
Uma importante tarefa da codologia no processamento de fluxos de informação de mensagens codificadas nos canais de sistemas de comunicação e computador é a separação dos fluxos e sua seleção de acordo com as características dadas. O fluxo dedicado é dividido em mensagens distintas, sendo que para cada uma delas é realizada uma análise aprofundada para estabelecer o código e suas características, seguida da decodificação e acesso à semântica da mensagem.
Assim, por exemplo, para um determinado código Reed-Solomon (código PC), você deve definir:
- o comprimento n da palavra-código (bloco);
- o número de informações k e símbolos de verificação Nk;
- um polinômio irredutível p (x) definindo um corpo finito GF (2 r );
- elemento primitivo α de um corpo finito;
- gerar polinômio g (x);
- parâmetro j do código;
- intercalação usada;
- a seqüência de transmissão de palavras-código ou símbolos para o canal e alguns outros.
Aqui, um problema particular ligeiramente diferente é considerado no trabalho - a modelagem do próprio código do PC, que é a parte principal central do problema de análise de código acima.
Descrição do código do PC e suas características
Por conveniência e uma melhor compreensão da essência do dispositivo de código para PC e do processo de codificação, apresentamos primeiro os conceitos e termos básicos (elementos) do código.
Os códigos Reed - Solomon (código RS) podem ser interpretados como códigos BCH não binários (Bose - Chowdhury - Hawkingham), os valores dos símbolos de código dos quais são retirados do campo GF (2 r ), ou seja, os símbolos de informação r são exibidos como um elemento separado do campo. Os códigos de Reed-Solomon são códigos cíclicos sistemáticos não binários lineares cujos símbolos são sequências de r bits, onde r é um número inteiro positivo maior que 1.
Os códigos de Reed-Solomon (n, k) são definidos nos símbolos de r bits para todos os n e k, para o qual:
0 <k <n <2 r + 2, onde
k é o número de símbolos de informação a serem codificados,
n é o número de símbolos de código no bloco codificado.
Para a maioria dos códigos Reed-Solomon (n, k); (n, k) = (2 r –1, 2 r –1–2 ∙ t), onde
t é o número de símbolos de erro que o código pode corrigir e
n - k = 2t é o número de símbolos de verificação.
O código Reed-Solomon tem a maior distância mínima (o número de caracteres que distinguem as sequências) possível para um código linear. Para códigos Reed-Solomon, a distância mínima é definida como segue: dmin = n - k +1.
Definição . Código de PC sobre o campo GF (q = m ), com comprimento de bloco n = q m-1, corrigindo t erros, é o conjunto de todas as palavras-código u (n) sobre GF (q) para as quais 2t componentes de espectro consecutivos com númerosigual a 0.
O fato de que 2t potências consecutivas de α são raízes do polinômio gerador g (x) ou que o espectro contém 2t componentes zero consecutivos é uma propriedade importante do código que permite que t erros sejam corrigidos.
Polinômio de informação Q. Especifica o texto da mensagem, que é dividido em blocos (palavras) de comprimento constante e digitalizado. É isso que deve ser transmitido no sistema de comunicação.
A geração do polinômio g (x) de um código de PC é um polinômio que transforma os polinômios de informação (mensagens) em palavras de código multiplicando Q · g (x) = = u (n) sobre GF (q).
O polinômio de verificação h (x) permite estabelecer a presença de caracteres distorcidos em uma palavra.
Síndrome polinomialS (z). Um polinômio contendo componentes correspondentes a posições erradas. Calculado para cada palavra recebida pelo decodificador.
Polinômio de erro E. Um polinômio com comprimento igual ao da palavra-código, com valores zero em todas as posições, exceto para aqueles que contêm distorções dos símbolos da palavra-código.
O polinômio localizador de erros Λ (z) fornece raízes que indicam as posições dos erros nas palavras recebidas pelo lado receptor do canal de comunicação (decodificador). Suas raízes podem ser encontradas por tentativa e erro, ou seja, substituindo por sua vez todos os elementos do campo até que Λ (z) se torne igual a zero.
O polinômio dos valores de erro Ω (z) ≡Λ (z) S (z) (modz 2t ) é módulo comparável z 2tcom o produto do polinômio localizador de erros pelo polinômio sindrômico.
Polinômio irredutível do campo p (x). Os campos finitos não existem para qualquer número de elementos, mas apenas se o número de elementos for um número primo p ou uma potência q = p m de um número primo. No primeiro caso, o campo é denominado simples (seus elementos são o resíduo dos números módulo um p primo), no segundo, é uma extensão do campo primo correspondente (seus q elementos dos polinômios de grau m-1 ou menos são os resíduos dos polinômios módulo do polinômio p (x) de grau m)
Polinômio primitivo . Se a raiz de um polinômio irredutível do campo é um elemento primitivo α, então p (x) é chamado de polinômio primitivo irredutível .
No decurso da descrição das ações com o código PC, precisaremos nos referir repetidamente ao campo de Galois, portanto, imediatamente aqui colocaremos uma planilha com os elementos deste campo com diferentes representações dos elementos (número decimal, vetor binário, polinômio, grau de um elemento primitivo ).
Tabela II - Características dos elementos do campo finito da extensão GF (2 4 ), polinômio irredutível p (x) = x 4 + x + 1, elemento primitivo α = 0010 = 2 10

Exemplo 1 . Sobre um campo finito GF (2 4 ), um polinômio de campo irredutível p (x) = x 4 + x + 1 é dado, um elemento primitivo α = 2, e um (n, k) - código Reed-Solomon (código PC) é dado. A distância do código deste código é d = n - k + 1 = 7. Este código pode corrigir até três erros no bloco (palavra-código) da mensagem.
O polinômio gerador g (z) do código tem grau m = nk = 15-9 = 6 (suas raízes são 6 elementos do campo GF (2 4 ) em notação decimal, a saber, elementos 2, 3, 4, 5, 6, 7) e é determinado pela proporção, ou seja, polinômio em z com coeficientes (elementos) de GF (2 4 ) na representação decimal para i = 1 (1) 6. No código PC considerado 2 9 = 512 palavras-código.
Codificação de mensagens para PC
Na tabela II, essas raízes também têm uma representação de poder ...

Aqui z é uma variável abstrata e α é um elemento primitivo do campo, por meio de suas potências todos (16) os elementos do campo são expressos. A representação polinomial de elementos de campo usa a variável x.
O cálculo do polinômio gerador g (x) = A B do código PC é realizado em partes (três colchetes cada):

A representação vetorial (através dos coeficientes g (z) pelos elementos de campo em representação decimal) do polinômio gerador tem a forma
g (z) = G <7> = (1, 11, 15, 5, 7, 10, 7).
Após a geração do polinômio gerador do código PC orientado para a detecção e correção de erros, uma mensagem é definida. A mensagem é apresentada em formato digital (por exemplo, código ASCII), a partir do qual ocorre a transição para representação polinomial ou vetorial.
Um vetor de informação (palavra de mensagem) possui k - componentes de (n, k). No exemplo k = 9, o vetor é de 9 componentes, todos os componentes são elementos do campo GF (2 4 ) na representação decimal Q <9> = (11, 13, 9, 6, 7, 15, 14, 12, 10) ...
A partir desse vetor, a palavra de código u é formada<15> é um vetor com 15 componentes. Palavras-código, como os próprios códigos, são sistemáticas e não sistemáticas. Uma palavra-código não sistemática é obtida multiplicando o vetor de informação Q pelo vetor correspondente ao polinômio gerador

Após as transformações, obtemos uma palavra-código não sistemática (vetor) na forma
Q · g = <11, 15, 3, 9, 6, 14, 7, 5, 12, 15, 14, 3, 3, 7, 1>.
Na codificação sistemática, uma mensagem (vetor de informação) é representada por um polinômio Q (z) na forma Q (z) = q (z) g (z) + R (z), onde o grau degR (z) <m = 6. Depois disso, para o vetor Q à direita é atribuído ao resto R (todos na forma decimal). Isso é feito assim.
O polinômio Q é deslocado para os dígitos superiores pelo valor m = n - k, que é obtido multiplicando Q (z) por Z n - k (no exemplo Z n - k = Z 6 ) e após o deslocamento, a divisão Q (z) Z n - k por g (z). Como resultado, encontre o restante da divisão R (z). Todas as operações são realizadas no campo GF (2 4 )
(11, 13, 9, 6, 7, 15, 14, 12, 10, 0, 0, 0, 0, 0, 0) =
= (1, 11, 15, 5, 7, 10, 7) ( 11, 15, 9, 10,12,10,10,10,10,3) + (1, 2, 3, 7, 13, 9) = G · S + R.
O restante da divisão dos polinômios é calculado da maneira usual ( ver canto aqui Exemplo 6 ). A divisão é realizada de acordo com o seguinte padrão: Seja Q = 26, g (z) = 7 então 26 = 7 3 + R (z), R (z) = 26 -7 3 = 26-21 = 5. Cálculo do restante R (z ) na divisão de polinômios. Atribuímos o resto R ao vetor Q à direita
e obtemos u <15> - uma palavra-código em uma forma sistemática. Esta visualização contém claramente uma mensagem de informação nos k bits de ordem superior da palavra-código
u <15> = (11,13,9,6,7,15,14,12,10; 1, 2, 3, 7, 13, 9)
Os dígitos do vetor são numerados da direita para a esquerda de 0 (1) 14. Os seis bits menos significativos à direita são os de verificação.
Decodificando códigos Reed-Solomon
Depois de receber um bloco, o decodificador processa cada bloco (palavra-código) e corrige erros que ocorreram durante a transmissão ou armazenamento. O decodificador divide o polinômio resultante pelo polinômio gerador do código RS. Se o resto for zero, nenhum erro foi encontrado, caso contrário, ocorrerão erros.
Um decodificador de PC típico executa cinco etapas em um loop de decodificação, a saber:
- Cálculo do polinômio sindrômico (seus coeficientes), erros são encontrados.
- A equação chave de Pade é resolvida - calculando os valores de erro e suas posições nos locais correspondentes.
- O procedimento de Chen é implementado - encontrar as raízes do polinômio localizador de erros.
- O algoritmo de Forney é usado para calcular o valor do erro.
- As correções são feitas em palavras-código distorcidas;
O ciclo termina extraindo a mensagem das palavras de código (removendo o código).
Cálculo da síndrome.
A geração da síndrome a partir da palavra-código recebida é a primeira etapa no processo de
decodificação. Aqui as síndromes são calculadas e é determinado se há erros na palavra-código recebida ou não.A
decodificação das palavras-código do PC pode ser organizada de diferentes maneiras. Os métodos clássicos incluem a decodificação usando algoritmos que operam no domínio do tempo ou da frequência, que usam o cálculo da síndrome ou não. Sem nos aprofundarmos na teoria desse problema, optaremos pela decodificação com o cálculo das síndromes de palavras-código no domínio do tempo.
Detecção de distorção
Sindrômico Onde o vetor é determinado sequencialmente para cada uma das palavras-código recebidas pelo decodificador em sua entrada. Com valores zero dos componentes do vetor síndrome, o decodificador considera que não há erro na palavra recebida. Se por pelo menos um, então o decodificador conclui que há erros no vetor de código e passa a identificá-los, que é a primeira etapa da operação do decodificador.
O cálculo da
multiplicação polinomial sindrômica no lado receptor da palavra-código C pela matriz de verificação H pode resultar em dois resultados:
- vetor da síndrome S = 0, que corresponde à ausência de erros no vetor C;
- vetor da síndrome S ≠ 0, que significa a presença de erros (um ou mais) nos componentes do vetor C.
O segundo caso é de interesse.
O vetor de código com erros é representado como C (E) = C + E, E é o vetor de erro. Então
Os componentes Sj da síndrome são determinados pela relação de soma
para n = q-1 e j = 1 (1) m = nk, ou pelo esquema de Horner:
Exemplo 2 . Deixe o vetor de erro ter a forma = <0 0 0 0 12 0 0 0 0 0 0 0 8 0 0 0>. Ele mutila os caracteres nas 3ª e 10ª posições no vetor de código. Os valores de erro são 8 e 12, respectivamente - esses valores também são elementos do campo GF (2 4 ) e são fornecidos em notação decimal (Tabela P). No vetor E, as posições são numeradas das mais baixas da direita para a esquerda, a partir de 0 (1) 14.
Vamos agora formar um vetor de código com dois erros no 3º bit e no 10º com os valores 8 e 12, respectivamente. Isso é feito somando no GF (2 4) de acordo com as regras da aritmética deste campo. A soma dos elementos do campo com zero não altera seu valor. Valores diferentes de zero (elementos de campo) são somados após convertê-los em uma representação polinomial, como os polinômios geralmente são somados, mas os coeficientes para o desconhecido são reduzidos mod 2.
Após o resultado da soma ser obtido, eles são novamente convertidos para representação decimal, tendo passado anteriormente pela representação de potência

O seguinte mostra o cálculo de valores corrompidos por erro nas posições 10 e 3 da palavra-código:
O decodificador executa cálculos de acordo com a fórmula geral para os componentes Sj, j = 1 (1) m. Aqui (no modelo) usamos a relação, uma vez que especificamos (simulamos) no próprio programa, termos diferentes de zero são obtidos apenas para i = 3 ei = 10.

Abaixo, mostraremos especialmente os cálculos por esta fórmula na forma expandida.
Matriz de verificação de código de PC
Assim que for formulado o polinômio gerador do código, torna-se possível construir uma matriz de verificação para palavras de código, bem como determinar o número de erros a serem corrigidos ( veja aqui, o decodificador ). Vamos construir uma matriz auxiliar [7 × 15], a partir da qual duas matrizes de verificação de paridade diferentes podem ser obtidas: as seis primeiras linhas são uma e as seis últimas linhas são as outras.
A própria matriz é formada de uma maneira especial. As duas primeiras linhas são óbvias, a terceira linha e todas as subsequentes são obtidas subtraindo da linha anterior (segunda) um segmento de números naturais 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 mod 15. Quando ocorre um valor zero, ele é substituído por 15, os resíduos negativos são convertidos em positivos.

Cada matriz corresponde ao seu próprio polinômio gerador para codificação sistemática e não sistemática.
Determinação dos coeficientes do polinômio sindrômico
A seguir, determinaremos os coeficientes do polinômio sindrômico para j = 1 (1) 6.
Com relação a uma palavra-código com comprimentochegando à entrada do decodificador, presumimos que ele está distorcido por erros.
Para identificar o vetor de erros, você precisa saber o seguinte:
- o número de posições distorcidas na palavra de código
- ;
- números (posição) de posições distorcidas em uma palavra de código ;
- valores de distorção ...
Como o vetor da síndrome (polinomial) S é calculado e usado posteriormente? Seu papel na decodificação de palavras-código é muito significativo. Vamos ilustrar isso com um exemplo numérico.
Exemplo 3 . (Cálculo dos componentes do vetor síndrome )

então no final nós temos = <8,13,7,13,15,15>
Para uma consideração mais aprofundada, apresentamos novos conceitos. O valor queserá chamado de localizador de erros, aqui o símbolo de palavra-código distorcido na posição , α é um elemento primitivo do campo GF (2 4 ).
O conjunto de localizadores de erros para uma palavra-código específica é considerado abaixo como os coeficientes do polinômio localizador de erros σ (z), raízes quais são os valores inverso para localizadores.
Além disso, as expressõesdesaparecer.
sempre termo livre da equação sempre termo livre da equação ...
O grau do polinômio dos localizadores de erro é igual av - o número de erros e não excede o valor...
Todos os caracteres distorcidos estão em posições diferentes da palavra, portanto, entre os localizadores, não pode haver elementos de campo repetidos e o polinômio σ (z) = 0 não tem raízes múltiplas.
Por conveniência de escrita, os valores de erro serão redesignados pelo símbolo... Para os coeficientes do polinômio sindrômico, foram consideradas previamente equações não lineares. Em nosso caso, v = 1 é a origem dos componentes da síndrome.
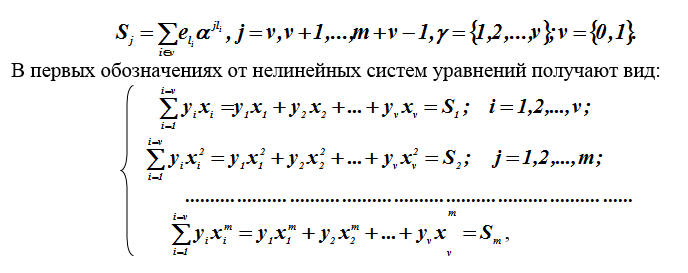
Onde São quantidades desconhecidas, e - parâmetros conhecidos, calculados na primeira etapa de decodificação (componentes do vetor da síndrome).
Os métodos para resolver esses sistemas de equações não lineares são desconhecidos, mas as soluções são encontradas usando truques (soluções alternativas). A transição para o sistema de Hankel (Toeplitz) de equações lineares com relação aos coeficienteso polinômio localizador.
Conversão para um sistema de equações lineares
para uma equação do polinômio localizador de erro, o valor de suas raízes é substituído ... Nesse caso, o polinômio desaparece. Uma identidade é formada, ambos os lados são multiplicados por, Nós temos:
...
Nós obtemos tais igualdades
Somamos essas igualdades sobre todos para o qual essas igualdades são satisfeitas. Como o polinômio σ (z) tem v raízes, abra os colchetes e transfira os coeficientes por sinal do valor:

Nessa igualdade, de acordo com o sistema de equações não lineares dado
anteriormente, cada soma é igual a um dos componentes do vetor da síndrome. Portanto, ele conclui que, com relação aos coeficientes você pode escrever um sistema de equações lineares.

Os sinais "-" ao calcular sobre um campo binário são omitidos, pois correspondem a "+". O sistema resultante de equações lineares é Hankel e corresponde a uma matriz com dimensões mordeu.

Esta matriz não é degenerada se o número de erros na palavra-código C (E) for estritamente igual a , ou seja, a capacidade de imunidade a ruído deste código não é violada.
Resolvendo um sistema de equações lineares
O sistema resultante de equações lineares contém os coeficientes como desconhecidos o polinômio localizador de erros para a palavra-código C (E). Os componentes previamente calculados do vetor sindrômico são considerados conhecidos... Aqui t é o número de erros na palavra, m é o número de posições de verificação na palavra.
Existem diferentes métodos para resolver o sistema formado.
Observe que a matriz (Hankel) não é degenerada para dimensões limitadas pelo número de erros permitidos em uma única palavra (menos de 0,5 m). Nesse caso, o sistema de equações é resolvido de forma única e o problema pode ser reduzido simplesmente à inversão da matriz de Hankel. Seria desejável remover a limitação da dimensão das matrizes, ou seja, sobre um campo infinito.
Métodos para resolver o sistema Hankel de equações lineares são conhecidos em campos infinitos:
- Trincheira iterativa - Berlekamp - Método Messi (método TBM); (1)
- Peterson determinístico direto - Gorenstein - Zierler; (APS - método); (2)
- Método de Sugiyama usando o algoritmo de Euclides para encontrar GCD (método C). (3)
Sem considerar outros métodos, vamos optar pelo método TBM. A motivação para a escolha é a seguinte.
O método (PHC) é simples e bom, mas para um pequeno número de erros corrigíveis, o método C é difícil de implementar em um computador e é publicado de forma limitada (coberto) nas fontes, embora o método C, como o método TBM de acordo com o conhecido polinômio de síndromes S (z), forneça solução da equação de Pade sobre o campo de Galois. Esta equação é formada pelo polinômio dos localizadores de erro σ (z) e o polinômio ω (z), na teoria da codificação é chamada de equação chave de Pade:
...
A solução para a equação chave é o conjunto raízes do polinômio σ (z) e, consequentemente, os localizadores , ou seja, posições de erro. Valores de erro (magnitudes) são determinados a partir da fórmula de Forney na forma

Onde e São os valores dos polinômios σ (z) e ω (z) no ponto inverso à raiz do polinômio σ (z);
i é a posição do erro; - a derivada formal do polinômio σ (z) em relação a z;
Derivada formal de um polinômio em um corpo finito
Existem diferenças e semelhanças para a derivada em relação a uma variável no campo dos números reais e a derivada formal em um corpo finito. Considere o polinômio

São os elementos do campo, i = 1 (1) n
elementos do campo. Um código sobre um campo real GF (2 4 ) é fornecido. A derivada em relação a z é:

Em um campo real infinito, as operações se multiplicam por n e somam n vezes que coincidem. Para campos finitos, a derivada é definida de forma diferente.
A derivada é determinada de forma semelhante pela razão:

onde ((i)) = 1 + 1 + ... + 1, (i) vezes, somados de acordo com as regras de um corpo finito: o sinal + denota a operação "soma tantas vezes", ou seja, elemento repetir 2 vezes, elemento repetir 3 vezes, elemento repita n vezes.
É claro que esta operação não coincide com a operação de multiplicação em um corpo finito. Em particular, nos campos GF (2 r ), a soma de um número par de termos idênticos é considerada mod2 e zerada, e o número ímpar é igual ao próprio termo sem alterações. Portanto, no campo GF (2 r ), a derivada assume a forma

a segunda e mais alta derivada uniforme neste campo são iguais a zero.
Sabe-se da álgebra que se um polinômio tem raízes múltiplas (de multiplicidade p), então a derivada do polinômio terá a mesma raiz, mas com multiplicidade p-1. Se p = 1, então f (z) ef '(z) não têm raiz comum. Portanto, se um polinômio e sua derivada têm um divisor comum, então há uma raiz múltipla. Todas as raízes da derivada f '(z) são múltiplas em f (z).
Método de solução de equação chave
TMB (Trench-Berlekampa-Messi) é um método para resolver a equação chave. O algoritmo iterativo fornece a definição dos polinômios σ (z) e ω (z), e a solução da equação de Pade (chave).
Dados iniciais: coeficientes polinomiaisgrau n-1.
Objetivo. Definição de forma explícita (analítica) dos polinômios σ (z) e ω (z).
O algoritmo usa a seguinte notação: j - número da etapa, - o grau do polinômio, - expansão do polinômio em potências e - variáveis e funções intermediárias na j-ésima etapa do algoritmo;
As condições iniciais devem ser especificadas, uma vez que a recursão é usada aqui.
Condições iniciais:

Exemplo 4 . Execução de um algoritmo iterativo para o vetor
S = (8,13,7,13,15,15). Polinômios são definidos e ...
Tabela 2 - Cálculo de polinômios localizadores de erro
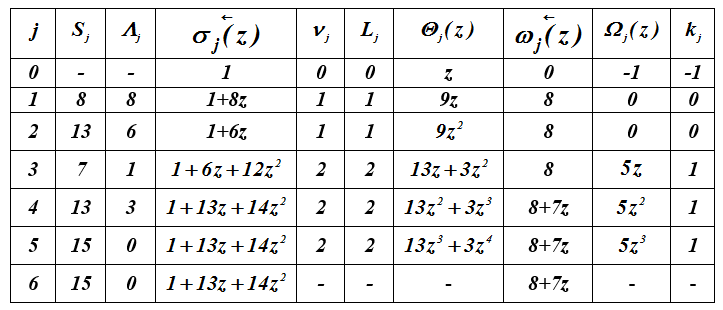

tão , = 7z + 8.
O polinômio localizador de erro σ (z) sobre o campo GF (2 4 ) com o polinômio irredutível p (x) = x 4 + x + 1 tem raízes
e , é fácil verificar isso por verificação direta, ou seja, e ... Substituição de raiz em
=
=;
=
=...
Tomando a derivada formal de σ (z), obtemos σ_2 (z) = 2 14 + 13 = 13, uma vez que 14z é obtido na soma 2 vezes e desaparece mod 2.
Usando a fórmula de Forney, encontraremos expressões para calcular os valores de erro...

Substituindo os valores i = 3 e i = 10 posições na última expressão,
encontramos
= =;
= =...
A arquitetura de construção de um pacote de software
Para construir um pacote de software, propõe-se usar a seguinte solução arquitetônica. O pacote de software é implementado como um aplicativo com uma interface gráfica de usuário.
Os dados iniciais do pacote de software são um fluxo digital de informações descarregadas usando um dump de um arquivo. Para a conveniência da análise e clareza da operação complexa, é suposto usar arquivos .txt.
O fluxo digital carregado é apresentado na forma de matrizes de dados, no decorrer do complexo trabalho no qual várias ações computacionais são aplicadas.
Em cada etapa da operação complexa, é possível visualizar os resultados intermediários do trabalho.
Os resultados da operação complexa do programa são apresentados na forma de dados numéricos exibidos em tabelas.
Os resultados da análise intermediária e final são salvos em arquivos.
Esquema de funcionamento do complexo de software A
operação com o complexo começa com o carregamento de um fluxo digital usando um despejo de um arquivo. Depois de baixado, o usuário é apresentado a uma representação visual do conteúdo binário do arquivo e seu conteúdo textual.
Dentro da estrutura desta interface, as seguintes tarefas funcionais devem ser implementadas:
- Baixe a mensagem original;
- Converter uma mensagem em um dump;
- Codificação da mensagem;
- Simulando uma mensagem interceptada
- Construção de espectros das palavras-código recebidas para análise da sua representação visual;
- Exibindo parâmetros de código.
Descrição do funcionamento do pacote de software
Ao iniciar o arquivo executável do programa, aparece na tela a janela mostrada na Figura 2, na qual é exibida a interface principal do programa.
A entrada do programa é um arquivo que precisa ser transmitido pelo canal de comunicação. Para sua transmissão através de canais de comunicação reais, a codificação é necessária - a adição de símbolos de verificação, necessários para a decodificação inequívoca de uma palavra no receptor-fonte. Para iniciar o complexo, você precisa selecionar o arquivo de texto desejado usando o botão “Carregar arquivo”. Seu conteúdo será exibido no campo inferior da janela principal do programa.
A representação binária da mensagem será apresentada no campo correspondente, a representação binária de palavras de informação - no campo “Representação binária de palavras de informação”.
O número de bits da mensagem original e o número total de palavras nela contidas são exibidos nos campos “Número de bits na mensagem transmitida” e “Número de palavras na mensagem transmitida”.
As informações formadas e as palavras-código são exibidas em tabelas no lado direito da janela principal do programa.
A janela do programa com resultados intermediários é mostrada na Figura 3.
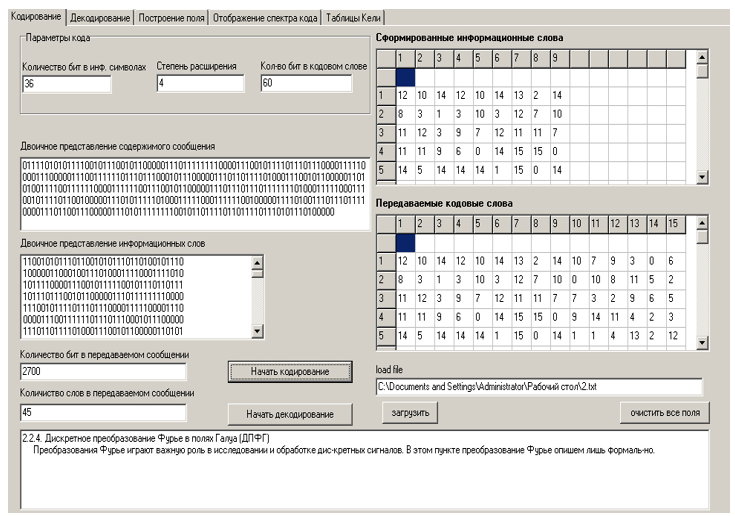
Figura 3 - Apresentação intermediária dos resultados do pacote de software

Figura 4. Resultados do download do arquivo de mensagem
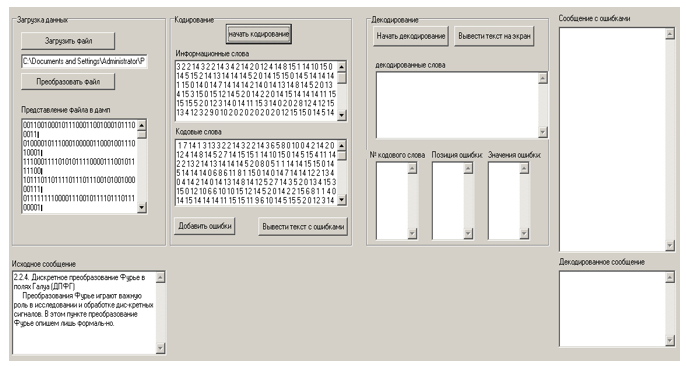
Figura 5. Resultados de codificação de arquivo

Figura 6. Saída de uma mensagem com erros inseridos.

Figura 7. Saída dos resultados da decodificação e a mensagem com erros introduzidos
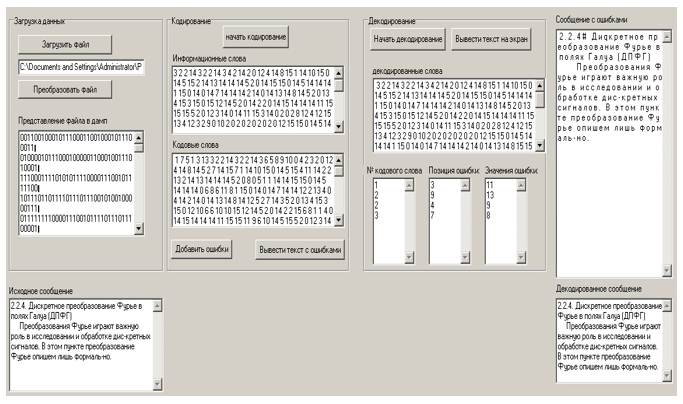
Figura 8. Saída da mensagem decodificada.
Conclusão
A NSA dos EUA é a principal operadora do sistema de interceptação global Echelon. O Echelon possui uma ampla infraestrutura, incluindo estações de rastreamento terrestre localizadas em todo o mundo. Quase todos os fluxos de informações mundiais são monitorados.
O estudo das possibilidades de acesso à semântica das mensagens de informação codificadas na atualidade da guerra de informação ativa, tanto no campo da tecnologia como na política, tornou-se o próximo desafio e uma das tarefas urgentes e exigidas de nosso tempo.
Na esmagadora maioria dos códigos, a codificação e a decodificação de mensagens (informações) são implementadas em uma base matemática rigorosa de campos de Galois estendidos finitos. Trabalhar com elementos de tais campos difere daqueles geralmente aceitos na aritmética e requer a escrita de procedimentos especiais para manipular elementos de campo ao usar ferramentas computacionais.
A obra oferecida à atenção dos leitores abre um pouco o véu do sigilo sobre tais atividades no âmbito das firmas, empresas e estados em geral.
Bibliografia
- . , . – .: , 1986. – 576 .
- - . , . . . , . – .: , 1979. – 744 .
- . . – .: , 1971. – 478 .
- .., .. . – .: , 1986. – 176 ., .
- . . . – .: , 2004. – 288 .
- .. . . – : - , 2005. – 147 .
- . ., .. . – : , 2001. – 60 .
- ., ., ., . . – .: , 1978. – 576 .
- . . . – .: . , 1990. – 288 .
- . ., .. « »/ . .26. . .. –. .: .. , 2007. – . 121-130.
- . ( 2. ). – . . . , 2002. – 97 .
- . . . – .: , 1987 – 120 .