
Conto por experiência própria o que foi útil, onde e quando. Pesquisa e tese, para que ficasse claro o que e onde cavar a seguir - mas aqui eu tenho uma experiência pessoal exclusivamente subjetiva, talvez tudo seja completamente diferente com você.
Por que é importante conhecer e ser capaz de lidar com linguagens de consulta? Em sua essência, na Ciência de Dados existem vários estágios mais importantes de trabalho e o primeiro e mais importante (sem ele, nada funcionará, é claro!) É a aquisição ou recuperação de dados. Na maioria das vezes, os dados de alguma forma estão armazenados em algum lugar e você precisa "obtê-los" de lá.
As linguagens de consulta permitem apenas que você extraia esses mesmos dados! E hoje vou falar sobre essas linguagens de consulta que foram úteis para mim e vou mostrar onde e como exatamente - por que é necessário estudar.
No total, haverá três blocos principais de tipos de consultas a dados, que analisaremos neste artigo:
- Linguagens de consulta "padrão" são o que eles geralmente entendem quando falam sobre uma linguagem de consulta como álgebra relacional ou SQL.
- Linguagens de consulta de script, como truques pandas python, numpy ou script de shell.
- Linguagens de consulta para gráficos de conhecimento e bancos de dados de gráficos.
Tudo o que está escrito aqui é apenas uma experiência pessoal, que veio a calhar, com uma descrição das situações e "porque era necessário" - todos podem experimentar como situações semelhantes podem te encontrar e tentar preparar-se para elas com antecedência, tendo lidado com estas línguas antes de ter de para (urgentemente) se inscrever em um projeto ou mesmo entrar em um projeto onde eles são necessários.
Linguagens de consulta "padrão"
Linguagens de consulta padrão são precisamente no sentido em que normalmente pensamos nelas quando falamos sobre consultas.
Álgebra relacional
Por que a álgebra relacional é necessária hoje? Para ter uma boa ideia de por que as linguagens de consulta são organizadas de determinada maneira e para usá-las conscientemente, você precisa entender o núcleo subjacente.
O que é álgebra relacional?
A definição formal é a seguinte: álgebra relacional é um sistema fechado de operações sobre relações em um modelo de dados relacional. Mais humanamente, é um sistema de operações sobre tabelas, de forma que o resultado também seja sempre uma tabela.
Veja todas as operações relacionais neste artigo da Habr - aqui descrevemos por que você precisa saber e onde isso é útil.
Pelo que?
Você começa a entender para que as linguagens de consulta são geralmente usadas e quais operações estão por trás das expressões de linguagens de consulta específicas - geralmente oferece uma compreensão mais profunda do que e como funcionam nas linguagens de consulta.
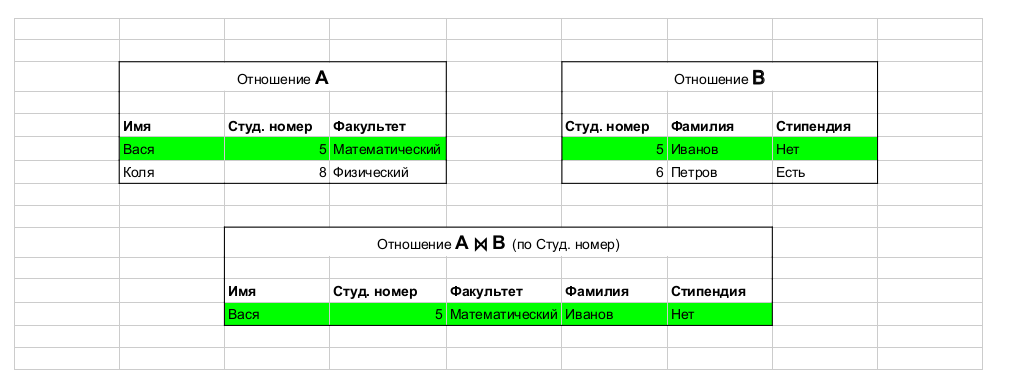
Retirado deste artigo. Exemplo de operação: join, que une tabelas.
Materiais de estudo:
um bom curso introdutório de Stanford . Em geral, há muitos materiais sobre álgebra relacional e teoria - Coursera, Udacity. Também existe uma grande quantidade de materiais online, incluindo bons cursos acadêmicos . Meu conselho pessoal é entender muito bem a álgebra relacional - esta é a base.
SQL

Retirado deste artigo.
O SQL é, na verdade, uma implementação da álgebra relacional - com uma advertência importante, o SQL é declarativo! Ou seja, escrevendo uma consulta na linguagem da álgebra relacional, você realmente diz como contar - mas com SQL você especifica o que deseja extrair, e então o SGBD já gera expressões (efetivas) na linguagem da álgebra relacional (sua equivalência é conhecida por nós sob o teorema de Codd ) ...
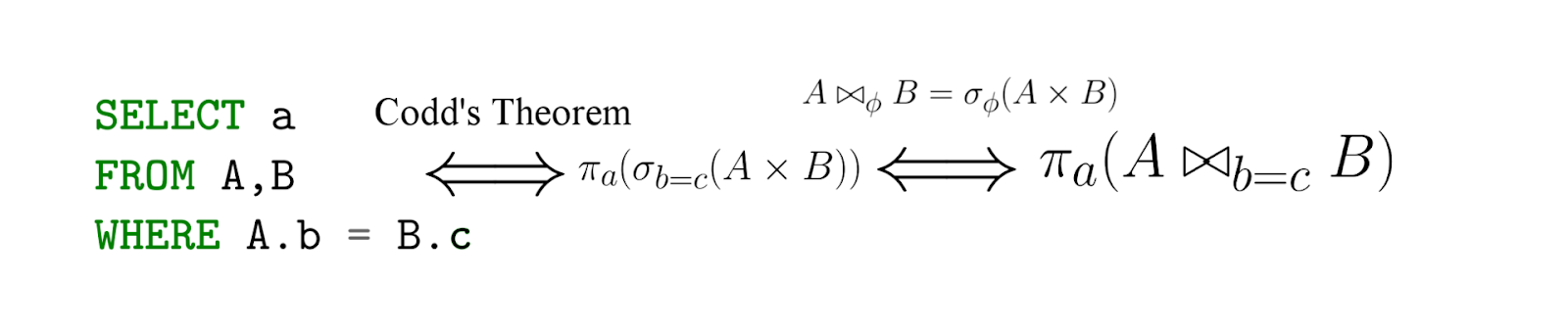
Retirado deste artigo.
Pelo que?
SGBDs relacionais: Oracle, Postgres, SQL Server, etc ainda estão virtualmente em todos os lugares e há uma chance incrivelmente alta de que você tenha que interagir com eles, o que significa que você terá que ler SQL (o que é muito provável) ou escrever nele ( também não é improvável).
O que ler e aprender
Dos mesmos links acima (sobre álgebra relacional), existe uma quantidade incrível de material, como este .
A propósito, o que é NoSQL?
"Vale a pena enfatizar mais uma vez que o termo 'NoSQL' tem uma origem totalmente espontânea e não tem uma definição geralmente aceita ou uma instituição científica por trás dele." O artigo correspondente sobre Habré.
Na verdade, as pessoas perceberam que um modelo relacional completo não é necessário para resolver muitos problemas, especialmente para aqueles onde, por exemplo, o desempenho é fundamental e certas consultas simples com agregação dominam - é fundamental ler rapidamente as métricas e gravá-las no banco de dados, e a maioria dos recursos são relacionais. acabou sendo não apenas desnecessário, mas também prejudicial - por que normalizar algo se isso vai estragar o mais importante para nós (para alguma tarefa específica) - desempenho?
Além disso, frequentemente eram necessários esquemas flexíveis em vez dos esquemas matemáticos fixos do modelo relacional clássico - e isso simplifica incrivelmente o desenvolvimento de aplicativos, quando é fundamental implantar o sistema e começar a trabalhar rapidamente, processando os resultados - ou o esquema e os tipos de dados armazenados não são tão importantes.
Por exemplo, estamos criando um sistema especialista e queremos armazenar informações em um determinado domínio junto com algumas metainformações - podemos não saber todos os campos e é difícil armazenar JSON para cada registro - isso nos dá um ambiente muito flexível para expandir o modelo de dados e iteração rápida - portanto, em tais o caso de NoSQL seria ainda preferível e legível. Um exemplo de entrada (de um dos meus projetos, onde NoSQL estava exatamente onde era necessário).
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775," ","ru"],
"en_wiki_pagecount":2338861}
Você pode ler mais sobre NoSQL aqui .
O que estudar?
Em vez disso, você só precisa ser bom em analisar sua tarefa, quais propriedades ela possui e quais sistemas NoSQL estão disponíveis que se encaixam nessa descrição - e já estudar esse sistema.
Linguagens de consulta de script
A princípio, parece, o que Python tem a ver com isso - é uma linguagem de programação, e não tem nada a ver com consultas.

- O Pandas é um canivete direto da Ciência de Dados, onde uma grande quantidade de transformação de dados, agregação, etc. ocorre nele.
- Numpy é a computação vetorial, matrizes e álgebra linear que existe.
- Scipy contém muita matemática neste pacote, especialmente estatísticas.
- Laboratório Jupyter - muitas análises exploratórias de dados se encaixam bem em laptops - bom para ser capaz.
- Pedidos - networking.
- Pysparks são muito populares entre os engenheiros de dados, provavelmente você terá que interagir com este ou e iniciar, simplesmente por causa de sua popularidade.
- * Selenium é muito útil para coletar dados de sites e recursos, às vezes simplesmente não há outra maneira de obter os dados.
Minha dica principal: Aprenda Python!
Pandas
Vamos pegar o seguinte código como exemplo:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])\
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})\
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))Na verdade, podemos ver que o código se encaixa no padrão SQL clássico.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_nameMas a parte importante é que esse código faz parte do script e do pipeline. Na verdade, estamos incorporando solicitações ao pipeline do Python. Nessa situação, a linguagem de consulta chega até nós de bibliotecas como Pandas ou pySpark.
Em geral, no pySpark, vemos um tipo semelhante de transformação de dados por meio da linguagem de consulta no espírito de:
df.filter(df.trip_type = “return”)\
.groupby(“day”)\
.agg({duration: 'mean'})\
.sort()Onde e o que ler
No próprio python, não é nenhum problema encontrar materiais para estudo. Há um grande número de tutoriais sobre pandas , pySpark e cursos no Spark (assim como no próprio DS ) na rede . Em geral, os materiais aqui são ótimos no Google e se eu tivesse que escolher um pacote para focar, seriam os pandas, é claro. Também há muitos materiais no pacote DS + Python .
Shell como uma linguagem de consulta
Muitos projetos de processamento e análise de dados com os quais tive que trabalhar são, na verdade, scripts de shell que chamam código em Python, em java e os próprios comandos de shell. Portanto, em geral, você pode considerar os pipelines no bash / zsh / etc, como uma solicitação de alto nível (você pode, é claro, fazer push loops lá, mas isso não é típico para código DS em linguagens shell), daremos um exemplo simples - eu precisava mapear o QID do Wikidata e um link completo para o wiki russo e inglês, para isso escrevi uma consulta simples a partir dos comandos do bash e para a saída escrevi um script simples em Python, que montei assim:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
Onde
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' Esse foi, na verdade, todo o pipeline que criou o mapeamento necessário, como vemos tudo, funcionou em modo stream:
- pv filepath - fornece uma barra de progresso com base no tamanho do arquivo e passa seu conteúdo
- unpigz -c leu parte do arquivo e deu jq
- jq com o fluxo-chave imediatamente produziu o resultado e o passou para o pós-processador (assim como no primeiro exemplo) em Python
- internamente, o pós-processador é uma máquina de estado simples que formatou a saída
No total, um pipeline complexo trabalhando em modo de fluxo em big data (0,5 TB), sem recursos significativos e composto de um pipeline simples e algumas ferramentas.
Outra dica importante: seja bom e eficiente no terminal e escreva em bash / zsh / etc.Onde é útil? Sim, em quase todos os lugares - existem, novamente, MUITOS materiais para estudo na rede. Em particular, este é meu artigo anterior.
Script R
Novamente, o leitor pode exclamar - bem, esta é uma linguagem de programação completa! E é claro que ele estará certo. No entanto, normalmente tive que lidar com R sempre em um contexto que, na verdade, era muito semelhante a uma linguagem de consulta.
R é uma estrutura de computação estatística e uma linguagem de computação e visualização estática (de acordo com isso ).
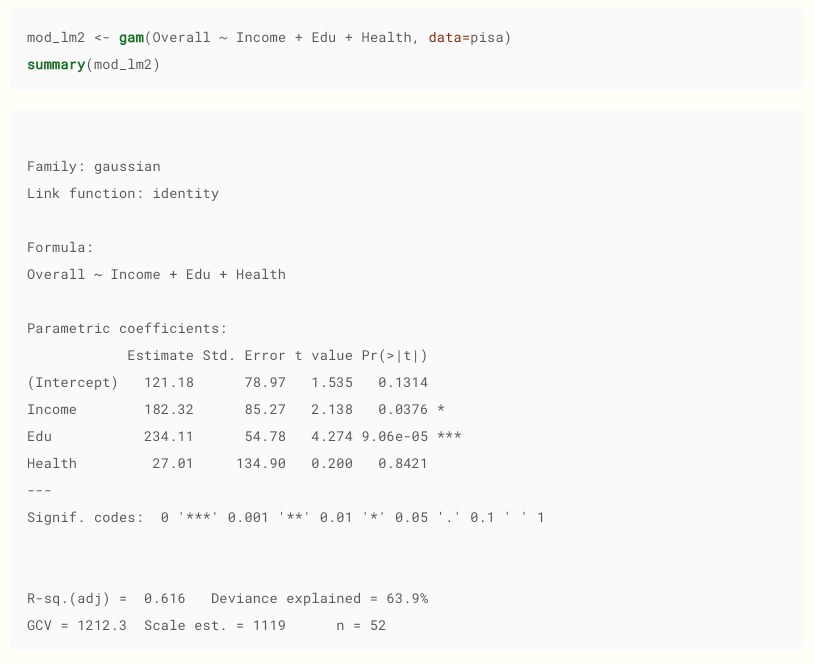
Retirado daqui . Aliás, recomendo, bom material.
Por que namorar um cientista para conhecer R? Pelo menos, porque há uma grande camada de pessoas que não são de TI que estão envolvidas na análise de dados em R. Eu me encontrei nos seguintes lugares:
- Setor farmacêutico.
- Biólogos.
- Setor financeiro.
- Pessoas com formação puramente matemática, lidando com estatísticas.
- Modelos estatísticos especializados e de aprendizado de máquina (que normalmente só podem ser encontrados na versão upstream como um pacote R).
Por que é realmente uma linguagem de consulta? Na forma em que costuma ser encontrado, é na verdade uma solicitação para criar um modelo, incluindo a leitura de dados e a fixação de parâmetros de consulta (modelo), bem como a visualização de dados em pacotes como ggplot2 - esta também é uma forma de escrever consultas.
Exemplo de consultas para renderização
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))Em geral, muitas ideias de R migraram para pacotes python, como pandas, numpy ou scipy, como dataframes e vetorização de dados - portanto, em geral, muitas coisas em R parecerão familiares e convenientes para você.
Existem muitas fontes de estudo, por exemplo, esta .
Gráfico de conhecimento
Aqui eu tenho uma experiência um pouco incomum, porque ainda frequentemente tenho que trabalhar com gráficos de conhecimento e linguagens de consulta para gráficos. Então, vamos examinar rapidamente o básico, já que essa parte é um pouco mais exótica.
Em bancos de dados relacionais clássicos, temos um esquema fixo - aqui o esquema é flexível, cada predicado é na verdade uma “coluna” e ainda mais.
Imagine que você modelaria uma pessoa e gostaria de descrever coisas importantes, por exemplo, vamos pegar uma pessoa específica de Douglas Adams, tomaremos essa descrição como base.
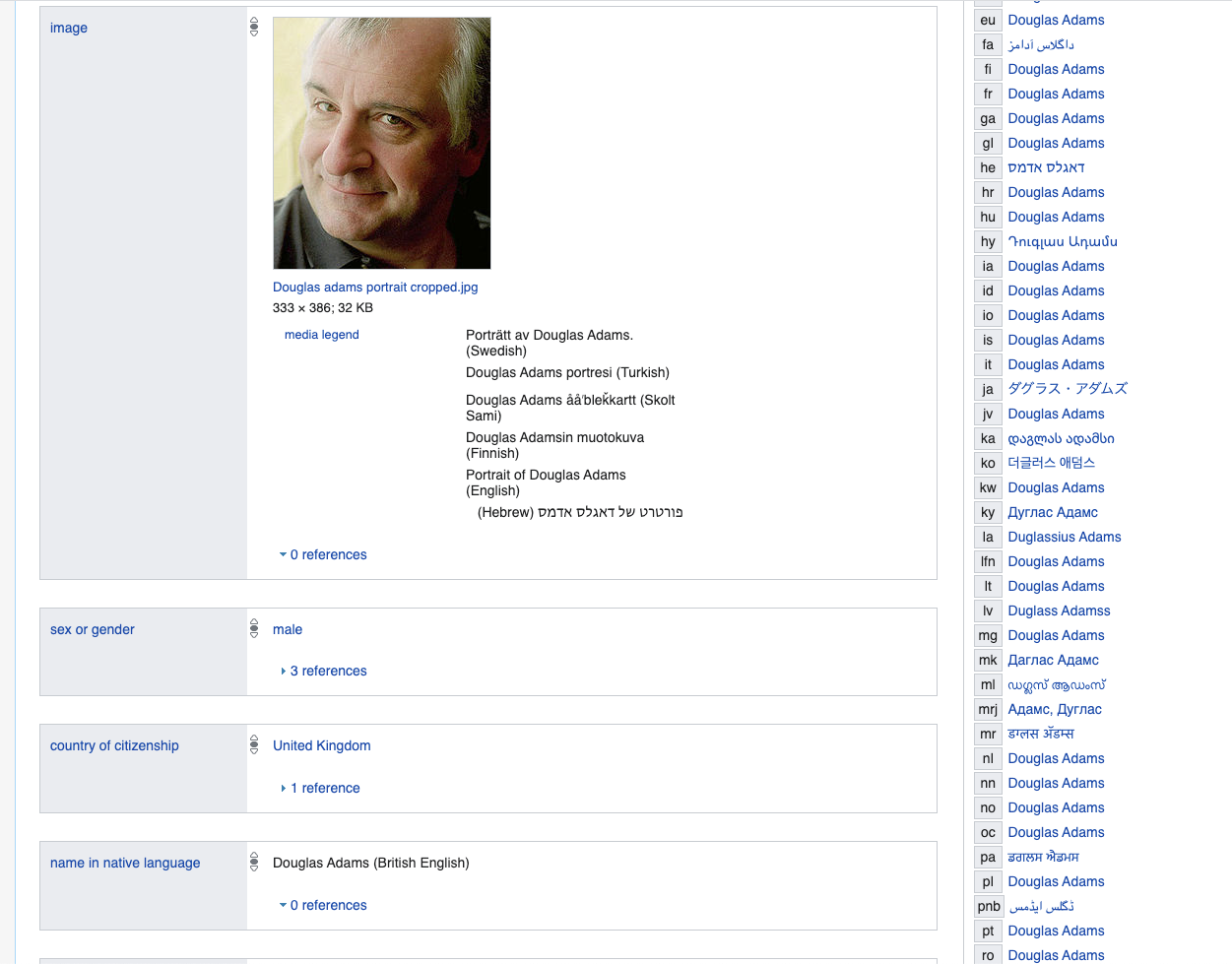
www.wikidata.org/wiki/Q42
Se estivéssemos usando um banco de dados relacional, teríamos que criar uma grande tabela ou tabelas com um grande número de colunas, a maioria das quais seria NULL ou preenchida com algum valor False padrão, por exemplo, improvável muitos de nós temos uma entrada na biblioteca nacional coreana - é claro, poderíamos colocá-los em tabelas separadas, mas isso seria, em última análise, uma tentativa de modelar a lógica flexível com predicados usando uma relacional fixa.
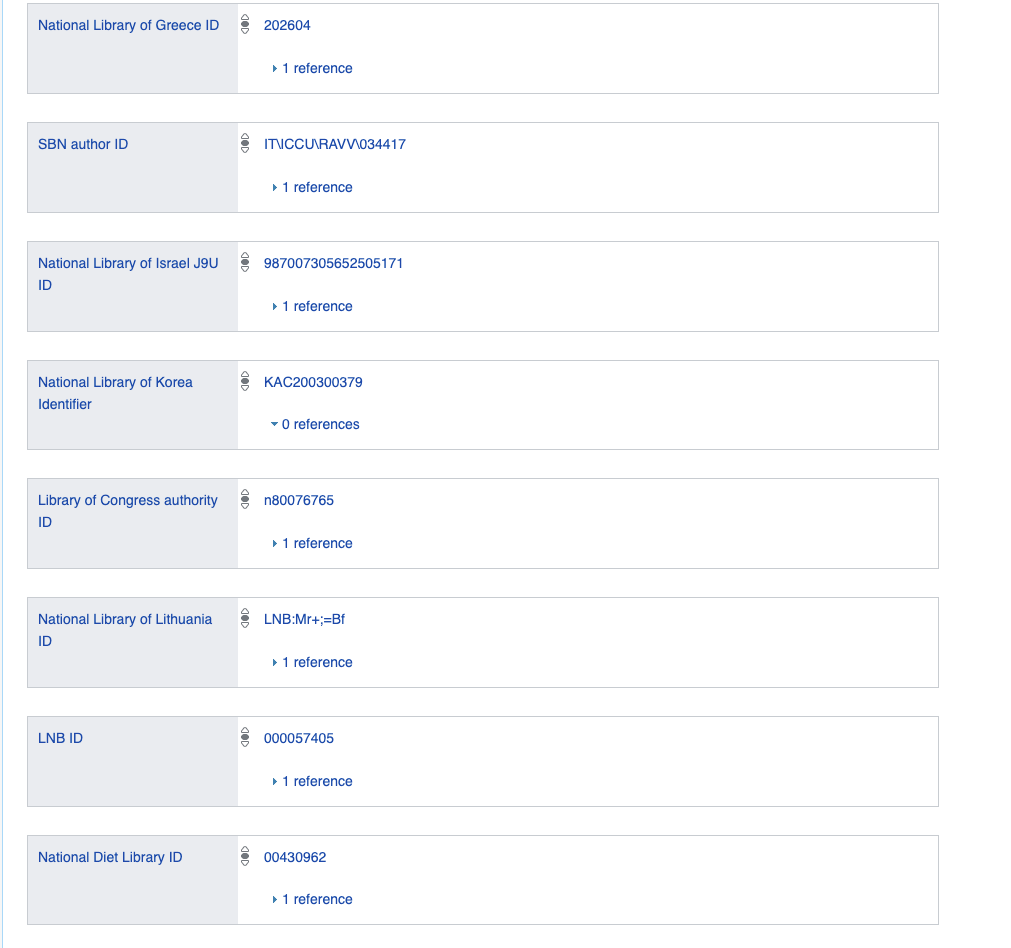
Portanto, imagine que todos os dados são armazenados como um gráfico ou como expressões lógicas binárias e unárias.
Onde você pode encontrar isso? Primeiro, trabalhando com dados wiki e com quaisquer bancos de dados gráficos ou dados conectados.
A seguir estão as principais linguagens de consulta que usei e com as quais trabalhei.
SPARQL
Wiki:
SPARQL ( . SPARQL Protocol and RDF Query Language) — , RDF, . SPARQL W3C .
Mas, na realidade, é uma linguagem de consultas a predicados lógicos unários e binários. Você está simplesmente declarando condicionalmente o que é fixo em uma expressão booleana e o que não é (muito simplista).
O próprio RDF (Resource Description Framework), no qual as consultas SPARQL são executadas, é um trio
object, predicate, subject- e a consulta seleciona os trios necessários de acordo com as restrições especificadas no espírito de: encontre um X tal que p_55 (X, q_33) seja verdadeiro - onde, é claro, p_55 é o que - essa relação com ID 55 e q_33 é um objeto com ID 33 (essa é a história toda, novamente omitindo todos os tipos de detalhes).
Exemplo de apresentação de dados:
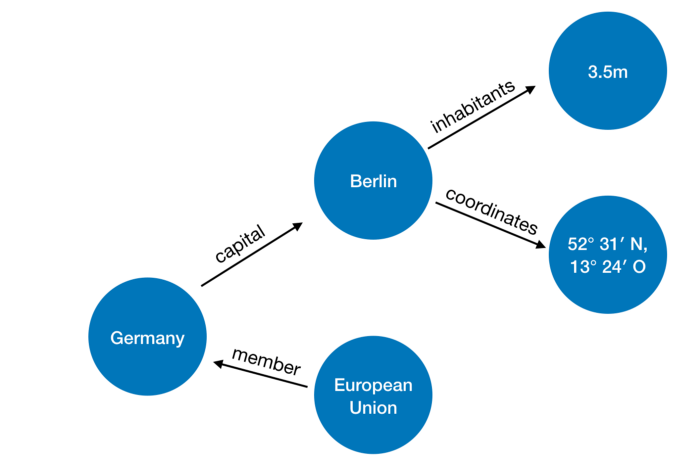
As fotos e um exemplo com países são daqui .
Exemplo de consulta básica

Na verdade, queremos encontrar o valor da variável? País, de modo que, para o predicado
membro_of, seja verdade que membro_de (? País, q458) e q458 é o ID da União Europeia.
Um exemplo de consulta SPARQL real dentro do mecanismo Python:
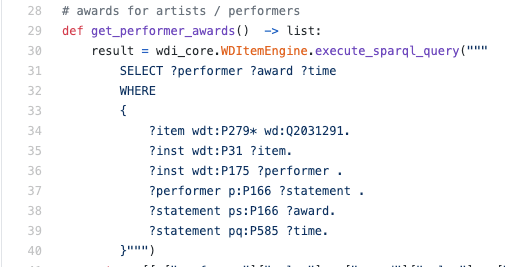
Como regra, eu tive que ler SPARQL, não escrever - em tal situação, provavelmente será uma habilidade útil entender a linguagem pelo menos em um nível básico para entender exatamente como os dados são recuperados.
Há muito material de estudo online, como este e este . Eu mesmo geralmente pesquisei no Google construções específicas e exemplos, e até agora tenho o suficiente.
Linguagens de consulta lógica
Você pode ler mais sobre o assunto no meu artigo aqui . Aqui, discutiremos brevemente por que as linguagens lógicas são adequadas para escrever consultas. Na verdade, RDF é apenas uma coleção de declarações lógicas da forma p (X) eh (X, Y), e uma consulta lógica se parece com isto:
output(X) :- country(X), member_of(X,“EU”).
Estamos falando sobre a criação de uma nova saída de predicado / 1 (/ 1 significa unário), quando desde que seja verdadeiro para X aquele país (X) - ou seja, X é o país e também membro_de (X, “UE”).
Ou seja, temos os dados e as regras, nesse caso, geralmente apresentados da mesma maneira, o que torna muito fácil e bom modelar tarefas.
Onde você conheceu na indústria: todo um grande projeto com uma empresa que escreve consultas nessa linguagem, bem como sobre o projeto atual no núcleo do sistema - pode parecer uma coisa um tanto exótica, mas às vezes ocorre.
Um exemplo de snippet de código em linguagem lógica que processa wikidata:
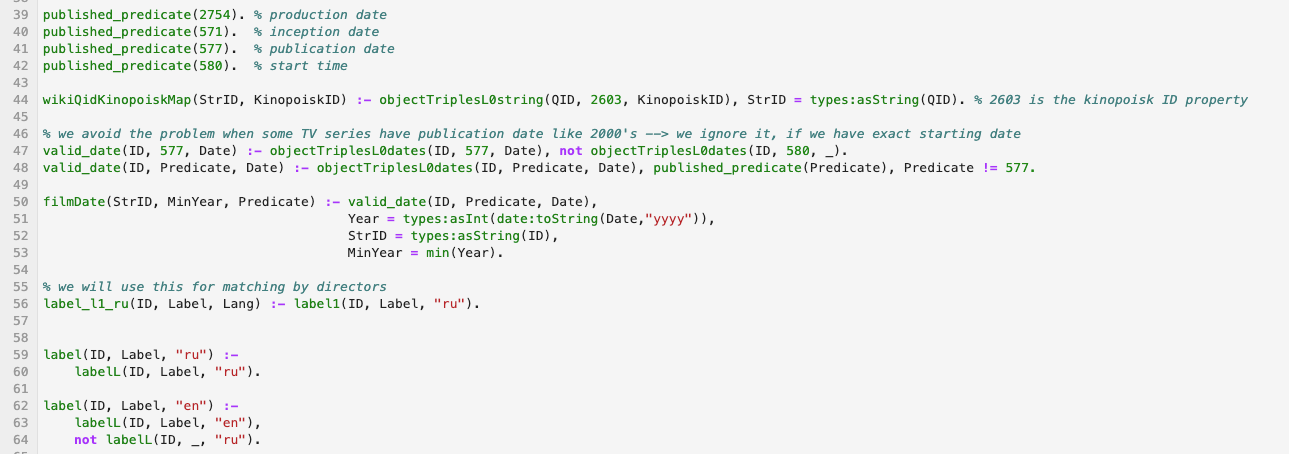
Materiais: Vou dar aqui alguns links para a linguagem de programação lógica moderna Answer Set Programming - eu recomendo estudá-la:
- http://peace.eas.asu.edu/aaai12tutorial/asp-tutorial-aaai.pdf
- http://ceur-ws.org/Vol-1145/tutorial1.pdf
- https://www.youtube.com/watch?v=gVQ0bP8zyHw
- https://www.youtube.com/watch?v=kdcd7Je2glc
- https://potassco.org/book/
- http://potassco.sourceforge.net/teaching.html
- https://www.cs.uni-potsdam.de/~torsten/Potassco/Tutorials/fmcad12.pdf
