
O aprendizado de máquina está mudando cada vez mais dos modelos projetados à mão para os pipelines otimizados automaticamente, usando ferramentas como H20 , TPOT e auto-sklearn . Essas bibliotecas, juntamente com técnicas como a pesquisa aleatória , visam simplificar a seleção de modelos e ajustar partes do aprendizado de máquina, encontrando o melhor modelo para um conjunto de dados sem nenhuma intervenção manual. No entanto, o desenvolvimento de objetos, sem dúvida o aspecto mais valioso dos pipelines de aprendizado de máquina, permanece quase inteiramente humano.
Recursos de design ( engenharia de recursos), também conhecido como criação de recurso, é o processo de criação de novos recursos a partir de dados existentes para treinar um modelo de aprendizado de máquina. Essa etapa pode ser mais importante do que o modelo real usado, porque o algoritmo de aprendizado de máquina aprende apenas com os dados que fornecemos e a criação de recursos que são relevantes para a tarefa é absolutamente necessária (consulte o excelente artigo “Algumas Coisas Úteis Informações sobre o aprendizado de máquina " ).
Normalmente, o desenvolvimento de recursos é um processo manual demorado, baseado no conhecimento do domínio, intuição e manipulação de dados. Esse processo pode ser extremamente tedioso, e as características finais serão limitadas pela subjetividade humana e pelo tempo. O design automatizado de recursos visa ajudar o cientista de dados a gerar automaticamente muitos objetos candidatos a partir de um conjunto de dados a partir do qual os melhores podem ser selecionados e usados para treinamento.
Neste artigo, veremos um exemplo de como usar o desenvolvimento automático de recursos com a biblioteca de recursos do Python.. Usaremos um conjunto de dados de amostra para mostrar o básico (cuidado com postagens futuras usando dados reais). O código completo deste artigo está disponível no GitHub .
Noções básicas de desenvolvimento de recursos
Desenvolvimento de características significa criar características adicionais a partir dos dados existentes, que geralmente estão espalhados por várias tabelas relacionadas. O desenvolvimento de recursos requer extrair informações relevantes dos dados e colocá-las em uma única tabela que pode ser usada para treinar um modelo de aprendizado de máquina.
O processo de criação de características consome muito tempo, pois geralmente são necessárias várias etapas para criar cada nova característica, principalmente ao usar as informações de várias tabelas. Podemos agrupar operações de criação de recursos em duas categorias: transformações e agregações . Vamos dar uma olhada em alguns exemplos para ver esses conceitos em ação.
Transformaçãoatua em uma única tabela (em termos de Python, uma tabela é apenas Pandas
DataFrame), criando novos recursos a partir de uma ou mais colunas existentes. Por exemplo, se tivermos a tabela de clientes abaixo,
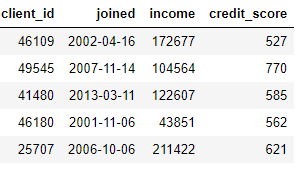
podemos criar recursos localizando o mês em uma coluna
joinedou obtendo o logaritmo natural de uma coluna income. Essas são duas transformações porque elas usam apenas informações de uma tabela.
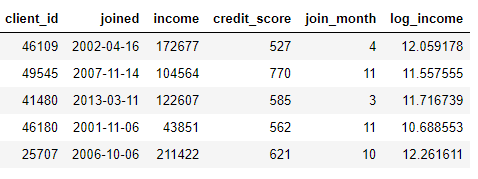
Por outro lado, as agregações são executadas em tabelas e usam um relacionamento um para muitos para agrupar casos e, em seguida, calcular estatísticas. Por exemplo, se tivermos outra tabela com informações sobre empréstimos a clientes, onde cada cliente pode ter vários empréstimos, podemos calcular estatísticas como valores médios, máximos e mínimos de empréstimos para cada cliente.
Esse processo inclui o agrupamento da tabela de empréstimos por cliente, o cálculo da agregação e a combinação dos dados recebidos com os dados do cliente. É assim que podemos fazer em Python usando a linguagem Pandas .
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)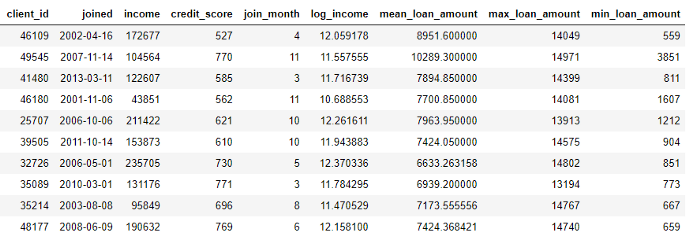
Essas operações não são complicadas por si mesmas, mas se tivermos centenas de variáveis espalhadas por dezenas de tabelas, esse processo não poderá ser feito manualmente. Idealmente, precisamos de uma solução que possa executar automaticamente transformações e agregações em várias tabelas e combinar os dados resultantes em uma tabela. Embora o Pandas seja um ótimo recurso, ainda existem muitas manipulações de dados que queremos fazer manualmente! (Para obter mais informações sobre o design manual de recursos, consulte o excelente Python Data Science Handbook .)
