Em minha palestra no Y.Subbotnik Pro, lembrei o que e como terminamos na montagem e arquitetura do "projeto moderno padrão" e quais resultados obtivemos.
- Há um ano e meio trabalho na equipe de arquitetura do Serp. Desenvolvemos runtime e montagem de novo código em React e TypeScript lá.
Vamos falar sobre nossa dor comum que esta palestra abordará. Quando você quiser fazer um pequeno projeto no React, você só precisa usar um conjunto padrão de ferramentas chamado três letras - CRA. Isso inclui scripts de construção, scripts para execução de testes, configuração de um ambiente de desenvolvimento e tudo já foi feito para produção. Tudo é feito de forma muito simples por meio de scripts NPM, e provavelmente todos sabem sobre isso que têm experiência com React.
Mas suponha que o projeto cresça, tenha muito código, muitos desenvolvedores, recursos de produção apareçam, como traduções, sobre as quais o Create React App não sabe nada. Ou você tem algum tipo de pipeline de CI / CD complexo. Em seguida, os pensamentos começam a fazer uma ejeção para usar Create React App como base e personalizá-lo para seu próprio projeto. Mas não está absolutamente claro o que o espera lá, por trás dessa ejeção. Porque quando você faz uma ejeção diz que é uma operação muito perigosa, não vai ser possível devolvê-la e assim por diante, muito assustador. Aqueles que pressionaram ejetar sabem que muitas configurações são lançadas por aí, o que você precisa entender. Em geral, existem muitos riscos e não está claro o que fazer.
Vou te contar como foi conosco. Primeiro, sobre nosso projeto. Nosso projeto de front-end é o Serp, Search Engine Results Pages, Yandex search results pages que todos já viram. Desde 2018, não estamos movendo React e TypeScript. Cerca de 12 megabytes de código já foram escritos em Serpa no ano passado. Existem alguns estilos e muitos códigos TS e SCSS. Quantos no começo, em 2018, tinha, eu não escrevia, é muito pouco, tinha um salto muito forte.
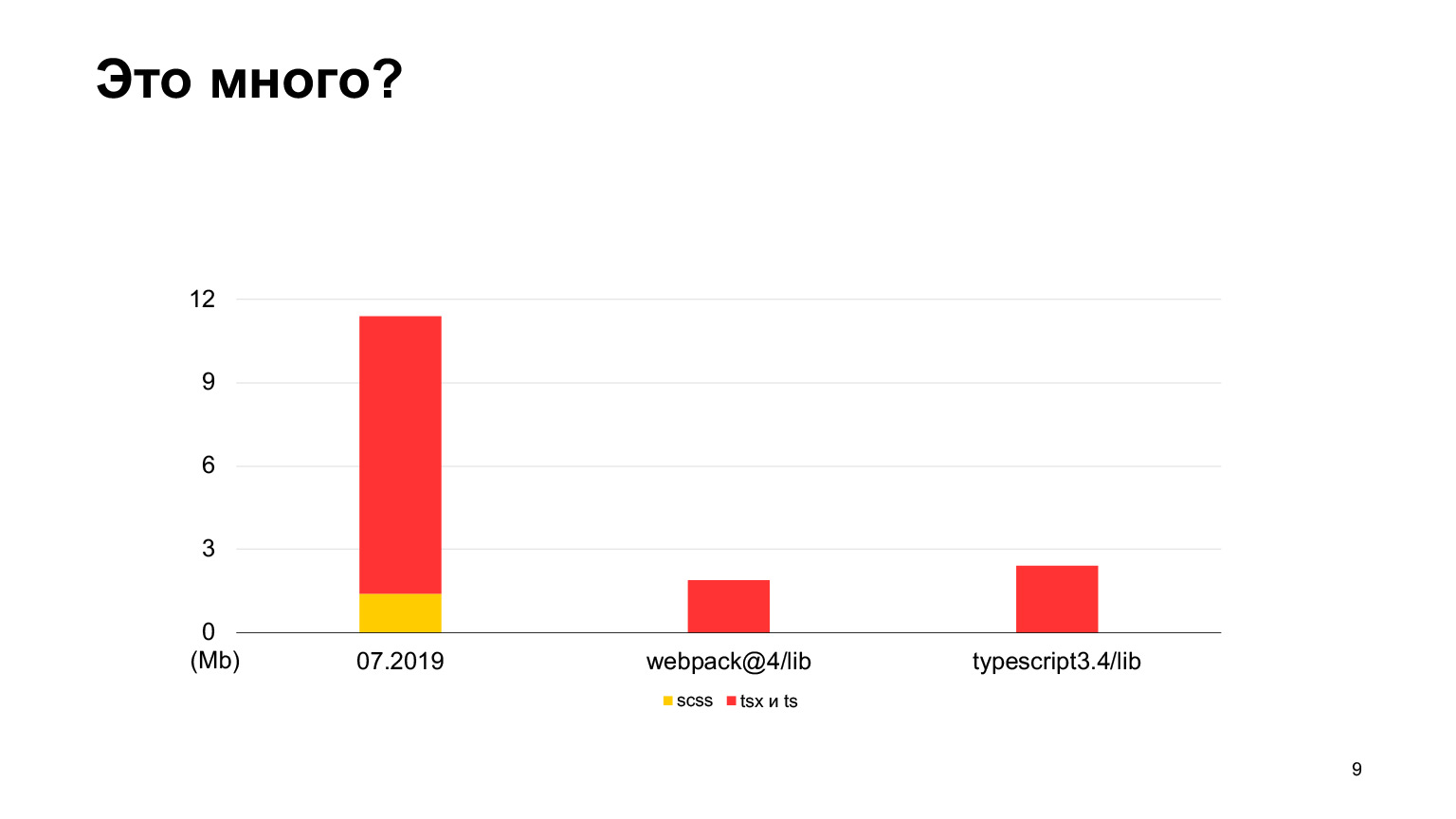
Vamos ver se isso é muito código ou não. Em comparação com o código-fonte do webpack-4, há muito menos código no webpack-4. Até mesmo o repositório TypeScript tem menos código.
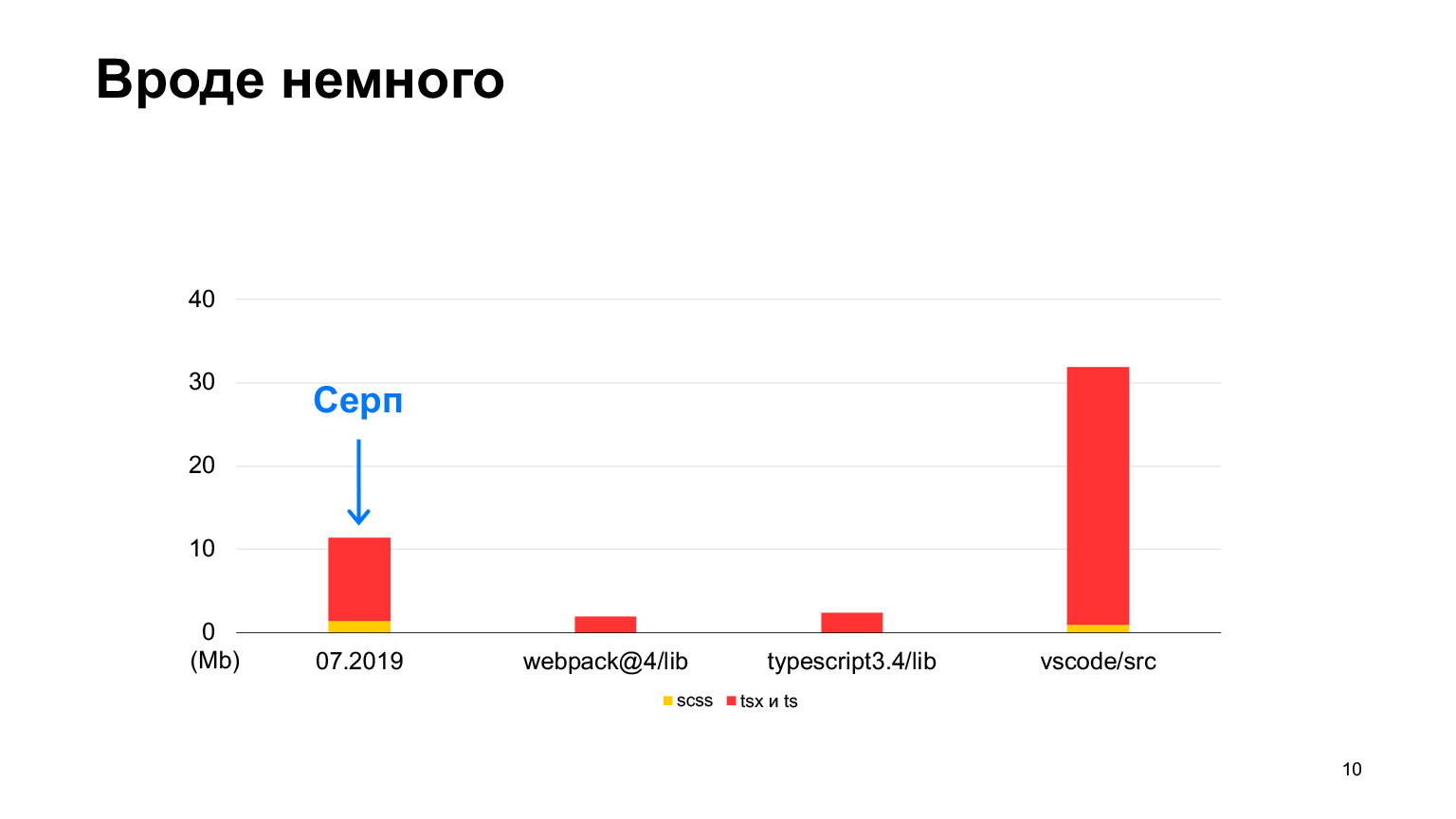
Mas o vs-code contém mais código, um bom projeto com até 30 megabytes de código TypeScript. Sim, também é escrito em TypeScript, e o Sickle parece ser menor. Em 2018, começamos, em 2019 havia 12 megabytes e 70 de nossos desenvolvedores trabalharam, fazendo 100 solicitações de pull por semana. Em um ano, eles triplicaram esse tamanho e receberam exatamente 30 megabytes. Fiz medições este mês, temos um total de 30 megabytes de código agora, e isso já é mais do que no vs-code.
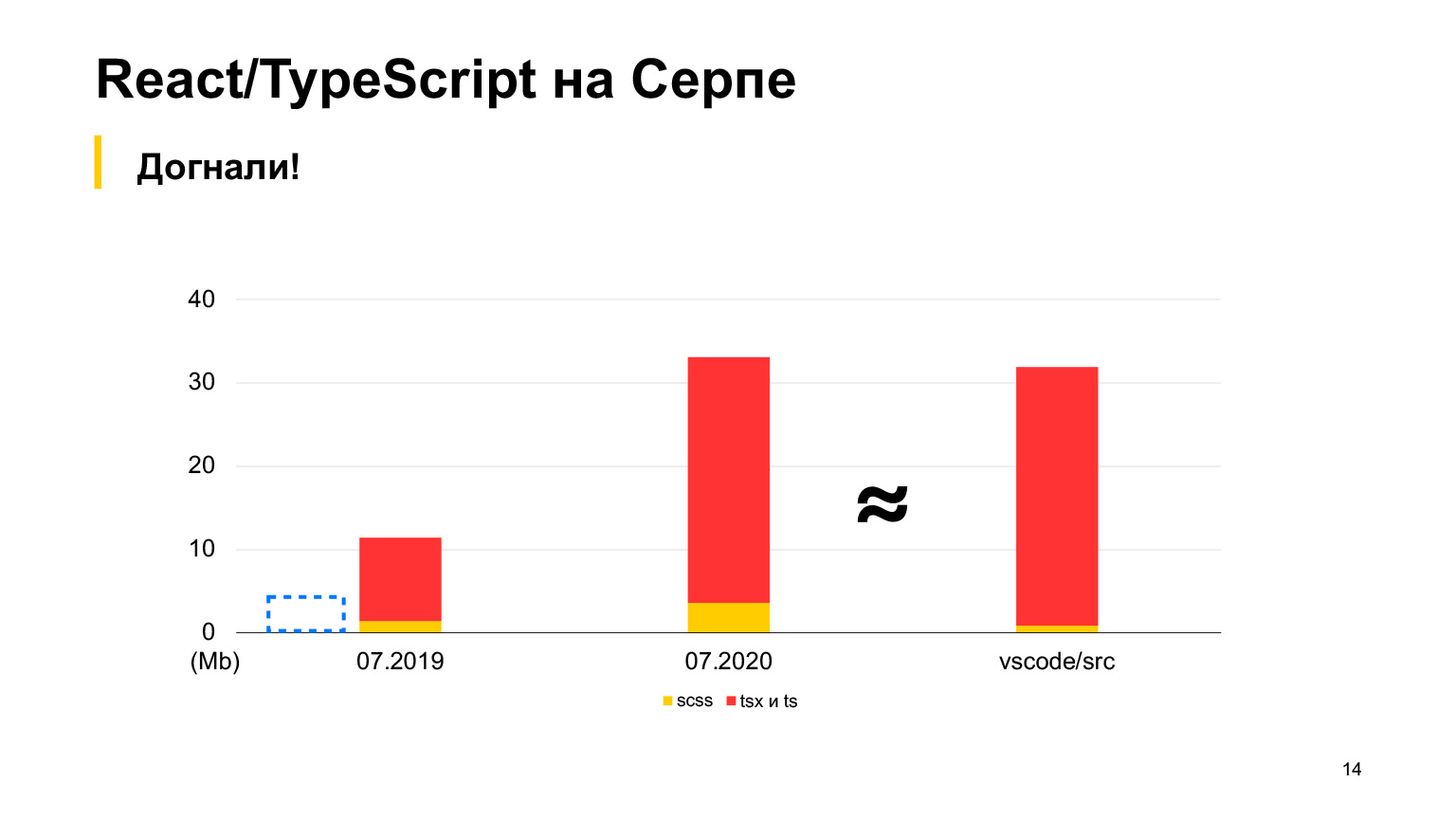
Aproximadamente igual, mas um pouco mais. Esta é a ordem do nosso projeto.
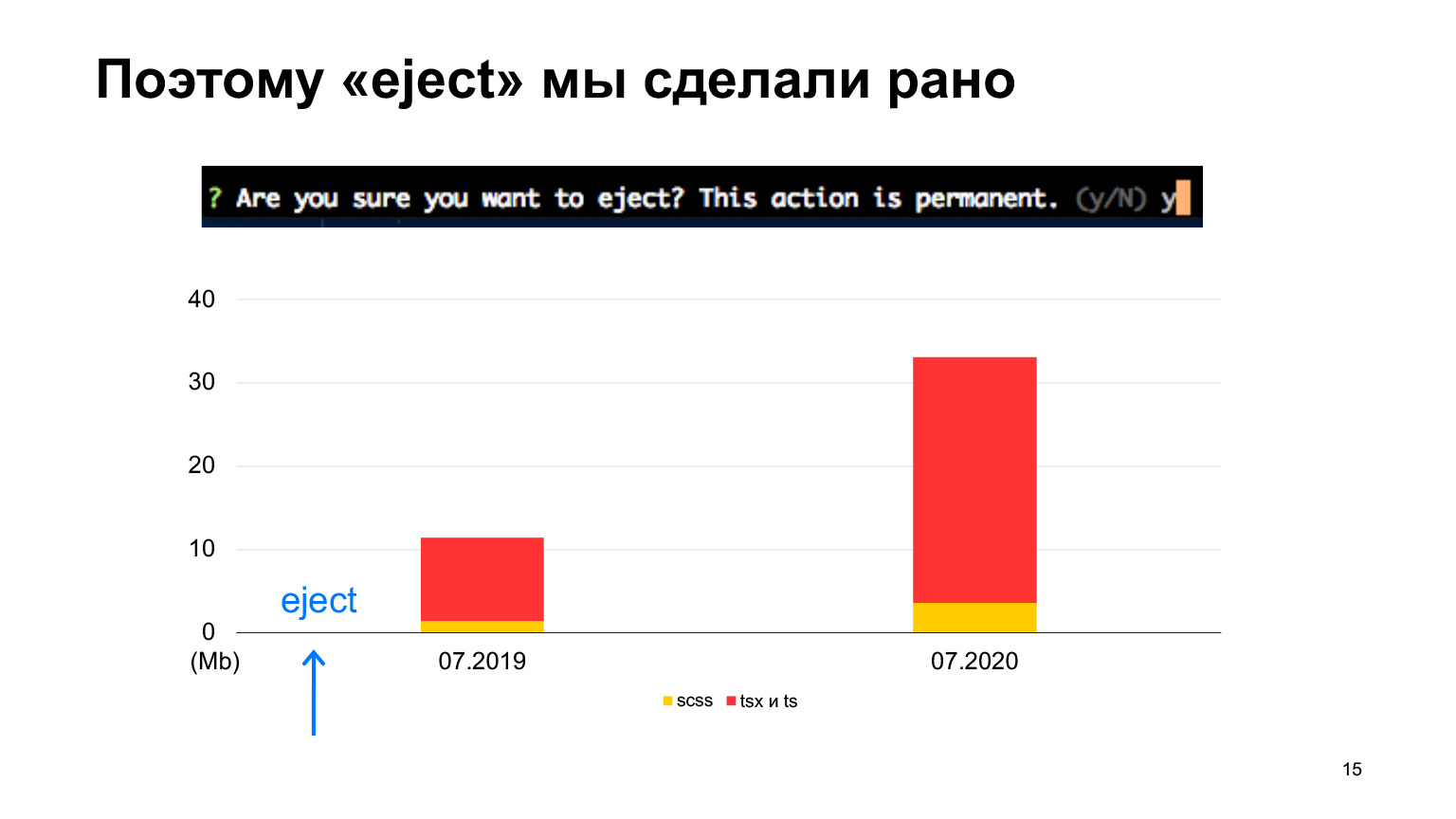
E ejetamos logo no início, porque sabíamos imediatamente que teríamos muito código e, muito provavelmente, as configurações iniciais que estão em Create React App não funcionariam para nós. Mas começamos da mesma forma, com o aplicativo Create React.
Então é sobre isso que a história será. Queremos compartilhar nossa experiência, dizer o que tivemos que fazer com o aplicativo Create React para que o Yandex Serp funcionasse corretamente nele. Ou seja, como conseguimos carregamento e inicialização rápidos no navegador, e como tentamos não desacelerar a construção, quais configurações, plug-ins e outras coisas usamos para isso. E, naturalmente, os resultados que alcançamos virão no final.

Como raciocinamos? A ideia original era que nosso Sickle é uma página que precisa ser renderizada muito rapidamente, porque, basicamente, há resultados de texto muito simples, então precisamos de modelos do lado do servidor, porque essa é a única maneira de obter uma renderização rápida. Ou seja, temos que desenhar algo antes mesmo de algo começar a ser inicializado no cliente.
Ao mesmo tempo, queria fazer o tamanho mínimo da estática, para não carregar nada supérfluo e a inicialização também fosse rápida. Ou seja, queremos a primeira renderização e a inicialização rápida.

O que o aplicativo Create React nos oferece? Infelizmente, não nos oferece nada sobre a renderização do servidor.
Diz que a renderização do servidor não é compatível com o aplicativo Create React. Além disso, Create React App tem apenas uma entrada para todo o aplicativo. Ou seja, por padrão, um grande pacote é coletado para toda a sua enorme variedade de páginas. Isso é muito. É claro que de 30 megabytes, cerca de metade são do tipo TS, mas ainda assim muitos códigos irão direto para o navegador.
Ao mesmo tempo, Create React App tem algumas boas configurações, por exemplo, o tempo de execução do webpack vai para lá em um pedaço separado. Ele é carregado separadamente, pode ser armazenado em cache porque não muda normalmente.
Além disso, os módulos de node_modules também são coletados em blocos separados. Eles também raramente mudam e, portanto, também são armazenados em cache pelo navegador, isso é ótimo, isso deve ser salvo. Mas, ao mesmo tempo, não há nada sobre traduções no aplicativo Create React.
Vamos montar nossa lista de como, em nosso caso, a lista de recursos de nossa plataforma deve se parecer. Primeiro, queremos renderizar ao norte, como eu disse, para fazer uma renderização rápida. Além disso, gostaríamos de ter um arquivo de entrada separado para cada resultado da pesquisa.

Se, por exemplo, Serpa tem uma calculadora, então gostaríamos que o pacote com a calculadora fosse entregue, e o pacote com o tradutor não precisa ser entregue rapidamente. Se tudo isso for coletado em um grande pacote, então tudo sempre irá embora, mesmo que metade dessas coisas não seja sobre um problema específico.
Além disso, gostaria de fornecer módulos comuns em partes separadas para não carregar o que já foi carregado.
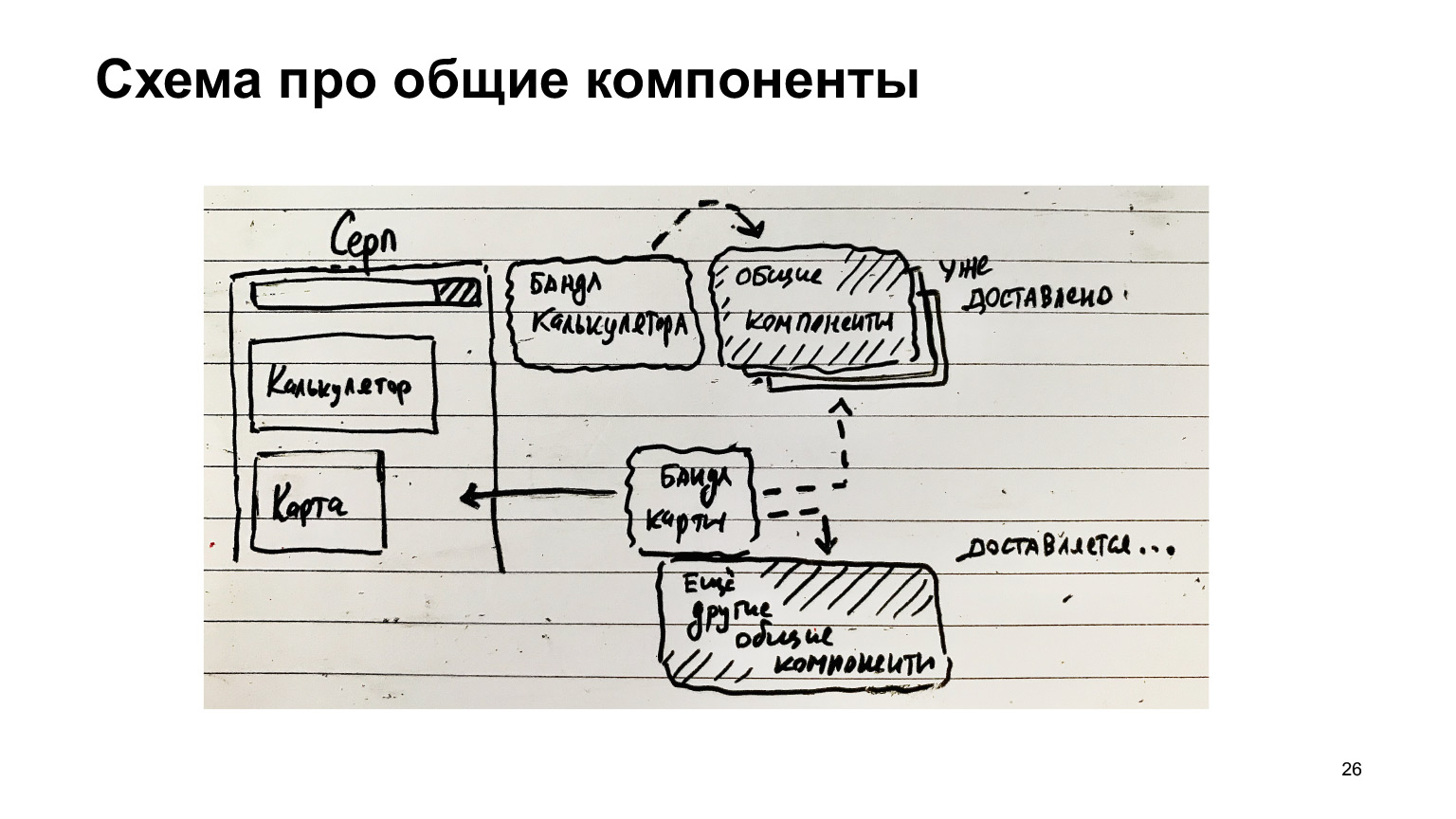
Aqui está outro exemplo com a foice. Ele tem uma calculadora, há um pacote de calculadora. Existem componentes comuns. Eles foram entregues ao cliente. Em seguida, outro recurso apareceu - um mapa. Dirigiu um pacote de mapas e outros componentes comuns, exceto aqueles que já foram entregues.
Se os componentes comuns são coletados separadamente, então há uma grande oportunidade para otimização e apenas o que é necessário é entregue, apenas diff. E os módulos mais populares que estão sempre na página, por exemplo, o tempo de execução do webpack, que é sempre necessário para toda essa infraestrutura, deve estar sempre carregado.
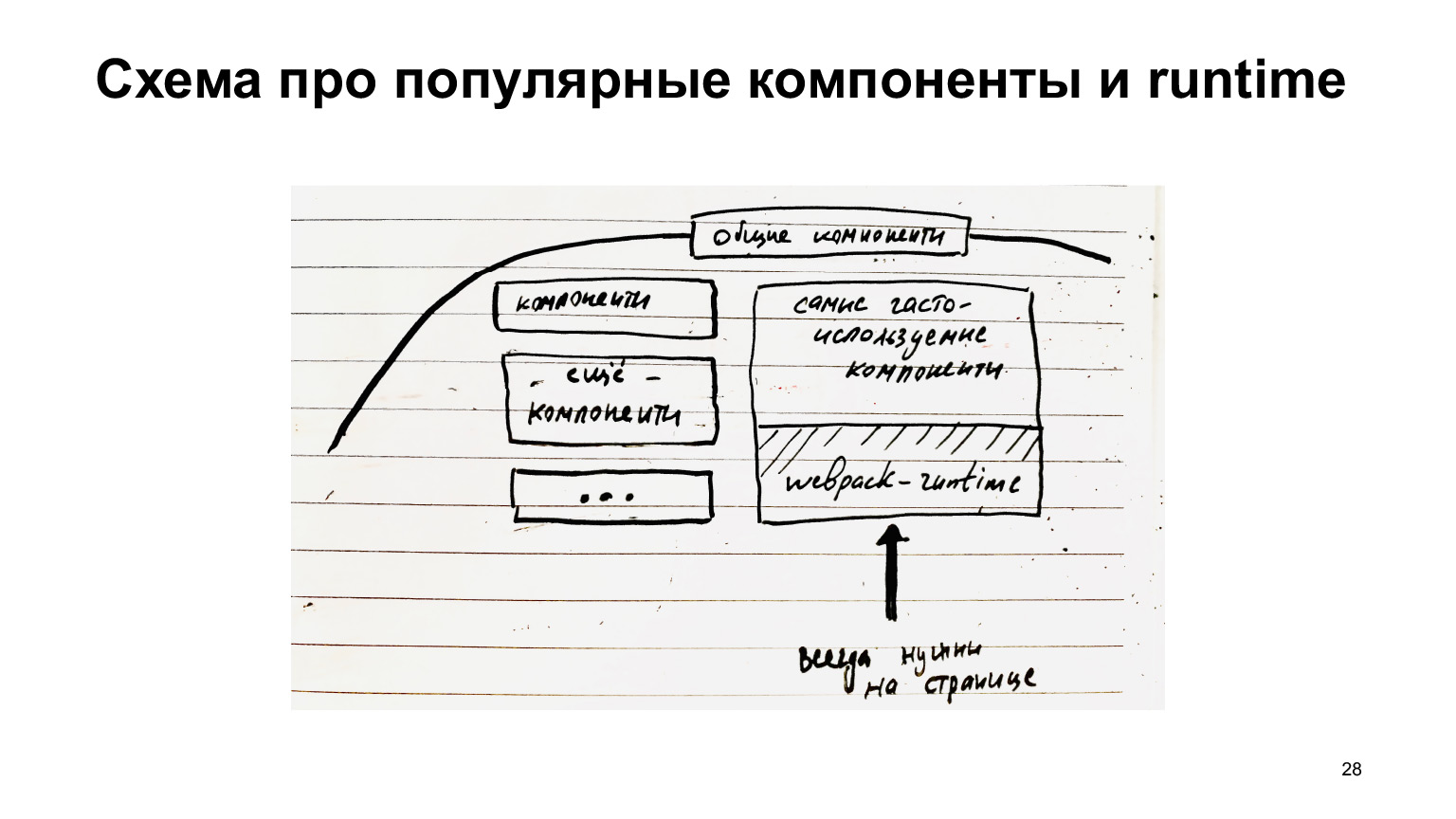
Portanto, faz sentido coletar em um bloco separado. Ou seja, esses componentes comuns também podem ser divididos em componentes que nem sempre são necessários e componentes que são sempre necessários. Eles podem ser coletados em um arquivo separado e sempre carregados, e também armazenados em cache, pois esses componentes comuns, como botões / links, não mudam com muita frequência, em geral, obtêm lucro com o cache.

E, ao mesmo tempo, você precisa tomar uma decisão sobre a montagem das traduções.

Tudo está bastante claro aqui. Se formos para o Turco Serp, gostaríamos de baixar apenas as traduções em turco, e não baixar todas as outras traduções, porque este é um código extra.
O que nós fizemos? Primeiro, sobre o código do servidor. A respeito disso, teremos duas direções - construindo para produção e lançando para dev.
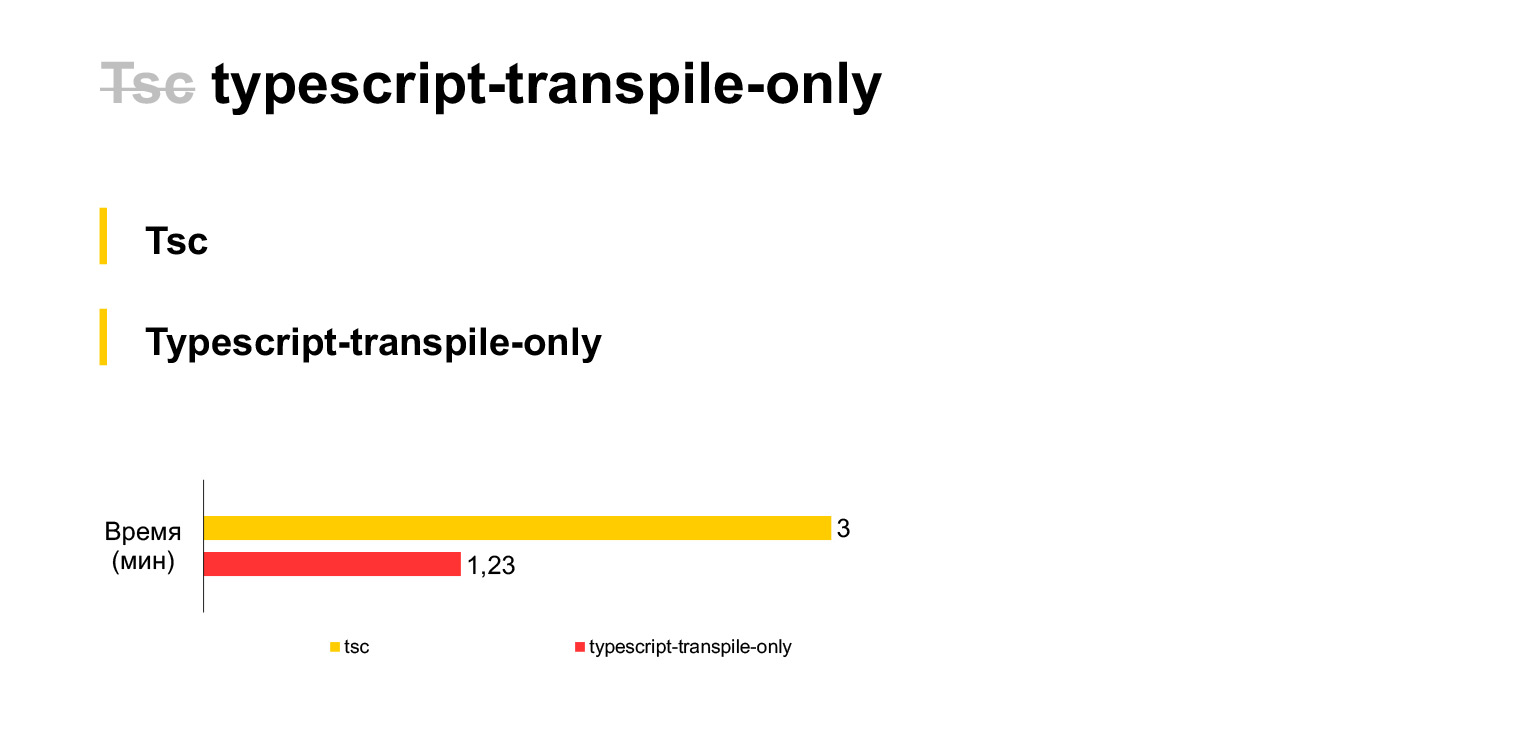
Em geral, você precisa fazer uma declaração separada sobre o TypeScript primeiro. Normalmente os projetos, como ouvi dizer, usam babel. Mas decidimos imediatamente usar o compilador TypeScript padrão, porque acreditamos que novos recursos do TypeScript o alcançariam mais rápido. Portanto, abandonamos imediatamente o babel e usamos o tsc.
Portanto, este nosso tamanho de código atual, nossos 30 megabytes, são compilados em um laptop em três minutos. Bastante. Se você abandonar a verificação de tipo e usar um fork tsc durante cada compilação (infelizmente, o TSC não tem uma configuração que desabilite a verificação de tipo, você tem que fazer um fork), então você pode economizar o dobro do tempo. A compilação do nosso código levará apenas um minuto e meio.
Por que não podemos verificar o tipo em tempo de compilação? Porque nós, por exemplo, podemos verificá-los em ganchos de pré-confirmação. Faça um linter que só executará a verificação de tipo e a própria montagem poderá ser feita sem a verificação de tipo. Tomamos essa decisão.
Como executamos no dev? Dev normalmente também usa um pacote de babel com webpack, mas usamos uma ferramenta como ts-node.

Esta é uma ferramenta muito simples. Para executá-lo, é suficiente escrever este require (ts-node) no arquivo JavaScript de entrada, e ele substituirá os require-s de todo o código TS posteriormente neste processo. E se um código TS for carregado nesse processo ao longo do caminho, ele será compilado em tempo real. Uma coisa muito simples.
Naturalmente, existe uma pequena sobrecarga associada ao fato de que, se o arquivo ainda não foi carregado neste processo, ele deve ser recompilado. Mas, na realidade, essa sobrecarga é mínima e geralmente aceitável.
Além disso, existem algumas linhas mais interessantes nesta lista. A primeira é ignorar estilos, porque não precisamos de estilos para modelos do lado do servidor. Precisamos apenas obter HTML. Portanto, também usamos esse módulo - ignore-styles. E, além disso, desligamos a verificação de tipo (apenas transpilar), como fizemos no TSC, para agilizar o trabalho do nó ts.
Passando para o código do cliente. Como coletamos o código ts no webpack? Usamos ts-loader e a opção transpileOnly, ou seja, praticamente o mesmo pacote. Em vez de babel-loader, ferramentas ts-loader e transpileOnly mais ou menos padrão.
Infelizmente, a construção incremental não funciona no ts-loader. Afinal, o ts-loader não é uma ferramenta padrão e não é feito pelos mesmos caras que fazem o TypeScript. Portanto, nem todas as opções do compilador são suportadas lá. Por exemplo, a construção incremental não é suportada.
Uma construção incremental é algo que pode ser muito útil no desenvolvimento. Da mesma forma, você pode adicionar esses caches ao pipeline. Em geral, quando suas alterações são pequenas, você não pode recompilar completamente tudo, todo o TypeScript, mas apenas o que mudou. Funciona de forma bastante eficaz.
Em geral, para fazer sem compilações incrementais, usamos o cache-loader. Esta é a solução padrão do webpack. Tudo está bem claro. Quando o código TypeScript tenta se conectar durante uma construção do webpack, ele é processado pelo compilador, adicionado ao cache e, da próxima vez, se não houver mudanças nos arquivos de origem, o cache-loader não executará o ts-loader e o retirará do cache. Ou seja, tudo é bastante simples aqui.
Ele pode ser usado para qualquer coisa, mas especificamente para TypeScript é uma coisa útil, porque ts-loader é um carregador bastante pesado, então o cache-loader é muito apropriado aqui.

Mas o cache-loader tem uma desvantagem - ele funciona com o tempo de modificação do arquivo. Aqui está um trecho do código-fonte. E não funcionou para nós.

Tivemos que bifurcar e refazer o algoritmo de cache com base no hash do conteúdo do arquivo, porque não era adequado para usarmos o cache-loader no pipeline.
O fato é que, quando você deseja reutilizar os resultados da compilação entre várias solicitações pull, esse mecanismo não funcionará. Porque se a montagem foi, por exemplo, há muito tempo. Em seguida, você tenta fazer uma nova solicitação de pull, que não altera os arquivos que foram coletados na vez anterior.
Mas seu mtime é mais recente. Conseqüentemente, o cache-loader pensará que os arquivos foram atualizados, mas na verdade não, porque este não é um momento de modificação, mas um momento de checkout. E se você fizer assim, os hashes do conteúdo serão comparados. O conteúdo não mudou, o resultado antigo será usado.
Deve ser notado aqui que se estivéssemos usando o babel, o babel-loader tem um mecanismo de cache interno por padrão, e já é feito em hashes do conteúdo, não no mtime. Portanto, talvez pensemos um pouco mais e olhemos para a babel.
Agora sobre a montagem de pedaços.

Vamos falar um pouco sobre o que o webpack faz por padrão. Se tivermos um arquivo de índice de entrada, os componentes serão conectados a ele. Eles também possuem componentes, etc. Além disso, módulos comuns são conectados: React, React-dom e lodash, por exemplo.
Então, por padrão, webpack, como todos provavelmente sabem, mas apenas no caso, repito, reúne todas as dependências em um grande pacote.
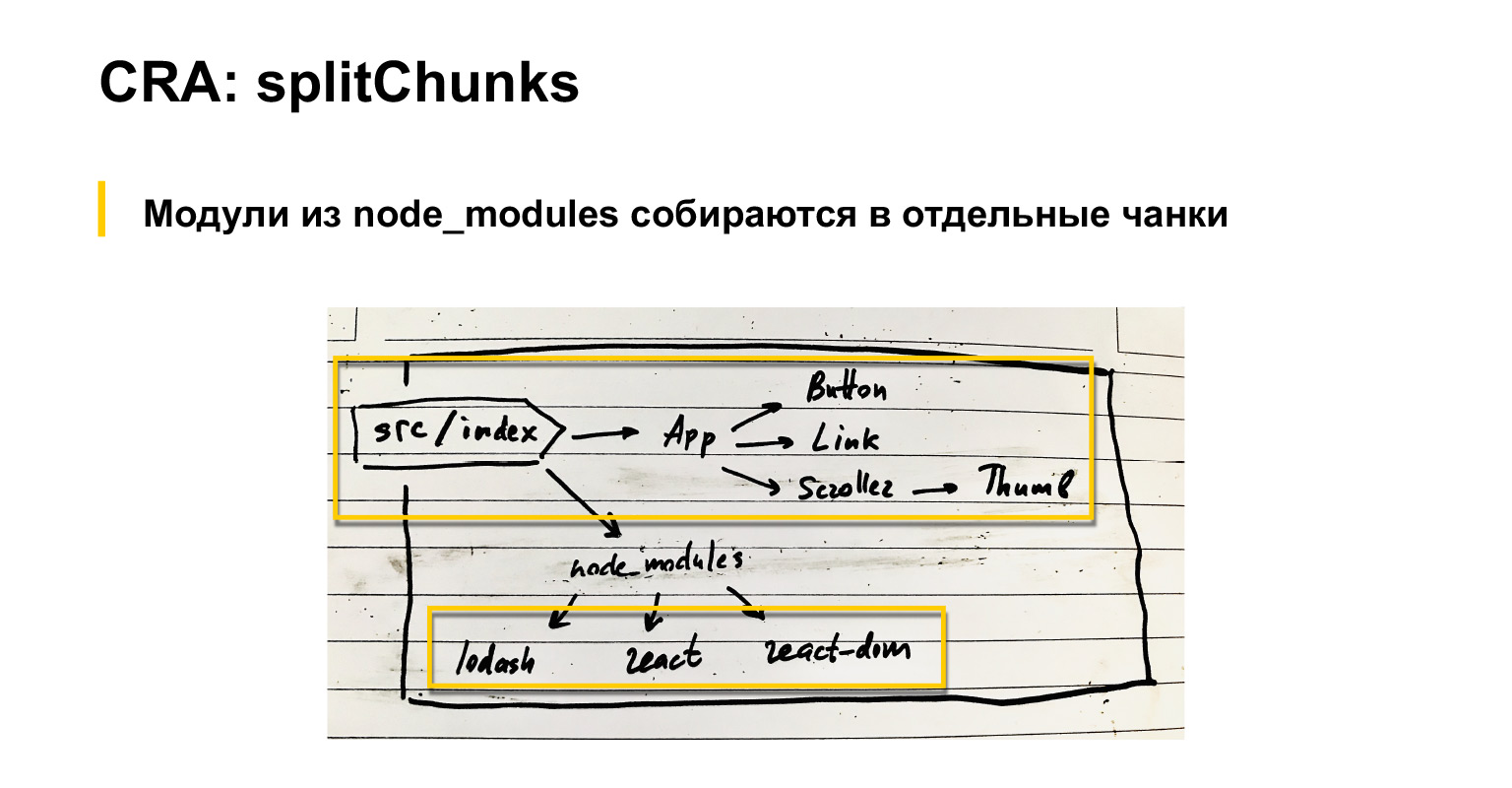
Ao mesmo tempo, tudo o que está conectado por meio de node_modules pode ser montado como externo, carregado com scripts separados ou em um bloco separado, configurando uma configuração de otimização.splitChunks especial no webpack. Na minha opinião, mesmo por padrão, esses módulos do fornecedor são coletados em um bloco separado. CRA tem uma versão ligeiramente ajustada deste splitChunks.

Vamos lembrar o que são runtimeChunks. Eu mencionei ele. Este é o tipo de código que contém esse “cabeçalho” de carregamento de scripts e funções que garantem o funcionamento do sistema modular no cliente. E então um array (ou cache), que, de fato, contém os módulos.

Por que eu contei sobre isso? Porque Create React App ainda usa uma configuração que coleta este runtimeChunks em um arquivo separado. Este arquivo não ficará preso no pacote íntegro original, mas em um arquivo separado. Ele pode ser armazenado em cache no navegador e tudo isso.
Então, o que não funciona para nós no aplicativo Create React?

Este splitChunks, que é usado lá por padrão, coleta apenas node_modules em blocos separados. Mas, na verdade, existem componentes comuns, bibliotecas comuns, que estão no nível do projeto. Eu também gostaria de agrupá-los em pedaços separados, porque eles, talvez, também raramente mudem. Por que nos limitamos apenas ao que está em node_modules?
Além disso, em relação ao runtimeChunks, também podemos dizer que seria ótimo, como discutimos originalmente, além do próprio runtime, também coletar módulos ali, no mesmo trecho, que são sempre necessários. Mesmos botões / links. Sempre há links no Serp. Sempre gostaria de coletar links. Ou seja, não apenas o tempo de execução do webpack, mas também alguns componentes super populares.
Isso não está presente no aplicativo Create React. Como fizemos isso conosco?

Ajustamos splitChunks de forma que desabilitamos todo o comportamento padrão e pedimos para coletar em código comum não apenas o que está em node_modules, mas também quais são os componentes comuns de nosso projeto e o código da biblioteca de nosso projeto, o que está em src / lib , src / componentes contém.
Além disso, coletamos em blocos separados o que está conectado por meio de importações dinâmicas e o que geralmente é chamado de blocos assíncronos.
Aqui você precisa prestar atenção a duas opções. Um é forçado e o outro é inicial. Em geral, impor é uma configuração conveniente o suficiente para desabilitar qualquer heurística complexa em splitChunks.
Por padrão, splitChunks tenta entender quantos módulos estão em demanda e levar essas estatísticas em consideração na divisão. Mas é difícil acompanhar isso, e a demanda pelo módulo pode mudar de tempos em tempos, e o módulo vai "pular" entre os blocos. Do bloco geral ao pacote de recursos e vice-versa. Ou seja, esse é um comportamento muito imprevisível, por isso o desativamos.
Ou seja, sempre dizemos tudo o que satisfaz as condições do campo de teste, entramos nos blocos comuns. Não queremos heurísticas.
Mas chunks: initial também é uma coisa boa, é sobre o fato de que esses módulos síncronos, módulos que são conectados por meio de importações dinâmicas, podem ser conectados em lugares diferentes de maneiras diferentes. Ou seja, você pode conectar o mesmo módulo por importação dinâmica ou por importação regular.
E o valor inicial permite que o mesmo módulo seja construído de duas maneiras. Ou seja, ele é coletado, tanto de forma assíncrona quanto síncrona, permitindo assim que seja usado nos dois sentidos. Bastante conveniente. Isso aumenta um pouco o tamanho da estática coletada, mas permite que você use quaisquer importações.
Pela documentação, aliás, isso é bastante difícil de entender. Recentemente, reli a documentação do webpack e nada de normal foi escrito sobre o initial.

Isso é o que fizemos com splitChunks. Agora o que fizemos com runtimeChunks. Em vez de coletar apenas o tempo de execução em runtimeChunks, queremos adicionar mais componentes populares lá.
Escrevemos nosso próprio plugin chamado MainChunkPlugin. E tem uma configuração muito trivial. Há apenas uma lista de módulos que precisam ser coletados lá, que consideramos populares.
Apenas usando nossas ferramentas de teste A / B, várias ferramentas offline, percebemos quais componentes estão mais frequentemente nos resultados da pesquisa. É aí que eles foram escritos em uma lista tão plana. E no final, nosso plugin coleta esses componentes da lista, bem como bibliotecas, bem como um tempo de execução do webpack que coleta esse optimization.splitChunks padrão.

A propósito, aqui está um trecho de código que une o tempo de execução. Também não é tão trivial mostrar que não é tão fácil escrever plugins, mas então vamos ver o que deu.

Também deve ser observado que, de modo geral, o webpack possui um mecanismo padrão para fazer isso, chamado DLLPlugin. Também permite coletar um bloco separado de acordo com a lista de dependências. Mas tem várias desvantagens. Por exemplo, não inclui runtimeChunks. Ou seja, runtimeChunks você sempre terá um chunk separado, e haverá um chunk montado pelo DLLPlugin. Isso não é muito conveniente.
Além disso, o DLLPlugin requer um assembly separado. Ou seja, se quiséssemos construir esse fragmento separado com os componentes mais percussivos usando o DLLPlugin, teríamos que executar dois assemblies.
Ou seja, se montasse esse fragmento separado com o arquivo de manifesto, o resto da montagem coletaria todo o resto, simplesmente subtraindo por meio do arquivo de manifesto, não coletaria o que já entrou no fragmento com componentes populares. E isso retarda a construção, porque a implementação do DLLPlugin levou sete segundos localmente. Isso é muito. E não pode ser otimizado porque tem execução sequencial estrita.
Além disso, em um determinado momento precisávamos construir esse nosso pedaço principal com componentes populares sem CSS, apenas JS. O DLLPlugin não faz isso. Ele sempre coleta o que está disponível por meio de demandas por importações. Ou seja, se você incluir CSS, sempre acerta também. Era desconfortável para nós. Mas se isso não for um problema para você e você não quiser escrever um código tão complicado, então o DLLPlugin é uma solução normal. Ele resolve o problema principal. Ou seja, ele entrega os componentes mais populares em um arquivo separado. Isso pode ser usado.
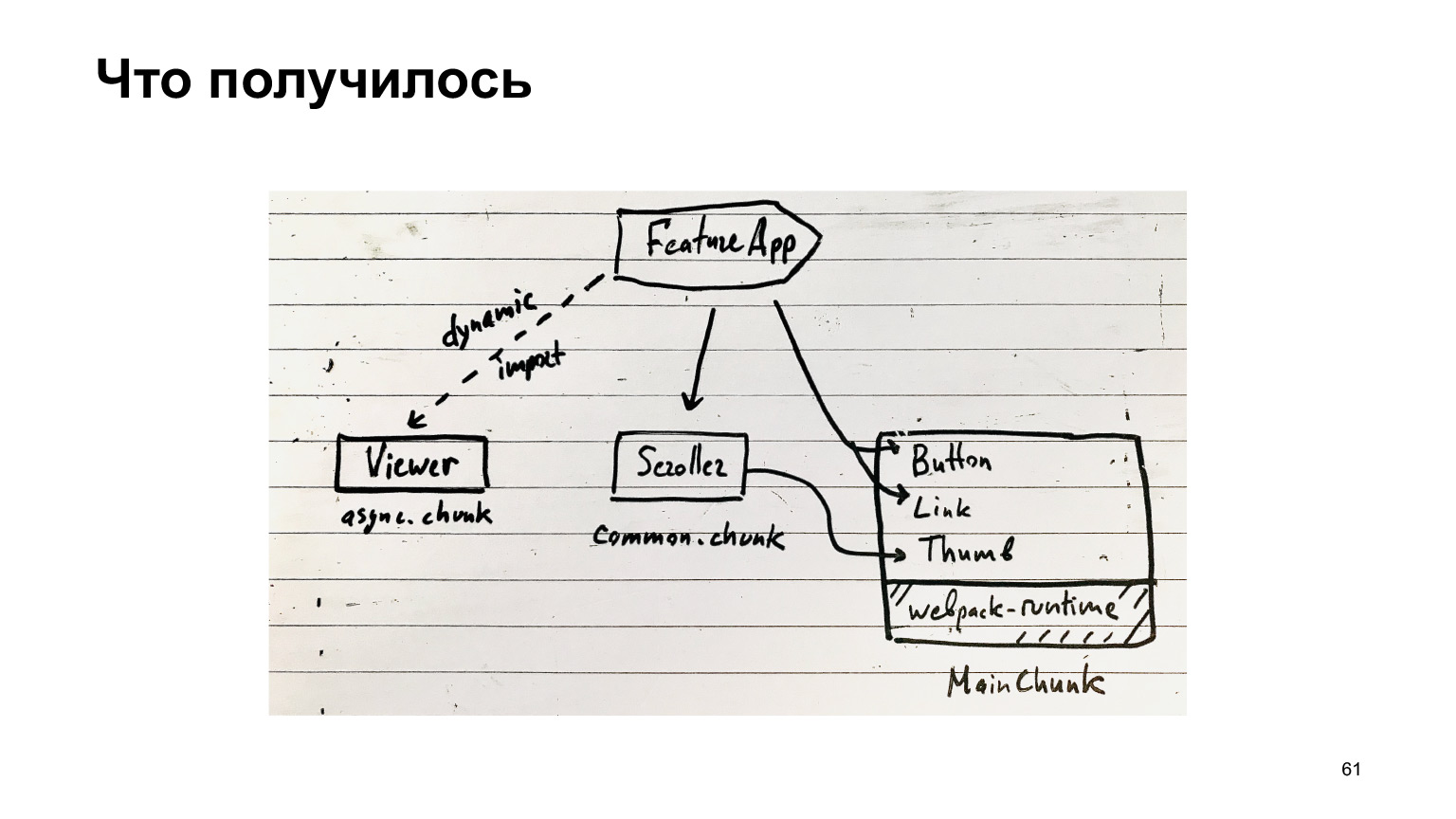
Então, o que conseguimos? Nosso recurso pode usar componentes super populares de nosso MainChunk, que são montados por um plugin especial de mesmo nome. Além disso, há chunks comuns, que incluem todos os tipos de componentes comuns, e há chunks assíncronos, que são carregados por meio de importações dinâmicas.
O resto do código está nos pacotes de recursos. Em princípio, essa é a sua estrutura de blocos.
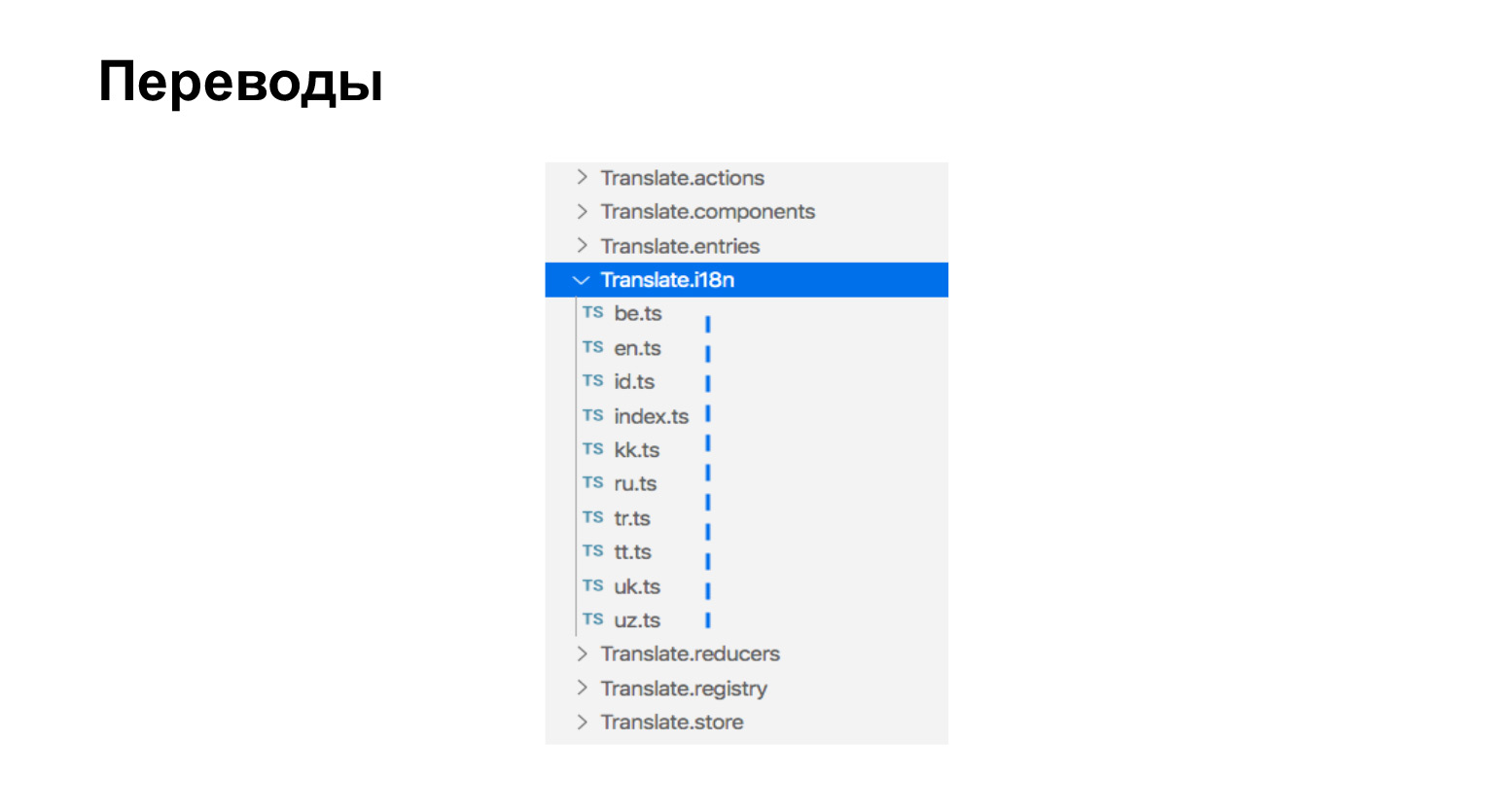
Sobre a montagem de traduções. Nossas traduções são apenas arquivos ts que estão ao lado dos componentes que precisam de traduções. Aqui temos nove idiomas, aqui estão nove arquivos.

As traduções são assim. É simplesmente um objeto que contém uma frase-chave e o significado da frase traduzida.

É assim que as traduções são conectadas ao componente e, em seguida, um auxiliar especial é usado.

Como essas traduções poderiam ser coletadas? Pensamos: precisamos coletar traduções, olhar na Internet, o que eles escrevem, como podemos fazer.
Dizem na Internet: use multicompilação. Ou seja, em vez de executar uma construção do webpack, apenas execute a construção do webpack para cada linguagem. Mas, dizem eles, tudo ficará bem, porque há um cache-loader, é todo esse trabalho geral com TypeScript, ou o que quer que você tenha, será armazenado em cache e, portanto, não demorará muito.
Não desanime, não pense que serão nove execuções reais do webpack. Não vai ser assim, vai ser bom.
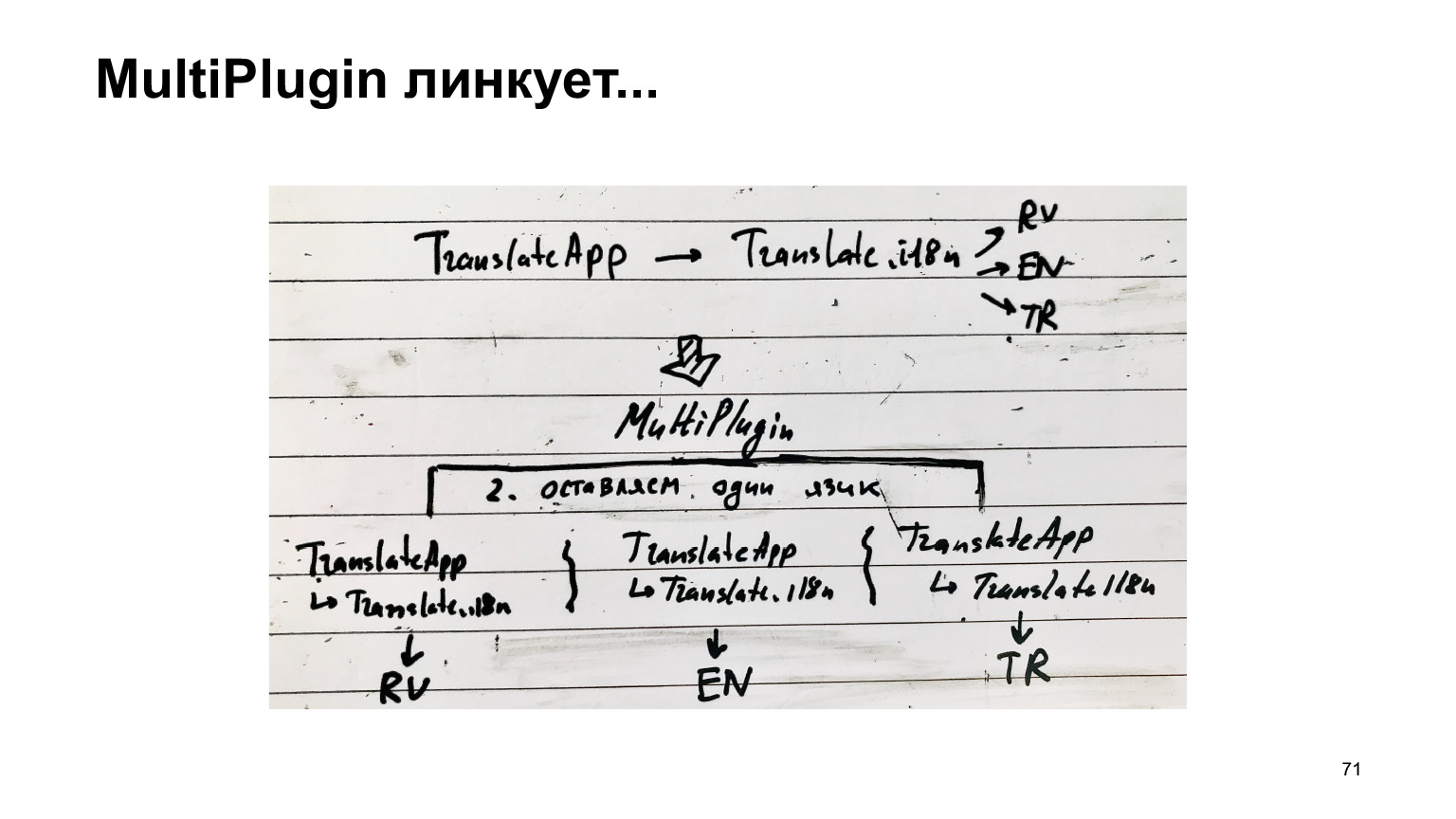
A única coisa que precisa ser corrigida é adicionar o módulo ReplacementPlugin, que, em vez de um arquivo de índice que conecta todos os idiomas, o substituirá por um idioma específico. Tudo é bastante trivial e, sim, a saída precisa ser corrigida. Agora descobrimos que precisamos coletar um pacote separado para cada idioma.

O diagrama para esta receita é o seguinte. Houve um tradutor. Ele conectou traduções do tradutor. Ele conectou linguagens e nós, em vez de coletar essa estrutura única, a replicamos para cada linguagem, obtemos uma linguagem separada e coletamos cada uma como uma compilação separada.
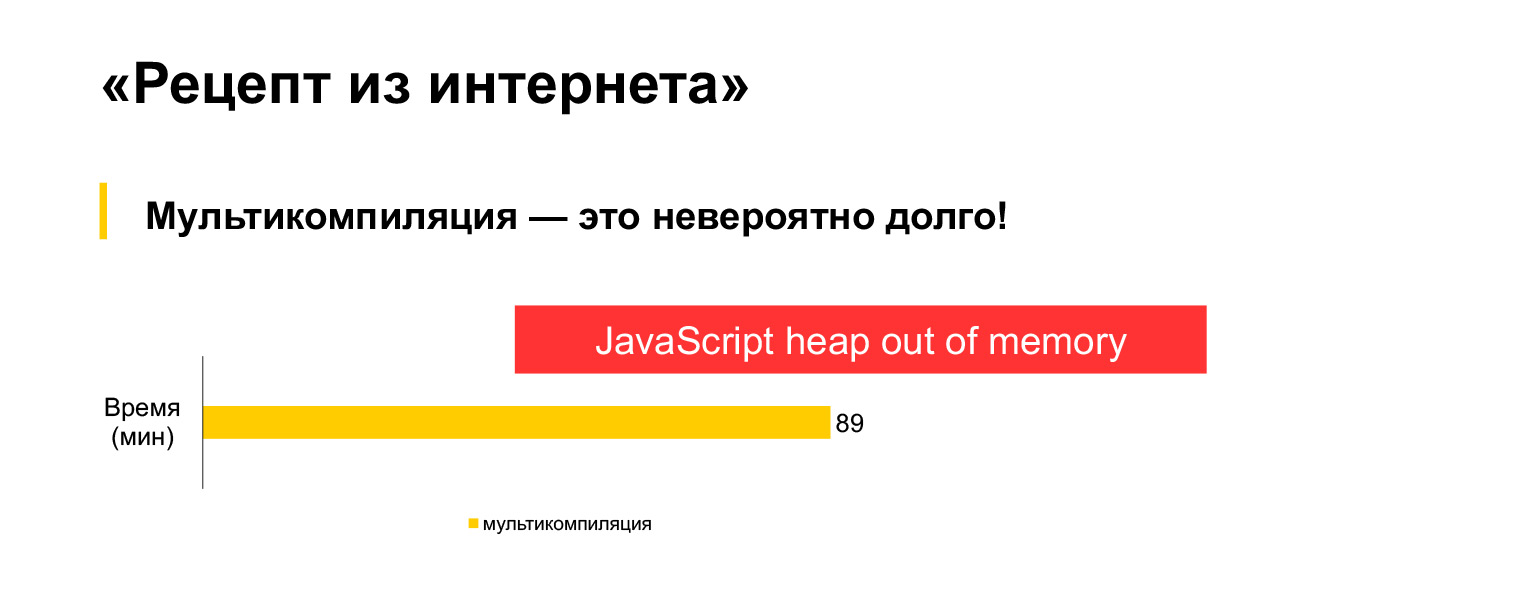
Infelizmente, isso não funciona. Tentei executar esta opção de multicompilação para nosso código atual de 30 MB, esperei uma hora e meia e recebi este erro.

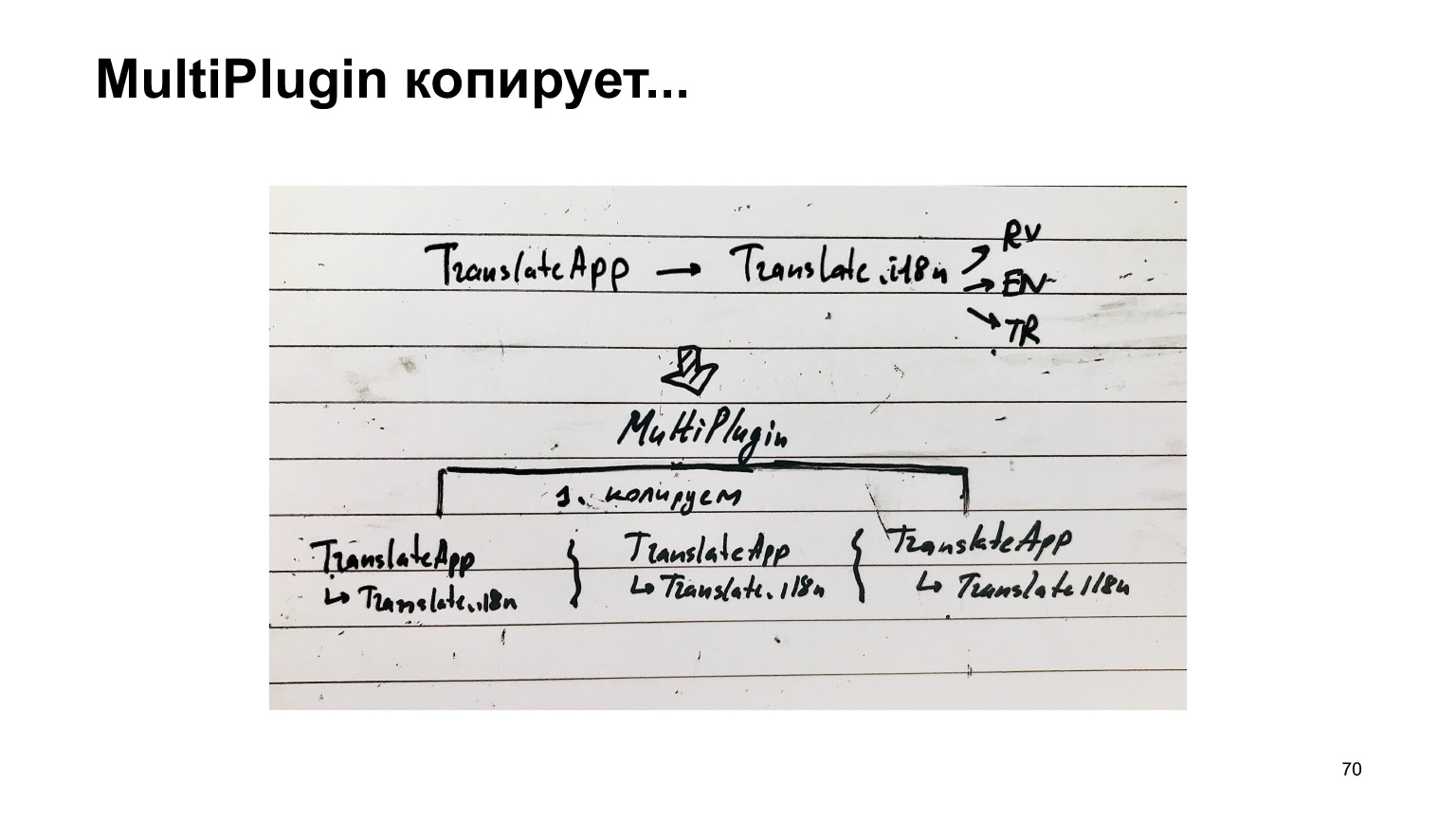
É muito longo e impossível. O que fizemos com isso? Fizemos outro plugin. Pegamos a mesma estrutura e nos colocamos no trabalho do webpack quando ele está prestes a salvar os arquivos de saída no disco. Copiamos essa estrutura tantas vezes quanto temos idiomas e colamos um idioma a cada um. E só então criamos os arquivos.

Ao mesmo tempo, o trabalho principal que o webpack faz para contornar as dependências de compilação não se repete. Ou seja, avançamos no último estágio e, portanto, podemos esperar que seja rápido.

Mas o código do plugin acabou sendo complicado. Este é literalmente um oitavo do nosso plugin. Estou apenas mostrando como é difícil. E lá encontramos regularmente insetos pequenos e desagradáveis. Mas não foi mais fácil implementá-lo. Mas funciona muito bem.
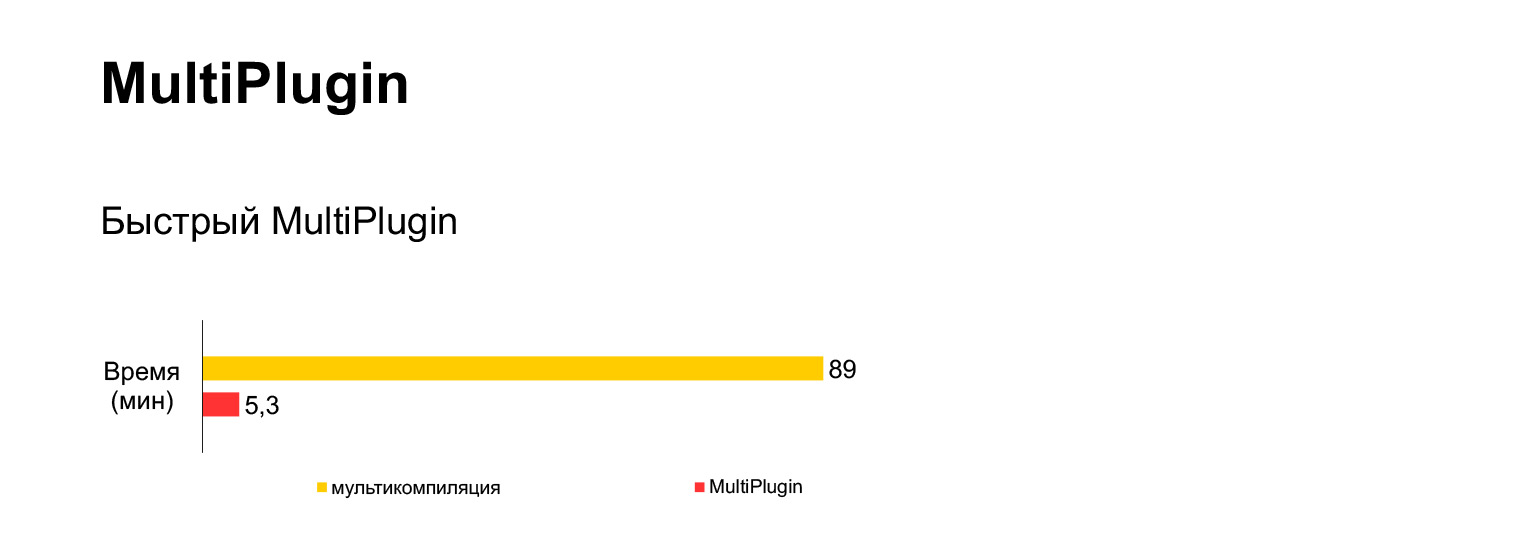
Ou seja, em vez de uma hora e meia com erro, temos cinco minutos de montagem com este nosso plugin.
Agora entrega e inicialização.

A entrega e a inicialização são simples. O que carregamos em recursos separados, usamos pré-carregamento, assim como todo mundo, eu acho. Em seguida, incluímos CSS, JS, na verdade HTML para nossos componentes e carregamos esses nossos recursos, mas sem assíncronos.
Nós experimentamos. Se usarmos async, o tempo de início da interatividade é atrasado, o que não gostaríamos. Portanto, basta usar o pré-carregamento e carregar no final da página. Em geral, nada de especial.

Ao mesmo tempo, alinhamos todo o resto. Ou seja, este é nosso MainChunk, embutimos seu CSS. Componentes gerais, estilos em geral, tudo o que está escrito no slide, iremos embutir. Esta também foi uma série de experimentos que mostraram que "inline" dá o melhor resultado para a primeira renderização e o início da interatividade.
E agora os números. Para falar sobre números, você precisa dizer duas palavras sobre métricas.

Temos uma equipe de velocidade dedicada que visa fazer com que todo o código de front-end funcione de forma eficiente. Isso diz respeito à modelagem do lado do servidor, carregamento de recursos e inicialização no cliente, em geral, tudo isso.
Temos um monte de métricas que são enviadas da produção para nosso sistema de registro especial. Podemos controlar isso em experimentos A / B. Temos ferramentas off-line, em geral, estamos acompanhando de forma bastante ativa tudo isso.
E usamos essas ferramentas quando implementamos nosso novo código no React e no TypeScript.

Agora vamos rastrear com a ajuda de ferramentas offline (porque não consegui montar uma experiência online honesta que usasse todas as nossas métricas). Vamos ver o que acontece se revertermos de nossa solução atual para Create React App nessas métricas principais.
A ferramenta funciona de forma muito simples. Uma parte das solicitações é obtida, neste caso, uma solicitação com recursos no React é obtida, porque nem todo o Serp foi reescrito no React ainda. Em seguida, nossos modelos são acionados, as medições são coletadas e inseridas em um utilitário especial que compara e encontra esses resultados e métricas. Nesse caso, apenas os resultados estatisticamente significativos permanecem. Em geral, tudo é razoável lá.
Vamos ver o que acontece.

A desativação do MultiPlugin, que, na verdade, coleta todas as traduções em vez de apenas a tradução necessária, não mostrou alterações estatisticamente significativas.
No começo fiquei um pouco chateado, depois percebi que, na verdade, isso não é problema, pois agora não temos muitos recursos que tenham muitas traduções traduzidas para o React. Portanto, quando houver mais desses recursos, essas mudanças significativas definitivamente aparecerão. Acontece que agora há recursos que são mostrados principalmente na Rússia e eles não têm traduções. E a quantidade de código contido nos componentes excede em muito a quantidade de traduções. Portanto, o fato de que todas as traduções estão a caminho é imperceptível.
Talvez fosse perceptível em experimentos mais honestos, se um experimento honesto fosse realizado. Mas a ferramenta offline não mostrou essas mudanças.

Se desativarmos o MainChunkPlugin, o tempo para o início da interatividade diminuirá e o carregamento de HTML também ficará muito lento. Portanto, a coisa é bastante necessária.
Por que o carregamento de HTML está ficando lento, porque todo o código que costumava ser carregado neste bloco separado por um recurso separado agora está embutido em HTML. É como se estivéssemos alinhando tudo, mas a interatividade também fica mais lenta. Em princípio, bastante esperado.
E agora a pergunta: o que aconteceria se você colocasse tudo em um pacote, não use nenhum pedaço com componentes comuns? Acontece que esta não é uma imagem feliz.

A primeira renderização diminui drasticamente. A interatividade também quase dobrou. Isso torna o HTML menor, pois todo o código começa a ser entregue em um recurso separado. Mas a interatividade, como você pode ver, não ajuda.
E montagem. Últimos slides.
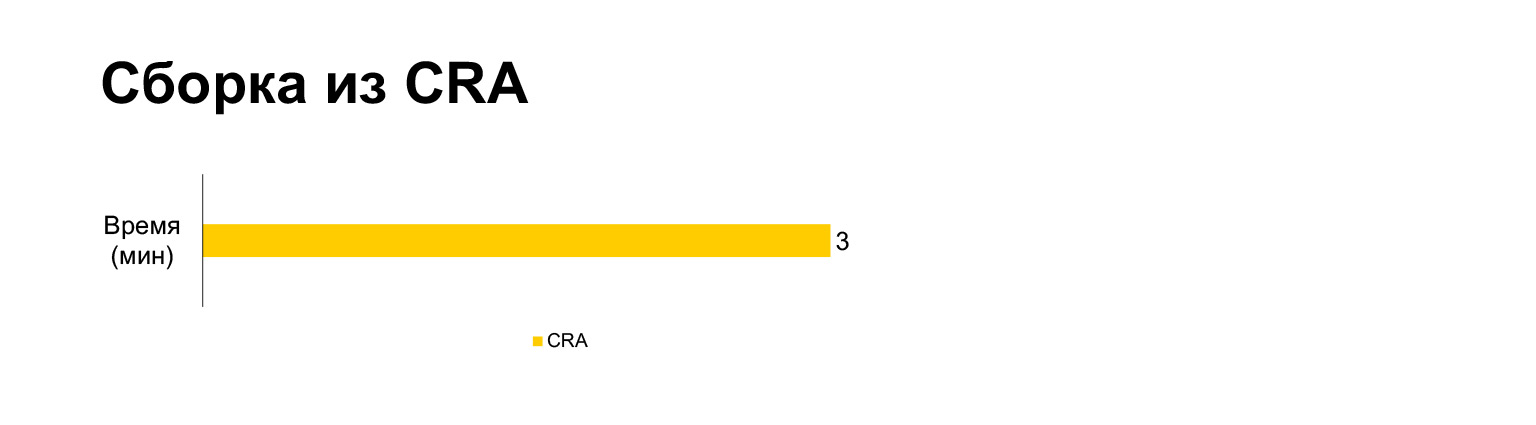
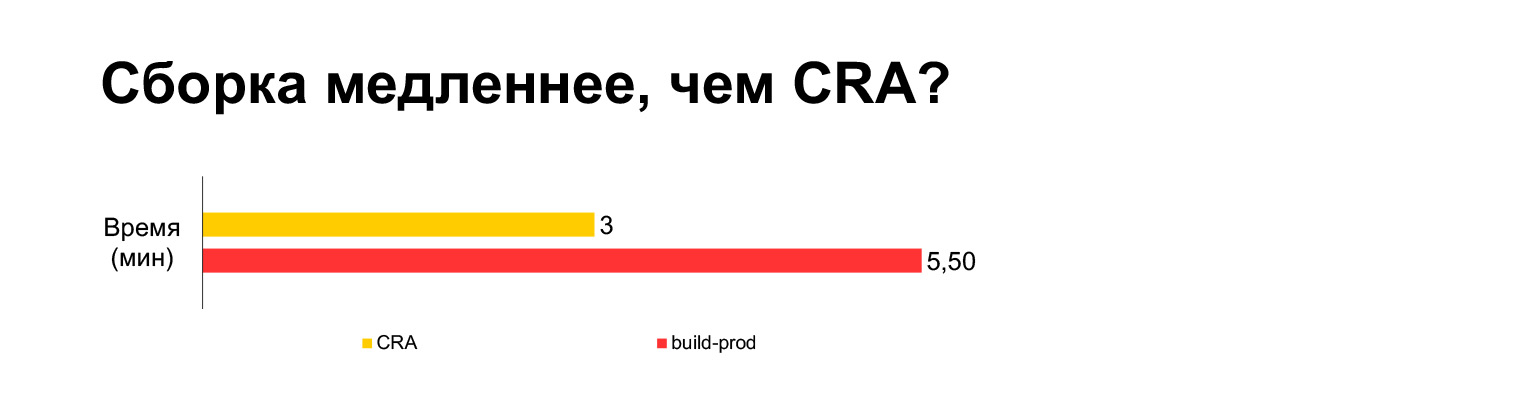
O tempo de compilação Create React App para o projeto atual leva três minutos em um laptop. E com todos os nossos sinos e assobios - cinco minutos. Longo?
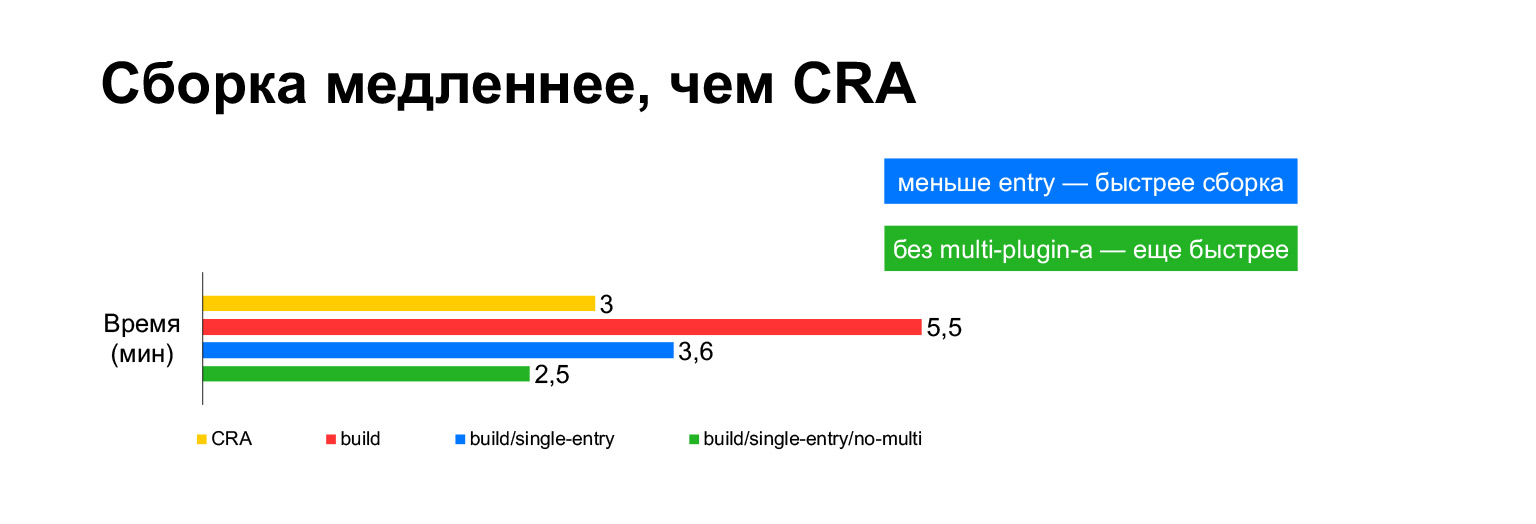
No entanto, na verdade, se você juntar em um pacote, leva três minutos. Construir sem MultiPlugin torna-o ainda mais rápido do que Criar aplicativo React. Mas, como mostrei nos slides anteriores, não podemos recusar essas modificações nos scripts de construção originais, porque sem elas, as métricas de velocidade ficarão muito ruins.
Agora vamos revisar o que é útil aprender com este relatório.

Babel não é a única maneira de trabalhar com TypeScript. TSC, ts-node e ts-loader podem ser usados. Funciona muito bem.
Dito isto, as verificações de TypeScript, verificação de tipo, não precisam ser executadas toda vez que você constrói. Isso desacelera muito - como você se lembra, duas vezes. Portanto, é melhor colocar essas coisas em verificações separadas, ganchos de pré-consolidação, por exemplo.
É melhor coletar os componentes usados com frequência em um bloco separado. Também é desejável coletar componentes comuns em blocos separados, porque isso permite carregar apenas o que é necessário, apenas diff.
O mais importante é que, se você não tiver todo o código usado em todas as páginas, precisará dividi-lo em entradas separadas, coletar pacotes separados e carregar conforme o usuário vê os tipos correspondentes de resultados de pesquisa. Baixe apenas os arquivos que você precisa. Isso, como você viu, dá o melhor resultado. Coisa bastante óbvia, mas não tenho certeza se todos fazem isso, porque eles ainda permanecem no aplicativo Create React.
A multicompilação é muito longa. Não acredite se alguém disser que a multicompilação está bem e caches em algum lugar dentro podem lidar com tudo isso. Usar pré-carga e embutido também dá resultados.
Alguns links sobre a foice:
- clck.ru/PdRdh e clck.ru/PdRjb - dois relatórios que tratam da reescrita de Serp in React, esta é a primeira etapa, sobre como chegamos a isso e por que começamos a fazê-lo. O segundo relato é sobre como planejamos e fizemos tudo isso do ponto de vista gerencial, quais foram as etapas.
- clck.ru/PdRnr - relatório sobre nossas métricas de velocidade. É para aqueles que de repente se perguntaram o que mais existe, como funcionam as ferramentas online.
Obrigado a todos.