Este artigo é uma tradução de uma das postagens do neptune.ai e destaca as ferramentas de aprendizado profundo mais interessantes apresentadas na conferência de aprendizado de máquina ICLR 2020.

Onde o aprendizado profundo avançado é criado e discutido?
Um dos principais locais para discussão do Deep Learning é o ICLR - a principal conferência sobre aprendizado profundo, que aconteceu de 27 a 30 de abril de 2020. Com mais de 5.500 participantes e quase 700 apresentações e palestras, este é um grande sucesso para um evento totalmente online. Você pode encontrar informações completas sobre a conferência aqui , aqui ou aqui .
Os encontros sociais virtuais foram um dos destaques do ICLR 2020. Os organizadores decidiram lançar um projeto denominado “Ferramentas e práticas de código aberto no estado da arte da pesquisa em EAD”. O tema foi escolhido devido ao fato de que o kit de ferramentas correspondente é uma parte inevitável do trabalho de um pesquisador de aprendizagem profunda. Os avanços nesta área levaram à proliferação de grandes ecossistemas (TensorFlow , PyTorch , MXNet), bem como ferramentas direcionadas menores que atendem às necessidades específicas dos pesquisadores.
O objetivo do evento mencionado foi reunir-se com os criadores e usuários de ferramentas open source, bem como compartilhar experiências e impressões entre a comunidade de Deep Learning. No total, foram reunidas mais de 100 pessoas, entre os principais inspiradores e líderes de projetos, a quem demos curtos períodos de tempo para apresentarem seus trabalhos. Os participantes e organizadores ficaram surpresos com a grande variedade e criatividade das ferramentas e bibliotecas apresentadas.
Este artigo contém projetos brilhantes apresentados a partir de um palco virtual.
Ferramentas e Bibliotecas
A seguir estão oito ferramentas que foram demonstradas no ICLR com uma visão geral detalhada dos recursos.
Cada seção apresenta respostas para uma série de pontos de uma maneira muito sucinta:
- Qual problema a ferramenta / biblioteca resolve?
- Como executo ou crio um caso de uso mínimo?
- Recursos externos para um mergulho mais profundo na biblioteca / ferramenta.
- Perfil dos representantes do projeto caso haja desejo de contatá-los.
Você pode pular para uma seção específica abaixo ou apenas navegar por todos eles um por um. Gostar de ler!
AmpliGraph
Tópico: Modelos de incorporação baseados em Knowledge Graph.
Linguagem de programação: Python
Por: Luca Costabello
Twitter | LinkedIn | GitHub | Os gráficos de conhecimento do site
são uma ferramenta versátil para representar sistemas complexos. Seja uma rede social, um conjunto de dados de bioinformática ou dados de compra no varejo, a modelagem de conhecimento como um gráfico permite que as organizações identifiquem conexões importantes que, de outra forma, seriam esquecidas.
Revelar as relações entre os dados requer modelos especiais de aprendizado de máquina especialmente projetados para trabalhar com gráficos.
AmpliGraphÉ um conjunto de modelos de aprendizado de máquina licenciados pela Apache2 para extrair embeddings de gráficos de conhecimento. Esses modelos codificam os nós e arestas do gráfico em uma forma vetorial e os combinam para prever fatos ausentes. Embeddings de gráfico são usados em tarefas como parte superior do gráfico de conhecimento, descoberta de conhecimento, armazenamento em cluster baseado em link e outros.
O AmpliGraph reduz a barreira de entrada para o tópico de incorporação de gráficos para pesquisadores, tornando esses modelos disponíveis para usuários inexperientes. Aproveitando a API de código aberto, o projeto oferece suporte a uma comunidade de entusiastas usando gráficos em aprendizado de máquina. O projeto permite que você aprenda como criar e visualizar embeddings a partir de gráficos de conhecimento baseados em dados do mundo real e como usá-los em tarefas subsequentes de aprendizado de máquina.
Para começar, a seguir está um trecho mínimo de código que treina um modelo em um dos conjuntos de dados de referência e prevê links ausentes:


AmpliGraph foi originalmente desenvolvido na Accenture Labs Dublin , onde é usado em vários projetos industriais.
Automunge
Plataforma de preparação de dados tabulares
Linguagem de programação: Python
Postado por Nicholas Teague
Twitter | LinkedIn | GitHub | Site
AutomungeÉ uma biblioteca Python para ajudar a preparar dados tabulares para uso em aprendizado de máquina. Por meio do kit de ferramentas do pacote, transformações simples são possíveis para que a engeenering de recursos normalize, codifique e preencha as lacunas. As transformações são aplicadas à subamostra de treinamento e, em seguida, aplicadas de maneira semelhante aos dados da subamostra de teste. As conversões podem ser executadas automaticamente, atribuídas a partir de uma biblioteca interna ou configuradas de forma flexível pelo usuário. As opções de preenchimento incluem “preenchimento baseado em aprendizado de máquina”, no qual os modelos são treinados para prever informações ausentes para cada coluna de dados.
Simplificando:
automunge (.) Prepara dados tabulares para uso em aprendizado de máquina,
postmunge (.)dados adicionais são processados sequencialmente e com alta eficiência.
Automunge está disponível para instalação via pip:

Após a instalação, basta importar a biblioteca para o Jupyter Notebook para inicialização:

Para processar automaticamente os dados de uma amostra de treinamento com parâmetros padrão, basta usar o comando:

Além disso, para o processamento subsequente de dados da subamostra de teste, é suficiente executar um comando usando o dicionário postprocess_dict obtido chamando automunge (.) Acima:

Os parâmetros assigncat e assigninfill na chamada automunge (.) Podem ser usados para definir detalhes de conversão e tipos de dados para preencher as lacunas. Por exemplo, para um conjunto de dados com colunas 'coluna1' e 'coluna2', você pode atribuir escalonamento com base em valores mínimo e máximo ('mnmx') com preenchimento ML para coluna1 e codificação one-hot ('texto') com preenchimento baseado em o valor mais comum para column2. Os dados de outras colunas não especificadas explicitamente serão processados automaticamente.

Recursos e links do
site | GitHub | Breve apresentação
DynaML
Aprendizado de máquina para a
linguagem de programação Scala : Scala
Postado por: Mandar Chandorkar
Twitter | LinkedIn | GitHub
DynaML é uma caixa de ferramentas de pesquisa e aprendizado de máquina baseada em Scala. Tem como objetivo fornecer ao usuário um ambiente de ponta a ponta que pode ajudar em:
- desenvolvimento / prototipagem de modelos,
- trabalhar com pipelines volumosos e complexos,
- visualização de dados e resultados,
- reaproveitamento de código na forma de scripts e Notebooks.
O DynaML aproveita os pontos fortes da linguagem e do ecossistema Scala para criar um ambiente que oferece desempenho e flexibilidade. Ele é baseado em projetos excelentes como Ammonite scala, Tensorflow-Scala e a biblioteca de computação numérica de alto desempenho Breeze .
Um componente chave do DynaML é o REPL / wrapper, que possui destaque de sintaxe e um sistema de preenchimento automático avançado.
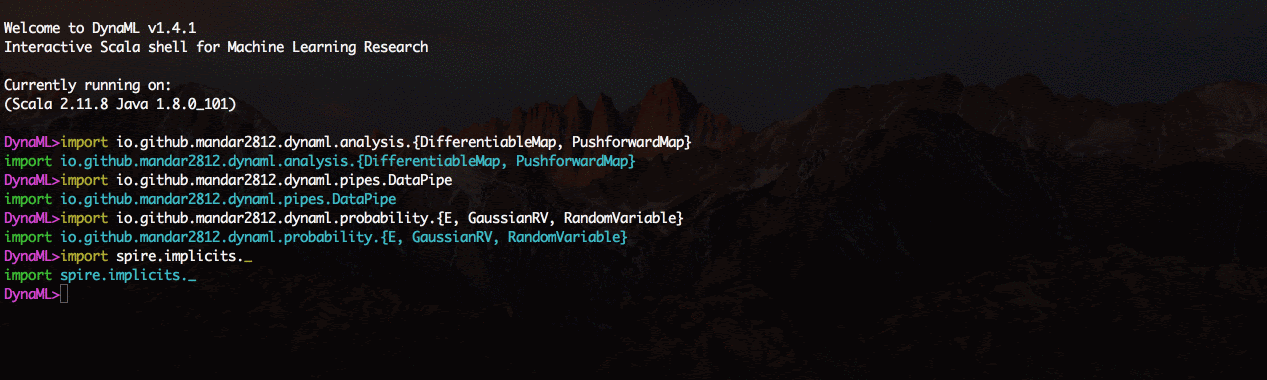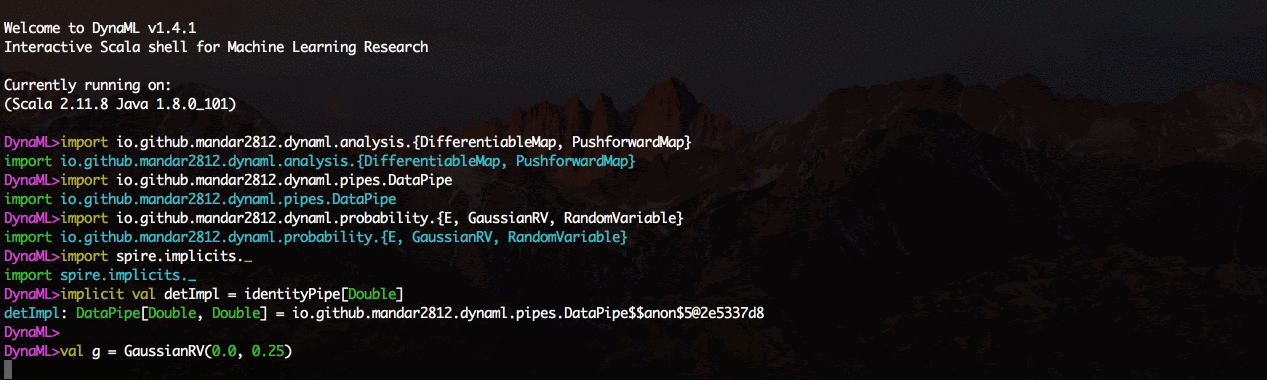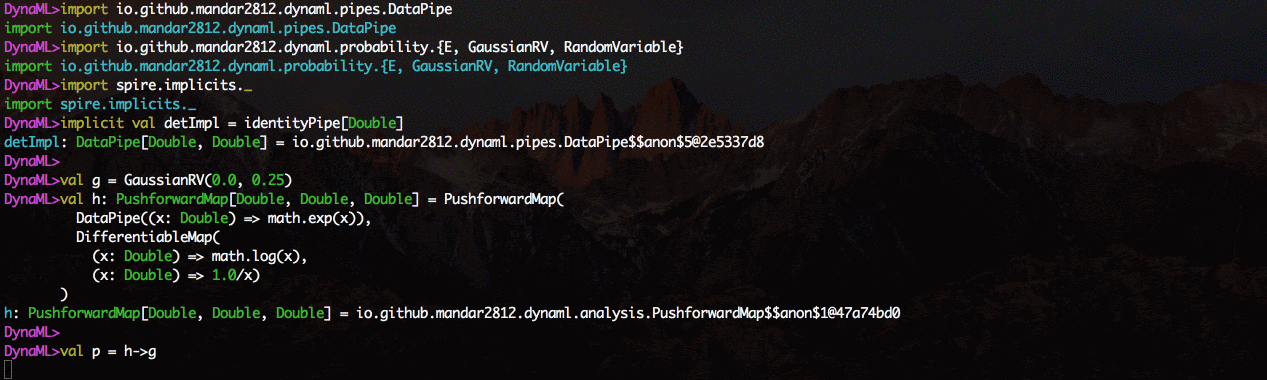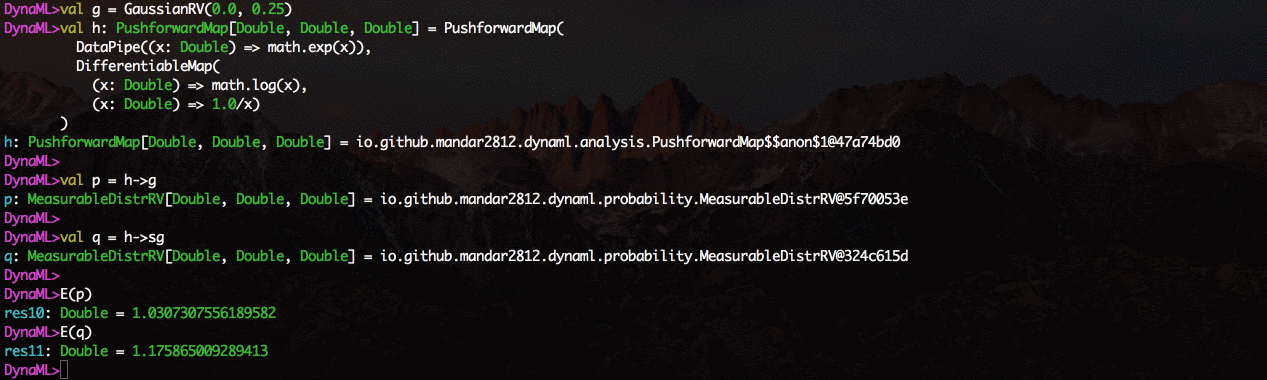
O ambiente vem com suporte para visualização 2D e 3D, os resultados podem ser exibidos diretamente do shell de comando.

O módulo de tubos de dados facilita a criação de pipelines de processamento de dados de maneira modular compatível com o layout. Crie funções, envolva-as usando o construtor DataPipe e construa blocos de funções usando o operador>.
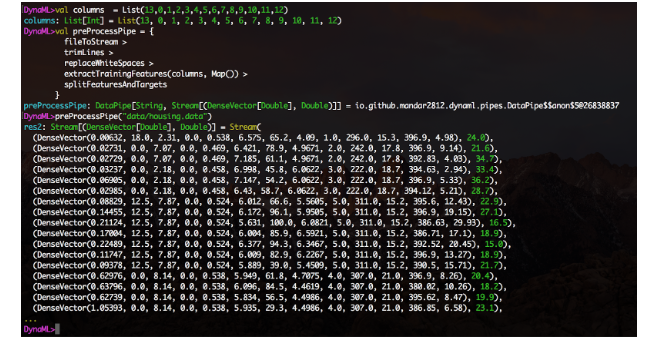
Um recurso experimental de integração de notebook Jupyter também está disponível, e o diretório de notebooks do repositório contém vários exemplos de uso do núcleo DynaML-Scala Jupyter.

O Guia do usuário contém referências e documentação abrangentes para ajudá-lo a dominar e obter o máximo do ambiente DynaML.
Abaixo estão alguns aplicativos interessantes que destacam os pontos fortes do DynaML:
- a física inspirou redes neurais para resolver a equação de Burger e o sistema Fokker-Planck ,
- Treinamento de aprendizado profundo,
- Modelos de processos gaussianos para previsão de séries temporais autoregressivas.
Recursos e links do
GitHub | Manual do usuário
Hidra
Gerenciador de configurações e parâmetros
Linguagem de programação: Python
Postado por Omry Yadan
Twitter | GitHub
Desenvolvido por Facebook AI, Hydra é uma plataforma Python que simplifica o desenvolvimento de aplicativos de pesquisa, fornecendo a capacidade de criar e substituir configurações usando arquivos de configuração e a linha de comando. A plataforma também oferece suporte para expansão automática de parâmetros, execução remota e paralela por meio de plug-ins, gerenciamento automático de diretório de trabalho e sugestão dinâmica de opções de conclusão pressionando a tecla TAB.
Usar Hydra também torna seu código mais portátil em diferentes ambientes de aprendizado de máquina. Permite que você alterne entre estações de trabalho pessoais, clusters públicos e privados sem alterar seu código. O acima exposto é obtido por meio de uma arquitetura modular.
Exemplo básico
Este exemplo usa uma configuração de banco de dados, mas você pode substituí-la facilmente por modelos, conjuntos de dados ou o que mais precisar.
config.yaml:

my_app.py:

Você pode substituir qualquer coisa na configuração da linha de comando:

Exemplo de composição:
você pode querer alternar entre duas configurações de banco de dados diferentes.
Crie esta estrutura de diretório:

config.yaml:
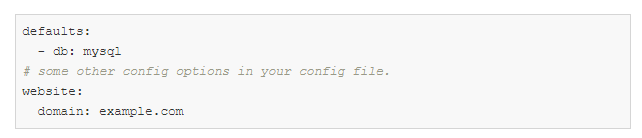
defaults é uma diretiva especial que diz ao Hydra para usar db / mysql.yaml ao compor um objeto de configuração.
Agora você pode escolher qual configuração de banco de dados usar, bem como substituir valores de parâmetros na linha de comando:

Confira o tutorial para saber mais.
Além disso, novos recursos interessantes estarão disponíveis em breve:
- configurações fortemente tipadas (arquivos de configuração estruturados),
- otimização de hiperparâmetros usando plug-ins Ax e Nevergrad,
- lançando AWS com o plugin Ray launcher,
- lançamento paralelo local via plugin joblib e muito mais.
Larq
Linguagem de
programação de redes neurais binarizadas : Python
Postado por: Lucas Geiger
Twitter | LinkedIn | GitHub
Larq é um ecossistema de pacote Python de código aberto para construção, treinamento e implantação de redes neurais binarizadas (BNNs). BNNs são modelos de aprendizado profundo nos quais as ativações e pesos não são codificados usando 32, 16 ou 8 bits, mas usando apenas 1 bit. Isso pode acelerar drasticamente o tempo de inferência e reduzir o consumo de energia, tornando o BNN ideal para aplicativos móveis e periféricos.
O ecossistema de código aberto Larq tem três componentes principais.
- Larq — , . API, TensorFlow Keras. . Larq BNNs, .
- Larq Zoo BNNs, . Larq Zoo , BNN .
- Larq Compute Engine — BNNs. TensorFlow Lite MLIR Larq FlatBuffer, TF Lite. ARM64, , Android Raspberry Pi, , , BNN.
Os autores do projeto estão constantemente criando modelos mais rápidos e expandindo o ecossistema Larq para novas plataformas de hardware e aplicativos de aprendizado profundo. Por exemplo, o trabalho está em andamento para integrar a quantização de 8 bits ponta a ponta para poder treinar e implantar combinações de redes binárias e de 8 bits usando o Larq.
Recursos e links do
site | GitHub larq / larq | GitHub larq / zoo | GitHub larq / compute-engine | Livros didáticos | Blog | Twitter
McKernel
Métodos de kernel em
linguagem de programação de tempo logaritmicamente linear : C / C ++
Postado por: J. de Curtó i Díaz
Twitter | Site
A primeira biblioteca C ++ de código aberto fornecendo uma aproximação de recursos aleatórios dos métodos do kernel e uma estrutura completa de Deep Learning.
McKernel oferece quatro usos diferentes.
- Código Hadamard de código aberto rápido e autocontido. Para uso em áreas como compressão, criptografia ou computação quântica.
- Técnicas nucleares extremamente rápidas. Podem ser usados sempre que métodos SVM (método de vetor de suporte: ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0 % BE% D1% 80% D0% BD% D1% 8B% D1% 85_% D0% B2% D0% B5% D0% BA% D1% 82% D0% BE% D1% 80% D0% BE% D0% B2 ) são superiores ao Deep Learning. Por exemplo, alguns aplicativos de robótica e vários casos de uso de aprendizado de máquina em saúde e outras áreas incluem Aprendizado federado e seleção de canal.
- A integração de Deep Learning e métodos nucleares permite o desenvolvimento da arquitetura de Deep Learning em uma direção antropomórfica / matemática a priori.
- Estrutura de pesquisa de aprendizado profundo para resolver uma série de questões em aberto no aprendizado de máquina.
A equação que descreve todos os cálculos tem a seguinte aparência:

Aqui, os autores, como pioneiros do formalismo, costumavam explicar o uso de sintomas aleatórios como métodos de Aprendizado Profundo e técnicas nucleares . A base teórica é baseada em quatro gigantes: Gauss, Wiener, Fourier e Kalman. A base para isso foi lançada por Rahimi e Recht (NIPS 2007) e Le et al. (ICML 2013).
Visando o usuário típico
O público primário de McKernel são pesquisadores e profissionais nas áreas de robótica, aprendizado de máquina para saúde, processamento de sinais e comunicações que precisam de implementação rápida e eficiente em C ++. Nesse caso, a maioria das bibliotecas de Deep Learning não atendem às condições fornecidas, uma vez que são baseadas principalmente em implementações de Python de alto nível. Além disso, o público pode ser representado por representantes da comunidade mais ampla de aprendizado de máquina e Deep Learning, que buscam aprimorar a arquitetura de redes neurais usando métodos nucleares.
Um exemplo visual super simples para executar uma biblioteca sem perder tempo fica assim:

Qual é o próximo?
Aprendizado End-to-End, Aprendizado Auto-Supervisionado, Meta-Aprendizado, Integração com Estratégias Evolucionárias, Reduzindo Significativamente o Espaço de Busca com NAS, ...
Recursos e Links
GitHub | Apresentação completa
SCCH Training Engine
Rotinas de automação para
linguagem de programação de aprendizado profundo : Python
Postado por: Natalya Shepeleva
Twitter | LinkedIn | Site O
desenvolvimento de um pipeline típico de Deep Learning é bastante padrão: pré-processamento de dados, design / implementação de tarefas, treinamento de modelo e avaliação de resultados. No entanto, de projeto para projeto, sua utilização requer a participação de um engenheiro em todas as fases do desenvolvimento, o que leva à repetição das mesmas ações, duplicação de código e, no final, leva a erros.
O objetivo do SCCH Training Engine é unificar e automatizar o processo de desenvolvimento do Deep Learning para os dois frameworks mais populares PyTorch e TensorFlow. A arquitetura de entrada única minimiza o tempo de desenvolvimento e protege contra bugs.
Para quem?
A arquitetura flexível do SCCH Training Engine tem dois níveis de experiência do usuário.
A Principal. Neste nível, o usuário deve fornecer dados para treinamento e escrever os parâmetros de treinamento do modelo no arquivo de configuração. Depois disso, todos os processos, incluindo processamento de dados, treinamento do modelo e validação dos resultados, serão executados automaticamente. Como resultado, um modelo treinado será obtido dentro de um dos frameworks principais.
Avançado.Graças ao conceito de componente modular, o usuário pode modificar os módulos de acordo com suas necessidades, implantando seus próprios modelos e utilizando diversas funções de perda e métricas de qualidade. Essa arquitetura modular permite adicionar recursos adicionais sem interferir na operação do pipeline principal.
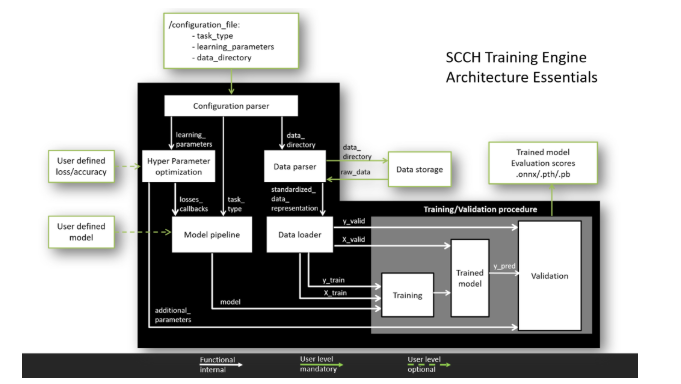
O que ele pode fazer?
Capacidades atuais:
- trabalhar com TensorFlow e PyTorch,
- um pipeline padronizado para analisar dados de vários formatos,
- um pipeline padronizado para treinamento de modelo e validação de resultados,
- suporte para tarefas de classificação, segmentação e detecção,
- suporte de validação cruzada.
Recursos em desenvolvimento:
- pesquisar os hiperparâmetros do modelo ideal,
- carregar pesos de modelo e treinamento de um ponto de controle específico,
- Suporte à arquitetura GAN.
Como funciona?
Para ver o SCCH Training Engine em toda a sua glória, você precisa dar dois passos.
- Basta copiar o repositório e instalar os pacotes necessários usando o comando: pip install requirements.txt.
- Execute python main.py para ver um estudo de caso MNIST com processamento e treinamento em um modelo LeNet-5.
Todas as informações sobre como criar um arquivo de configuração e como usar recursos avançados podem ser encontradas na página GitHub .
Lançamento estável com recursos principais: programado para o final de maio de 2020.
Recursos e links
GitHub | Local na rede Internet
Tokenizers
Linguagem de programação de tokenizadores de texto : Rust with Python API
Postado por: Anthony Mua
Twitter | LinkedIn | GitHub
abraçando / tokenizers fornece acesso aos tokenizers mais modernos, com foco no desempenho e uso polivalente. Os tokenizadores permitem que você treine e use os tokenizadores sem esforço. Os tokenizadores podem ajudá-lo independentemente de você ser um estudioso ou um profissional da área de PNL.
Características principais
- Velocidade extrema: a tokenização não deve ser um gargalo em seu pipeline e você não precisa pré-processar seus dados. Graças à implementação nativa do Rust, a tokenização de gigabytes de texto leva apenas alguns segundos.
- Offsets / Alignment: Fornece controle de offset mesmo ao processar texto com procedimentos de normalização complexos. Isso facilita a extração de texto para tarefas como NER ou resposta a perguntas.
- Pré-processamento: cuida de qualquer pré-processamento necessário antes de alimentar dados em seu modelo de linguagem (truncamento, preenchimento, adição de tokens especiais, etc.).
- Facilidade de aprendizado: treine qualquer tokenizer em um novo chassi. Por exemplo, aprender um tokenizer para BERT em um novo idioma nunca foi tão fácil.
- Multi-idiomas: um pacote com vários idiomas. Você pode começar a usá-lo agora mesmo com Python, Node.js ou Rust. O trabalho nessa direção continua!
Exemplo:

E assim por diante:
- serialização em um único arquivo e carregamento em uma linha para qualquer tokenizer,
- Suporte para Unigrama.
Hugging Face vê sua missão como ajudar a promover e democratizar a PNL.
Recursos e links do
GitHub abraçando face / transformadores | GitHub abraçando face / tokenizadores | Twitter
Conclusão
Em conclusão, deve-se observar que há um grande número de bibliotecas que são úteis para Deep Learning e machine learning em geral, e não há como descrever todas elas em um artigo. Alguns dos projetos descritos acima serão úteis em casos específicos, alguns já são bem conhecidos, e alguns projetos maravilhosos, infelizmente, não entraram no artigo.
Nós, da CleverDATA, nos esforçamos para nos manter atualizados com novas ferramentas e bibliotecas úteis e aplicamos ativamente novas abordagens em nosso trabalho relacionado ao uso de Deep Learning e Machine Learning. De minha parte, gostaria de chamar a atenção dos leitores para essas duas bibliotecas que não estão incluídas no artigo principal, mas ajudam muito no trabalho com redes neurais: Catalyst (https://catalyst-team.com ) e Albumentation ( https://albumentations.ai/ ).
Tenho certeza de que todo especialista praticante tem suas próprias ferramentas e bibliotecas favoritas, incluindo aquelas pouco conhecidas por um grande público. Se lhe parece que alguma ferramenta útil em seu trabalho foi em vão ignorada, por favor, escreva-a nos comentários: mesmo mencioná-la na discussão ajudará a projetos promissores para atrair novos seguidores, e o aumento da popularidade, por sua vez, leva a uma melhoria na funcionalidade e ao desenvolvimento de si mesmos bibliotecas.
Obrigado pela atenção e espero que o conjunto de bibliotecas apresentado seja útil no seu trabalho!