
Resolver problemas de ciência de dados em Python não é fácil
Por quê? As ferramentas existentes são pouco adequadas para resolver problemas relacionados a séries temporais e essas ferramentas são difíceis de integrar entre si. Os métodos do Scikit-learn pressupõem que os dados são estruturados em um formato tabular e que cada coluna consiste em variáveis aleatórias independentes e igualmente distribuídas - suposições que nada têm a ver com dados de séries temporais. Os pacotes que têm módulos para aprendizado de máquina e funcionam com séries temporais, como modelos de estatísticas , não são muito bons amigos. Além disso, muitas operações importantes com séries temporais, como a divisão de dados em conjuntos de treinamento e teste em intervalos de tempo, não estão disponíveis em pacotes existentes. Sktime
foi criado para resolver problemas semelhantes .

Logotipo da biblioteca Sktime no GitHub
Sktime é um kit de ferramentas de aprendizado de máquina de código aberto em Python projetado especificamente para trabalhar com séries temporais. Este projeto é desenvolvido e financiado pela comunidade pelo British Council for Economic and Social Research , Consumer Data Research e o Alan Turing Institute .
Sktime estende a API scikit-learn para resolver problemas de série temporal. Ele contém todos os algoritmos e ferramentas de transformação necessários para resolver de forma eficiente problemas de regressão, previsão e classificação de séries temporais. A biblioteca inclui algoritmos de aprendizado de máquina especiais e métodos de transformação para séries temporais não encontrados em outras bibliotecas populares.
Sktime foi projetado para funcionar com scikit-learn, adaptar algoritmos facilmente para problemas de série temporal inter-relacionados e construir modelos complexos. Como funciona? Muitos problemas de séries temporais estão relacionados entre si de uma forma ou de outra. Um algoritmo que pode ser aplicado para resolver um problema pode frequentemente ser aplicado para resolver outro relacionado a ele. Essa ideia é chamada de redução. Por exemplo, um modelo para regressão de série temporal (que usa uma série para prever um valor de saída) pode ser reutilizado para um problema de previsão de série temporal (que prevê um valor de saída - um valor que será recebido no futuro).
A ideia principal do projeto:“Sktime oferece aprendizado de máquina integrável e fácil de entender usando séries temporais. Possui algoritmos que são compatíveis com scikit-learn e ferramentas de compartilhamento de modelo, apoiados por uma taxonomia clara de tarefas de aprendizagem, documentação clara e uma comunidade amigável. "
Neste artigo, destacarei alguns dos recursos exclusivos do sktime .
Modelo de dados correto para séries temporais
Sktime usa uma estrutura de dados aninhada para séries temporais na forma de dataframes pandas .
Cada linha em um dataframe típico contém variáveis aleatórias independentes e igualmente distribuídas - casos, e as colunas - variáveis diferentes. Para métodos sktime, cada célula em um dataframe Pandas agora pode conter uma série temporal inteira. Este formato é flexível para dados multidimensionais, em painel e heterogêneos, e permite a reutilização de métodos tanto no Pandas quanto no scikit-learn .
Na tabela abaixo, cada linha é uma observação contendo uma matriz de séries temporais na coluna X e um valor de classe na coluna Y. Os avaliadores e transformadores sktime são adeptos de trabalhar com tais séries temporais.
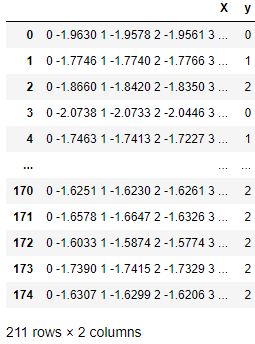
Uma estrutura de dados de série temporal nativa compatível com sktime.
Na tabela a seguir, cada elemento da série X foi movido para uma coluna separada, conforme exigido pelos métodos do scikit-learn. A dimensão é bastante alta - 251 colunas! Além disso, a ordem de tempo das colunas é ignorada por algoritmos de aprendizagem que funcionam com valores tabulares (mas usados por algoritmos de classificação e regressão de série temporal).
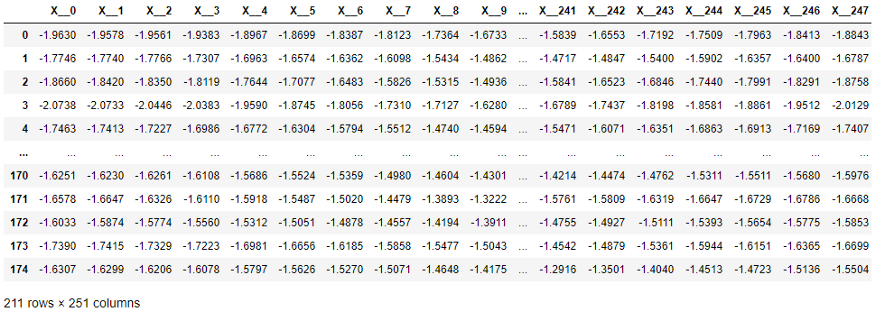
Estrutura de dados de série temporal exigida pelo scikit-learn.
Para tarefas de modelagem de várias séries conjuntas, uma estrutura de dados de série temporal nativa que seja compatível com sktime é ideal. Modelos treinados nos dados tabulares esperados pelo scikit-learn ficarão presos em muitos recursos.
O que o sktime pode fazer?
De acordo com a página do GitHub , sktime atualmente oferece os seguintes recursos:
- Algoritmos modernos para classificação de séries temporais, análise de regressão e previsão (transferidos do kit
tsmlde ferramentas para Java); - Transformadores de séries temporais: transformações de séries únicas (por exemplo, retendência ou dessazonalização), transformações de séries como recursos (por exemplo, extração de recursos) e ferramentas para compartilhar vários transformadores.
- Pipelines para transformadores e modelos;
- Configurando o modelo;
- Conjunto de modelos, por exemplo, floresta aleatória totalmente customizável para classificação e regressão de séries temporais, conjunto para problemas multidimensionais.
API sktime
Como mencionado anteriormente, sktime suporta API básica scikit-learn métodos para aulas
fit, predicte transform.
Para classes (ou modelos) avaliadores, o sktime fornece um método
fitpara treinar o modelo e um método predictpara gerar novas previsões.
Os avaliadores em sktime expandem covariáveis e classificadores scikit-learn, fornecendo análogos desses métodos, que são capazes de trabalhar com séries temporais.
Para classes o transformador sktime fornece métodos
fite transformpara converter os dados da série. Existem vários tipos de transformações disponíveis:
- , , ;
- , (, );
- (, );
- , , , (, ).
O próximo exemplo é uma adaptação do guia de previsão do GitHub . A série neste exemplo (o conjunto de dados da companhia aérea Box-Jenkins) mostra o número de passageiros de aeronaves internacionais por mês de 1949 a 1960.
Primeiro, carregue os dados e divida-os em suítes de treinamento e teste e faça um gráfico. No sktime temos dois recursos convenientes para fácil execução dessas tarefas -
temporal_train_test_splitforque são separados por um conjunto de dados e tempo plot_ys, plotados com base no teste e na amostra de treinamento.
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])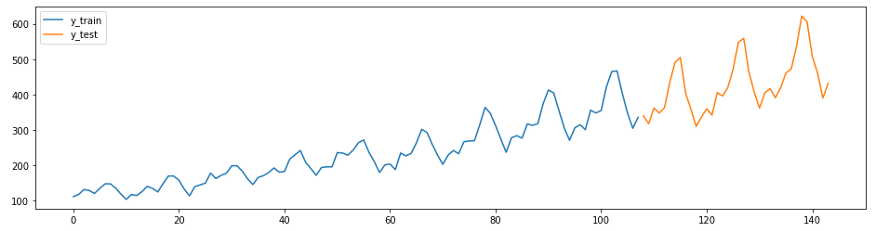
Antes de fazer previsões complexas, é útil comparar sua previsão com os valores obtidos usando algoritmos Bayesianos ingênuos. Um bom modelo deve exceder esses valores. No sktime temos um método
NaiveForecastercom diferentes estratégias para criar projeções de linha de base.
O código e o diagrama abaixo mostram duas previsões ingênuas. O Forecaster c
strategy = “last”sempre prevê o último valor da série.
O Forecaster s
strategy = “seasonal_last”prevê o último valor da série para uma determinada temporada. A sazonalidade no exemplo é definida como “sp=12”, ou seja, 12 meses.
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957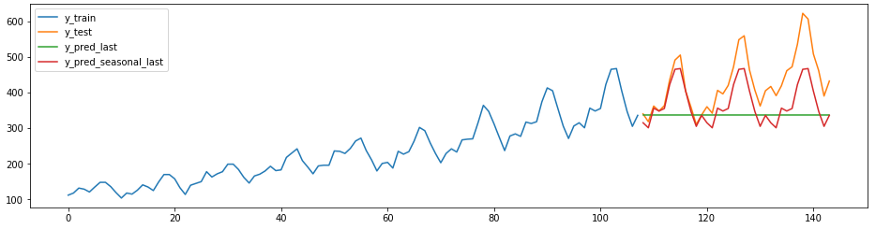
O seguinte snippet de previsão mostra como os regressores sklearn existentes podem ser facilmente, corretamente e com esforço mínimo adaptados para tarefas de previsão. Abaixo está um método
ReducedRegressionForecasterdo sktime que prevê uma série usando um modelo sklearnRandomForestRegressor. Sob o capô, o sktime divide os dados de treinamento em janelas de 12 para que o regressor possa continuar o treinamento.
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)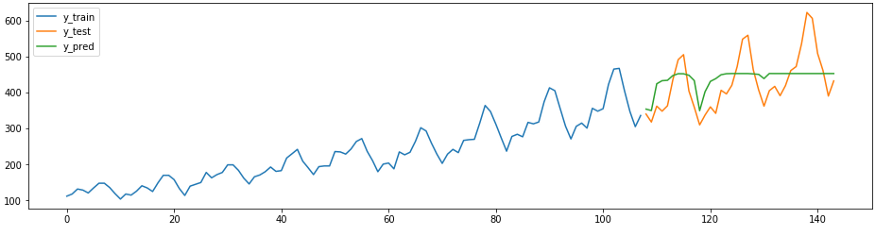
No sktime também têm seus próprios métodos de previsão, por exemplo
AutoArima.
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469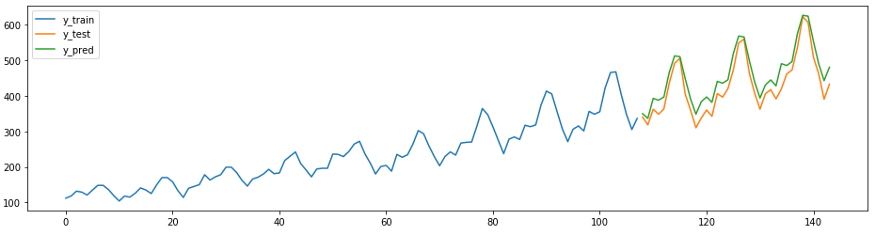
Para um mergulho mais profundo na funcionalidade de previsão do sktime , confira o tutorial aqui .
Classificação de série temporal
Também
sktimepode ser usado para classificar séries temporais em grupos diferentes.
No exemplo de código abaixo, a classificação de uma única série temporal é tão fácil quanto a classificação no scikit-learn. A única diferença é a estrutura de dados de série temporal aninhada da qual falamos acima.
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868Um exemplo foi retirado de pypi.org/project/sktime
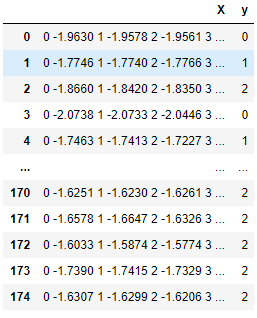
Dados passados para TimeSeriesForestClassifier
Para aprender mais sobre a classificação de séries, consulte os tutoriais de classificações univariadas e multivariadas de sktime .
Recursos adicionais de sktime
Para saber mais sobre Sktime, consulte os links a seguir para documentação e exemplos.
- Descrição detalhada da API: sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .