
Foto do site Unsplash . Autor: Hitesh Choudhary
Obter o mesmo resultado em Python que com uma consulta SQL
Freqüentemente, ao trabalhar no mesmo projeto, temos que alternar entre SQL e Python. Dito isso, alguns de nós estão familiarizados com a manipulação de dados em consultas SQL, mas não em Python, o que prejudica nossa eficiência e produtividade. Na verdade, usando o Pandas, você pode obter o mesmo resultado em Python e em consultas SQL.
Começo do trabalho
O pacote Pandas precisa ser instalado se não estiver lá.
conda install pandasEstaremos usando o famoso conjunto de dados Titanic de Kaggle .
Depois de instalar o pacote e baixar os dados, precisamos importá-lo para nosso ambiente Python.

Usaremos um DataFrame para armazenar dados. Várias funções do Pandas nos ajudarão a gerenciar essa estrutura de dados.
SELECIONE, DISTINTO, CONTAGEM, LIMITE
Vamos começar com consultas SQL simples que usamos muito.
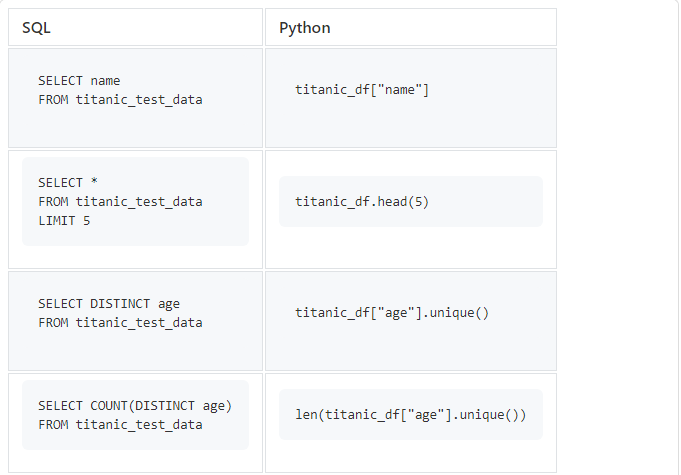
titanic_df["age"].unique()retornará uma matriz de valores únicos, então teremos que usar len()para contar seu número.
SELECT, WHERE, OR, AND, IN (SELECT com condições)
Após a primeira parte, você aprendeu como explorar um DataFrame de maneiras simples. Agora vamos tentar fazer isso com algumas condições (esta é uma instrução
WHEREem SQL).

Se quisermos apenas selecionar colunas específicas do DataFrame, podemos fazer isso com um par extra de colchetes.
Observação: se você estiver selecionando várias colunas, deverá colocar a matriz
["name","age"]entre colchetes.
isin()funciona exatamente da mesma forma que INnas consultas SQL. Para usar NOT IN, em Python, precisamos usar negação (~).
GROUP BY, ORDER BY, COUNT
GROUP BYe ORDER BYtambém são instruções SQL populares para mineração de dados. Agora vamos tentar usá-los em Python.

Se quisermos classificar apenas uma coluna COUNT, podemos simplesmente passar um valor booleano para o método
sort_values. Se vamos classificar várias colunas, devemos passar um array de booleanos para o método sort_values.
O método
sum()retornará as somas de cada uma das colunas do DataFrame, que podem ser agregadas numericamente. Se quisermos apenas uma coluna específica, precisamos especificar o nome da coluna usando colchetes.
MIN, MAX, MEAN, MEDIAN
Finalmente, vamos tentar algumas das funções estatísticas padrão que são importantes ao explorar dados.
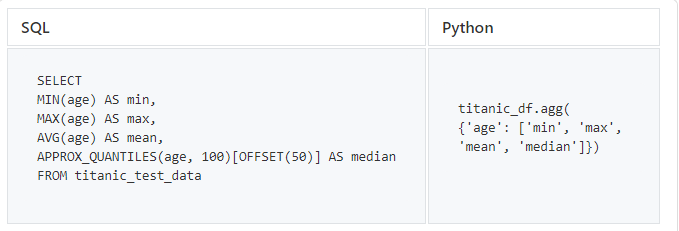
O SQL não contém operadores que retornam o valor mediano, então usamos o BigQuery para obter o valor mediano da coluna de idade. No
APPROX_QUANTILES
Pandas, o método de agregação
.agg()também oferece suporte a outras funções, por exemplo sum.
Agora você aprendeu como reescrever consultas SQL em Python usando Pandas . Espero que você ache este artigo útil.
Todo o código pode ser encontrado em meu repositório Github .
Obrigado pela atenção!