
Várias opções de visualização nos ajudarão com isso :
Visualização de texto reduzida
O texto original de um plano bastante simples já causa problemas na análise:
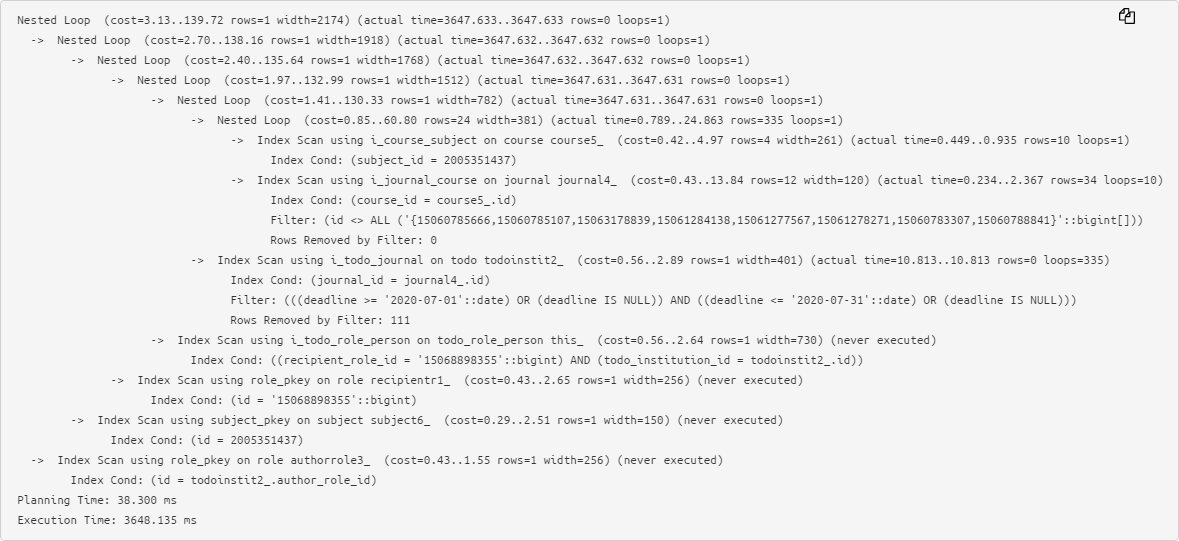
Portanto, preferimos a forma abreviada, quando as principais informações sobre o tempo de execução e buffers usados de cada nó são retiradas à esquerda e à direita , e é muito fácil perceber os máximos:
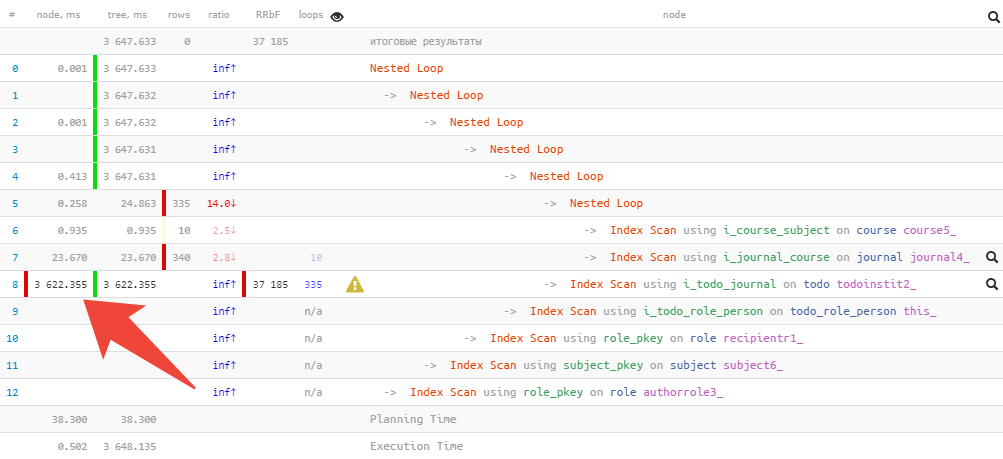
Gráfico de pizza
Mas às vezes até mesmo entender “onde dói mais” não é fácil, especialmente se contiver várias dezenas de nós e mesmo a forma reduzida do plano leva de 2 a 3 telas.

Nesse caso, o gráfico de pizza usual virá em nosso socorro:
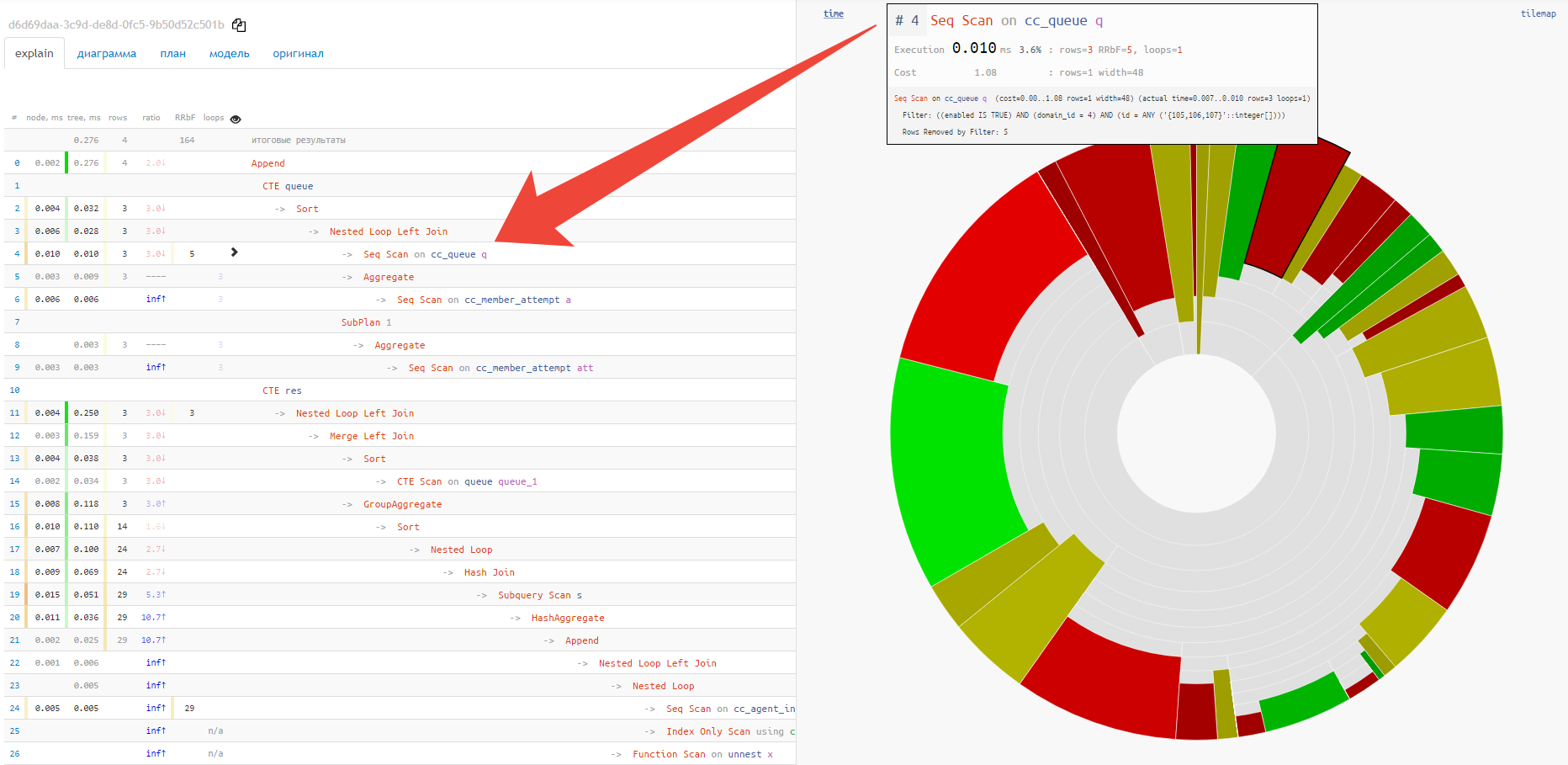
imediatamente, de improviso, você pode ver a parcela aproximada do consumo de recursos por cada um dos nós. Quando passarmos o mouse sobre ele, à esquerda na visualização de texto, veremos um ícone para o nó selecionado.
Telha
Infelizmente, o gráfico de partes não mostra a relação entre nós diferentes e os pontos "mais quentes". Para isso, a opção "tile" é muito mais adequada:
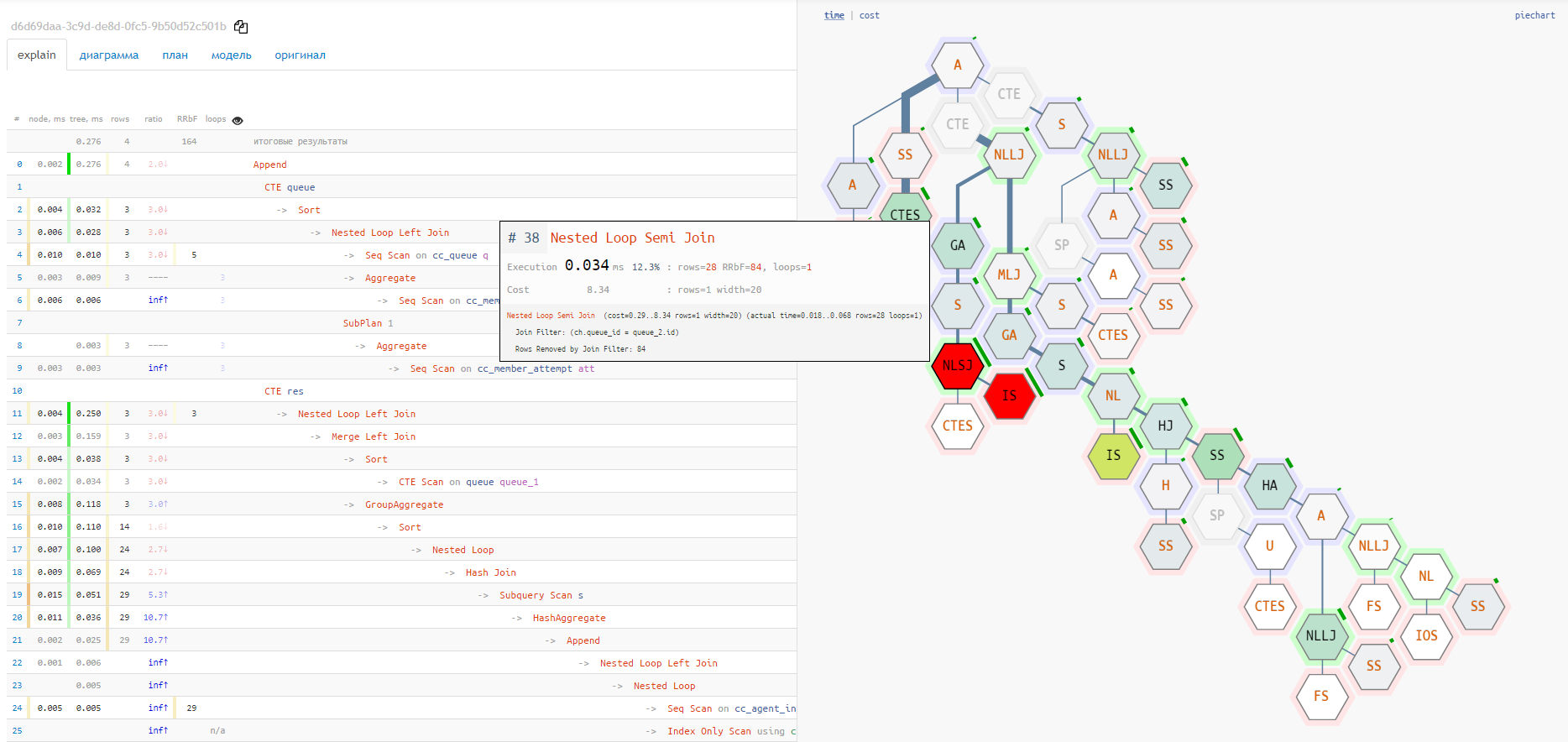
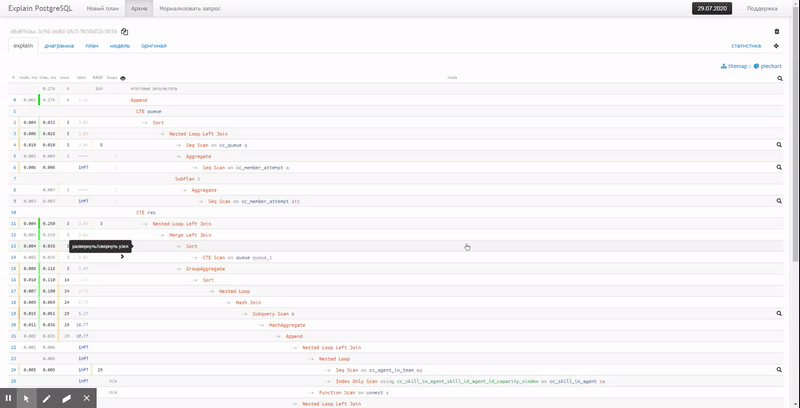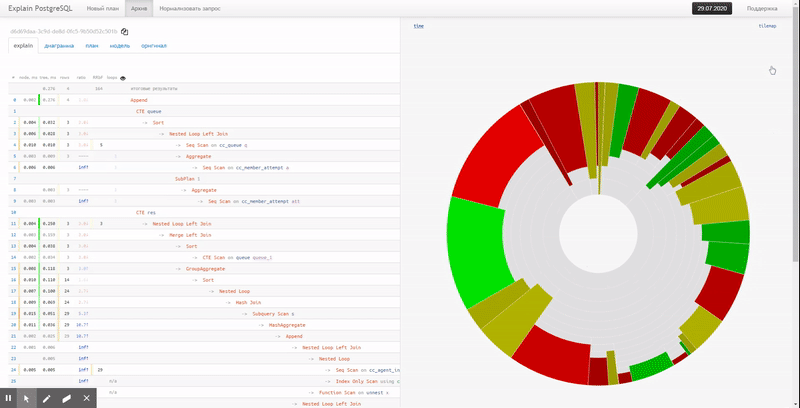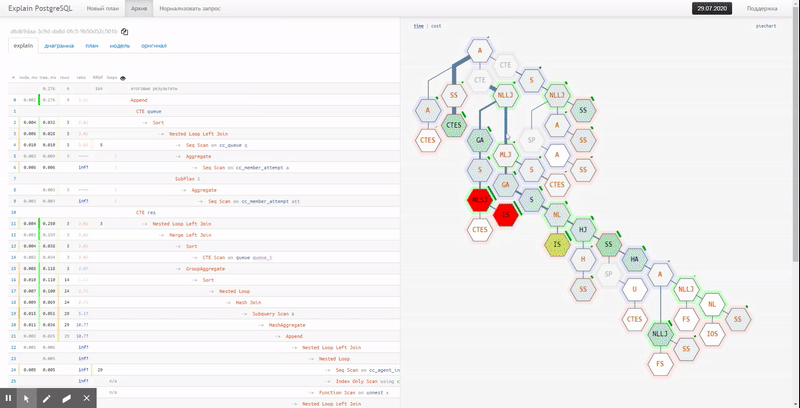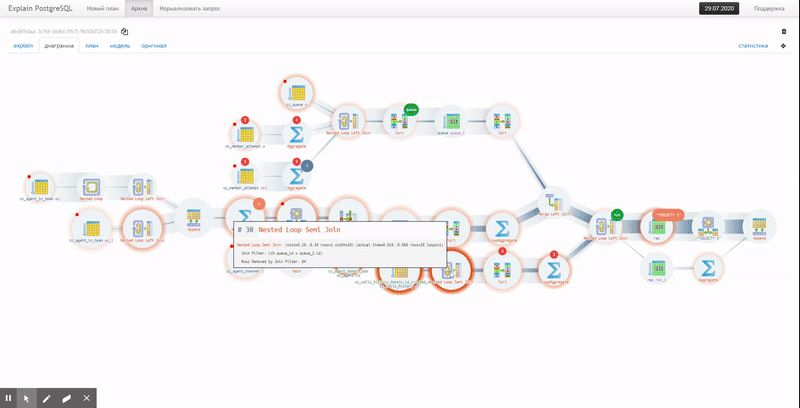
Diagrama de execução
Mas ambas as opções não mostram a cadeia completa de anexos de nós de serviço
CTE/InitPlain/SubPlan- ela só pode ser vista no diagrama de execução real:

Mais métricas necessárias!
Se você fotografar o plano de execução real da consulta como
EXPLAIN (ANALYZE), verá apenas o tempo decorrido lá . Mas muitas vezes isso não é suficiente para conclusões corretas!
Por exemplo, ao executar uma consulta em um cache "frio", você receberá (mas não verá!) O horário de recebimento dos dados da mídia, e não o trabalho da consulta em si.
Portanto, algumas recomendações:
- Use para ver o volume de páginas de dados sendo subtraídas. Esse valor praticamente não está sujeito a oscilações da carga do próprio servidor e pode ser usado como métrica para otimização.
EXPLAIN (ANALYZE, BUFFERS) - Use
track_io_timingpara entender exatamente quanto tempo demorou para trabalhar com a transportadora .
E se o seu plano contém não apenas tempo , mas também
buffersou i/o timings, então, em cada uma das opções de diagrama, você pode alternar para o modo de análise para essas métricas. Às vezes, você pode ver imediatamente, por exemplo, que mais da metade de todas as leituras caiu em um único nó de problema:

Artigos anteriores sobre o assunto: