Você pode fazer isso manualmente, mas também existem estruturas e bibliotecas para isso que tornam esse processo mais rápido e fácil. Hoje vamos falar
sobre um deles, o featuretools , bem como a experiência prática de usá-lo.

O pipeline mais moderno
Olá! Eu sou Alexander Loskutov, trabalho na Leroy Merlin como analista de dados ou, como está na moda chamá-lo agora, um cientista de dados. Minhas responsabilidades incluem trabalhar com dados, começando com consultas analíticas e descarregando, terminando com o treinamento do modelo, envolvendo-o, por exemplo, em um serviço, configurando a entrega e implantação do código e monitorando seu trabalho.
Desfazer Previsão é um dos produtos em que estou trabalhando.
Objetivo do produto: prever a probabilidade de um cliente cancelar um pedido online. Com a ajuda dessa previsão, podemos determinar qual dos clientes que fez um pedido deve ser chamado primeiro para pedir a confirmação do pedido, e quem pode nem ser chamado. Em primeiro lugar, o próprio facto de uma chamada e confirmação de uma encomenda de um cliente por telefone reduz a probabilidade de cancelamento e, em segundo lugar, se ligarmos e a pessoa recusar, podemos poupar recursos. Mais tempo será liberado para os funcionários, que eles teriam gasto na coleta do pedido. Além disso, desta forma o produto ficará na prateleira, e se naquele momento o cliente da loja precisar, poderá comprá-lo. E isso vai reduzir o número de mercadorias que foram coletadas em pedidos cancelados posteriormente e não estavam nas prateleiras.
Precursores
Para o piloto do produto, só aceitamos pedidos pós-pagos para retirada em várias lojas.
Uma solução pronta funciona assim: um pedido chega até nós, com a ajuda do Apache NiFi enriquecemos as informações sobre ele - por exemplo, puxando dados sobre mercadorias. Em seguida, tudo isso é transferido por meio do corretor de mensagens Apache Kafka para o serviço escrito em Python. O serviço calcula os recursos para o pedido e, em seguida, um modelo de aprendizado de máquina é usado para eles, o que dá a probabilidade de cancelamento. Depois disso, de acordo com a lógica do negócio, preparamos uma resposta se precisamos ligar para o cliente agora ou não (por exemplo, se o pedido foi feito com a ajuda de um funcionário da loja ou o pedido foi feito à noite, então você não deve ligar).
Ao que parece, o que impede de ligar para todos em uma fila? O fato é que temos um número limitado de recursos para chamadas, por isso é importante entender quem definitivamente deve ligar e quem definitivamente atenderá o pedido sem ligar.
Desenvolvimento de modelo
Eu estava engajado no serviço, no modelo e, conseqüentemente, no cálculo de recursos para o modelo, que será discutido mais adiante.
Ao calcular recursos durante o treinamento, usamos três fontes de dados.
- Placa com informações meta do pedido: número do pedido, carimbo de data / hora, dispositivo do cliente, método de entrega, método de pagamento.
- Placa com posições nas receitas: nº da encomenda, artigo, preço, quantidade, quantidade de mercadoria em stock. Cada posição segue em uma linha separada.
- Tabela - um livro de referência de mercadorias: artigo, vários campos com uma categoria de mercadorias, unidades de medida, descrição.
Usando métodos Python padrão e a biblioteca pandas, você pode facilmente combinar todas as tabelas em uma grande, após o que, usando groupby, você pode calcular todos os tipos de atributos, como agregados por pedido, histórico por produto, por categoria de produto, etc. Mas existem vários problemas aqui.
- Paralelismo de cálculos. O groupby padrão funciona em um thread e em big data (até 10 milhões de linhas), cem recursos são considerados inaceitavelmente longos, enquanto a capacidade dos núcleos restantes fica ociosa.
- A quantidade de código: cada solicitação precisa ser escrita separadamente, verificada a correção e, em seguida, todos os resultados ainda precisam ser coletados. Isso leva tempo, especialmente devido à complexidade de alguns dos cálculos - por exemplo, calcular o histórico mais recente de um item em um recibo e agregar essas características para um pedido.
- Você pode cometer erros se codificar tudo manualmente.
A vantagem da abordagem "escrever tudo à mão" é, naturalmente, total liberdade de ação, você pode dar a sua imaginação para desenvolver.
Surge a pergunta: como pode essa parte do trabalho ser otimizada. Uma solução é usar o featuretools biblioteca .
Já estamos passando à essência deste artigo, ou seja, à própria biblioteca e à prática de seu uso.
Por que apresentar ferramentas?
Vamos considerar várias estruturas para aprendizado de máquina na forma de uma placa (a imagem em si foi honestamente roubada daqui , e provavelmente nem todas estão indicadas lá, mas ainda assim):
Estamos principalmente interessados no bloco de Engenharia de Recursos. Se olharmos para todos esses frameworks e pacotes, descobrimos que featuretools é o mais sofisticado deles, e ainda inclui a funcionalidade de algumas outras bibliotecas como tsfresh .
Além disso, as vantagens das ferramentas de recursos (nem mesmo publicidade!) Incluem:
- computação paralela fora da caixa
- disponibilidade de muitos recursos fora da caixa
- flexibilidade na personalização - coisas bastante complexas podem ser consideradas
- contabilizando relacionamentos entre diferentes tabelas (relacional)
- menos código
- menos probabilidade de cometer um erro
- por si só é grátis, sem cadastro e sem SMS (mas com pypi)
Mas não é tão simples.
- A estrutura requer algum aprendizado, e o domínio total levará uma quantidade razoável de tempo.
- Não tem uma comunidade tão grande, embora as perguntas mais populares continuem indo bem no Google.
- O uso em si também requer cuidados para não inflar o espaço de recursos desnecessariamente e para não aumentar o tempo de cálculo.
Treinamento
Vou dar um exemplo de configuração de ferramentas de recursos.
A seguir, haverá um código com breves explicações, mais detalhadas sobre as ferramentas de recursos, suas classes, métodos, capacidades, você poderá ler, inclusive na documentação no site do framework. Se você estiver interessado em exemplos de aplicação prática com uma demonstração de algumas possibilidades interessantes em tarefas reais, escreva nos comentários, talvez eu escreva um artigo separado.
Então.
Primeiro, você precisa criar um objeto da classe EntitySet, que contém tabelas com dados e sabe sobre seu relacionamento entre si.
Deixe-me lembrá-lo de que temos três tabelas com dados:
- orders_meta (meta informação do pedido)
- orders_items_lists (informações sobre itens em pedidos)
- itens (referência de artigos e suas propriedades)
Escrevemos (além disso, os dados de apenas 3 lojas são usados):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

Hooray! Agora temos um objeto que nos permitirá contar todos os tipos de signos.
Darei um código para calcular recursos bastante simples: para cada pedido, calcularemos várias estatísticas sobre preços e quantidade de bens, bem como alguns recursos por tempo e os produtos e categorias de bens mais frequentes no pedido (funções que realizam várias transformações com dados são chamadas de primitivas em ferramentas de recursos) ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)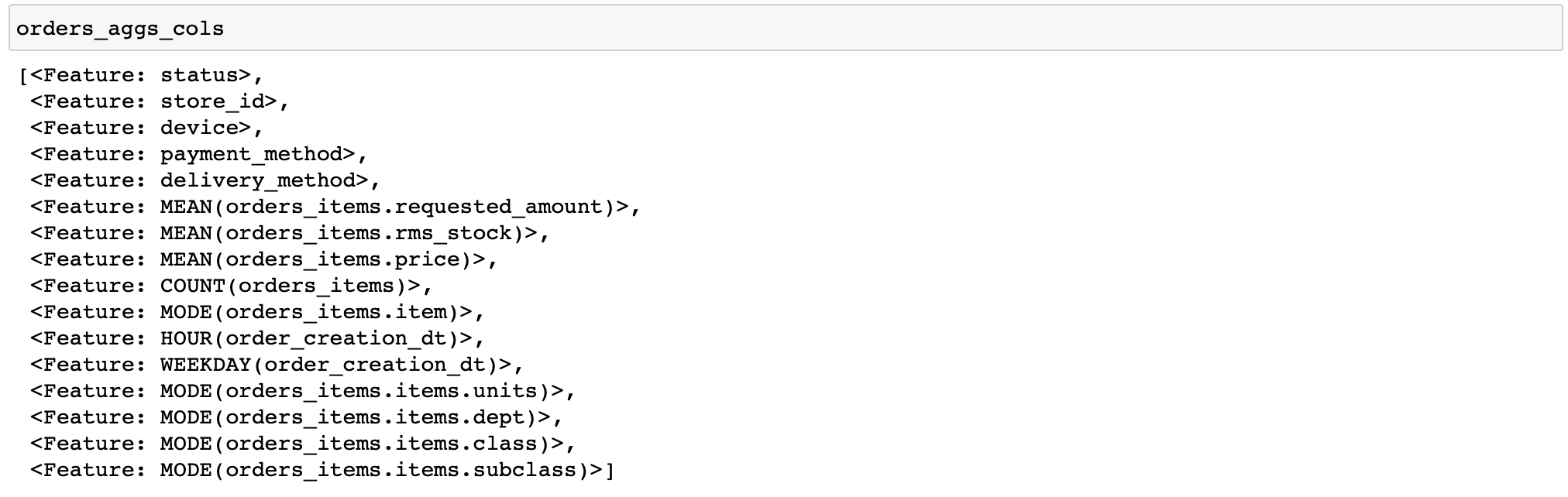

Não há colunas booleanas nas tabelas, portanto, a primitiva any não foi aplicada. Em geral, é conveniente que o próprio featuretools analise o tipo de dados e aplique apenas as funções apropriadas.
Além disso, especifiquei manualmente apenas alguns pedidos para o cálculo. Isso permite que você depure rapidamente seus cálculos (e se você configurou algo errado).
Agora vamos adicionar mais alguns agregados aos nossos recursos, a saber, percentis. Mas as ferramentas de recursos não têm primitivos integrados para calculá-los. Então você precisa escrever você mesmo.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
E adicione-os ao cálculo:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)Então tudo é o mesmo. Até agora, tudo é muito simples e fácil (relativamente, é claro).
E se quisermos salvar nossa calculadora de recursos e usá-la no estágio de execução do modelo, ou seja, no serviço?
Ferramentas de recursos em combate
É aqui que começam as principais dificuldades.
Para calcular as características de um pedido recebido, você terá que fazer todas as operações com a criação do EntitySet novamente. E se para tabelas grandes parece bastante normal jogar objetos pandas.DataFrame no EntitySet, então fazer operações semelhantes para DataFrames de uma linha (há mais deles na tabela com verificações, mas em média 3,3 posições por verificação, ou seja, não o suficiente) - não muito. Afinal, a criação de tais objetos e cálculos com a sua ajuda inevitavelmente contêm uma sobrecarga, ou seja, um número irremovível de operações necessárias, por exemplo, para alocação de memória e inicialização ao criar um objeto de qualquer tamanho ou o próprio processo de paralelização ao calcular vários recursos simultaneamente.
Portanto, no modo de operação "um pedido por vez" em nossos produtos, as ferramentas de recursos não apresentam a melhor eficiência, levando em média 75% do tempo de resposta do serviço (em média 150-200 ms dependendo do hardware). Para comparação: calcular uma previsão usando catboost em recursos prontos leva 3% do tempo de resposta do serviço, ou seja, não mais que 10 ms.
Além disso, há outra armadilha associada ao uso de primitivas customizadas. O fato é que não podemos simplesmente salvar em pickle um objeto da classe que contém as primitivas que criamos, uma vez que as últimas não são conservadas.
Então por que não usar a função embutida save_features (), que pode salvar uma lista de objetos FeatureBase, incluindo os primitivos que criamos?
Irá salvá-los, mas não será possível lê-los mais tarde usando a função load_features () se não os criarmos novamente com antecedência. Ou seja, os primitivos que, em teoria, deveríamos ler do disco, primeiro criamos de novo para nunca mais os usarmos.
Se parece com isso:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorNa função load (), você deve criar primitivos (declarando a variável custom_primitives) que não serão usados. Mas sem isso, o carregamento de recursos adicionais no local onde a função load_features () é chamada falhará com o RuntimeError: Primitive "percentile05" no módulo "featuretools.primitives.base.aggregation_primitive_base" não encontrado .
Acontece que não é muito lógico, mas funciona, e você pode salvar a calculadora já vinculada a um determinado formato de dados (uma vez que os recursos estão vinculados ao EntitySet para o qual foram calculados, embora sem os próprios valores) e a calculadora apenas com uma determinada lista de primitivos.
Talvez no futuro isso seja corrigido e seja possível salvar convenientemente um conjunto arbitrário de objetos FeatureBase.
Por que então o usamos?
Porque do ponto de vista do tempo de desenvolvimento, é barato, enquanto o tempo de resposta sob a carga existente se encaixa em nosso SLA (5 segundos) com uma margem.
No entanto, você deve estar ciente de que, para um serviço que deve responder rapidamente às solicitações recebidas com freqüência, usar ferramentas de recursos sem "agachamentos" adicionais, como chamadas assíncronas, será problemático.
Esta é nossa experiência de usar ferramentas de recursos nos estágios de aprendizagem e inferência.
Este framework é muito bom como uma ferramenta para calcular rapidamente um grande número de recursos para treinamento, ele reduz muito o tempo de desenvolvimento e reduz a probabilidade de erros.
Usar ou não na fase de retirada depende de suas tarefas.