1 O que é o manuscrito Voynich?
O manuscrito Voynich é um manuscrito misterioso (códice, manuscrito ou apenas um livro) em boas 240 páginas que chegou até nós, presumivelmente, do século XV. O manuscrito foi adquirido acidentalmente de um antiquário pelo marido do famoso escritor carbonário Ethel Voynich - Wilfred Voynich - em 1912 e logo se tornou propriedade do público em geral.
O idioma do manuscrito ainda não foi determinado. Vários pesquisadores do manuscrito sugerem que o texto do manuscrito é criptografado. Outros têm certeza de que o manuscrito foi escrito em um idioma que não sobreviveu nos textos que conhecemos hoje. Outros ainda consideram o manuscrito Voynich um absurdo (veja o hino moderno ao absurdo Codex Seraphinianus ).
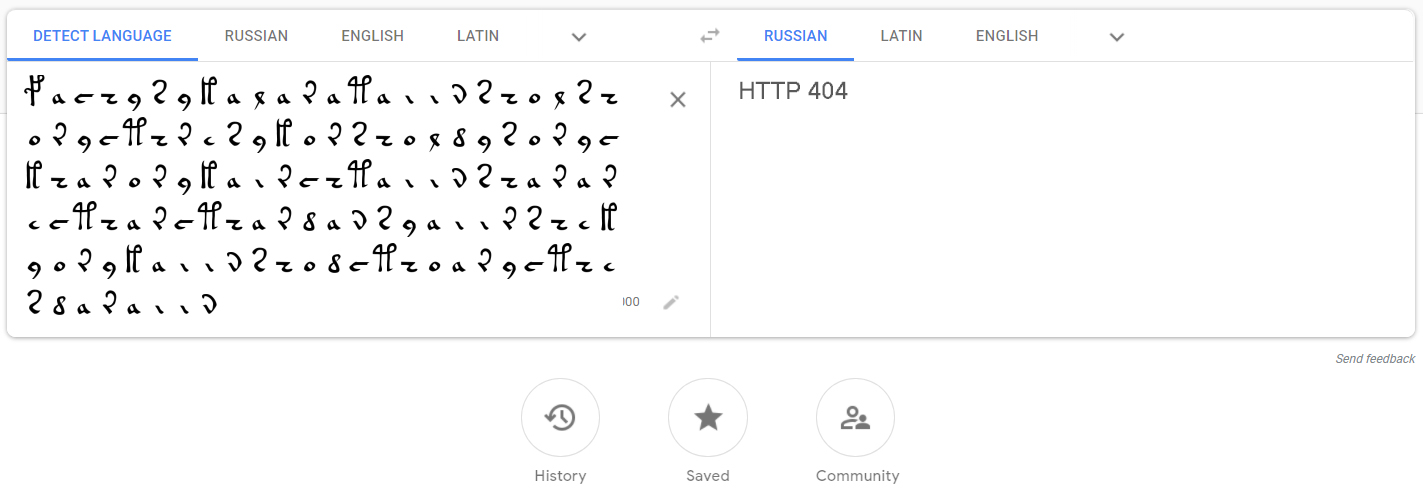
Como exemplo, darei um fragmento digitalizado de um assunto com texto e ninfas:

2 Por que este manuscrito estranho é tão interessante?
Talvez seja uma falsificação tardia? Aparentemente não. Ao contrário do Sudário de Turin, nem a análise de radiocarbono nem outras tentativas de contestar a antiguidade do pergaminho deram uma resposta inequívoca. Mas Voynich não poderia ter previsto a análise de isótopos no início do século 20 ...
Mas e se o manuscrito for um conjunto de cartas sem sentido da pena de um monge brincalhão, um nobre em uma consciência alterada? Não definitivamente NÃO. Batendo nas teclas sem pensar , eu, por exemplo, representarei o ruído branco do teclado QWERTY modulado familiar de todos como “ asfds dsf”. Um exame grafológico mostra que o autor escreveu com mão firme os símbolos do alfabeto que conhecia bem. Além disso, as correlações da distribuição de letras e palavras no texto do manuscrito correspondem ao texto “vivo”. Por exemplo, em um manuscrito, condicionalmente dividido em 6 seções, existem palavras - "endêmica", freqüentemente encontrada em uma das seções, mas ausente em outras.
Mas e se o manuscrito for uma cifra complexa e as tentativas de quebrá-la forem teoricamente sem sentido? Se acreditarmos na idade venerável do texto, a versão criptografada é extremamente improvável. A Idade Média poderia ter oferecido apenas uma cifra de substituição, que Edgar Allan Poe quebrou com tanta facilidade e elegância . Novamente, a correlação de letras e palavras do texto não é típica para a grande maioria das cifras.
Apesar dos sucessos colossais na tradução de scripts antigos, incluindo o uso de recursos de computação modernos, o manuscrito Voynich ainda desafia linguistas profissionais experientes ou jovens cientistas de dados ambiciosos.
3 Mas e se a linguagem do manuscrito for conhecida por nós
... mas a grafia é diferente? Quem, por exemplo, reconhece o latim neste texto ?

E aqui está outro exemplo - transliteração de um texto em inglês para grego:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονBiblioteca de transliteração do Python . NB: esta não é mais uma cifra de substituição - algumas combinações de várias letras são transmitidas em uma letra e vice-versa.
Vou tentar identificar (classificar) a língua do manuscrito, ou encontrar o parente mais próximo a ela a partir das línguas conhecidas, destacando os traços característicos e treinando o modelo sobre eles:
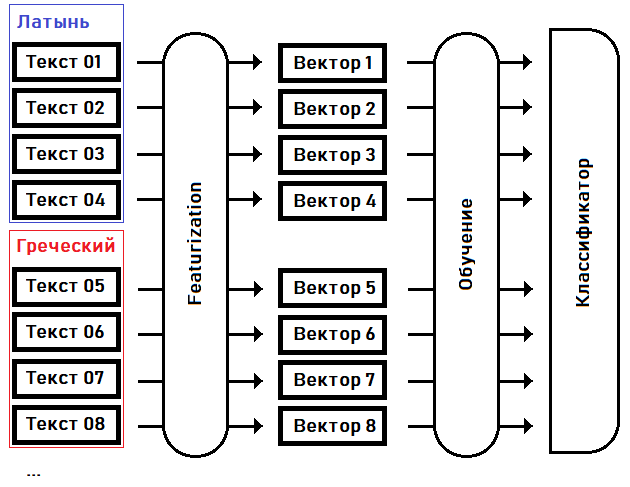
Na primeira fase - caracterização- transformamos textos em vetores de características: matrizes de números reais de tamanho fixo, onde cada dimensão do vetor é responsável por sua própria característica especial (característica) do texto fonte. Por exemplo, vamos concordar na 15ª dimensão do vetor para manter a frequência da palavra mais comum no texto, na 16ª dimensão - a segunda palavra mais popular ... na enésima dimensão - a sequência mais longa da mesma palavra repetida, etc.
Na segunda etapa - treinamento - selecionamos os coeficientes do classificador com base no conhecimento prévio da língua de cada um dos textos.
Depois que o classificador for treinado, podemos usar esse modelo para determinar o idioma do texto que não foi incluído na amostra de treinamento. Por exemplo, para o texto do manuscrito Voynich.
4 A imagem é tão simples - qual é o truque?
A parte complicada é como transformar exatamente um arquivo de texto em um vetor. Separar o joio do trigo e deixar apenas as características próprias da língua como um todo, e não de cada texto específico.
Se, para simplificar, transformar os textos fonte em codificação (ou seja, números) e “alimentar” esses dados como são para um dos muitos modelos de rede neural, o resultado provavelmente não nos agradará. Muito provavelmente, um modelo treinado nesses dados estará vinculado ao alfabeto e é a partir de símbolos que, em primeiro lugar, tentará determinar a linguagem de um texto desconhecido.
Mas o alfabeto do manuscrito "não tem análogos". Além disso, não podemos confiar totalmente nos padrões de distribuição de letras. Teoricamente, também é possível transferir a fonética de um idioma pelas regras de outro (o idioma é élfico - e as runas são Mordor)
O astuto escriba não usou sinais de pontuação ou números como os conhecemos. Todo o texto pode ser considerado um fluxo de palavras, dividido em parágrafos. Não há nem certeza sobre onde uma frase termina e outra começa.
Isso significa que subiremos a um nível superior em relação às letras e contaremos com as palavras. Vamos compilar um dicionário baseado no texto do manuscrito e rastrear os padrões já no nível da palavra.
5 Texto original do manuscrito
Claro, você não precisa codificar os caracteres intrincados do manuscrito Voynich em seus equivalentes Unicode e vice-versa - este trabalho já foi feito para nós, por exemplo, aqui . Com as opções padrão, obtenho o seguinte equivalente à primeira linha do manuscrito:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-Pontos e pontos de exclamação (bem como vários outros símbolos do alfabeto EVA ) são apenas separadores, que para nossos propósitos podem ser substituídos por espaços. Pontos de interrogação e asteriscos são palavras / letras não reconhecidas.
Para verificação, vamos substituir o texto aqui e obter um fragmento do manuscrito:
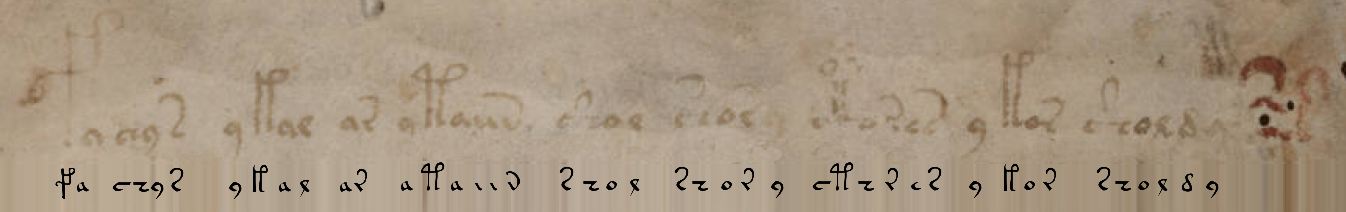
6 Programa - classificador de texto (Python)
Aqui está um link para o repositório de código com as dicas README mínimas de que você precisa para testar o código em ação.
Eu coletei mais de 20 textos em latim, russo, inglês, polonês e grego, tentando manter o volume de cada texto em ± 35.000 palavras (o volume do manuscrito Voynich).
Tentei selecionar datas próximas nos textos, em uma grafia - por exemplo, em textos em língua russa evitei a letra Ѣ, e as variantes de escrever letras gregas com diacríticos diferentes levaram a um denominador comum. Eu também removi números, especiais dos textos. caracteres, espaços extras, letras convertidas em um caso.
A próxima etapa é construir um "dicionário" contendo informações como:
- frequência de uso de cada palavra no texto (textos),
- A "raiz" de uma palavra - ou melhor, uma parte comum imutável de um conjunto de palavras,
- "prefixos" e "terminações" comuns - ou melhor, o início e o fim das palavras, junto com a "raiz" que constitui as palavras reais,
- sequências comuns de 2 e 3 palavras idênticas e a frequência de sua ocorrência.
Eu peguei a "raiz" da palavra entre aspas - um algoritmo simples (e às vezes eu mesmo) não é capaz de determinar, por exemplo, qual é a raiz da palavra suporte? Ao tornar-se ka? Abaixo da taxa ?
De um modo geral, esse vocabulário são dados parcialmente preparados para a construção de um vetor de recursos. Por que escolhi esta etapa - compilar e armazenar em cache dicionários para textos individuais e para um conjunto de textos para cada uma das línguas? O fato é que esse dicionário leva muito tempo para ser construído, cerca de meio minuto para cada arquivo de texto. E já tenho mais de 120 arquivos de texto.
