
Meu nome é Ilya Gulyaev, sou um engenheiro de automação de teste na equipe de verificação pós-implantação da DINS.
Em DINS, usamos Jenkins em muitos processos: desde a construção de builds até a execução de implantações e autotestes. Em minha equipe, usamos Jenkins como uma plataforma para lançar verificações de fumaça uniformemente após implantar cada um de nossos serviços, desde ambientes de desenvolvimento à produção.
Um ano atrás, outras equipes decidiram usar nossos pipelines não apenas para verificar um serviço após atualizá-lo, mas também para verificar o estado de todo o ambiente antes de executar grandes lotes de teste. A carga em nossa plataforma aumentou dez vezes, e Jenkins parou de lidar com a tarefa em mãos e apenas começou a cair. Rapidamente percebemos que adicionar recursos e ajustar o coletor de lixo poderia apenas atrasar o problema, mas não resolvê-lo completamente. Portanto, decidimos encontrar gargalos do Jenkins e otimizá-los.
Neste artigo, explicarei como o Jenkins Pipeline funciona e compartilharei minhas descobertas que podem ajudá-lo a tornar seus pipelines mais rápidos. O material será útil para engenheiros que já trabalharam com Jenkins e desejam conhecer melhor a ferramenta.
O que é um Jenkins Pipeline Beast
Jenkins Pipeline é uma ferramenta poderosa que permite automatizar vários processos. Jenkins Pipeline é um conjunto de plug-ins que permite descrever ações na forma de uma DSL Groovy e é o sucessor do plug-in Build Flow.
O script para o plug-in Build Flow foi executado diretamente no mestre em um thread Java separado que executou o código Groovy sem barreiras impedindo o acesso à API interna do Jenkins. Essa abordagem representava um risco de segurança, que mais tarde se tornou um dos motivos para abandonar o Build Flow e serviu como um pré-requisito para a criação de uma ferramenta segura e escalonável para a execução de scripts - Jenkins Pipeline.
Você pode aprender mais sobre a história da criação do Jenkins Pipeline no artigo do autor Build Flow ouPalestra de Oleg Nenashev sobre Groovy DSL em Jenkins .
Como funciona o Jenkins Pipeline
Agora vamos descobrir como os pipelines funcionam por dentro. Eles costumam dizer que Jenkins Pipeline é um tipo de trabalho completamente diferente no Jenkins, ao contrário dos bons e velhos trabalhos de freestyle que podem ser clicados na interface da web. Do ponto de vista do usuário, pode ser assim, mas do lado do Jenkins, os pipelines são um conjunto de plug-ins que permitem transferir a descrição das ações para o código.
Similaridades de empregos em pipeline e estilo livre
- A descrição do trabalho (não as etapas) é armazenada no arquivo config.xml
- Os parâmetros são armazenados em config.xml
- Os gatilhos também são armazenados em config.xml
- E até mesmo algumas opções são armazenadas em config.xml
Então. Pare. A documentação oficial diz que parâmetros, gatilhos e opções podem ser configurados diretamente no Pipeline. Onde está a verdade?
A verdade é que os parâmetros descritos no Pipeline serão adicionados automaticamente à seção de configuração na interface da web quando o trabalho for iniciado. Você pode confiar em mim porque escrevi essa funcionalidade na última edição , mas mais sobre isso na segunda parte do artigo.
Diferenças entre Pipeline e Freestyle Jobs
- No momento do início do trabalho, Jenkins não sabe nada sobre o agente para executar o trabalho.
- As ações são descritas em um script bacana.
Lançamento do pipeline declarativo do Jenkins
O processo de inicialização do Jenkins Pipeline consiste nas seguintes etapas:
- Carregar a descrição do trabalho do arquivo config.xml
- Inicie um thread separado (executor leve) para concluir a tarefa
- Carregando o script do pipeline
- Construindo e verificando uma árvore de sintaxe
- Atualizações de configuração de trabalho
- Combinando parâmetros e propriedades especificados na descrição do trabalho e no script
- Salvar descrições de trabalho no sistema de arquivos
- Executar um script em uma caixa de areia descolada
- Solicitação do agente para um trabalho inteiro ou uma única etapa
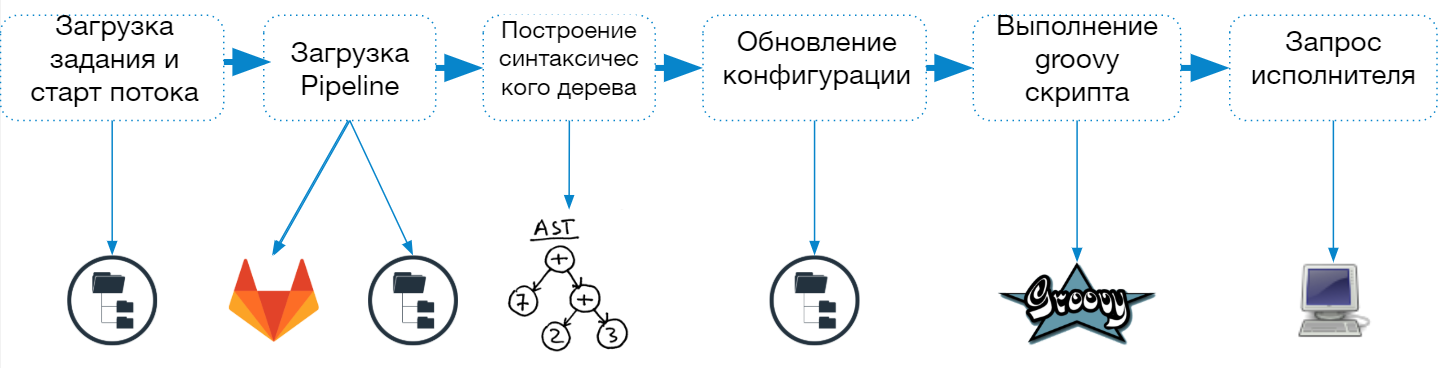
Quando um trabalho de pipeline começa, Jenkins cria um thread separado e envia o trabalho para a fila para execução e, após carregar o script, determina qual agente é necessário para concluir a tarefa.
Para oferecer suporte a essa abordagem, um pool de threads especial do Jenkins (executores leves) é usado. Você pode ver que eles são executados no master, mas não afetam o pool usual de executores: O
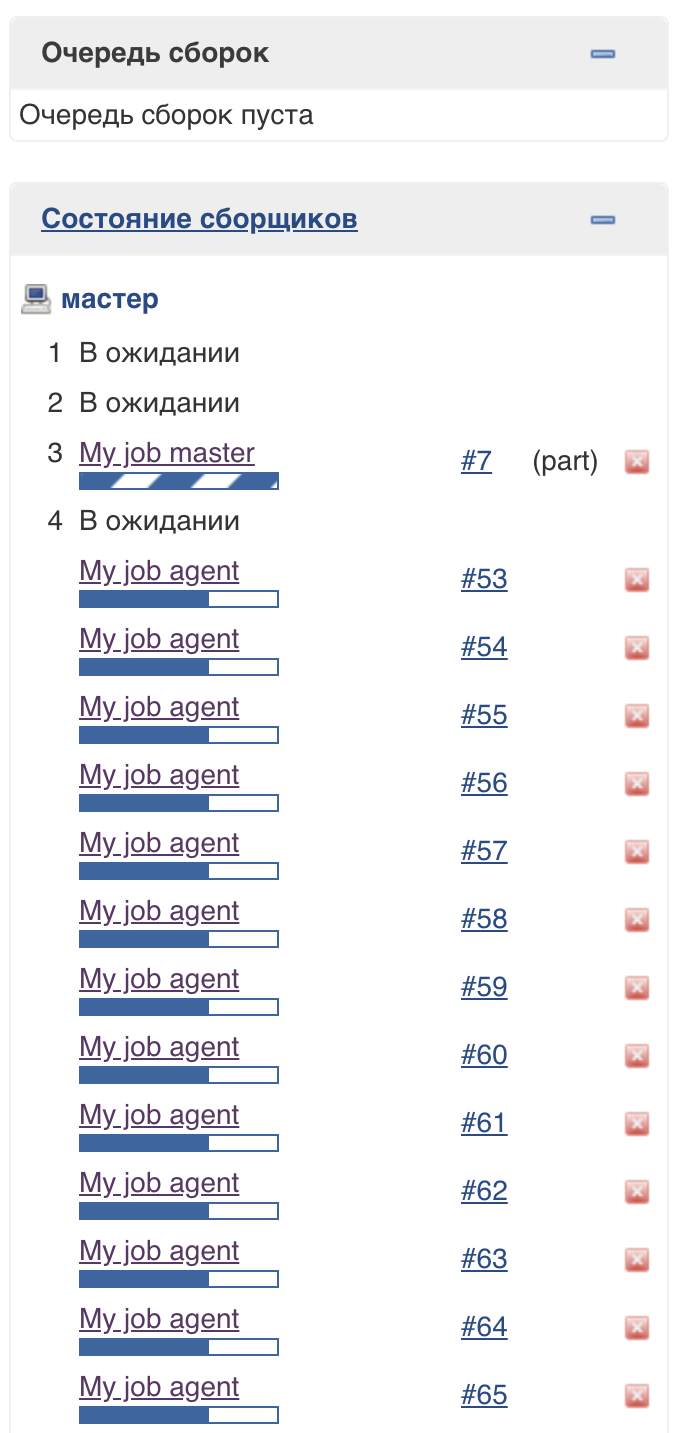
número de threads neste pool não era limitado (no momento da redação deste artigo).
Parâmetros de trabalho no pipeline. Bem como gatilhos e algumas opções
O processamento de parâmetros pode ser descrito pela fórmula:

A partir dos parâmetros do trabalho que vemos na inicialização, os parâmetros do Pipeline da inicialização anterior são removidos primeiro e, somente então, os parâmetros especificados no Pipeline da inicialização atual são adicionados. Isso permite que os parâmetros sejam removidos do trabalho, caso tenham sido removidos do Pipeline.
Como isso funciona de dentro para fora?
Vamos considerar um exemplo de config.xml (o arquivo que armazena a configuração do trabalho):
<?xml version='1.1' encoding='UTF-8'?>
<flow-definition plugin="workflow-job@2.35">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobAction plugin="pipeline-model-definition@1.5.0"/>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="pipeline-model-definition@1.5.0">
