
O registro no diário é uma daquelas coisas que só é lembrada quando eles quebram. E isso não é crítica de forma alguma. A questão é que os logs como tais não geram dinheiro. Eles fornecem informações sobre o que os programas estão (ou têm feito), ajudando a manter coisas que nos fazem dinheiro funcionando. Em pequena escala (ou durante o desenvolvimento), as informações necessárias podem ser obtidas simplesmente exibindo mensagens em
stdout... Mas assim que você vai para um sistema distribuído, e imediatamente há a necessidade de agregar essas mensagens e enviá-las para algum repositório central, onde trarão o maior benefício. Essa necessidade é ainda mais relevante se você estiver lidando com contêineres em uma plataforma como o Kubernetes, onde os processos e o armazenamento local são temporários.
Uma abordagem familiar para processar registros
Desde o início dos contêineres e a publicação do manifesto dos Doze Fatores , um certo padrão geral se formou no processamento de toras geradas por contêineres:
- processa mensagens de saída para
stdoutoustderr, -
containerd(Docker) redireciona streams padrão para arquivos fora de contêineres, - e a cauda do encaminhador de log lê esses arquivos (ou seja, obtém as últimas linhas deles) e envia os dados para o banco de dados.
O popular encaminhador de log fluentd é um projeto CNCF (como o containerd). Com o tempo, ele se tornou o padrão de fato para ler, transformar, transferir e indexar logs. Ao criar um cluster Kubernetes no GKE com o Cloud Logging (antigo Stackdriver) conectado, você obterá quase o mesmo padrão - apenas com o sabor fluentd do Google.
Foi esse padrão que surgiu quando a Olark (a empresa para a qual trabalha o autor do artigo - transl. Aprox.)começou a migrar serviços para K8s como GKE há quatro anos. E quando superamos o log-as-a-service, esse padrão foi seguido, criando nosso próprio sistema de agregação de log capaz de processar 15-20 mil linhas por segundo em pico de carga.
Existem razões pelas quais essa abordagem funciona bem e porque os princípios dos 12 fatores recomendam diretamente a saída de logs para fluxos padrão . O fato é que permite que o aplicativo não se preocupe com o roteamento de log e torna os containers facilmente "observáveis" (estamos falando de observabilidade) durante o desenvolvimento ou na produção. E se o seu sistema de registro ficar confuso, pelo menos há alguma possibilidade de que os registros permaneçam nos discos do host do nó do cluster.
A desvantagem dessa abordagem é que os logs restantes são relativamente caros em termos de uso de CPU . Começamos a prestar atenção a isso depois que, durante a próxima otimização do sistema de registro, descobrimos que fluentd consome 1/8 de toda a cota de solicitações de CPU em produção:
- Isso se deve em parte à topologia do cluster: fluentd é hospedado em cada nó para arquivos locais de cauda (como DaemonSet , na linguagem K8s), você tem nós quad-core e precisa reservar 50% do núcleo para o processamento de logs e ... bem, essa é a ideia.
- Outra parte dos recursos é gasta em processamento de texto, que também atribuímos ao fluentd. Na verdade, quem perderia a oportunidade de limpar entradas de log ofuscadas?
- O restante vai para inotifywait , que monitora arquivos no disco, processa leituras e mantém o controle.
Queríamos saber quanto custa tudo isso: existem outras maneiras de enviar logs para o fluentd. Por exemplo, você pode usar a porta de encaminhamento (estamos falando sobre o uso de tipo
forwardem source- aprox. Transl.). Será mais barato?
Experimento prático
Para isolar o custo de buscar linhas de toras usando rejeitos, montei uma pequena bancada de teste . Inclui os seguintes componentes:
- Programa Python para criar um certo número de gravadores de log com frequência e tamanho de mensagem configuráveis;
- arquivo para docker compose executando:
- fluentd para processamento de logs,
- cAdvisor para monitorar o contêiner fluentd,
- Prometheus para coletar métricas cAdvisor,
- Grafana para visualização de dados no Prometheus.
Notas sobre este diagrama:
- Os gravadores de log geram mensagens em um formato JSON uniforme (que o container também usa) e podem gravá-las em arquivos ou encaminhá-las para a porta de encaminhamento fluentd.
- Ao gravar em arquivos, uma classe é usada
RotatingFileHandlerpara simular melhor as condições do cluster. - O Fluentd é configurado para "lançar" todos os registros
nulle não processar expressões regulares ou verificar os registros em relação a tags. Portanto, sua principal tarefa será obter as linhas de registro. - , Prometheus cAdvisor, fluentd.
A seleção dos parâmetros para comparação foi realizada de forma bastante subjetiva. Eu escrevi outro utilitário para estimar o volume de logs que são gerados por nós de nosso cluster. Não surpreendentemente, ele varia amplamente: de várias dezenas de linhas por segundo a 500 ou mais nos nós mais ocupados.
Esta é outra fonte de problemas: se estiver usando um DaemonSet, o fluentd deve ser configurado para lidar com os nós mais ocupados no cluster. Em princípio, o desequilíbrio pode ser evitado atribuindo rótulos apropriados aos geradores de log principais e usando regras suaves de antiafinidade para distribuí-los uniformemente, mas isso está além do escopo deste artigo. Inicialmente, planejei comparar diferentes mecanismos de "entrega" de logscom uma carga de 500/1000 linhas por segundo usando 1 a 10 gravadores de log.
Resultado dos testes
Os primeiros testes mostraram que as linhas por segundo foram o principal contribuinte para a utilização da CPU no tailing , independentemente de quantos arquivos de log observamos. Os dois gráficos abaixo comparam a carga em 1000 p / s de um gravador de log e de 10. Pode-se ver que eles são quase iguais:
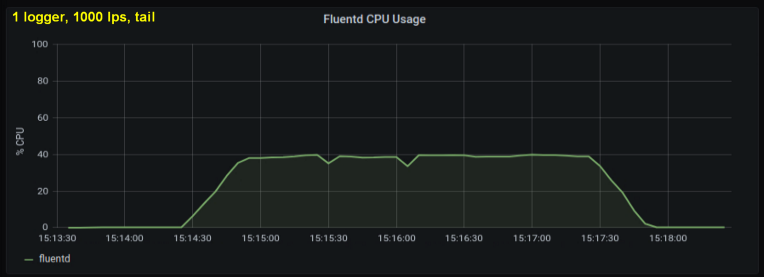
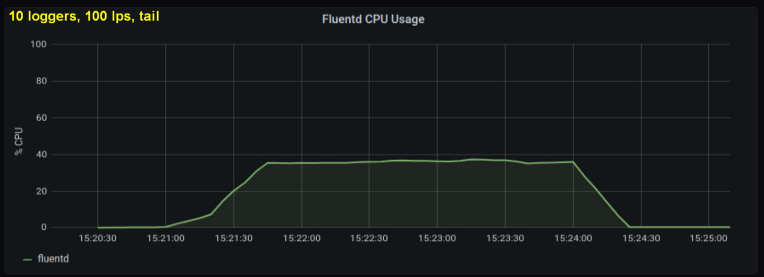
Uma pequena digressão: eu não incluí o gráfico correspondente aqui, mas na minha máquina descobri que dez processos de log gravar 100 linhas por segundo tem um rendimento agregado maior do que um único processo gravar 1000 linhas por segundo. Isso pode ser devido às especificações do meu código - eu não me concentrei neste problema deliberadamente.
Em qualquer caso, eu esperava que o número de arquivos de log abertos fosse um fator significativo, mas descobri que isso realmente não afeta os resultados. Outra variável insignificante semelhante é o comprimento da corda. O teste acima usou um comprimento de string padrão de 100 caracteres. Fiz execuções com linhas dez vezes mais longas, mas isso não teve um efeito perceptível na carga do processador durante o teste, que em todos os casos foi de 180 segundos.
Considerando o exposto, decidi testar 2 escritores, pois me pareceu que um processo estava atingindo um limite interno. Por outro lado, também não foram necessários mais processos. Fiz testes com 500 e 1000 linhas por segundo. O seguinte conjunto de gráficos mostra os resultados para os arquivos de cauda e a porta de encaminhamento:

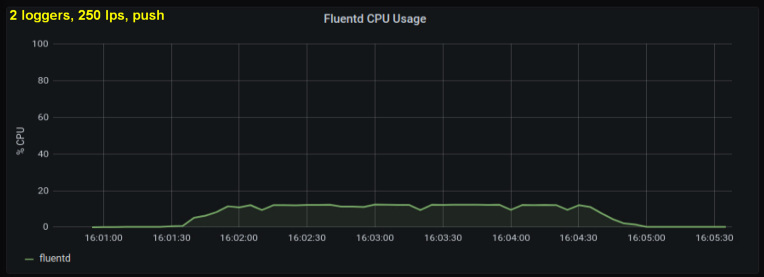
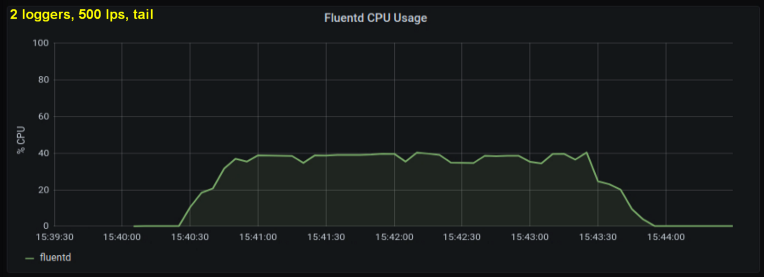

conclusões
Ao longo de uma semana, executei esses testes de muitas maneiras diferentes e terminei com duas conclusões importantes:
- O método com um soquete de encaminhamento consome consistentemente 30-50% menos poder de processamento do que ler linhas de arquivos de log com o mesmo tamanho. Uma explicação possível (para pelo menos parte da diferença observada) é que serializando os dados no pacote de mensagens - fluentd. fluentd , messagepack. , Python- forward-, . , : , fluentd, .
- , CPU , . tailing', forward-. , (1000 writer' 10 writer'), forward-:


Esses resultados significam que todos devemos gravar logs no soquete em vez de arquivos? Obviamente, não é tão simples ...
Se pudéssemos mudar a maneira como coletamos logs tão facilmente, a maioria dos problemas existentes não seriam problemas. A saída de logs
stdouttorna muito mais fácil monitorar e trabalhar com contêineres durante o desenvolvimento. A saída de logs de ambas as maneiras, dependendo do contexto, aumentará muito a complexidade - da mesma forma, configurar fluentd para renderizar logs durante o desenvolvimento (por exemplo, usando o plugin de saída stdout) irá aumentá-la .
Talvez uma interpretação mais prática desses resultados seja uma recomendação para ampliar os nós... Como o fluentd deve ser configurado para funcionar com os nós mais ocupados (mais ruidosos), faz sentido reduzir o número de nós. Combinado com um mecanismo de antiafinidade que distribuiria os principais geradores de log uniformemente, seria uma ótima estratégia. Infelizmente, o redimensionamento de nós envolve muitas nuances e compensações que vão muito além das necessidades do sistema de registro.
Escala obviamente também importa... Em pequena escala, o inconveniente e a complexidade adicional talvez sejam impraticáveis. Além disso, geralmente existem problemas mais urgentes. Se você está apenas começando e o cheiro de "tinta fresca" não desapareceu do processo de engenharia, você pode padronizar seu formato de registro com antecedência e cortar custos usando o método de soquete sem sobrecarregar os desenvolvedores.
Para quem trabalha com projetos de grande escala, as conclusões deste artigo são inadequadas, porque empresas como o Google fizeram uma análise do problema muito mais completa e com conhecimento intensivo (em comparação com a minha). Nessa escala, obviamente, você está implantando seus próprios clusters e pode fazer o que quiser com o pipeline de registro (em outras palavras, aproveite as duas abordagens).
Para concluir, deixe-me antecipar algumas perguntas e respondê-las com antecedência. Primeiro, “Não é este artigo sobre fluentd realmente? E o que isso tem a ver com o Kubernetes em geral ? " ... A resposta para os dois lados dessa pergunta é: "Bem, talvez ."
- No meu conhecimento e experiência gerais, essa ferramenta é uma ocorrência comum ao rastrear arquivos no Linux em situações onde há muita E / S de disco. Não fiz testes com outro encaminhador de log como o Logstash , mas seria interessante ver os resultados.
- Kubernetes, CPU, , . , , . , Kubernetes, tailing' Kubernetes-as-a-Service.
Por fim, algumas palavras sobre outro recurso consumível - a memória . Inicialmente, eu iria incluí-lo no artigo: um painel especialmente preparado para isso mostra o uso de memória do fluentd. Mas no final descobriu-se que esse fator não é importante. De acordo com os resultados do teste, a quantidade máxima de memória usada não excedeu 85 MB, com a diferença entre os testes individuais raramente excedendo 10 MB. Este consumo de memória bastante baixo é obviamente devido ao fato de que eu não usei plug-ins de saída em buffer. Mais importante, acabou sendo quase o mesmo para os dois métodos. E o artigo já estava ficando muito volumoso ...
Deve-se observar que existem muitos outros "cantos" que você pode examinar se quiser fazer testes mais aprofundados. Por exemplo, você pode descobrir em quais estados do processador e chamadas do sistema fluentd passa a maior parte do tempo, mas para fazer isso, é necessário fazer o invólucro apropriado para ele.
PS do tradutor
Leia também em nosso blog: