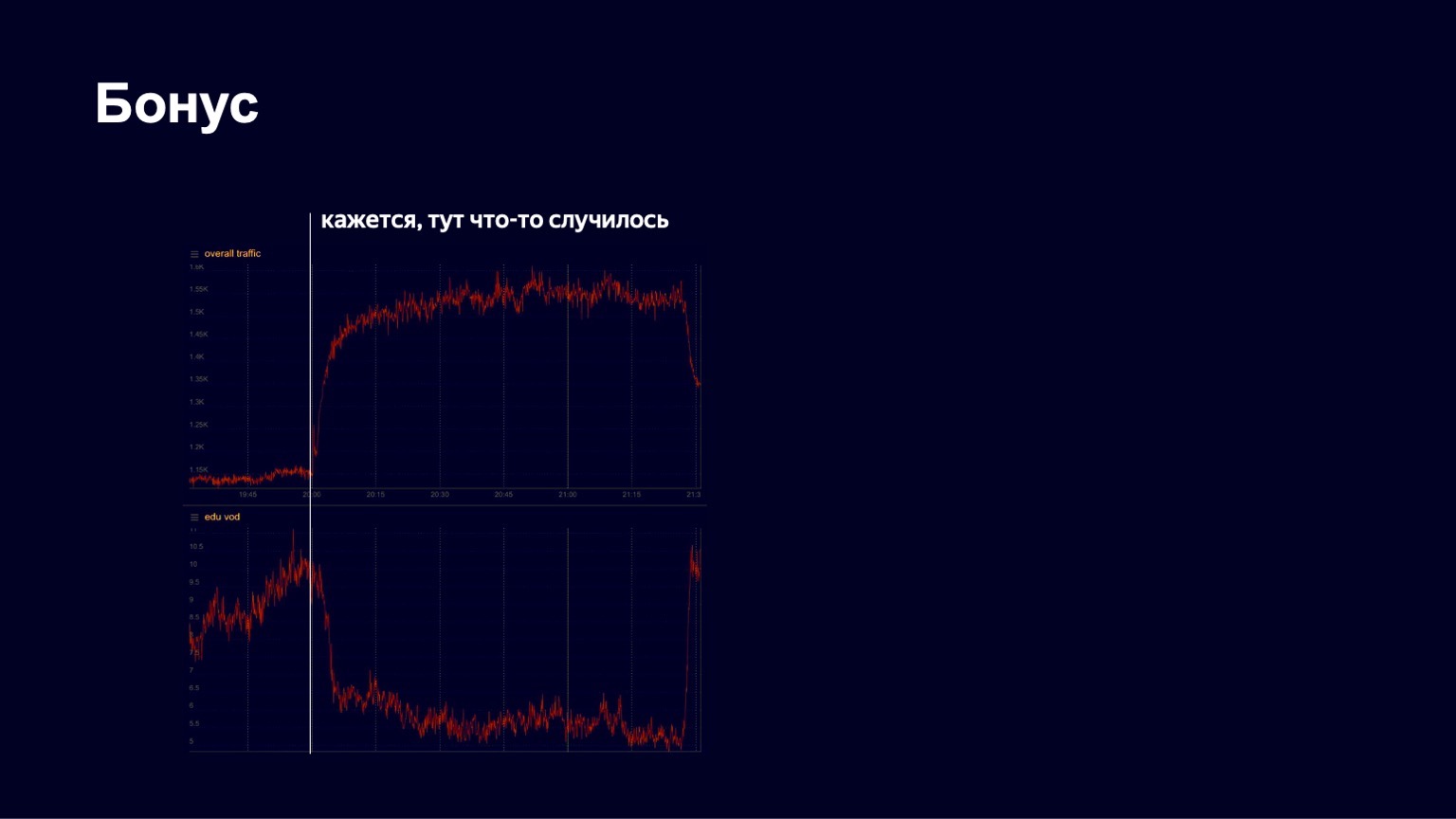
Abaixo está uma foto do tráfego em conteúdo educacional. Vimos que ele caiu bruscamente em algum ponto. Começamos a entrar em pânico, para saber o que estava acontecendo em geral, o que estava quebrado. Então percebemos que o tráfego total para o serviço começou a crescer. Obviamente, algo interessante aconteceu.
Na verdade, naquele momento aconteceu o seguinte.
É assim que o homem dança rápido.
O concerto Little Big começou, e todos os alunos saíram para assistir. Mas após o final do show, eles voltaram e com sucesso continuaram a estudar. Vemos essas fotos com bastante frequência em nosso serviço. Portanto, acho que nosso trabalho é bastante interessante. Obrigado a todos! Provavelmente terminarei com isso sobre CDN.