
Olá!
Meu nome é Nikita, e supervisiono o desenvolvimento de vários projetos na DomClick. Hoje eu quero continuar o tema das "fotos engraçadas" no mundo RabbitMQ. Em seu artigo, Alexey Kazakov considerou uma ferramenta poderosa como filas de espera e diferentes implementações da estratégia de repetição. Hoje vamos falar sobre como usar o RabbitMQ para agendar tarefas periódicas.
Por que precisamos criar nossa própria bicicleta e por que abandonamos o Celery e outras ferramentas de gerenciamento de tarefas? O fato é que não se enquadravam em nossas tarefas e requisitos de tolerância a falhas, que são bastante rígidos em nossa empresa.
Ao mudar para o Docker e o Kubernetes, muitos desenvolvedores enfrentam problemas para organizar tarefas periódicas, as coroas são lançadas com um pandeiro e o controle do processo deixa muito a desejar. E há problemas com picos de carga durante o dia.
Minha tarefa era implementar no projeto um sistema confiável para o processamento de tarefas periódicas, ao mesmo tempo que era facilmente escalável e tolerante a falhas. Nosso projeto é em Python, então era lógico ver como Celery se adequava a nós. Esta é uma boa ferramenta, mas com ela frequentemente encontramos problemas de confiabilidade, escalabilidade e liberação contínua. Um pod - um grupo de processo. Ao dimensionar o Celery, é necessário aumentar os recursos de um pod, pois não há sincronização entre os pods, o que significa interromper o processamento das tarefas, ainda que temporariamente. E se as tarefas também são de longo prazo, então você já adivinhou o quão difícil é gerenciar. A segunda desvantagem óbvia: fora da caixa, não há suporte para assincronia, e para nós isso é importante, porque as tarefas contêm principalmente operações de E / S e o Celery é executado em threads.
Naquela época (2018), não encontramos uma ferramenta pronta adequada e começamos a desenvolver a nossa. Tomando por base a funcionalidade de diferimento de execução de tarefas e Dead Letter Exchange, decidimos criar um sistema de processamento de tarefas periódicas. O conceito era mais ou menos assim:
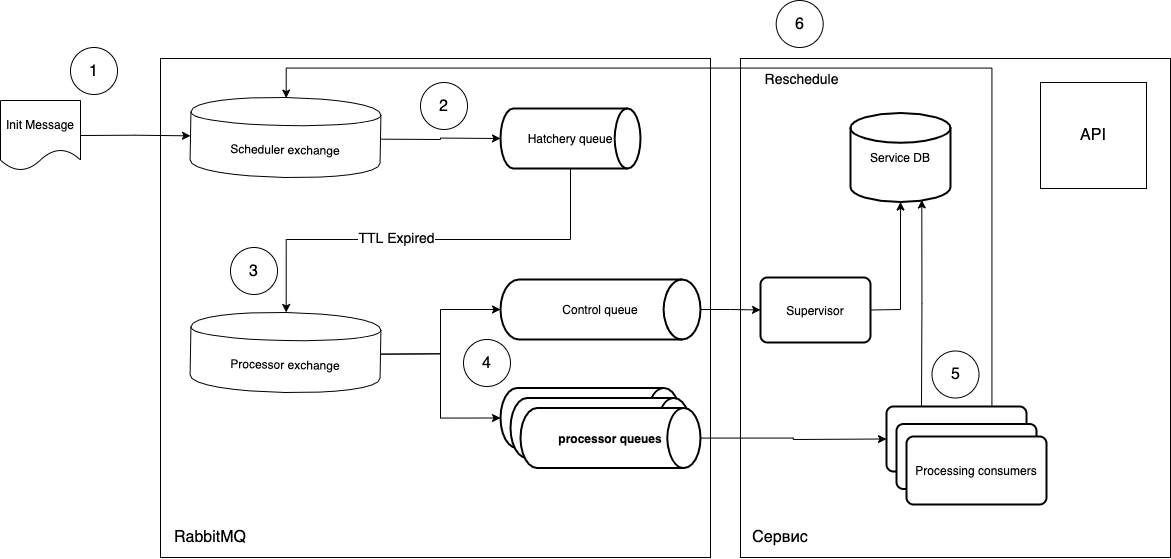
vou tentar explicar o que é o quê.