7 Featurization
A obtenção de um vetor de características é apenas um estágio preliminar para a mágica posterior do classificador. Como um freak OOP, é claro, eu criei uma classe abstrata BaseFeaturizer para a lógica upstream, de modo a não violar o princípio de inversão de dependência . Esta classe deixa aos descendentes a capacidade de transformar um ou mais arquivos de texto de uma vez em vetores numéricos.
Além disso, a classe de herança deve dar um nome a cada característica individual (coordenada-i do vetor de característica). Isso será útil se decidirmos visualizar a lógica da máquina da classificação. Por exemplo, a 0ª dimensão do vetor será marcada como CRw1 - autocorrelação da frequência de palavras retiradas do texto na posição adjacente (com lag 1).
Da classe BaseFeaturizer, herdei a classeWordMorphFeaturizer , cuja lógica é baseada na frequência de uso das palavras ao longo do texto e dentro de uma janela deslizante de 12 palavras.
Um aspecto importante é que o código de um herdeiro específico de BaseFeaturizer, além dos próprios textos, também precisa de dicionários preparados com base neles (a classe CorpusFeatures ), que provavelmente já estão armazenados em cache no disco no momento do início do treinamento e teste do modelo.
8 Classificação
A próxima classe abstrata é BaseClassifier . Este objeto pode ser treinado e então classificar os textos por seus vetores de características.
Para a implementação (a classe RandomForestLangClassifier ), escolhi o algoritmo Random Forest Classifier da biblioteca sklearn . Por que esse classificador específico?
- O Random Forest Classifier me convém com seus parâmetros padrão,
- não requer normalização dos dados de entrada,
- oferece uma visualização simples e intuitiva do algoritmo de tomada de decisão.
Visto que, em minha opinião, o Random Forest Classifier deu conta de sua tarefa, não escrevi nenhuma outra implementação.
9 Treinamento e teste
80% dos arquivos - grandes fragmentos das obras de Byron, Aksakov, Apuleius, Pausanias e outros autores, cujos textos pude encontrar em formato txt - foram selecionados aleatoriamente para treinar o classificador. Os 20% restantes (28 arquivos) são para teste fora da amostra.
Enquanto testei o classificador em aproximadamente 30 textos em inglês e 20 em russo, o classificador deu uma grande porcentagem de erros: em quase metade dos casos, o idioma do texto foi determinado incorretamente. Mas quando comecei ~ 120 arquivos de texto em 5 idiomas (russo, inglês, latim, grego antigo e polonês) o classificador parou de cometer erros e começou a reconhecer corretamente o idioma de 27 a 28 arquivos de 28 casos de teste.
Então compliquei um pouco o problema: transcrevi o romance irlandês do século 19 "Rachel Gray" para o grego e o enviei a um classificador treinado. O idioma do texto na transliteração foi novamente definido corretamente.
10 O algoritmo de classificação é claro
Esta é a aparência de uma das 100 árvores no Random Forest Classifier treinado (para tornar a imagem mais legível, cortei 3 nós da subárvore certa):
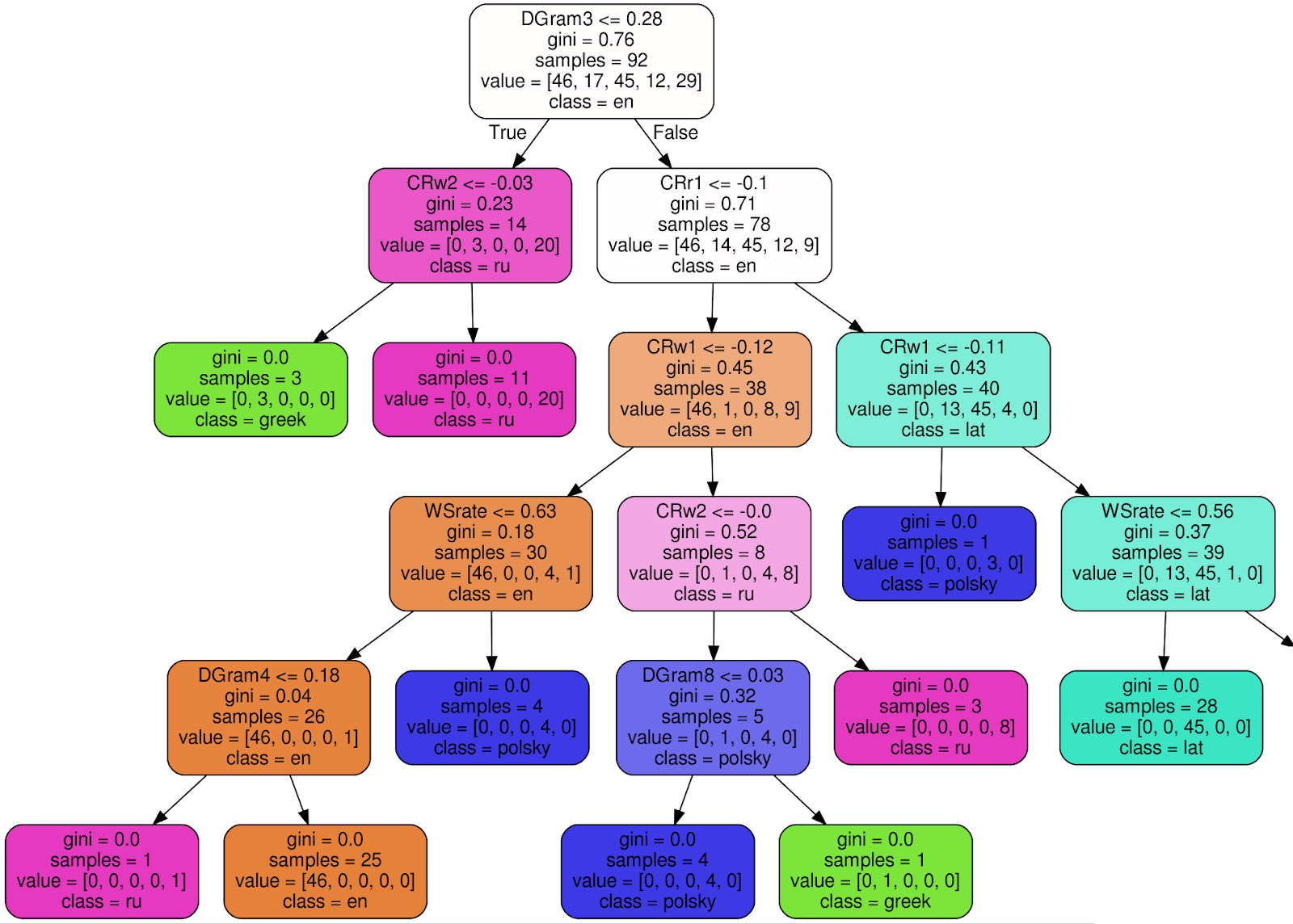
Usando o nó raiz como exemplo , explicarei o significado de cada assinatura:
- DGram3 <= 0,28 - critério de classificação. Nesse caso, DGram3 é uma medida específica de um vetor de recurso nomeado pela classe WordMorphFeaturizer, ou seja, a frequência da terceira palavra mais comum em uma janela deslizante de 12 palavras,
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
Se o critério (DGram3 <= 0,28 para o nó raiz) for atendido, vá para a subárvore esquerda, caso contrário - para a direita. Em cada folha, todos os textos devem ser atribuídos a uma classe (idioma) e o critério de incerteza de Gini ≡ 0. A
decisão final é feita por um conjunto de 100 árvores semelhantes construídas durante o treinamento do classificador.
11 E como o programa definiu a linguagem do manuscrito?
Latim , estimativa de probabilidade 0,59. E, claro, essa ainda não é a solução para o problema do século.
Uma correspondência direta entre o dicionário do manuscrito e a língua latina não é fácil - se não impossível. Por exemplo, aqui estão dez das palavras usadas com mais frequência: Manuscritos Voynich, latim,

grego antigo e línguas russas: o
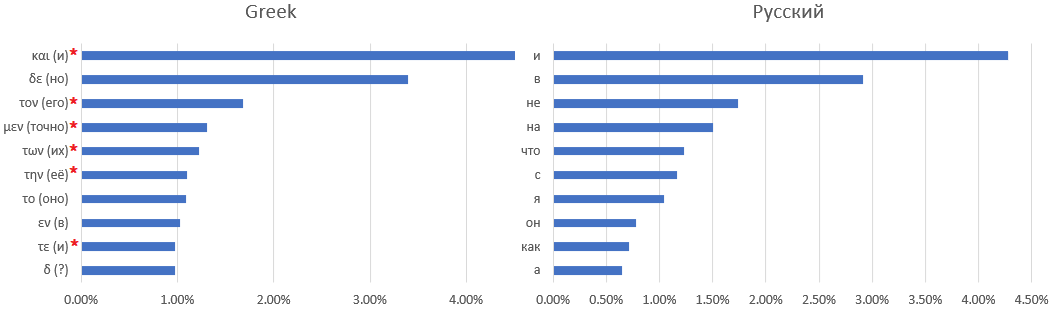
asterisco marca palavras que são difíceis de encontrar um equivalente em russo - por exemplo, artigos ou preposições que mudam de significado dependendo do contexto.
Uma correspondência óbvia como
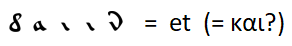
com a extensão das regras para substituir letras por outras palavras usadas com frequência, não consegui encontrar. Você só pode fazer suposições - por exemplo, a palavra mais comum é a conjunção "e" - como em todas as outras línguas consideradas, exceto o inglês, em que a conjunção "e" foi colocada em segundo lugar pelo artigo definido "o".
Qual é o próximo?
Em primeiro lugar, vale a pena tentar complementar a amostra de línguas com textos em francês moderno, espanhol, ..., línguas do Oriente Médio, se possível - inglês antigo, línguas francesas (antes do século XV) e outras. Mesmo que nenhum desses idiomas seja o idioma do manuscrito, a precisão da definição de idiomas conhecidos ainda aumentará e um equivalente mais próximo provavelmente será selecionado para o idioma do manuscrito.
Um desafio mais criativo é tentar definir uma classe gramatical para cada palavra. Para vários idiomas (é claro, em primeiro lugar - inglês), os tokenizers PoS (Part of Speech) como parte dos pacotes disponíveis para download funcionam bem com essa tarefa. Mas como determinar o papel das palavras em uma língua desconhecida?
Problemas semelhantes foram resolvidos pelo lingüista soviético B.V. Sukhotin - por exemplo, ele descreveu os algoritmos:
- separação de caracteres de um alfabeto desconhecido em vogais e consoantes - infelizmente, não 100% confiável, especialmente para línguas com fonética não trivial, como o francês,
- seleção de morfemas no texto sem espaços.
Para a tokenização PoS, podemos partir da frequência de uso das palavras, ocorrência em combinações de 2/3 palavras, a distribuição das palavras nas seções do texto: as uniões e as partículas devem ser distribuídas de maneira mais uniforme do que os substantivos.
Literatura
Não vou deixar aqui links para livros e tutoriais sobre PNL - basta na net. Em vez disso, vou listar obras de arte que se tornaram uma grande descoberta para mim quando criança, onde os heróis tiveram que trabalhar duro para desvendar os textos cifrados:
- E. A. Poe: The Golden Beetle é um clássico atemporal
- V. Babenko: "Meeting" é uma famosa história de detetive distorcida e um tanto visionária do final dos anos 80,
- K. Kirita: “Cavaleiros da Rua Chereshnevaya, ou o Castelo da Garota de Branco” é um romance adolescente fascinante, escrito sem descontos para a idade do leitor.