Todo mundo tem seus livros favoritos sobre magia. Alguém tem Tolkien, alguém tem Pratchett, alguém, como eu, tem Max Fry. Hoje vou falar sobre minha magia de TI favorita - sobre o BPF e a infraestrutura moderna ao seu redor.
BPF está em seu pico agora. A tecnologia está se desenvolvendo aos trancos e barrancos, penetrando nos lugares mais inesperados e se tornando cada vez mais acessível para o usuário médio. Em quase todas as conferências populares hoje, você pode ouvir um relatório sobre este tópico, e GopherCon Rússia não é exceção: apresento a vocês uma versão em texto do meu relatório .
Não haverá descobertas exclusivas neste artigo. Vou apenas tentar mostrar o que é o BPF, o que ele pode fazer e como pode ajudá-lo pessoalmente. Também daremos uma olhada nos recursos relacionados ao Go.
Depois de ler meu artigo, eu realmente gostaria que seus olhos se iluminassem da mesma forma que os olhos de uma criança que lê o livro Harry Potter pela primeira vez, para que você volte para casa ou para o trabalho e experimente um novo “brinquedo” em ação.
O que é eBPF?
Então, que tipo de mágica um homem barbudo de 34 anos com olhos ardentes vai falar para você?
Vivemos com você em 2020. Se você abrir o Twitter, vai ler os tweets de cavalheiros mal-humorados que afirmam que o software agora está sendo escrito com uma qualidade tão terrível que é mais fácil jogar tudo fora e começar de novo. Alguns chegam a ameaçar sair da profissão, porque não agüentam mais: tudo está quebrando constantemente, incômodo, lento.
Talvez tenham razão: sem mil comentários não saberemos. Mas com o que eu definitivamente concordo é que a pilha de software moderna está mais complexa do que nunca.
BIOS, EFI, sistema operacional, drivers, módulos, bibliotecas, redes, bancos de dados, caches, orquestradores como K8s, containers como Docker, enfim, nosso software com runtimes e coletores de lixo. Um verdadeiro profissional pode responder à pergunta sobre o que acontece depois que você digita ya.ru em seu navegador por vários dias.
É muito difícil entender o que está acontecendo em seu sistema, especialmente se algo está errado no momento e você está perdendo dinheiro. Esse problema levou ao surgimento de linhas de negócios projetadas para ajudá-lo a entender o que está acontecendo dentro do seu sistema. As grandes empresas têm departamentos inteiros de Sherlock que sabem onde martelar e que porca apertar para economizar milhões de dólares.
Em entrevistas, frequentemente pergunto às pessoas como elas irão depurar problemas se forem acordadas às quatro da manhã.
Uma abordagem é analisar os logs . Mas o problema é que apenas aqueles que o desenvolvedor colocou em seu sistema estão disponíveis. Eles não são flexíveis.
A segunda abordagem popular é estudar métricas . Os três sistemas mais populares para trabalhar com métricas são escritos em Go. As métricas são muito úteis, mas nem sempre ajudam a compreender as causas, permitindo que você veja os sintomas.
A terceira abordagem que está ganhando popularidade é a chamada observabilidade: a capacidade de fazer perguntas arbitrariamente complexas sobre o comportamento do sistema e obter respostas para elas. Como a pergunta pode ser muito complexa, a resposta pode exigir uma ampla variedade de informações e, até que a pergunta seja feita, não sabemos o quê. Isso significa que a flexibilidade é vital para a observabilidade.
Permitir a alteração do nível de registro em tempo real? Conectar-se com um depurador a um programa em execução e fazer algo lá sem interromper seu trabalho? Entenda quais solicitações estão chegando ao sistema, visualize as fontes de solicitações lentas, veja em qual memória é gasta por meio do pprof e obtenha um gráfico de sua mudança ao longo do tempo? Medir a latência de uma função e a dependência da latência dos argumentos? Todas essas abordagens me referirei à observabilidade. Este é um conjunto de utilidades, abordagens, conhecimentos, experiências, que juntos lhe darão a oportunidade de fazer, senão tudo, muito "lucro", mesmo no sistema de trabalho. Canivete suíço moderno de TI.

Mas como isso pode ser feito? Havia e existem muitos instrumentos no mercado: simples, complexos, perigosos, lentos. Mas o tópico do artigo de hoje é BPF.
O kernel do Linux é orientado a eventos. Quase tudo o que acontece no kernel e no sistema como um todo pode ser representado como um conjunto de eventos. A interrupção é um evento, o recebimento de um pacote pela rede é um evento, a transferência de um processador para outro processo é um evento, o lançamento de uma função é um evento.
Portanto, BPF é um subsistema do kernel Linux que possibilita escrever pequenos programas que serão iniciados pelo kernel em resposta a eventos. Esses programas podem lançar luz sobre o que está acontecendo em seu sistema e controlá-lo.
Foi uma introdução muito longa. Vamos nos aproximar da realidade.
1994 viu a primeira versão do BPF, que alguns de vocês podem ter encontrado ao escrever regras simples para o utilitário tcpdump para visualizar ou farejar pacotes de rede. O tcpdump pode definir "filtros" para ver não todos, mas apenas os pacotes nos quais você está interessado. Por exemplo, "apenas protocolo tcp e apenas porta 80". Para cada pacote de passagem, uma função era executada para decidir se salvava aquele pacote específico ou não. Pode haver muitos pacotes, o que significa que nossa função deve ser muito rápida. Nossos filtros tcpdump estavam sendo convertidos em funções BPF, um exemplo disso é mostrado na imagem abaixo.
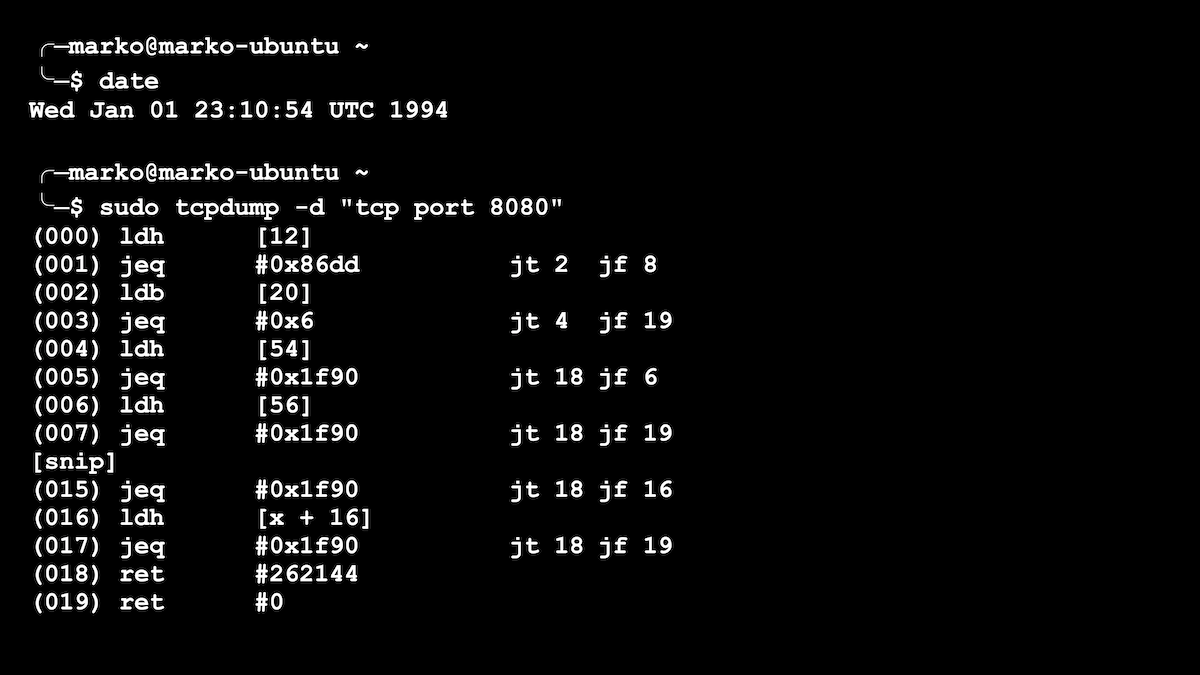
Um filtro simples para tcpdump é apresentado como um programa BPF
O BPF original era uma máquina virtual muito simples com vários registros. Mesmo assim, o BPF acelerou significativamente a filtragem de pacotes de rede. Ao mesmo tempo, este foi um grande passo em frente.

Em 2014, Alexey Starovoitov expandiu a funcionalidade do BPF. Ele aumentou o número de registros e o tamanho permitido do programa, adicionou a compilação JIT e fez um verificador que conferia a segurança dos programas. Mas o mais impressionante é que novos programas BPF podiam ser iniciados não apenas durante o processamento de pacotes, mas também em resposta a vários eventos do kernel, e passavam informações entre o kernel e o espaço do usuário.
Essas mudanças abriram caminho para novos casos de uso para BPF. Algumas coisas que antes eram feitas escrevendo módulos de kernel complexos e perigosos agora são relativamente fáceis de fazer por meio do BPF. Por que isso é legal? Sim, porque qualquer erro ao escrever um módulo geralmente leva ao pânico. Não para o pânico Go-shnoy fofo, mas para o pânico do kernel, após o qual - apenas reinicie.
O usuário médio do Linux agora tem uma habilidade superpoderosa de olhar sob o capô, anteriormente disponível apenas para desenvolvedores de kernel hardcore ou qualquer outra pessoa. Esta opção é comparável à capacidade de escrever sem esforço um programa para iOS ou Android: em telefones mais antigos, era impossível ou muito mais difícil.
A nova versão do BPF de Alexey é chamada eBPF (da palavra extendido - extendido). Mas agora ele substituiu todas as versões antigas do BPF e se tornou tão popular que todos o chamam simplesmente de BPF para simplificar.
Onde o BPF é usado?
Então, quais são esses eventos, ou gatilhos, aos quais os programas BPF podem ser anexados, e como as pessoas começaram a aproveitar esse poder recém-descoberto?
Atualmente, existem dois grandes grupos de gatilhos.
O primeiro grupo é usado para processar pacotes de rede e gerenciar o tráfego de rede. Estes são XDP, eventos de controle de tráfego e alguns mais.
Esses eventos são necessários para:
- , . Cloudflare Facebook BPF- DDoS-. ( BPF- ), . .
- , , — , , . . Facebook, , , .
- Crie balanceadores inteligentes. O exemplo mais impressionante é o projeto Cilium , que é mais frequentemente usado no cluster K8s como uma rede mesh. Cilium gerencia o tráfego: equilibra, redireciona e analisa. E tudo isso é feito com a ajuda de pequenos programas BPF lançados pelo kernel em resposta a um ou outro evento relacionado a pacotes ou sockets de rede.
Este foi o primeiro grupo de gatilhos associados a problemas de rede com a capacidade de influenciar o comportamento. O segundo grupo está relacionado à observabilidade mais geral; os programas desse grupo na maioria das vezes não têm a capacidade de influenciar algo, mas podem apenas "observar". Ela me interessa muito mais.
Este grupo contém gatilhos como:
- perf events — , Linux- perf: , , minor/major- . . , , , - . , , , , .
- tracepoints — ( ) , (, ). , — , , , , . - , tracepoints :
- ;
- , ;
- API, , , , , API.
, , , , , pprof .
- ;
- USDT — , tracepoints, user space-. . : MySQL, , PHP, Python. enable-dtrace . , Go . -, , DTrace . , , Solaris: , , GC -, .
Bem, então outro nível de magia começa:
- Os gatilhos ftrace nos fornecem a capacidade de executar um programa BPF no início de quase qualquer função do kernel. Totalmente dinâmico. Isso significa que o kernel chamará sua função BPF antes de executar qualquer função do kernel que você escolher. Ou todas as funções do kernel - tanto faz. Você pode anexar a todas as funções do kernel e obter uma boa visualização de todas as chamadas na saída.
- kprobes / uprobes fornecem quase a mesma coisa que ftrace, só que temos a capacidade de fazer snap em qualquer lugar ao executar uma função, tanto no kernel quanto no espaço do usuário. No meio da função existe algum tipo de if em uma variável e você precisa traçar um histograma dos valores dessa variável? Não é um problema.
- kretprobes/uretprobes — , user space. , , . , , PID fork.
A coisa mais notável sobre tudo isso, repito, é que, sendo chamado em qualquer um desses gatilhos, nosso programa BPF pode dar uma boa olhada: ler os argumentos da função, cronometrar, ler variáveis, variáveis globais, obter um rastreamento de pilha, salvar isso então, para mais tarde, transfira dados para o espaço do usuário para processamento, obtenha dados do espaço do usuário para filtragem ou alguns comandos de controle. Beleza!
Não sei quanto a você, mas para mim a nova infraestrutura é como um brinquedo que espero ansiosamente há muito tempo.
API, ou como usá-lo
Ok, Marco, você nos convenceu a olhar para o BPF. Mas como abordar isso?
Vamos dar uma olhada no que consiste um programa BPF e como interagir com ele.

