Google: Google: 90% dos nossos engenheiros usam um programa que você escreveu (Homebrew), mas você não pode inverter uma árvore binária em um tabuleiro, então adeus.
Embora nunca tenha tido necessidade de inversão de árvore binária, encontrei exemplos de uso real de estruturas de dados e algoritmos no meu trabalho diário, quando trabalhei no Skype / Microsoft, Skyscanner e Uber . Isso incluiu codificação e tomada de decisão com base nas especificações de estruturas de dados e algoritmos. Mas eu, na maior parte do tempo, usei o conhecimento relevante para entender como certos sistemas foram criados e por que foram criados dessa forma. O conhecimento dos conceitos relevantes torna mais fácil entender a arquitetura e implementação dos sistemas nos quais esses conceitos são usados.

Neste artigo, incluí histórias sobre situações em que estruturas de dados, como árvores e gráficos, bem como vários algoritmos, foram usados em projetos reais. Aqui, espero mostrar ao leitor que um conhecimento básico de estruturas de dados e algoritmos não é uma teoria inútil necessária apenas para entrevistas, mas algo que provavelmente será realmente necessário para alguém que trabalha em empresas de tecnologia inovadoras de rápido crescimento.
Aqui, falaremos sobre um número muito pequeno de algoritmos, mas no que diz respeito às estruturas de dados, posso observar que irei abordar quase todos eles aqui. Não deveria ser surpresa para ninguém que eu não sou um fã do tipo de perguntas de entrevista que super enfatizam algoritmos que estão fora de contato com a prática e têm como alvo estruturas de dados exóticas, como árvores vermelhas e pretas ou árvores AVL. Nunca fiz essas perguntas em entrevistas e não as farei. No final deste artigo, compartilharei minhas idéias sobre essas entrevistas. Mas, apesar do acima, o conhecimento das estruturas de dados subjacentes é de imenso valor. Esse conhecimento permite que você selecione exatamente o que é necessário para resolver certos problemas práticos.
Agora, vamos ver exemplos de como usar estruturas de dados e algoritmos na vida real.
Árvores e travessia de árvores: frameworks Skype, Uber e UI
Quando estávamos desenvolvendo o Skype para Xbox One, o código teve que ser escrito para um sistema operacional Xbox puro que não tinha as bibliotecas de que precisávamos. Desenvolvemos um dos primeiros aplicativos completos para esta plataforma. Precisávamos de um sistema de navegação de aplicativo que pudesse ser operado usando a tela de toque e dando comandos de voz ao aplicativo.
Nós criamos uma estrutura de navegação baseada em WinJS. Para isso, precisávamos manter um gráfico semelhante ao DOM, necessário para organizar a observação dos elementos com os quais o usuário poderia interagir. Para encontrar tais elementos, realizamos travessia de DOM, que se resumiu a travessia de árvore, ou seja, a estrutura existente de elementos DOM. Este é um exemplo clássico de BFS ou DFS (pesquisa em largura ou pesquisa em profundidade - pesquisa em largura ou pesquisa em profundidade).
Se você está fazendo desenvolvimento web, isso significa que já está trabalhando com uma estrutura em árvore, ou seja, o DOM. Todos os nós DOM podem ter nós filhos. O navegador exibe nós na tela após atravessar a árvore DOM. Se você precisar encontrar um elemento específico, poderá usar os métodos DOM integrados para resolver esse problema. Por exemplo, o método getElementById. Uma alternativa é desenvolver sua própria solução BFS ou DFS para atravessar os nós e encontrar o que você precisa. Por exemplo, algo semelhante é feito aqui .
Muitos frameworks que renderizam elementos de UI usam estruturas de árvore em suas profundidades. Portanto, o React suporta DOM virtual e usa um algoritmo de reconciliação inteligente(comparações). Isso permite obter alto desempenho devido ao fato de que apenas partes alteradas da interface são renderizadas novamente. Uma visualização deste processo pode ser encontrada aqui.
Na arquitetura móvel Uber, RIBs, as árvores também são usadas. Isso torna essa arquitetura semelhante à maioria das outras estruturas de IU que exibem estruturas hierárquicas de elementos. A arquitetura RIBs mantém uma árvore RIB para fins de gerenciamento de estado. Anexar e desanexar RIBs controla sua renderização. Enquanto trabalhamos com RIBs, às vezes esboçamos tentando descobrir se os RIBs se encaixam na hierarquia existente e discutimos se os RIBs em questão deveriam ter elementos visíveis. Ou seja, falaram se essa estrutura participará da formação da apresentação visual da interface, ou será utilizada apenas para gerenciamento de estado.

Transições de estado ao usar RIBs. Você pode encontrar mais detalhes sobre RIBs aqui.Se
você precisar renderizar elementos hierárquicos, esteja ciente de que estruturas de árvore são normalmente usadas para isso, percorrendo-os e renderizando os elementos visitados. Eu encontrei muitas ferramentas internas que usam essa abordagem. Um exemplo de tal ferramenta é o renderizador RIBs criado pela equipe da plataforma móvel do Uber. Aqui está uma palestra sobre este assunto.
Gráficos ponderados e localizador de caminho mais curto: Skyscanner
O Skyscanner é um projeto que visa encontrar as melhores ofertas em passagens aéreas. A procura de tais ofertas é feita visualizando e analisando todas as rotas existentes no mundo e combinando-as. A essência dessa tarefa está mais relacionada à coleta automática de dados por um robô de busca, e não ao armazenamento em cache de todos esses dados, já que as companhias aéreas calculam de forma independente o tempo de espera para o próximo voo. Mas a possibilidade de planejar uma viagem com uma visita a várias cidades se resume à tarefa de encontrar o caminho mais curto.
O planejamento de viagens para várias cidades foi uma das possibilidades que o Skyscanner demorou muito para implementar. Ao mesmo tempo, as dificuldades relacionavam-se principalmente ao próprio sistema em desenvolvimento. As melhores ofertas desse tipo são encontradas usando algoritmos de caminho mais curto como o de Dijkstra ou A *. As rotas de vôo são apresentadas na forma de um gráfico direcionado. Cada uma de suas arestas recebe um peso na forma de um preço de ingresso. Ao pesquisar a melhor rota, encontrar a rota mais barata entre duas cidades é realizada usando a implementação do algoritmo A * modificado . Se você estiver interessado no tópico de seleção de passagens aéreas e encontrar as rotas mais curtas, aqui está um bom artigo sobre como usar o BFS para resolver esses problemas.
No entanto, no caso do Skyscanner, qual algoritmo foi usado para resolver o problema não era particularmente importante. Armazenar em cache, usar robôs de busca, organizar o trabalho com vários sites - tudo isso era muito mais difícil do que escolher um algoritmo. Mas, ao mesmo tempo, diferentes variantes do problema de encontrar o caminho mais curto surgem em muitas empresas diferentes de planejamento de viagens e na otimização do custo dessas viagens. Sem surpresa, este tópico também foi tema de conversas nos bastidores do Skyscanner.
Classificar: Skype (ou algo parecido)
Raramente tive um motivo para implementar eu mesmo algoritmos de classificação ou para estudar profundamente as complexidades de sua estrutura. Mas, apesar disso, foi interessante entender como esses algoritmos funcionam - de classificação por bolha, classificação por inserção, classificação por mesclagem e classificação por seleção, até o algoritmo mais complexo - classificação rápida. Descobri que raramente é necessário implementar tais algoritmos, especialmente se você não precisa escrever uma função de classificação que faça parte de uma biblioteca.
No Skype, entretanto, tive que recorrer ao uso prático de meu conhecimento de algoritmos de classificação. Um de nossos programadores decidiu implementar a classificação por inserções para exibir os contatos. Em 2013, quando o Skype estava online, os contatos eram baixados em lotes. Demorou algum tempo para baixar todos eles. Como resultado, aquele programador pensou que seria melhor construir uma lista de contatos classificados por nome usando a classificação por inserção. Discutimos muito esse algoritmo, pensando por que não usar apenas algo que já foi implementado. Como resultado, demoramos muito para testar adequadamente nossa implementação do algoritmo e verificar seu desempenho. Pessoalmente, não vejo muito sentido em criar minha própria implementação desse algoritmo. Mas então o projeto estava em tal estágioonde tínhamos tempo para essas coisas.
Claro, existem situações reais em que a classificação eficiente desempenha um papel muito importante em um projeto. E se o desenvolvedor puder, de forma independente, com base nas características dos dados, escolher o algoritmo mais adequado, isso pode dar um aumento perceptível no desempenho da solução. A classificação por inserção pode ser muito útil quando você trabalha com grandes conjuntos de dados transmitidos em algum lugar em tempo real e visualiza imediatamente esses dados. O Merge Sort pode funcionar bem para abordagens de divisão e conquista ao lidar com grandes quantidades de dados armazenados em nós diferentes. Nunca trabalhei com esses sistemas, então, por enquanto, continuo a considerar algoritmos de classificação como algo que tem uso limitado no trabalho diário. É verdade,não se trata da importância de compreender como funcionam os diferentes algoritmos de classificação.
Tabelas de hash e hashing: em todos os lugares
A estrutura de dados que uso regularmente é uma tabela hash. Isso também inclui funções hash. Esta é uma ferramenta muito útil que pode ser usada para resolver uma variedade de tarefas - desde a contagem do número de certas entidades, detecção de duplicatas, armazenamento em cache, até cenários como fragmentação usados em sistemas distribuídos . As tabelas de hash são, depois dos arrays, a estrutura de dados mais comum em programação. Eu o usei em inúmeras situações. Ele está presente em quase todas as linguagens de programação e, se necessário, é fácil de implementar você mesmo.
Pilhas e filas: de vez em quando
Uma pilha é uma estrutura de dados familiar a qualquer pessoa que tenha código depurado escrito em uma linguagem que ofereça suporte a rastreamentos de pilha. Se falarmos da pilha como uma estrutura de dados, então, no decorrer do trabalho, encontrei vários problemas para a solução dos quais ela era necessária. Mas deve-se observar que conheci as pilhas corretamente enquanto depurava e fazia o perfil do desempenho do código. As pilhas também são uma escolha natural para a estrutura de dados usar ao fazer DFS.
Raramente tive de recorrer ao uso de filas, mas as encontrei com bastante frequência nas bases de código de vários projetos. Digamos que algo foi colocado na fila e algo foi recuperado dele. Normalmente, as filas são usadas para implementar a travessia da árvore em largura e são ideais para essa tarefa. As filas também podem ser usadas em muitas outras situações. Um dia me deparei com um código de agendamento de trabalho no qual encontrei um exemplo de uso decente da fila de prioridade implementada pelo módulo heapq do Python , quando os trabalhos mais curtos foram executados primeiro.
Algoritmos criptográficos: Uber
Dados importantes que os usuários inserem em aplicativos móveis ou aplicativos da web devem ser criptografados antes de serem transmitidos pela rede. E eles os descriptografam apenas onde são necessários. Para organizar tal esquema de trabalho, a implementação de algoritmos criptográficos deve estar presente nas partes cliente e servidor dos aplicativos.
Compreender algoritmos criptográficos é muito interessante. Ao mesmo tempo, você não deve oferecer seus próprios algoritmos para resolver certos problemas. Esta é uma das piores idéias que um programador pode imaginar. Em vez disso, ele pega um padrão existente e bem documentado e usa as primitivas integradas das respectivas estruturas. Normalmente, o AES atua como o padrão escolhido ao implementar soluções criptográficas.... É seguro o suficiente para ser usado para criptografar informações classificadas nos Estados Unidos . Não há ataques de trabalho conhecidos ao protocolo. AES-192 e AES-256 são geralmente bastante confiáveis para a maioria das tarefas práticas.
Quando vim para o Uber, o sistema de criptografia móvel e o sistema de criptografia do aplicativo web já estavam implementados, baseavam-se nos mecanismos descritos acima, então tive um motivo para estudar os detalhes sobre AES (Advanced Encryption Standard), sobre HMAC (Hashed Message Authentication Codes) , sobre o algoritmo RSA e outras coisas. Também foi interessante entender como se prova a força criptográfica da sequência de ações usada na criptografia. Por exemplo, se falamos sobre criptografia autenticada com dados anexados, verifica-se que analisando os modos encrypt-and-MAC, MAC-then-encrypt e encrypt-then-MAC, é possível provar a força criptográfica de apenas um deles , embora isso não signifique que o resto não é criptograficamente seguro.
Você dificilmente precisará implementar primitivas criptográficas sozinho, a menos que esteja implementando uma estrutura criptográfica completamente nova. Mas você pode muito bem se deparar com a necessidade de tomar decisões sobre quais primitivos usar e como combiná-los. Você também pode precisar de conhecimento no campo de algoritmos criptográficos para entender por que um determinado sistema usa uma determinada abordagem para criptografia de dados.
Árvores de decisão: Uber
Enquanto trabalhamos em um dos projetos, tivemos que implementar uma lógica de negócios complexa em um aplicativo móvel. Ou seja, com base em meia dúzia de regras, uma das várias telas tinha que ser mostrada. Essas regras eram muito complexas porque os resultados da sequência de teste e a preferência do usuário tinham que ser levados em consideração.
O programador que começou a resolver esse problema tentou primeiro expressar todas essas regras na forma de instruções if-else. Isso resultou em um código extremamente confuso. Como resultado, decidiu-se usar a árvore de decisão. Com sua ajuda, foi fácil realizar todas as verificações necessárias. Foi relativamente fácil de implementar. Além disso, se necessário, ele pode ser alterado sem muitos problemas. Precisávamos criar nossa própria implementação da árvore de decisão, de modo que a verificação de condição fosse realizada em suas bordas. Isso é tudo de que precisamos desta árvore. Embora pudéssemos ter economizado o tempo gasto na implementação da árvore adotando uma abordagem diferente, a equipe decidiu que aquela árvore específica seria mais fácil de manter e começou a trabalhar. Esta árvore tem esta aparência:as bordas simbolizam os resultados da verificação das condições (esses são resultados binários ou os resultados representados por intervalos de valores), e os nós folha da árvore descrevem as telas para as quais você precisa navegar.
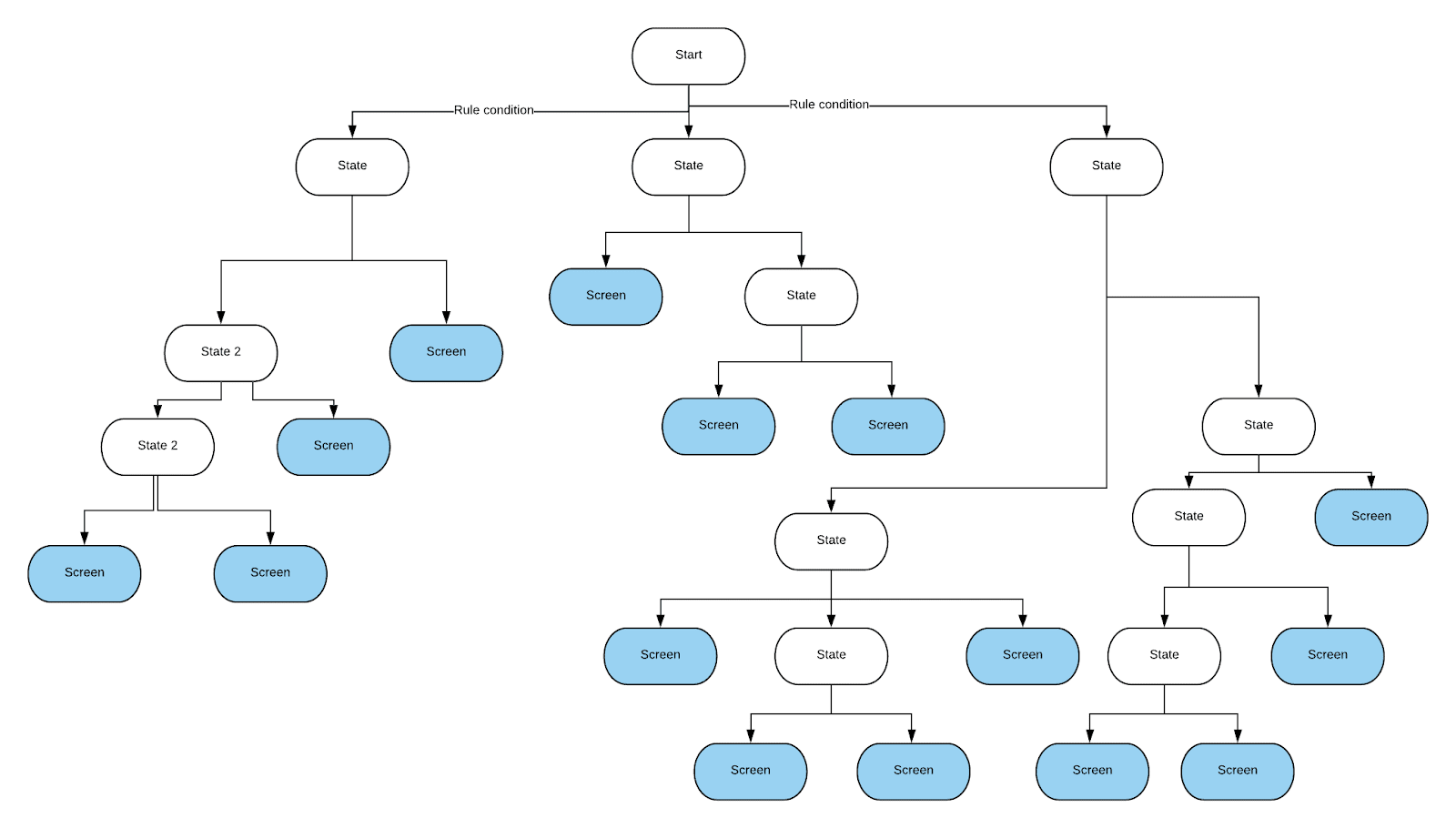
, , .
O sistema de compilação do aplicativo móvel do Uber, denominado SubmitQueue, também usava uma árvore de decisão, mas foi gerada dinamicamente. A equipe de experiência do desenvolvedor teve que enfrentar o difícil problema de realizar uma fusão diária de centenas de branches de origem com o branch de destino. Ao mesmo tempo, cada montagem levou cerca de 30 minutos para ser concluída. Isso incluiu a compilação, execução de testes de unidade e integração e testes de interface. Paralelizar assemblies não era uma solução boa o suficiente, pois muitas vezes havia alterações sobrepostas em assemblies diferentes, o que causava conflitos de mesclagem. Na prática, isso significava que às vezes os programadores tinham que esperar de 2 a 3 horas, recorrer ao rebase e reiniciar o processo de mesclagem novamente, na esperança de que dessa vez não enfrentassem um conflito.
A equipe de experiência do desenvolvedor adotou uma abordagem inovadora para prever conflitos de mesclagem e assemblies de fila de acordo. Isso foi feito usando uma árvore de decisão binária especial (árvore de especulação).

SubmitQueue usa uma árvore de decisão binária com arestas anotadas com probabilidades previstas. Essa abordagem permite determinar quais conjuntos de montagens podem ser executados em paralelo. Isso é feito para reduzir o tempo entre o recebimento e a execução de tarefas e para aumentar o rendimento do sistema. Nesse caso, apenas o código totalmente testado e viável deve entrar no branch
master.A equipe de experiência do desenvolvedor que criou este sistema escreveu um excelente material sobre ele. Mas aqui- outro artigo sobre o mesmo assunto, bem ilustrado. O resultado da implementação deste sistema foi a criação de um sistema de montagem de projeto muito mais rápido do que antes. Isso nos permitiu otimizar o tempo de construção de projetos e ajudou a tornar a vida de centenas de programadores móveis mais fácil.
Grades hexagonais, índices hierárquicos: Uber
Este é o último projeto sobre o qual quero falar aqui. Era totalmente baseado em uma estrutura de dados particular. Foi fazendo isso que aprendi sobre essa estrutura de dados. Estamos falando de uma grade hexagonal com índices hierárquicos.
Um dos problemas mais desafiadores e interessantes da Uber foi a otimização do custo das viagens e a distribuição dos pedidos entre os parceiros. As taxas de viagens podem mudar dinamicamente, os motoristas estão constantemente em movimento. Os engenheiros do Uber criaram o sistema de grade H3. Ele é projetado para visualizar e analisar dados entre cidades em diferentes escalas. A estrutura de dados usada para resolver os problemas acima é uma grade hexagonal com índices hierárquicos. Algumas ferramentas internas especializadas são usadas para visualizar os dados.

Dividindo o mapa em células hexagonais
Essa estrutura de dados tem seu próprio sistema de indexação, travessia, suas próprias definições de áreas individuais da grade, suas próprias funções. Uma descrição detalhada de tudo isso pode ser encontrada na documentação da API correspondente. Leia mais sobre o H3 aqui . Aqui está o código-fonte. Aqui você pode encontrar uma história sobre como e por que esse sistema foi criado.
A experiência com este sistema me permitiu ter uma ideia de que criar suas próprias estruturas de dados especializadas pode fazer sentido ao resolver problemas muito específicos. Existem muito poucos problemas na solução dos quais você pode aplicar uma grade hexagonal, se você não levar em conta a divisão em fragmentos do mapa com uma comparação com cada fragmento de dados resultante de níveis diferentes. Mas, como em outros casos, se você estiver familiarizado com outras estruturas de dados, isso será muito mais fácil de entender. E para uma pessoa que lidou com uma grade hexagonal, será mais fácil criar uma nova estrutura de dados projetada para resolver problemas semelhantes aos que são resolvidos usando essa grade.
Estruturas de dados e algoritmos em entrevistas
Acima, falei sobre quais estruturas de dados e algoritmos encontrei enquanto trabalhava em várias empresas por um longo tempo. Proponho-me agora retornar àquele tweet de Max Howell, que mencionei no início do artigo. Lá, Max reclamou que, em uma entrevista ao Google, ele foi convidado a inverter uma árvore binária em um quadro. Ele não fez isso. Ele foi mostrado a porta. Nesta situação, estou do lado de Max.
Eu acredito que saber como algoritmos populares funcionam, ou como funcionam estruturas de dados exóticas, não é o tipo de conhecimento que você precisa para trabalhar para uma empresa de tecnologia. Você precisa saber o que é um algoritmo, precisa ser capaz de criar algoritmos simples de forma independente, por exemplo, trabalhando com o princípio "ganancioso". Você também precisa ter conhecimento das estruturas de dados mais comuns, como tabelas de hash, filas e pilhas. Mas algo bastante específico, como o algoritmo de Dijkstra ou A *, ou algo ainda mais complexo, não é algo que precisa ser aprendido de cor. Se você realmente precisar desses algoritmos, poderá encontrar facilmente materiais de referência sobre eles. Por exemplo, se falamos de algoritmos que não estão relacionados a algoritmos de classificação, geralmente tento entendê-los em termos gerais e entender sua essência.O mesmo se aplica a estruturas de dados exóticas, como árvores vermelhas e pretas e árvores AVL. Nunca tive necessidade de usá-los. E se eu precisasse deles, sempre poderia atualizar meu conhecimento sobre eles recorrendo às publicações apropriadas. Ao entrevistar, como eu disse, nunca faço essas perguntas e não pretendo fazê-las.
Sou a favor de problemas práticos relacionados à programação, em que você pode resolver uma variedade de abordagens: de métodos de "força bruta" e variantes "gananciosas" de algoritmos a idéias algorítmicas mais avançadas. Por exemplo, acho que é perfeitamente normal ter uma tarefa de alinhamento de texto como esta . Por exemplo, tive que resolver esse problema ao criar um componente para renderizar texto no Windows Phone. Você pode resolver esse problema simplesmente usando um array e algumas instruções if-else, sem recorrer a algumas estruturas de dados complicadas.
Na verdade, muitas equipes e empresas exageram a importância dos problemas algorítmicos. Eu entendo a atratividade das perguntas do algoritmo. Eles permitem que você avalie o candidato em um curto espaço de tempo, as perguntas são fáceis de refazer, o que significa que se as perguntas que foram feitas a alguém se tornarem públicas, não haverá problemas especiais. As perguntas de algoritmo são boas para organizar testes para um grande número de candidatos. Por exemplo, você pode criar um pool de mais de cem perguntas e distribuí-las aleatoriamente aos candidatos. Perguntas sobre programação dinâmica e estruturas de dados exóticas estão se tornando cada vez mais comuns. Especialmente no Vale do Silício. Essas perguntas podem ajudar as empresas a contratar programadores fortes. Mas essas mesmas perguntas podem fechar o caminho na empresa para as pessoas que tiveram sucesso nos negócios,onde não é necessário um conhecimento profundo de algoritmos.
Se você trabalha em uma empresa que só contrata pessoas com profundo conhecimento de algoritmos complexos quase desde o nascimento, sugiro que pense com cuidado se essas são as pessoas de que você precisa. Por exemplo, contratei grandes equipes no Skyscanner (Londres) e Uber (Amsterdã) sem fazer perguntas complicadas sobre algoritmos. Limitei-me às estruturas de dados mais comuns e para testar as capacidades dos entrevistados relacionadas à resolução de problemas. Ou seja, eles precisavam saber sobre estruturas de dados comuns e ser capazes de criar algoritmos simples para resolver os problemas que enfrentam. Estruturas de dados e algoritmos são apenas ferramentas.
Resumindo: estruturas de dados e algoritmos são ferramentas
Se você trabalha para uma empresa de tecnologia inovadora e dinâmica, provavelmente encontrará implementações de uma ampla variedade de estruturas de dados e algoritmos no código dos produtos dessa empresa. Se você estiver desenvolvendo algo completamente novo, frequentemente terá que procurar estruturas de dados que tornem mais fácil resolver os problemas que você enfrenta. Em situações como essa, você precisa de um conhecimento geral de algoritmos e estruturas de dados e seus prós e contras para fazer a escolha certa.
Estruturas de dados e algoritmos são ferramentas que você deve usar com confiança ao escrever programas. Quando você conhecer essas ferramentas, verá muito do que já sabe nas bases de código que as utilizam. Além disso, esse conhecimento permitirá que você resolva problemas complexos com muito mais confiança. Você estará ciente das limitações teóricas dos algoritmos e como eles podem ser otimizados. Isso o ajudará a chegar a uma solução que, com todas as compensações necessárias, acabe sendo a melhor possível.
Se você deseja obter uma melhor compreensão das estruturas de dados e algoritmos, aqui estão algumas dicas e recursos:
- -, , , , , , . , , . , . — , .
- « ». , , , . — , , . , , , .
- Aqui estão mais alguns livros: “ Algoritmos. Guia de Desenvolvimento "e" Algoritmos em Java, 4ª Edição ". Usei-os para atualizar meu conhecimento universitário de algoritmos. É verdade, não os li até o fim. Pareciam-me bastante secos e inaplicáveis ao meu trabalho diário.
Quais estruturas de dados e algoritmos você encontrou na prática?