Featuretools
Felizmente, featuretools é exatamente a solução que estamos procurando. Essa biblioteca Python de código aberto gera automaticamente muitos traços de um conjunto de tabelas relacionadas. O Featuretools é baseado em uma técnica conhecida como " Deep Feature Synthesis ", que soa muito mais impressionante do que realmente é (o nome vem da combinação de vários recursos, não porque usa aprendizado profundo!).
A síntese profunda de recursos combina várias operações de transformação e agregação (chamadas primitivas de recursosno dicionário FeatureTools) para criar recursos a partir de dados espalhados por várias tabelas. Como a maioria das idéias no aprendizado de máquina, é um método complexo baseado em conceitos simples. Ao estudar um bloco de construção de cada vez, podemos formar um bom entendimento dessa poderosa técnica.
Primeiro, vamos dar uma olhada nos dados do nosso exemplo. Já vimos algo do conjunto de dados acima e o conjunto completo de tabelas se parece com o seguinte:
clients: informações básicas sobre clientes na associação de crédito. Cada cliente possui apenas uma linha nesse quadro de dados
loans: empréstimos a clientes. Cada crédito tem apenas sua própria linha nesse quadro de dados, mas os clientes podem ter vários créditos.
payments: pagamentos de empréstimos. Cada pagamento tem apenas uma linha, mas cada empréstimo terá vários pagamentos.
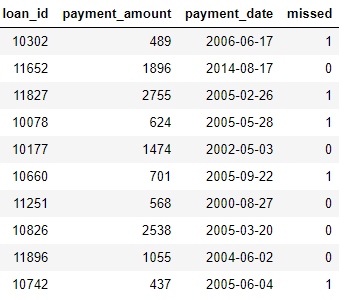
Se tivermos uma tarefa de aprendizado de máquina, como prever se um cliente reembolsará um empréstimo futuro, queremos combinar todas as informações do cliente em uma tabela. As tabelas estão vinculadas (por meio das variáveis
client_ide loan_id) e poderíamos usar uma série de transformações e agregações para concluir manualmente o processo. No entanto, veremos em breve que, em vez disso, podemos usar ferramentas de recurso para automatizar o processo.
Entidades e EntitySets (entidades e conjuntos de entidades)
Os dois primeiros conceitos de recursos são entidades e conjuntos de entidades . Entidade é apenas uma tabela (ou
DataFramese você pensa em Pandas). EntitySet é uma coleção de tabelas e relacionamentos entre elas. Imagine entityset é apenas outra estrutura de dados Python com seus próprios métodos e atributos.
Podemos criar um conjunto vazio de entidades em featuretools usando o seguinte:
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')Agora precisamos adicionar entidades. Cada entidade deve ter um índice, que é uma coluna com todos os elementos exclusivos. Ou seja, cada valor no índice deve aparecer apenas uma vez na tabela. O índice no quadro de dados
clientsé client_idporque cada cliente possui apenas uma linha nesse quadro de dados. Adicionamos uma entidade com um índice existente ao conjunto de entidades usando a seguinte sintaxe:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients,
index = 'client_id', time_index = 'joined')O quadro de dados
loanstambém possui um índice exclusivo loan_ide a sintaxe para adicioná-lo a um conjunto de entidades é a mesma que para clients. No entanto, não há índice exclusivo para o quadro de dados de pagamento. Quando adicionamos essa entidade ao conjunto de entidades, precisamos passar um parâmetro make_index = Truee especificar o nome do índice. Além disso, enquanto featuretools irá inferir automaticamente o tipo de dados de cada coluna em uma entidade, que pode substituir isso passando um dicionário de tipos de coluna para o parâmetro variable_types.
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')Para esse quadro de dados, mesmo sendo
missedum número inteiro, ele não é uma variável numérica , pois pode receber apenas 2 valores discretos; Depois de adicionar os quadros de dados ao conjunto de entidades, examinamos qualquer um deles:
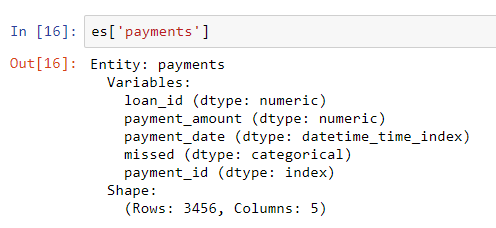
Os tipos de coluna foram inferidos corretamente com a revisão especificada. Em seguida, precisamos indicar como as tabelas no conjunto de entidades estão relacionadas.
Relações entre tabelas
A melhor maneira de representar o relacionamento entre duas tabelas é com uma analogia pai-filho . Relação um-para-muitos: cada pai pode ter vários filhos. Na área da tabela, a tabela pai possui uma linha para cada pai, mas a tabela filho pode ter várias linhas correspondentes a vários filhos do mesmo pai.
Por exemplo, em nosso conjunto de dados, o
clientsquadro é o pai do loansquadro. Cada cliente tem apenas uma linha clients, mas pode ter várias linhas loans. Da mesma forma, loansos paispaymentsporque cada empréstimo terá vários pagamentos. Os pais estão ligados aos filhos por uma variável comum. Quando fazemos a agregação, estamos agrupando a tabela filho pela variável pai e calculando estatísticas nos filhos de cada pai.
Para formalizar o relacionamento nas ferramentas de recursos , precisamos apenas especificar uma variável que vincule as duas tabelas.
clientse a tabela está loansassociada à variável client_id, e loans, e payments- com a ajuda de loan_id. A sintaxe para criar um relacionamento e adicioná-lo a um conjunto de entidades é mostrada abaixo:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es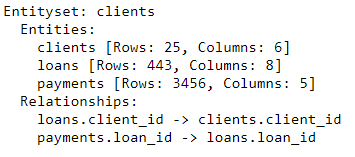
O conjunto de entidades agora contém três entidades (tabelas) e relacionamentos que unem essas entidades. Depois de adicionar entidades e formalizar relacionamentos, nosso conjunto de entidades está completo e estamos prontos para criar recursos.
Primitivas de recursos
Antes de podermos entrar completamente na síntese profunda de traços, precisamos entender as primitivas de traços . Já sabemos o que são, mas apenas os chamamos por nomes diferentes! Estas são apenas as operações básicas que usamos para formar novos recursos:
- Agregações: operações executadas em um relacionamento pai-filho (um-para-muitos) que são agrupadas por pai e calculam estatísticas para filhos. Um exemplo é agrupar uma tabela
loansporclient_ide determinar o montante máximo do empréstimo para cada cliente. - Conversões: operações executadas de uma tabela para uma ou mais colunas. Os exemplos incluem a diferença entre duas colunas na mesma tabela ou o valor absoluto de uma coluna.
Novos recursos são criados nas ferramentas de recurso usando essas primitivas, por si ou como várias primitivas. Abaixo está uma lista de algumas das primitivas em featuretools (também podemos definir primitivas personalizadas ):
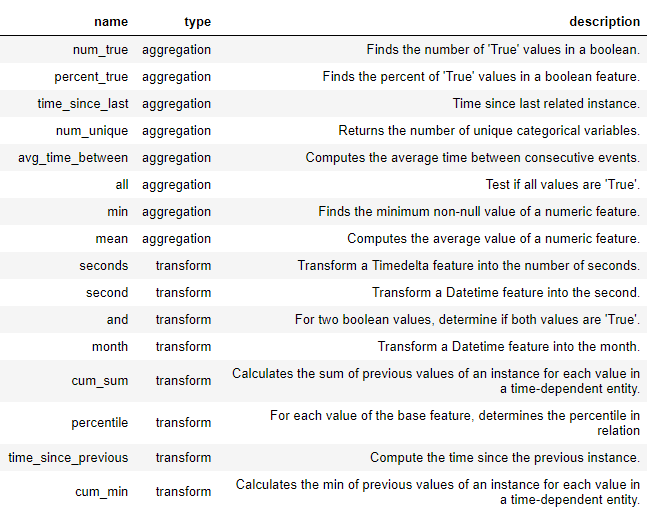
Essas primitivas podem ser usadas sozinhas ou combinadas para criar recursos. Para criar recursos com as primitivas especificadas, usamos uma função
ft.dfs(significa síntese profunda de recursos). Passamos um conjunto de entidades target_entity, que é uma tabela à qual queremos adicionar os recursos selecionados trans_primitives(transformações) e agg_primitives(agregados):
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])O resultado é um quadro de dados de novos recursos para cada cliente (porque criamos clientes
target_entity). Por exemplo, temos um mês em que cada cliente ingressou, o que é uma primitiva de transformação:
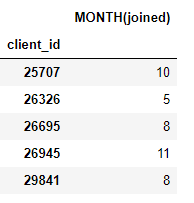
Também temos várias primitivas de agregação, como os valores médios de pagamento para cada cliente:
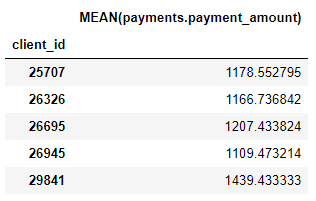
Embora tenhamos especificado apenas algumas primitivas, as feature featols criaram muitos novos recursos combinando e empilhando essas primitivas.