Primeiro, temos um programa BPF que, se verificado, será carregado no kernel. Lá, ele será JIT compilado em código de máquina e executado no modo kernel quando o gatilho ao qual ele for anexado for acionado.
O programa BPF tem a capacidade de interagir com a segunda parte - o programa do espaço do usuário. Existem duas maneiras de fazer isso. Podemos escrever em um buffer circular, e a parte do espaço do usuário pode ler a partir dele. Também podemos escrever e ler no armazenamento de valor-chave, que é chamado de mapa BPF, e a parte do espaço do usuário, respectivamente, pode fazer a mesma coisa e, consequentemente, podem transferir algumas informações entre si.
Caminho direto
A maneira mais fácil de trabalhar com BPF, que em nenhum caso você deve começar, é escrever programas BPF semelhantes à linguagem C e compilar esse código usando o compilador Clang em código de máquina virtual. Em seguida, carregamos esse código usando a chamada de sistema BPF diretamente e interagimos com nosso programa BPF também usando a chamada de sistema BPF.
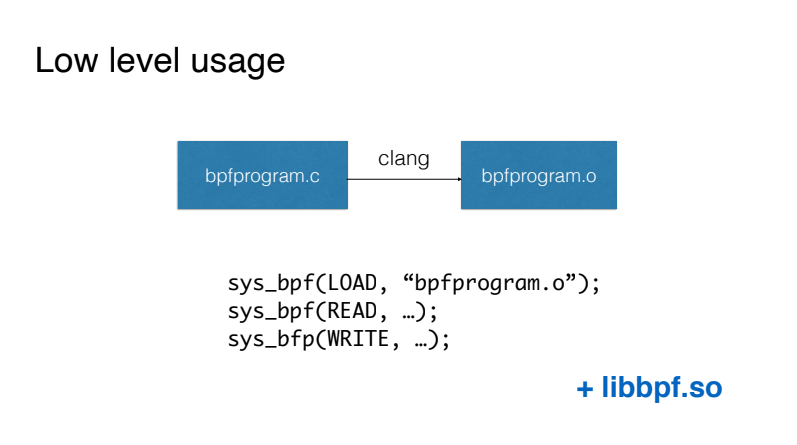
A primeira simplificação disponível é usar a biblioteca libbpf, que vem com as fontes do kernel e permite que você não trabalhe diretamente com a chamada de sistema BPF. Na verdade, ele fornece wrappers convenientes para carregar código, trabalhando com os chamados mapas para transferir dados do kernel para o espaço do usuário e vice-versa.
bcc
É claro que tal uso está longe de ser amigável. Felizmente, sob a marca iovizor, surgiu o projeto BCC, que simplifica muito a nossa vida.

Na verdade, ele prepara todo o ambiente de construção e nos dá a oportunidade de escrever programas BPF únicos, onde a parte C será montada e carregada no kernel automaticamente, e a parte do espaço do usuário pode ser feita em Python simples e compreensível.
bpftrace
Mas o BCC também parece complicado para muitas coisas. Por alguma razão, as pessoas especialmente não gostam de escrever partes em C.
Os mesmos caras da iovizor introduziram a ferramenta bpftrace, que permite escrever scripts BPF em uma linguagem de script simples como AWK (ou geralmente one-liners).

O renomado especialista em desempenho e observabilidade Brendan Gregg preparou a seguinte visualização das formas disponíveis de trabalhar com BPF:

Verticalmente, temos a simplicidade da ferramenta e horizontalmente, seu poder. Pode-se ver que o BCC é uma ferramenta muito poderosa, mas não super simples. O bpftrace é muito mais simples, mas é menos poderoso.
Exemplos de uso de BPF
Mas vamos olhar para as habilidades mágicas que se tornaram disponíveis para nós, com exemplos específicos.
Tanto o BCC quanto o bpftrace contêm uma pasta Ferramentas, que contém um grande número de scripts interessantes e úteis prontos para uso. Eles também são o Stack Overflow local do qual você pode copiar pedaços de código para seus scripts.
Por exemplo, aqui está um script que mostra a latência para consultas DNS:
╭─marko@marko-home ~
╰─$ sudo gethostlatency-bpfcc
TIME PID COMM LATms HOST
16:27:32 21417 DNS Res~ver #93 3.97 live.github.com
16:27:33 22055 cupsd 7.28 NPI86DDEE.local
16:27:33 15580 DNS Res~ver #87 0.40 github.githubassets.com
16:27:33 15777 DNS Res~ver #89 0.54 github.githubassets.com
16:27:33 21417 DNS Res~ver #93 0.35 live.github.com
16:27:42 15580 DNS Res~ver #87 5.61 ac.duckduckgo.com
16:27:42 15777 DNS Res~ver #89 3.81 www.facebook.com
16:27:42 15777 DNS Res~ver #89 3.76 tech.badoo.com :-)
16:27:43 21417 DNS Res~ver #93 3.89 static.xx.fbcdn.net
16:27:43 15580 DNS Res~ver #87 3.76 scontent-frt3-2.xx.fbcdn.net
16:27:43 15777 DNS Res~ver #89 3.50 scontent-frx5-1.xx.fbcdn.net
16:27:43 21417 DNS Res~ver #93 4.98 scontent-frt3-1.xx.fbcdn.net
16:27:44 15580 DNS Res~ver #87 5.53 edge-chat.facebook.com
16:27:44 15777 DNS Res~ver #89 0.24 edge-chat.facebook.com
16:27:44 22099 cupsd 7.28 NPI86DDEE.local
16:27:45 15580 DNS Res~ver #87 3.85 safebrowsing.googleapis.com
^C%
O utilitário mostra o tempo de execução de consultas DNS em tempo real, para que você possa capturar, por exemplo, alguns outliers inesperados.
E este é um script que "espia" o que os outros digitam em seus terminais:
╭─marko@marko-home ~
╰─$ sudo bashreadline-bpfcc
TIME PID COMMAND
16:51:42 24309 uname -a
16:52:03 24309 rm -rf src/badooEsse tipo de script pode ser usado para detectar um mau vizinho ou auditar a segurança dos servidores de uma empresa.
Script para visualizar chamadas de fluxo de linguagens de alto nível:
╭─marko@marko-home ~/tmp
╰─$ sudo /usr/sbin/lib/uflow -l python 20590
Tracing method calls in python process 20590... Ctrl-C to quit.
CPU PID TID TIME(us) METHOD
5 20590 20590 0.173 -> helloworld.py.hello
5 20590 20590 0.173 -> helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.hello
5 20590 20590 2.175 -> helloworld.py.hello
5 20590 20590 2.176 -> helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.hello
^C%Este exemplo mostra a pilha de chamadas de um programa Python.
O mesmo Brendan Gregg fez uma imagem na qual recolheu todos os scripts existentes com setas indicando os subsistemas que cada utilitário permite "observar". Como você pode ver, já temos um grande número de utilitários prontos disponíveis - para quase todas as ocasiões.

Não tente ver algo aqui. A imagem é usada como referência
E nós com Go?
Agora vamos falar sobre Go. Temos duas questões principais:
- Você pode escrever programas BPF em Go?
- É possível analisar programas escritos em Go?
Vamos em ordem.
Até o momento, o único compilador que pode ser compilado em um formato compreendido pelo mecanismo BPF é o Clang. Outro compilador popular, o GCC, ainda não possui um backend BPF. E a única linguagem de programação que pode ser compilada para BPF é uma versão muito limitada de C.
No entanto, o programa BPF tem uma segunda parte, que está no espaço do usuário. E pode ser escrito em Go.
Como mencionei acima, o BCC permite que você escreva esta parte em Python, que é a linguagem principal da ferramenta. Ao mesmo tempo, no repositório principal, BCC também suporta Lua e C ++, e em um repositório de terceiros também suporta Go .

Esse programa é exatamente igual a um programa Python. No início há uma linha em que um programa BPF em C, e depois dizemos onde anexar esse programa, e de alguma forma interagir com ele, por exemplo, obtemos dados do mapa EPF.
Na verdade, isso é tudo. Você pode ver o exemplo com mais detalhes no Github .
Provavelmente, a principal desvantagem é que a biblioteca C libbcc ou libbpf é usada para o trabalho, e construir um programa Go com essa biblioteca não é nada como um belo passeio no parque.
Além de iovisor / gobpf, encontrei mais três projetos atuais que permitem que você escreva uma parte de userland no Go.
- https://github.com/dropbox/goebpf
- https://github.com/cilium/ebpf
- https://github.com/andrewkroh/go-ebpf
A versão do Dropbox não requer nenhuma biblioteca C, mas você mesmo precisa construir a parte do kernel do programa BPF usando Clang e carregá-la no kernel com o programa Go.
A versão Cilium possui os mesmos recursos da versão Dropbox. Mas vale a pena citar, até porque é feito pela galera do projeto Cilium, o que significa que está fadado ao sucesso.
Trouxe o terceiro projeto para completar a foto. Como os dois anteriores, ele não possui dependências C externas, requer montagem manual de um programa BPF C, mas não parece ser muito promissor.
Na verdade, há outra questão: por que escrever programas BPF em Go? Afinal, se você observar o BCC ou o bpftrace, os programas BPF geralmente levam menos de 500 linhas de código. Não é mais fácil escrever um script na linguagem bpftrace ou descobrir um pouco do Python? Eu vejo duas razões aqui.
Primeiro, você realmente ama o Go e prefere fazer tudo nele. Além disso, os programas potencialmente Go são mais fáceis de transportar de máquina para máquina: vinculação estática, binários simples e assim por diante. Mas tudo está longe de ser tão óbvio, já que estamos amarrados a um núcleo específico. Vou parar por aqui, caso contrário, meu artigo se estenderá por mais 50 páginas.
Segunda opção: você não está escrevendo um script simples, mas um sistema em grande escala que também usa BPF internamente. Tenho até um exemplo de tal sistema em Go :

O projeto Scope se parece com um binário que, quando lançado na infraestrutura do K8s ou outra nuvem, analisa tudo o que acontece ao redor e mostra o que são containers, serviços, como eles interagem, etc. E muito disso é feito usando BPF. Um projeto interessante.
Analisando programas Go
Se você se lembra, tínhamos mais uma pergunta: podemos analisar programas escritos em Go usando BPF? Primeiro pensamento - é claro! Que diferença faz em que idioma o programa é escrito? Afinal, este é apenas um código compilado que, como todos os outros programas, calcula algo no processador, consome memória como se não dentro de si mesmo, interage com o hardware por meio do kernel e com o kernel por meio de chamadas de sistema. Em princípio, isso está correto, mas existem características de diferentes níveis de complexidade.
Passando argumentos
Um dos recursos é que o Go não usa a ABI que a maioria dos outros idiomas usam. Acontece que os pais fundadores decidiram assumir o sistema ABI do Plano 9 , que eles conheciam muito bem.
ABI é como uma API, um acordo de interoperabilidade, apenas no nível de bits, bytes e código de máquina.
O principal elemento ABI que nos interessa é como seus argumentos são passados para a função e como a resposta é passada de volta da função. Enquanto a ABI padrão x86-64 usa registradores do processador para passar argumentos e respostas, a ABI do Plano 9 usa uma pilha para isso.
Rob Pike e sua equipe não planejavam fazer outro padrão: eles já tinham um compilador C quase pronto para o sistema Plan 9, tão simples quanto dois-dois, que eles rapidamente converteram em um compilador para Go. Abordagem de engenharia em ação.
Mas isso, na verdade, não é um problema muito crítico. Em primeiro lugar, podemos ver em breve Go passando argumentos através de registradores e, em segundo lugar, obter argumentos da pilha de BPF não é difícil: o alias sargX já foi adicionado ao bpftrace e o mesmo aparecerá no BCC , provavelmente em um futuro próximo ...
Upd : a partir do momento que fiz o relatório, apareceu até uma proposta oficial detalhada de transição para o uso de cadastros na ABI.
Identificador de thread exclusivo
O segundo recurso tem a ver com o recurso favorito de Go, goroutines. Uma maneira de medir a latência de uma função é economizar o tempo que leva para chamar a função, tempo para sair da função e calcular a diferença e salve a hora de início com uma tecla contendo o nome da função e TID (número da rosca). O número da linha é necessário, pois a mesma função pode ser chamada simultaneamente por diferentes programas ou diferentes linhas do mesmo programa.

Mas em Go, goroutines caminham entre threads de sistema: agora, uma goroutine é executada em uma thread e um pouco mais tarde em outra. E no caso do Go, não colocaríamos o TID na chave, mas sim o GID, ou seja, o ID da goroutine, mas não podemos pegar. Tecnicamente, esse ID existe. Você pode até mesmo retirá-lo com hacks sujos, já que está em algum lugar na pilha, mas fazer isso é estritamente proibido pelas recomendações do grupo de desenvolvimento Go principal. Eles sentiram que nunca precisaríamos dessas informações. Bem como armazenamento local Goroutine, mas estou divagando.
Expandindo a pilha
O terceiro problema é o mais sério. Tão sério que, mesmo que de alguma forma resolvamos o segundo problema, isso não nos ajudará em nada a medir a latência das funções Go.
Provavelmente, a maioria dos leitores entende bem o que é uma pilha. A mesma pilha onde, em contraste com o heap ou heap, você pode alocar memória para variáveis e não pensar em liberá-las.
Se falarmos sobre C, então a pilha tem um tamanho fixo. Se formos além desse tamanho fixo, o famoso estouro de pilha acontecerá .
Em Go, a pilha é dinâmica. Em versões anteriores, eram pedaços concatenados de memória. Agora é um bloco contínuo de tamanho dinâmico. Isso significa que se a peça selecionada não for suficiente para nós, iremos expandir a atual. E se não podemos expandir, selecionamos outro maior e movemos todos os dados do local antigo para o novo. É uma história fascinante que fala de garantias de segurança, cgo, coletor de lixo, mas isso é assunto para outro artigo.
É importante saber que para que Go mova a pilha, ele precisa percorrer a pilha de chamadas do programa, todos os ponteiros da pilha.
É aí que reside o principal problema: os uretprobes, que são usados para anexar uma função BPF, alteram dinamicamente a pilha no final da execução da função para uma chamada embutida para seu manipulador, o chamado trampolim. E tal mudança em sua pilha, inesperada para Go, na maioria dos casos termina com uma falha do programa. Ops!

No entanto, essa história não é única. O desvendador de "pilha" do C ++ também trava no momento do tratamento da exceção.
Não há solução para este problema. Como de costume em tais casos, as partes estão trocando argumentos absolutamente razoáveis sobre a culpa uma da outra.
Mas se você realmente precisar colocar uretprobe, o problema pode ser contornado. Como? Não coloque uretprobe. Podemos colocar um uprobe em todos os lugares onde saímos da função. Pode haver um desses lugares, ou talvez 50.

E aqui a singularidade de Go joga em nossas mãos.
Normalmente, esse truque não funcionaria. Um compilador bastante inteligente pode fazer a chamada otimização de chamada final , quando em vez de retornar de uma função e retornar ao longo da pilha de chamadas, simplesmente pulamos para o início da próxima função. Esse tipo de otimização é crítico para linguagens funcionais como Haskell . Sem isso, eles não poderiam dar um passo sem o estouro da pilha. Mas, com essa otimização, simplesmente não podemos encontrar todos os lugares de onde retornamos da função.
A peculiaridade é que a versão 1.14 do compilador Go ainda não é capaz de otimizar a chamada final. Isso significa que o truque de anexar a todas as saídas explícitas de uma função funciona, embora seja muito tedioso.
Exemplos de
Não pense que BPF é inútil para Go. Isso está longe de ser o caso: podemos fazer tudo o mais que não afete as nuances acima. E nós vamos.
Vamos dar uma olhada em alguns exemplos.
Vamos pegar um programa simples de preparação. Basicamente, é um servidor web que escuta na porta 8080 e tem um manipulador de solicitação HTTP. O manipulador obterá o parâmetro name, o parâmetro Go do URL e fará algum tipo de verificação do "site" e, em seguida, enviará todas as três variáveis (nome, ano e status de verificação) para a função prepareAnswer (), que preparará uma resposta como uma string.

A validação do site é uma solicitação HTTP que verifica se o site da conferência está funcionando e usando um pipe e uma goroutine. E a função de preparar a resposta apenas transforma tudo em uma string legível.
Iremos acionar nosso programa com uma simples solicitação curl:

Como primeiro exemplo, usaremos bpftrace para imprimir todas as chamadas de função de nosso programa. Atribuímos aqui todas as funções que se enquadram no principal. Em Go, todas as suas funções têm um símbolo semelhante ao nome do pacote-ponto-nome da função. Nosso pacote é o principal, e o tempo de execução da função seria o tempo de execução.

Quando eu faço curl, o manipulador, a função de validação do site e a subfunção goroutine são lançados, e então a função de preparação de resposta. Classe!
A seguir, desejo não apenas exibir quais funções estão sendo executadas, mas também seus argumentos. Vamos usar a função prepareAnswer (). Ela tem três argumentos. Vamos tentar imprimir dois inteiros.
Tomamos bpftrace, só que agora não um one-liner, mas um script. Anexamos à nossa função e usamos os apelidos para os argumentos da pilha que mencionei.
Na saída, vemos o que aprovamos em 2020, obtivemos o status 200 e passamos 2021 uma vez.
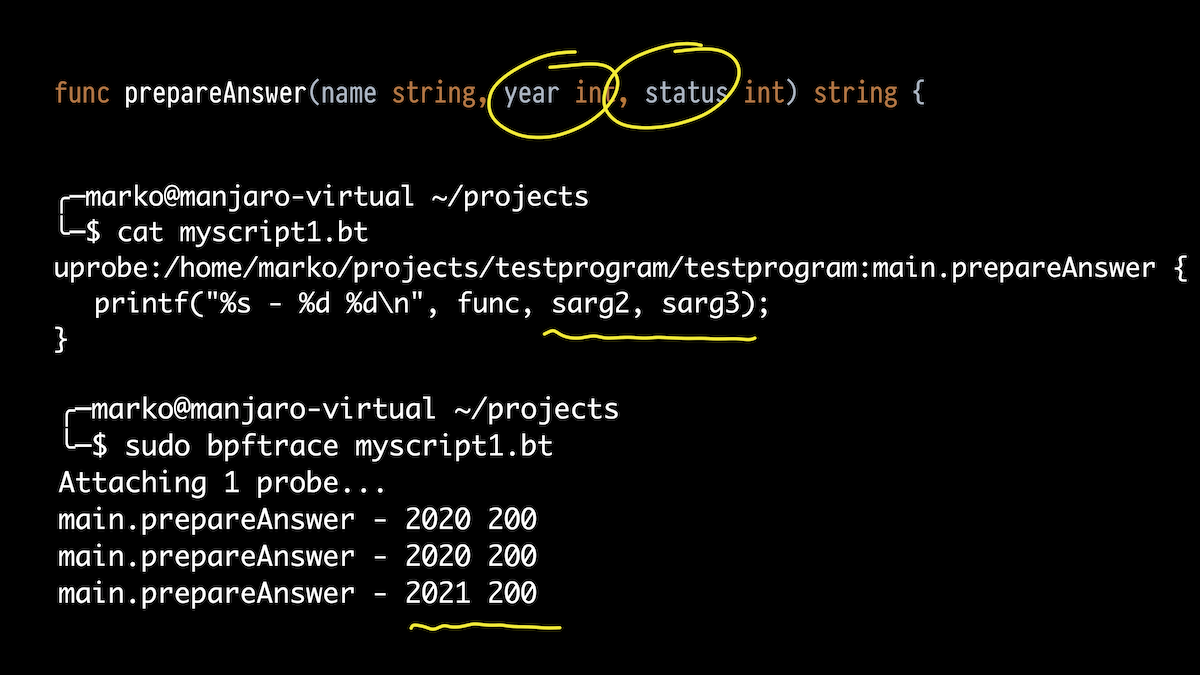
Mas a função tem três argumentos. O primeiro é uma corda. O que tem ele?
Vamos apenas imprimir todos os argumentos da pilha de 0 a 4. E o que vemos? Alguma figura grande, alguma figura menor e nossos velhos 2021 e 200. O que são esses números estranhos no início?

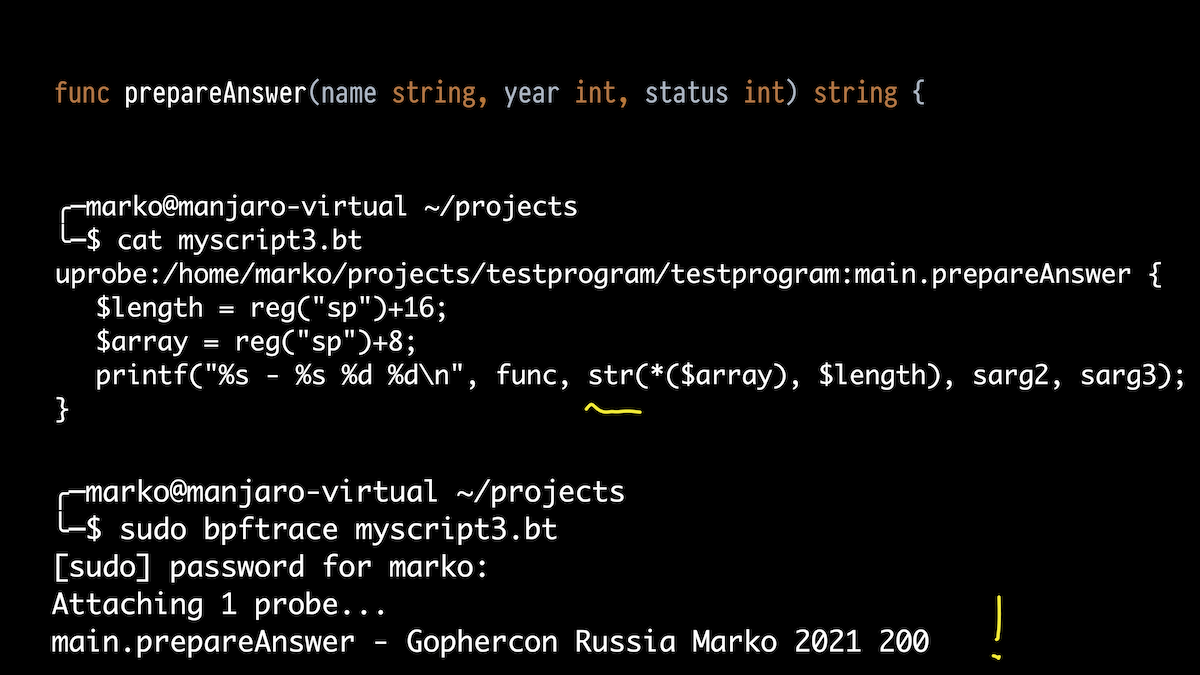
É aqui que é útil conhecer o dispositivo Go. Se em C uma string é apenas uma matriz terminada em zero de caracteres, então em Go uma string é na verdade uma estrutura que consiste em um ponteiro para uma matriz de caracteres (não terminada em zero, a propósito) e comprimento.

Mas o compilador Go, quando passa uma string como um argumento, expande essa estrutura e a passa como dois argumentos. E acontece que o primeiro dígito estranho é apenas um ponteiro para nosso array, e o segundo é o comprimento.
E a verdade: o comprimento esperado da string é 22.
Conseqüentemente, corrigimos nosso script um pouco para obter esses dois valores por meio da pilha de registradores do ponteiro e do deslocamento correto, e usando a função embutida str () nós a geramos como uma string. Tudo funciona:
Bem, vamos dar uma olhada no tempo de execução. Por exemplo, eu queria saber quais goroutines nosso programa lança. Eu sei que as goroutines são acionadas pelas funções newproc () e newproc1 (). Vamos nos conectar a eles. O primeiro argumento para a função newproc1 () é um ponteiro para a estrutura funcval, que tem apenas um campo - um ponteiro de função:
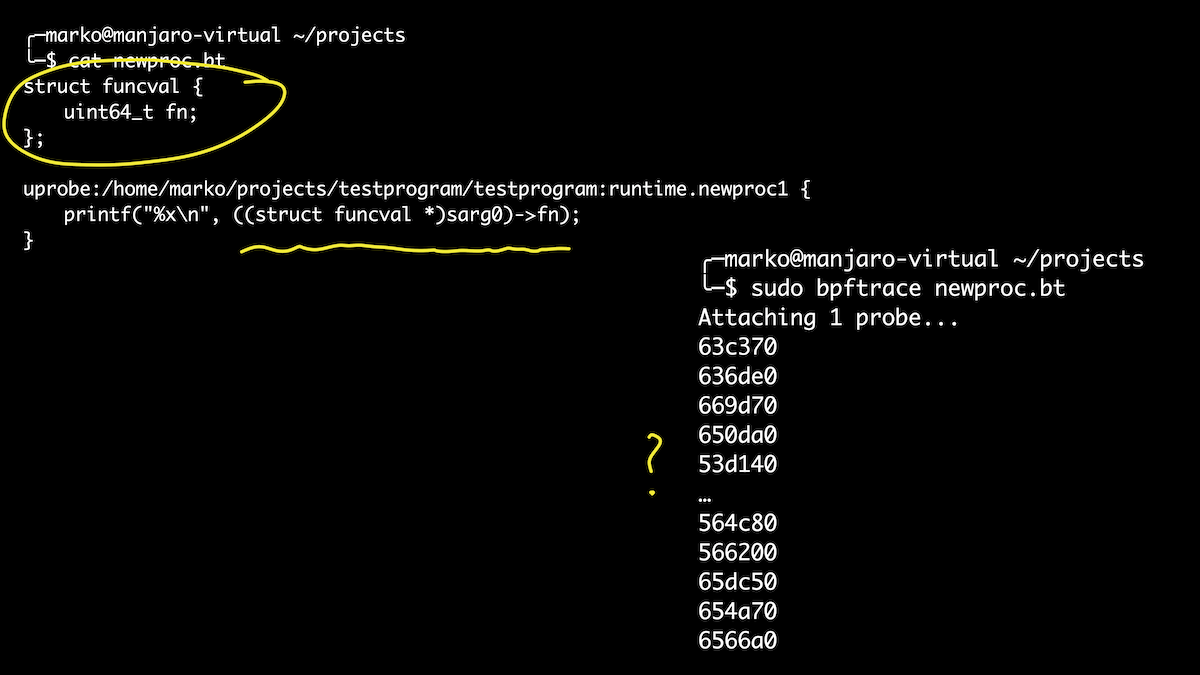
Nesse caso, usaremos a oportunidade para definir estruturas diretamente no script. É um pouco mais fácil do que brincar com conjuntos de compensação. Aqui, geramos todos os goroutines que são iniciados quando nosso manipulador é chamado. E se depois disso obtivermos os nomes dos símbolos para nossos offsets, apenas entre eles veremos nossa função checkSite. Hooray!
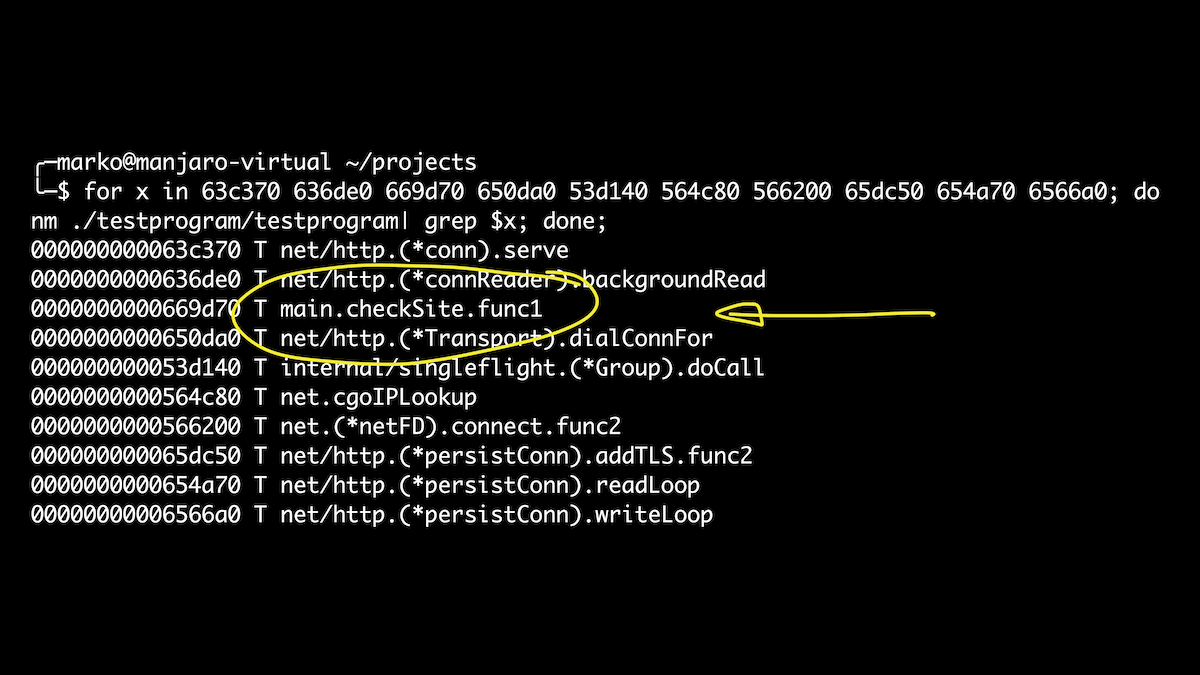
Esses exemplos são uma gota no oceano de capacidades BPF, BCC e bpftrace. Com o conhecimento adequado dos recursos internos e experiência, você pode obter quase todas as informações de um programa em execução sem interrompê-lo ou alterá-lo.
Conclusão
Isso é tudo que eu queria dizer a você. Espero ter sido capaz de inspirar você.
BPF é uma das tendências mais modernas e promissoras do Linux. E tenho certeza de que nos próximos anos veremos muito mais coisas interessantes não só na tecnologia em si, mas também nas ferramentas e sua distribuição.
Antes que seja tarde e nem todo mundo saiba do BPF, brinque com ele, torne-se mágico, resolva problemas e ajude seus colegas. Dizem que os truques de mágica só funcionam uma vez.
Quanto a Go, éramos, como sempre, bastante únicos. Sempre temos algumas nuances: ou o compilador é diferente, então o ABI, precisamos de algum tipo de GOPATH, um nome que não pode ser Google. Mas nos tornamos uma força a ser reconhecida e acredito que a vida só vai melhorar.