<jobProperties>
<string>jenkins.model.BuildDiscarderProperty</string>
</jobProperties>
<triggers/>
<parameters>
<string>parameter_3</string>
</parameters>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties>
<hudson.model.ParametersDefinitionProperty>
<parameterDefinitions>
<hudson.model.StringParameterDefinition>
<name>parameter_1</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_2</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_3</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
</parameterDefinitions>
</hudson.model.ParametersDefinitionProperty>
<jenkins.model.BuildDiscarderProperty>
<strategy class="org.jenkinsci.plugins.BuildRotator.BuildRotator" plugin="buildrotator@1.2">
<daysToKeep>30</daysToKeep>
<numToKeep>10000</numToKeep>
<artifactsDaysToKeep>-1</artifactsDaysToKeep>
<artifactsNumToKeep>-1</artifactsNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
<com.sonyericsson.rebuild.RebuildSettings plugin="rebuild@1.28">
<autoRebuild>false</autoRebuild>
<rebuildDisabled>false</rebuildDisabled>
</com.sonyericsson.rebuild.RebuildSettings>
</properties>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="workflow-cps@2.80">
<scm class="hudson.plugins.filesystem_scm.FSSCM" plugin="filesystem_scm@2.1">
<path>/path/to/jenkinsfile/</path>
<clearWorkspace>true</clearWorkspace>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>
A seção de propriedades contém parâmetros, gatilhos e opções com os quais o trabalho será iniciado. Uma seção adicional, DeclarativeJobPropertyTrackerAction, é usada para armazenar parâmetros definidos apenas no pipeline.
Quando um parâmetro é removido do pipeline, ele será removido de DeclarativeJobPropertyTrackerAction e das propriedades , pois Jenkins saberá que o parâmetro foi definido apenas no pipeline.
Ao adicionar um parâmetro, a situação é invertida, o parâmetro será adicionado DeclarativeJobPropertyTrackerAction e propriedades , mas apenas no momento da execução do pipeline.
É por isso que, se você definir os parâmetros apenas no pipeline, elesestará indisponível no primeiro lançamento .
Execução do Jenkins Pipeline
Depois que o script do Pipeline foi baixado e compilado, o processo de execução começa. Mas esse processo não envolve apenas fazer groovy. Eu destaquei as principais operações pesadas que são realizadas no momento da execução do job:
Execução do código Groovy
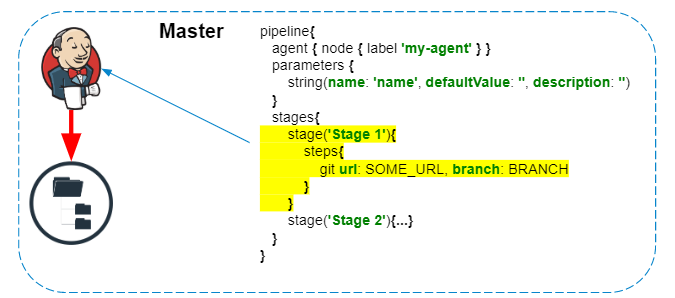
O script do pipeline é sempre executado no mestre - não devemos nos esquecer disso, para não criar carga desnecessária no Jenkins. Apenas as etapas que interagem com o sistema de arquivos do agente ou chamadas do sistema são executadas no agente.
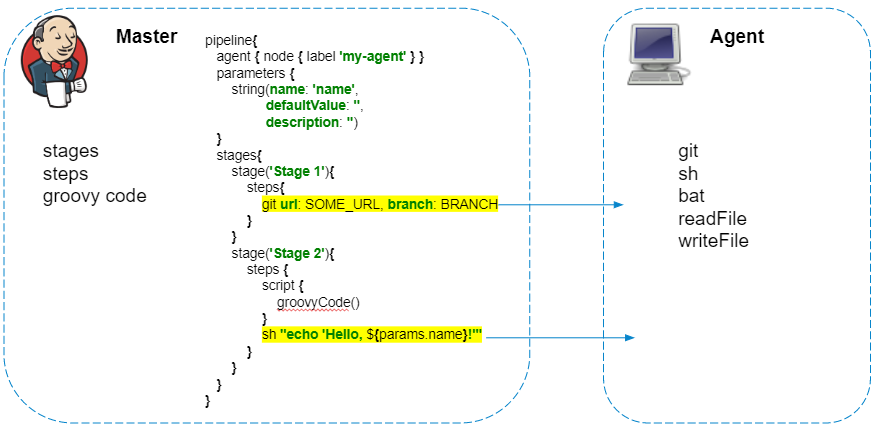
Os pipelines possuem um ótimo plugin que permite fazer solicitações HTTP . Além disso, a resposta pode ser salva em um arquivo.
httpRequest url: 'http://localhost:8080/jenkins/api/json?pretty=true', outputFile: 'result.json'
Inicialmente, pode parecer que esse código deve ser executado completamente no agente, enviar uma solicitação do agente e salvar a resposta no arquivo result.json. Mas tudo acontece ao contrário, e a solicitação é executada pelo próprio Jenkins, e para salvar o conteúdo do arquivo é copiado para o agente. Se o processamento adicional da resposta no pipeline não for necessário, aconselho você a substituir essas solicitações por curl:
sh 'curl "http://localhost:8080/jenkins/api/json?pretty=true" -o "result.json"'
Trabalhando com logs e artefatos
Independentemente do agente no qual os comandos são executados, os logs e artefatos são processados e salvos no sistema de arquivos mestre em tempo real.
Se o pipeline usa credenciais, antes de salvar os registros são filtrados adicionalmente no mestre .
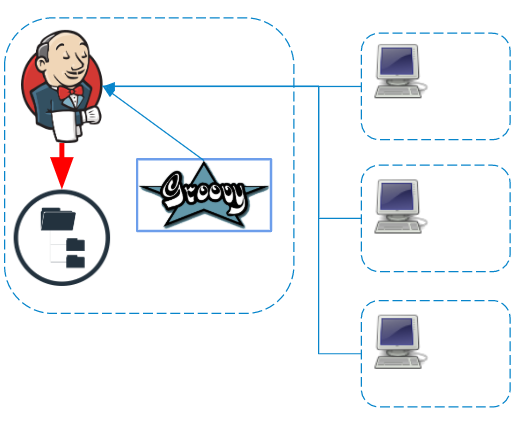
Salvando etapas (durabilidade do pipeline) O
Jenkins Pipeline se posiciona como uma tarefa que consiste em partes separadas que são independentes e podem ser reproduzidas quando o mestre falha. Mas você tem que pagar por isso com gravações adicionais no disco, porque dependendo das configurações da tarefa, etapas com vários graus de detalhes são serializadas e salvas no disco.
Dependendo da durabilidade do pipeline, as etapas no gráfico do pipeline serão armazenadas em um ou mais arquivos para cada execução de trabalho. Trecho da documentação :
O plug-in de suporte de fluxo de trabalho para etapas de armazenamento (FlowNode) usa a classe FlowNodeStorage e suas implementações SimpleXStreamFlowNodeStorage e BulkFlowNodeStorage.
- FlowNodeStorage usa cache na memória para agregar gravações em disco. O buffer é gravado automaticamente em tempo de execução. Geralmente, você não precisa se preocupar com isso, mas tenha em mente que salvar um FlowNode não garante que ele será gravado no disco imediatamente.
- SimpleXStreamFlowNodeStorage usa um pequeno arquivo XML para cada FlowNode - embora usemos um cache na memória de referência suave para nós, isso resulta em um desempenho muito pior ao atravessar pela primeira vez os FlowNodes.
- BulkFlowNodeStorage usa um arquivo XML maior com todos os FlowNodes nele. Essa classe é usada no modo de atividade PERFORMANCE_OPTIMIZED, que grava com muito menos frequência. Isso geralmente é muito mais eficiente porque uma grande gravação de streaming é mais rápida do que um monte de pequenos registros e minimiza a carga no sistema operacional para gerenciar todos os arquivos minúsculos.
Original
Storage: in the workflow-support plugin, see the 'FlowNodeStorage' class and the SimpleXStreamFlowNodeStorage and BulkFlowNodeStorage implementations.
- FlowNodeStorage uses in-memory caching to consolidate disk writes. Automatic flushing is implemented at execution time. Generally, you won't need to worry about this, but be aware that saving a FlowNode does not guarantee it is immediately persisted to disk.
- The SimpleXStreamFlowNodeStorage uses a single small XML file for every FlowNode — although we use a soft-reference in-memory cache for the nodes, this generates much worse performance the first time we iterate through the FlowNodes (or when)
- The BulkFlowNodeStorage uses a single larger XML file with all the FlowNodes in it. This is used in the PERFORMANCE_OPTIMIZED durability mode, which writes much less often. It is generally much more efficient because a single large streaming write is faster than a bunch of small writes, and it minimizes the system load of managing all the tiny files.
As etapas salvas podem ser encontradas no diretório:
$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_ID/workflow/
Arquivo de exemplo:
<?xml version='1.1' encoding='UTF-8'?>
<Tag plugin="workflow-support@3.5">
<node class="cps.n.StepStartNode" plugin="workflow-cps@2.82">
<parentIds>
<string>4</string>
</parentIds>
<id>5</id>
<descriptorId>org.jenkinsci.plugins.workflow.support.steps.StageStep</descriptorId>
</node>
<actions>
<s.a.LogStorageAction/>
<cps.a.ArgumentsActionImpl plugin="workflow-cps@2.82">
<arguments>
<entry>
<string>name</string>
<string>Declarative: Checkout SCM</string>
</entry>
</arguments>
<isUnmodifiedBySanitization>true</isUnmodifiedBySanitization>
</cps.a.ArgumentsActionImpl>
<wf.a.TimingAction plugin="workflow-api@2.40">
<startTime>1600855071994</startTime>
</wf.a.TimingAction>
</actions>
</Tag>
Resultado
Espero que este material tenha sido interessante e ajudado a entender melhor o que são pipelines e como funcionam internamente. Se você ainda tiver dúvidas - compartilhe-as abaixo, será um prazer responder!
Na segunda parte do artigo, considerarei casos separados que o ajudarão a encontrar problemas com o Pipeline de Jenkins e a acelerar suas tarefas. Aprenderemos como resolver problemas de inicialização simultânea, examinar as opções de sobrevivência e discutir por que o Jenkins deve ser perfilado.