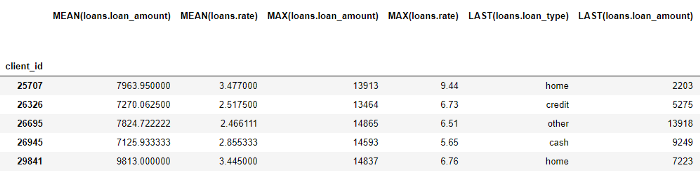
O quadro de dados completo contém 793 colunas de novos recursos!
Síntese Profunda de Sinais
Agora temos tudo para entender a síntese profunda de recursos (DFS). De fato, já fizemos dfs na chamada de função anterior! Uma característica profunda é simplesmente uma característica que consiste em uma combinação de várias primitivas, e dfs é o nome do processo que cria essas características. A profundidade de um recurso profundo é o número de primitivas necessárias para criar um recurso.
Por exemplo, uma coluna
MEAN (payment.payment_amount)é um recurso profundo com profundidade 1, porque foi criada usando uma única agregação. Um elemento com profundidade de dois é esse LAST(loans(MEAN(payment.payment_amount)). Isso é feito combinando duas agregações: ÚLTIMO (mais recente) em cima de MEAN. Isso representa o pagamento médio do empréstimo mais recente para cada cliente.
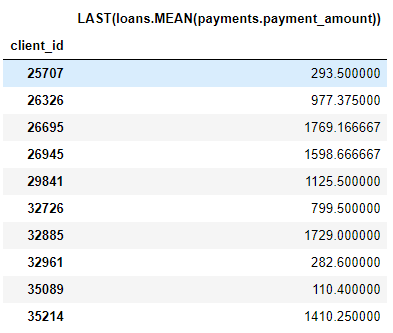
Podemos compor feições na profundidade que desejamos, mas na prática nunca fui além da profundidade 2. Após esse ponto, as características são difíceis de interpretar, mas exorto qualquer pessoa interessada a tentar "ir mais fundo" .
Não precisamos especificar manualmente as primitivas, mas podemos permitir que os recursos selecionem automaticamente recursos para nós. Para isso, usamos a mesma chamada de função
ft.dfs, mas não passamos nenhuma primitiva:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()
Featuretools criou muitos novos recursos para nós. Embora esse processo crie novas características automaticamente, ele não substituirá um cientista de dados, porque ainda precisamos descobrir o que fazer com todas essas características. Por exemplo, se nosso objetivo é prever se um cliente reembolsará um empréstimo, podemos procurar os sinais mais relevantes para um resultado específico. Além disso, se tivermos conhecimento da área de assunto, podemos usá-la para selecionar primitivas de recursos específicos ou sintetizar profundamente os recursos candidatos .
Próximos passos
O design automatizado de recursos resolveu um problema, mas criou outro: Muitos recursos. Embora seja difícil dizer quais desses recursos serão importantes antes da montagem de um modelo, provavelmente nem todos serão relevantes para a tarefa na qual queremos treinar nosso modelo. Além disso, muitos recursos podem prejudicar o desempenho do modelo, pois os recursos menos úteis excluem os mais importantes.
O problema de muitos atributos é conhecido como a maldição da dimensão . À medida que o número de características (dimensão dos dados) aumenta no modelo, fica mais difícil estudar a correspondência entre características e objetivos. De fato, a quantidade de dados necessária para que o modelo funcione bem éescala exponencialmente com o número de recursos .
A maldição da dimensionalidade é combinada com a redução de recursos (também conhecida como seleção de recursos) : o processo de remoção de recursos desnecessários. Isso pode assumir várias formas: Análise de componente principal (PCA), SelectKBest, usando valores de recurso de um modelo ou codificação automática usando redes neurais profundas. No entanto, a redução de recurso é um tópico separado para outro artigo. Neste ponto, sabemos que podemos usar ferramentas de recursos para criar muitos recursos de muitas tabelas com o mínimo de esforço!
Resultado
Como muitos tópicos no aprendizado de máquina, o design automatizado de recursos com recursos de ferramenta é um conceito complexo baseado em idéias simples. Usando os conceitos de conjuntos de entidades, entidades e relacionamentos, as ferramentas de operações podem executar uma síntese profunda de recursos para criar novos recursos. A síntese profunda de recursos, por sua vez, combina primitivas - agregados que operam por meio de relacionamentos um-para-muitos entre tabelas e transformações , funções aplicadas a uma ou mais colunas em uma tabela - para criar novos recursos a partir de várias tabelas.

Descubra os detalhes de como obter uma profissão de alto nível do zero ou subir de nível em habilidades e salário fazendo os cursos on-line pagos do SkillFactory:
- Curso de Machine Learning (12 semanas)
- Data Science (12 )
- (9 )
- «Python -» (9 )
- DevOps (12 )
- - (8 )