- As tarefas são enviadas na forma de uma mensagem para a troca do Scheduler.
- O
routing_keysoftware entra na fila necessária do Hatchery, que possui um parâmetromessage_ttl, bem como a conexão com a troca do Processador como uma troca de cartas comerciais. A fila de "maturação" não está associada ao tipo de tarefas, ela apenas desempenha o papel de um "cronômetro", ou seja, você pode criar quantas filas precisar de períodos e administrarrouting_key. - Como a fila não tem ouvintes, as mensagens após "amadurecer" na fila vão para a troca do processador.
- Em seguida, o consumidor livre (consumidor de processamento) pega a mensagem e executa. Após a execução, o ciclo é repetido se necessário.
Qual é a vantagem de tal esquema?
- Execução em fases, ou seja, uma nova tarefa não será processada se a anterior não tiver sido concluída.
- Um único ouvinte (consumidor), ou seja, você pode criar workers universais e especializados. Ajustado simplesmente aumentando o número de pods necessários.
- Implante novas tarefas sem interromper o trabalho das atuais. Tudo que você precisa fazer é atualizar suavemente os pods do listener e enviar a mensagem apropriada para a fila. Ou seja, você pode criar pods com um novo código, que lidará com novas mensagens, e os processos atuais permanecerão nos pods antigos. Isso nos dá uma atualização perfeita.
- Você pode usar código assíncrono e qualquer infraestrutura, embora seja independente da pilha.
- Você pode controlar a execução de tarefas no nível
ack/ nativorejecte também obter uma fila opcional adicional (fila de controle) que pode rastrear o ciclo de vida das tarefas.
O circuito acabou por ser bastante simples, criamos rapidamente um protótipo funcional. E o código é lindo. Basta marcar a função de retorno de chamada com um decorador simples que controla o ciclo de vida da mensagem.
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
Agora usamos esse esquema para realizar apenas tarefas sequenciais periódicas, mas também pode ser usado quando é importante iniciar a execução de uma tarefa em um horário específico, sem deslocar o tempo para a própria execução. Para isso, basta reagendar a tarefa depois que a mensagem chegar ao supervisor.
É verdade que essa abordagem tem custos indiretos adicionais. Você precisa entender que em caso de erro, a mensagem voltará para a fila, outro trabalhador irá buscá-la e imediatamente iniciará a execução. Portanto, você precisa separar o tratamento de erros de acordo com o grau de criticidade e pensar com antecedência sobre o que fazer com a mensagem em caso deste ou daquele erro.
Opções possíveis:
- O erro se corrigirá (por exemplo, é um erro do sistema): envie
noacke repita o tratamento de erros. - Erro de lógica de negócios: você precisa interromper o ciclo - enviar
ack. - O erro do ponto 1 é repetido com muita frequência: envenenamos
rejecte sinalizamos os desenvolvedores. Existem opções aqui. Você pode criar uma fila de cartas de negociação para as mensagens a serem depositadas para retornar a mensagem após a análise, ou você pode usar a técnica de repetição (especificarmessage_ttl).
Exemplo de decorador:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
Este esquema está a funcionar connosco há meio ano, é bastante fiável e praticamente não requer atenção. O travamento do aplicativo não interrompe o planejador e apenas atrasa ligeiramente a execução das tarefas.
Não há vantagens sem desvantagens. Este esquema também tem uma vulnerabilidade crítica. Se algo aconteceu ao RabbitMQ e as mensagens desapareceram, você precisa verificar manualmente o que foi perdido e iniciar o loop novamente. Mas esta é uma situação extremamente improvável na qual você terá que pensar sobre este serviço por último :)
PS Se o tópico de agendamento de tarefas periódicas parece interessante para você, então no próximo artigo, eu contarei a você com mais detalhes como automatizamos a criação de fila, bem como sobre o Supervisor.
Links: