
O objetivo deste artigo é compartilhar nossa primeira experiência com MLflow .
Começaremos nossa revisão do MLflow em seu servidor de rastreamento e continuaremos por todas as iterações do estudo. Em seguida, compartilharemos nossa experiência de conectar o Spark ao MLflow usando UDFs.
Contexto
Na Alpha Health, usamos aprendizado de máquina e inteligência artificial para capacitar as pessoas a cuidar de sua saúde e bem-estar. É por isso que os modelos de aprendizado de máquina estão no centro dos produtos de dados que desenvolvemos, e é por isso que nossa atenção foi chamada para MLflow, uma plataforma de código aberto que cobre todos os aspectos do ciclo de vida do aprendizado de máquina.
MLflow
O principal objetivo do MLflow é fornecer uma camada adicional sobre o aprendizado de máquina que permitiria aos cientistas de dados trabalhar com quase qualquer biblioteca de aprendizado de máquina ( h2o , keras , mleap , pytorch , sklearn e tensorflow ), levando seu trabalho para o próximo nível.
MLflow oferece três componentes:
- Acompanhamento - registro e consulta de experimentos: código, dados, configuração e resultados. É muito importante acompanhar o processo de criação do modelo.
- Projetos - formato de embalagem para executar em qualquer plataforma (por exemplo, SageMaker )
- Modelos é um formato comum para enviar modelos a várias ferramentas de implantação.
MLflow (alfa no momento em que este artigo foi escrito) é uma plataforma de código aberto que permite gerenciar o ciclo de vida do aprendizado de máquina, incluindo experimentação, reutilização e implantação.
Configurando MLflow
Para usar MLflow, você primeiro precisa configurar todo o ambiente Python, para isso usaremos PyEnv (para instalar Python no Mac, dê uma olhada aqui ) Assim podemos criar um ambiente virtual onde instalaremos todas as bibliotecas necessárias para rodar.
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```Instale as bibliotecas necessárias.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```Observação: estamos usando o PyArrow para executar modelos como UDFs. As versões PyArrow e Numpy precisaram ser corrigidas, pois as versões mais recentes eram conflitantes.
Iniciar IU de rastreamento
O rastreamento de MLflow nos permite registrar e fazer solicitações para experimentos usando Python e API REST . Além disso, você pode definir onde armazenar os artefatos do modelo (localhost, Amazon S3 , Azure Blob Storage , Google Cloud Storage ou servidor SFTP ). Como estamos usando AWS no Alpha Health, S3 será usado como o armazenamento para os artefatos.
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3://<bucket>/mlflow/artifacts/ \
--host localhost
--port 5000MLflow recomenda o uso de armazenamento de arquivos persistente. O armazenamento de arquivos é onde o servidor armazenará os metadados de execução e experimento. Ao iniciar o servidor, certifique-se de que aponta para o armazenamento persistente de arquivos. Aqui, vamos usá-lo apenas para fazer experiências
/tmp.
Lembre-se de que, se quisermos usar o servidor mlflow para executar experimentos antigos, eles devem estar presentes no armazenamento de arquivos. Porém, mesmo sem isso, poderíamos usá-los na UDF, pois só precisamos do caminho para o modelo.
Nota: Lembre-se de que a UI de rastreamento e o cliente modelo devem ter acesso ao local do artefato. Ou seja, independentemente do fato de a UI de rastreamento estar localizada na instância EC2, quando o MLflow é iniciado localmente, a máquina deve ter acesso direto ao S3 para escrever modelos de artefato.
A IU de rastreamento armazena artefatos em um intervalo S3
Modelos em execução
Assim que o servidor de rastreamento estiver em execução, você pode começar a treinar os modelos.
Como exemplo, usaremos a modificação do vinho do exemplo MLflow no Sklearn .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csvComo já dissemos, o MLflow permite que você registre parâmetros, métricas e artefatos de modelos para que você possa rastrear como eles se desenvolvem à medida que você itera. Esse recurso é extremamente útil, porque dessa forma podemos reproduzir o melhor modelo entrando em contato com o servidor de rastreamento ou entendendo qual código executou a iteração necessária usando os logs de hash commit do git.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")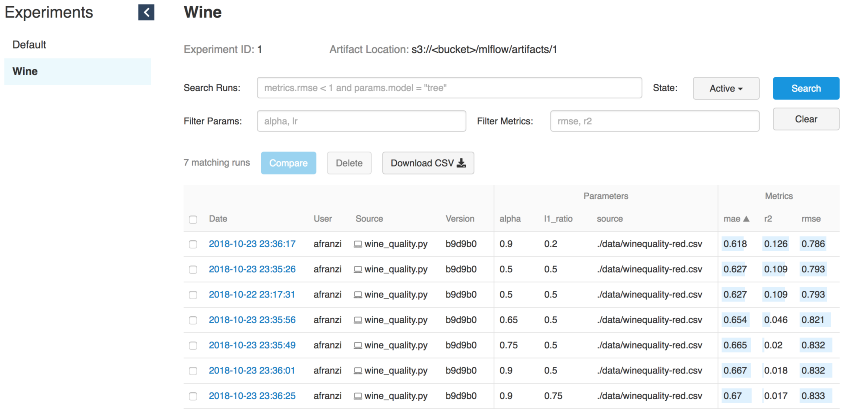
Iterações de vinho
Parte do servidor para o modelo
O servidor de rastreamento MLflow, iniciado com o comando “mlflow server”, tem uma API REST para rastrear inicializações e gravar dados no sistema de arquivos local. Você pode especificar o endereço do servidor de rastreamento usando a variável de ambiente "MLFLOW_TRACKING_URI" e a API de rastreamento MLflow entrará em contato automaticamente com o servidor de rastreamento neste endereço para criar / obter informações de lançamento, métricas de registro, etc.Para fornecer um servidor ao modelo, precisamos de um servidor de rastreamento em execução (consulte a interface de inicialização) e um ID de execução do modelo.
Fonte: Docs // Executando um servidor de rastreamento

ID de execução
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path modelPara veicular modelos usando a funcionalidade de veiculação MLflow, precisamos acessar a IU de rastreamento para obter informações sobre o modelo simplesmente especificando
--run_id.
Uma vez que o modelo se comunica com o Tracking Server, podemos obter o novo endpoint do modelo.
# Query Tracking Server Endpoint
curl -X POST \
http://127.0.0.1:5005/invocations \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Executando modelos do Spark
Apesar de o servidor de rastreamento ser poderoso o suficiente para servir modelos em tempo real, treiná-los e usar a funcionalidade de servir (fonte: mlflow // docs // models # local ), usar Spark (lote ou streaming) é uma solução ainda mais poderosa para conta de distribuição.
Imagine que você acabou de fazer um treinamento offline e depois aplicou o modelo de saída a todos os seus dados. É aqui que Spark e MLflow mostrarão seu melhor.
Instale o PySpark + Jupyter + Spark
Fonte: PySpark - Jupyter de introdução
Para mostrar como aplicamos modelos MLflow a dataframes Spark, precisamos configurar notebooks Jupyter para trabalhar junto com PySpark.
Comece instalando a versão estável mais recente do Apache Spark :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀Instale o PySpark e o Jupyter em um ambiente virtual:
pip install pyspark jupyterConfigure as variáveis de ambiente:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"Uma vez determinados
notebook-dir, podemos armazenar nossos cadernos na pasta desejada.
Lançamento do Jupyter do PySpark
Como pudemos configurar o Jupiter como o driver do PySpark, agora podemos executar os blocos de notas do Jupyter no contexto do PySpark.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
Conforme mencionado acima, o MLflow fornece uma função para registrar artefatos de modelo no S3. Assim que tivermos o modelo selecionado em nossas mãos, teremos a oportunidade de importá-lo como UDF utilizando o módulo
mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark - Produzindo previsões da qualidade do vinho
Até este ponto, falamos sobre como usar o PySpark com MLflow executando previsões da qualidade do vinho em todo o conjunto de dados do vinho. Mas e se você precisar usar os módulos Python MLflow do Scala Spark?
Também testamos isso dividindo o contexto do Spark entre Scala e Python. Ou seja, registramos o MLflow UDF em Python e o usamos a partir do Scala (sim, talvez não seja a melhor solução, mas o que temos).
Scala Spark + MLflow
Para este exemplo, adicionaremos o Kernel Toree ao Júpiter existente.
Instale Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```Como você pode ver no bloco de notas anexado, o UDF é compartilhado entre o Spark e o PySpark. Esperamos que esta parte seja útil para aqueles que amam Scala e desejam implantar modelos de aprendizado de máquina para produção.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf.<locals>.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Próximos passos
Apesar de estar em Alpha no momento em que este livro foi escrito, o MLflow parece muito promissor. A mera capacidade de executar várias estruturas de aprendizado de máquina e usá-las a partir de um único terminal leva os sistemas de recomendação para o próximo nível.
Além disso, o MLflow aproxima engenheiros de dados e cientistas de dados ao criar uma camada comum entre eles.
Depois de fazer essa pesquisa no MLflow, temos certeza de que iremos usá-lo para nossos pipelines Spark e sistemas de recomendação.
Seria bom sincronizar o armazenamento de arquivos com o banco de dados em vez do sistema de arquivos. Dessa forma, precisamos obter vários endpoints que podem usar o mesmo armazenamento de arquivo. Por exemplo, use várias instâncias de Prestoe Athena com a mesma metastore Glue.
Para resumir, gostaria de agradecer à comunidade MLFlow por tornar nosso trabalho com dados mais interessante.
Se você estiver jogando com MLflow, sinta-se à vontade para nos escrever e dizer como você o usa, e ainda mais se você o usar em produção.
Saiba mais sobre os cursos:
Aprendizado de máquina. Curso básico de
aprendizado de máquina. Curso avançado
Consulte Mais informação: