
escalabilidade é um requisito fundamental para aplicativos em nuvem. Com o Kubernetes, dimensionar um aplicativo é tão fácil quanto aumentar o número de réplicas para uma implantação apropriada ou
ReplicaSet- mas é um processo manual.
O Kubernetes permite que os aplicativos sejam escalonados automaticamente (ou seja, pods em implantação ou
ReplicaSet) de maneira declarativa usando a especificação do autoescalador horizontal de pods. O critério padrão para o escalonamento automático são as métricas de utilização da CPU (métricas de recursos), mas métricas personalizadas e métricas fornecidas externamente podem ser integradas. Kubernetes AAS
equipe da Mail.rutraduziu um artigo sobre como usar métricas externas para dimensionar seu aplicativo Kubernetes automaticamente. Para mostrar como tudo funciona, o autor usa métricas de solicitação de acesso HTTP, que são coletadas usando o Prometheus.
Em vez de escalonamento automático horizontal de pods, o Kubernetes Event Driven Autoscaling (KEDA) é um operador Kubernetes de código aberto. Ele se integra nativamente com o Autoescalador de pod horizontal para fornecer escalonamento automático suave (incluindo de / para zero) para cargas de trabalho baseadas em eventos. O código está disponível no GitHub .
Resumo da operação do sistema
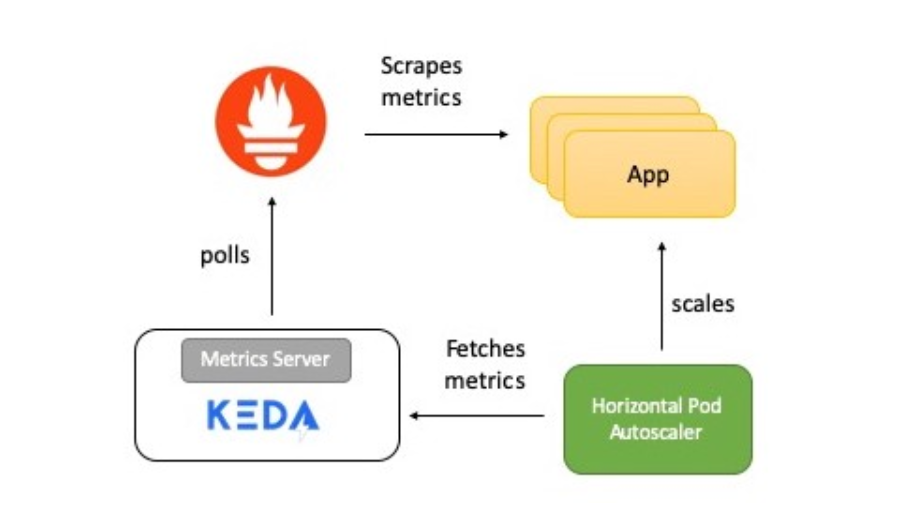
O diagrama mostra uma breve descrição de como tudo funciona:
- O aplicativo fornece métricas para o número de solicitações HTTP no formato Prometheus.
- O Prometheus está definido para coletar essas métricas.
- O escalador Prometheus em KEDA é configurado para escalar automaticamente o aplicativo com base no número de solicitações HTTP.
Agora vou contar em detalhes sobre cada elemento.
KEDA e Prometheus
O Prometheus é um kit de ferramentas de monitoramento e alerta de sistema de código aberto, parte da Cloud Native Computing Foundation . Coleta métricas de várias fontes e salva como dados de série temporal. Para visualizar dados, você pode usar o Grafana ou outras ferramentas de visualização que funcionam com a API Kubernetes.
KEDA apóia o conceito de scaler - ele atua como uma ponte entre KEDA e o sistema externo. A implementação do scaler é específica para cada sistema de destino e extrai dados dele. KEDA então os usa para controlar o escalonamento automático.
Os escaladores oferecem suporte a várias fontes de dados, como Kafka, Redis, Prometheus. Ou seja, o KEDA pode ser usado para dimensionar automaticamente as implantações do Kubernetes usando as métricas do Prometheus como critérios.
Aplicação de teste
O aplicativo de teste Golang fornece acesso HTTP e atende a duas funções importantes:
- Usa a biblioteca cliente do Prometheus Go para instrumentar o aplicativo e fornecer a métrica http_requests que contém um contador de visitas. O endpoint para o qual as métricas do Prometheus estão disponíveis é localizado pelo URI
/metrics.
var httpRequestsCounter = promauto.NewCounter(prometheus.CounterOpts{ Name: "http_requests", Help: "number of http requests", }) - Em resposta à solicitação, o
GETaplicativo incrementa o valor da chave (access_count) no Redis. Essa é uma maneira fácil de fazer o trabalho como parte de um manipulador HTTP e também verificar as métricas do Prometheus. O valor da métrica deve ser igual ao valoraccess_countno Redis.
func main() { http.Handle("/metrics", promhttp.Handler()) http.HandleFunc("/test", func(w http.ResponseWriter, r *http.Request) { defer httpRequestsCounter.Inc() count, err := client.Incr(redisCounterName).Result() if err != nil { fmt.Println("Unable to increment redis counter", err) os.Exit(1) } resp := "Accessed on " + time.Now().String() + "\nAccess count " + strconv.Itoa(int(count)) w.Write([]byte(resp)) }) http.ListenAndServe(":8080", nil) }
O aplicativo é implantado no Kubernetes via
Deployment. Também é criado um serviço ClusterIPque permite ao servidor Prometheus receber métricas do aplicativo.
Aqui está o manifesto de implantação do aplicativo .
Servidor Prometheus
O manifesto de implantação do Prometheus consiste em:
ConfigMap- para transferir a configuração do Prometheus;Deployment- para implantar o Prometheus em um cluster Kubernetes;ClusterIP- serviço de acesso ao UI Prometheus;ClusterRole,ClusterRoleBindingEServiceAccount- para a detecção automática de serviços em Kubernetes (Auto-discovery).
Aqui está o manifesto para executar o Prometheus .
KEDA Prometheus ScaledObject
O scaler atua como uma ponte entre o KEDA e o sistema externo do qual as métricas precisam ser obtidas.
ScaledObjectÉ um recurso personalizado, ele precisa ser implantado para sincronizar a implantação com a fonte do evento, neste caso o Prometheus.
ScaledObjectcontém informações de escalonamento de implantação, metadados de origem de eventos (como segredos de conexão, nome de fila), intervalo de pesquisa, período de recuperação e outras informações. Isso resulta no recurso de escalonamento automático apropriado (definição HPA) para escalar a implantação.
Quando um objeto
ScaledObjecté excluído, sua definição HPA correspondente é apagada.
Aqui está a definição
ScaledObjectpara o nosso exemplo, ele usa um scaler Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
http://prometheus-service.default.svc.cluster.local:9090
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Considere os seguintes pontos:
- Ele aponta para
Deploymentum nomego-prom-app. - Tipo de gatilho -
Prometheus. O endereço do servidor Prometheus é mencionado junto com o nome da métrica, o limite e a solicitação PromQL a ser usada. Solicitação PromQL -sum(rate(http_requests[2m])). - De acordo com
pollingIntervalKEDA, ele consulta Prometheus por um alvo a cada quinze segundos. Pelo menos um pod (minReplicaCount) é compatível , e o número máximo de pods não excedemaxReplicaCount(neste exemplo, dez).
Pode ser definido
minReplicaCountcomo zero. Nesse caso, o KEDA ativa uma implantação zero para um e fornece o HPA para escalonamento automático adicional. A ordem inversa também é possível, ou seja, escalar de um a zero. No exemplo, não selecionamos zero porque este é um serviço HTTP e não um sistema sob demanda.
A magia do escalonamento automático
O limite é usado como um gatilho para dimensionar a implantação. Em nosso exemplo, a consulta PromQL
sum(rate (http_requests [2m]))retorna o valor agregado da taxa de solicitação HTTP (solicitações por segundo), medida nos últimos dois minutos.
Como o limite é três, haverá um abaixo, desde que o valor seja
sum(rate (http_requests [2m]))menor que três. Se o valor aumentar, um under adicional será adicionado cada vez que ele sum(rate (http_requests [2m]))aumentar em três. Por exemplo, se o valor for de 12 a 14, o número de pods será quatro.
Agora vamos tentar configurar!
Presetting
Tudo que você precisa é um cluster Kubernetes e um utilitário personalizado
kubectl. Este exemplo usa um cluster minikube, mas você pode usar qualquer outro. Existe um guia para instalar o cluster .
Instale a versão mais recente no Mac:
curl -Lo minikube
https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
Instale o kubectl para acessar seu cluster do Kubernetes.
Instale a versão mais recente no Mac:
curl -LO
"https://storage.googleapis.com/kubernetes-release/release/$(curl -s
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
Instalando KEDA
Você pode implantar o KEDA de várias maneiras, elas estão listadas na documentação . Estou usando YAML monolítico:
kubectl apply -f
https://raw.githubusercontent.com/kedacore/keda/master/deploy/KedaScaleController.yaml
KEDA e seus componentes são instalados no namespace
keda. Comando para verificar:
kubectl get pods -n keda
Espere, quando sob KEDA Operador começa - vai para
Running State. E então continue.
Instalando Redis com Helm
Se você não tiver o Helm instalado, use este tutorial . Comando para instalar no Mac:
brew install kubernetes-helm
helm init --history-max 200
helm initinicializa a CLI local e também é instalada Tillerno cluster Kubernetes.
kubectl get pods -n kube-system | grep tiller
Aguarde até que o pod do Tiller entre no estado Running
Nota do tradutor : o autor usa Helm @ 2, que requer a instalação do componente do servidor Tiller. Helm @ 3 é atualmente relevante, não precisa de uma parte do servidor.
Depois de instalar o Helm, um comando é suficiente para iniciar o Redis:
helm install --name redis-server --set cluster.enabled=false --set
usePassword=false stable/redis
Verifique se o Redis foi iniciado com sucesso:
kubectl get pods/redis-server-master-0
Aguarde até que o Redis entre no estado
Running.
Implante o aplicativo
Comando para implantação:
kubectl apply -f go-app.yaml
//output
deployment.apps/go-prom-app created
service/go-prom-app-service created
Verifique se tudo começou:
kubectl get pods -l=app=go-prom-app
Aguarde a transição do Redis para o estado
Running.
Implantando Servidor Prometheus
O Manifesto do Prometheus usa o Kubernetes Service Discovery para o Prometheus . Ele permite que você descubra pods de aplicativos dinamicamente com base em um rótulo de serviço.
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_run]
regex: go-prom-app-service
action: keep
Para implantação:
kubectl apply -f prometheus.yaml
//output
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/default configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prom-conf created
deployment.extensions/prometheus-deployment created
service/prometheus-service created
Verifique se tudo começou:
kubectl get pods -l=app=prometheus-server
Espere sob Prometeu entrar no estado
Running.
Use
kubectl port-forwardpara acessar a interface de usuário do Prometheus (ou servidor API) em http: // localhost: 9090 .
kubectl port-forward service/prometheus-service 9090
Implantar a configuração de escalonamento automático KEDA
Comando para criar
ScaledObject:
kubectl apply -f keda-prometheus-scaledobject.yaml
Verifique os registros do operador KEDA:
KEDA_POD_NAME=$(kubectl get pods -n keda
-o=jsonpath='{.items[0].metadata.name}')
kubectl logs $KEDA_POD_NAME -n keda
O resultado é mais ou menos assim:
time="2019-10-15T09:38:28Z" level=info msg="Watching ScaledObject:
default/prometheus-scaledobject"
time="2019-10-15T09:38:28Z" level=info msg="Created HPA with
namespace default and name keda-hpa-go-prom-app"
Verifique em aplicativos. Uma instância deve estar em execução porque
minReplicaCounté 1:
kubectl get pods -l=app=go-prom-app
Verifique se o recurso HPA foi criado com sucesso:
kubectl get hpa
Você deve ver algo como:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 0/3 (avg) 1 10 1 45s
Verificação de saúde: acesso ao aplicativo
Para acessar o endpoint REST de nosso aplicativo, execute:
kubectl port-forward service/go-prom-app-service 8080
Agora você pode acessar o aplicativo Go usando o endereço http: // localhost: 8080 . Para fazer isso, execute o comando:
curl http://localhost:8080/test
O resultado é mais ou menos assim:
Accessed on 2019-10-21 11:29:10.560385986 +0000 UTC
m=+406004.817901246
Access count 1
Verifique também o Redis neste ponto. Você verá que a chave
access_countaumentou para 1:
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
"1"
Certifique-se de que o valor da métrica
http_requestsseja o mesmo:
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 1
Criação de carga
Usaremos ei , um utilitário para gerar a carga:
curl -o hey https://storage.googleapis.com/hey-release/hey_darwin_amd64
&& chmod a+x hey
Você também pode baixar o utilitário para Linux ou Windows .
Executá-lo:
./hey http://localhost:8080/test
Por padrão, o utilitário envia 200 solicitações. Você pode verificar isso usando as métricas do Prometheus e também do Redis.
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 201
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
201
Confirme o valor real da métrica (retornado pela consulta PromQL):
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//output
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1571734214.228,"1.686057971014493"]}]}}
Nesse caso, o resultado real é igual
1,686057971014493e exibido no campo value. Isso não é suficiente para o dimensionamento, pois o limite que definimos é 3.
Mais carga!
No novo terminal, controle o número de pods de aplicativos:
kubectl get pods -l=app=go-prom-app -w
Vamos aumentar a carga usando o comando:
./hey -n 2000 http://localhost:8080/test
Depois de um tempo, você verá o HPA escalando a implantação e lançando novos pods. Verifique o HPA para ter certeza de:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 1830m/3 (avg) 1 10 6 4m22s
Se a carga não for constante, a implantação será reduzida ao ponto em que apenas um pod funciona. Se você quiser verificar a métrica real (retornada pela consulta PromQL), use o comando:
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
Limpeza
//Delete KEDA
kubectl delete namespace keda
//Delete the app, Prometheus server and KEDA scaled object
kubectl delete -f .
//Delete Redis
helm del --purge redis-server
Conclusão
O KEDA permite que você dimensione automaticamente suas implantações do Kubernetes (de / para zero) com base em dados de métricas externas. Por exemplo, com base nas métricas do Prometheus, comprimento da fila no Redis, latência do consumidor no tema Kafka.
O KEDA se integra a uma fonte externa e também fornece métricas por meio do Metrics Server para o pod autoescalador horizontal.
Boa sorte!
O que mais ler: