
Dia bom. Nossos nomes são Tatiana Voronova e Elvira Dyaminova, estamos envolvidos na análise de dados no Center 2M. Em particular, treinamos modelos de redes neurais para detectar objetos em imagens: pessoas, equipamentos especiais, animais.
No início de cada projeto, a empresa negocia com os clientes a qualidade de reconhecimento aceitável. Esse nível de qualidade não deve ser garantido apenas na entrega do projeto, mas também mantido durante a operação adicional do sistema. Acontece que é necessário monitorar e treinar constantemente o sistema. Gostaria de reduzir os custos desse processo e me livrar do procedimento de rotina, liberando tempo para trabalhar em novos projetos.
A reciclagem automática não é uma ideia única, pois muitas empresas possuem ferramentas de pipeline internas semelhantes. Neste artigo, gostaríamos de compartilhar nossa experiência e mostrar que não é necessário ser uma grande empresa para implementar com êxito essas práticas.
Um de nossos projetos é contar pessoas em filas . Devido ao fato de o cliente ser uma grande empresa com um grande número de filiais, as pessoas em determinadas horas se acumulam conforme programado, ou seja, um grande número de objetos (cabeças das pessoas) é detectado regularmente. Portanto, decidimos iniciar a implementação do treinamento automático precisamente para esta tarefa.
É assim que nosso plano era. Todos os itens, exceto o trabalho do escriba, são realizados no modo automático:
- Uma vez por mês, todas as imagens da câmera da última semana são selecionadas automaticamente.
- xls- sharepoint, - : « ».
- ( ) – xml- ( ), – .
- « ». xls- ( – , – ). «». , , .
, : (, ) , , (, - ). -. - xls- «» > 0. , ( ). , . , , « ». , . , . , , .
- «» 0, – - .
- , , , , . , .
No final, esse processo nos ajudou muito. Monitoramos um aumento nos erros do tipo II, quando muitas cabeças se tornaram "mascaradas" de repente, enriquecemos o conjunto de dados de treinamento com um novo tipo de cabeças no tempo e treinamos novamente o modelo atual. Além disso, esta viagem permite levar em consideração a sazonalidade. Estamos constantemente ajustando o conjunto de dados, levando em consideração a situação atual: as pessoas costumam usar chapéus ou, pelo contrário, quase todo mundo vem à instituição sem eles. No outono, o número de pessoas que usam capuzes aumenta. O sistema se torna mais flexível e reage à situação.
Por exemplo, na imagem abaixo - um dos ramos (em um dia de inverno), cujos quadros não foram apresentados no conjunto de dados de treinamento:
Se calcularmos as métricas para esse quadro (TP = 25, FN = 3, FP = 0), verifica-se que o recall é de 89%, a precisão é de 100% e a média harmônica entre precisão e completude é de cerca de 94. 2% (sobre métricas logo abaixo). Resultado muito bom para uma nova sala.
Nosso conjunto de dados de treinamento tinha tampas e capuzes, portanto o modelo não ficou confuso, mas com o início do modo de máscara, ele começou a cometer erros. Na maioria dos casos, quando a cabeça está claramente visível, não surgem problemas. Mas se uma pessoa está longe da câmera, então, em um determinado ângulo, o modelo para de detectar a cabeça (a imagem da esquerda é o resultado do trabalho do modelo antigo). Graças à marcação semiautomática, conseguimos consertar esses casos e treinar novamente o modelo a tempo (a imagem correta é o resultado do novo modelo).

Muito perto:

ao testar o modelo, selecionamos quadros que não estavam envolvidos no treinamento (um conjunto de dados com um número diferente de pessoas no quadro, de diferentes ângulos e tamanhos diferentes), para avaliar a qualidade do modelo, usamos recall e precisão.
Lembre -se de que a integridade mostra qual proporção de objetos que realmente pertencem a uma classe positiva, previmos corretamente.
Precisão - a precisão mostra qual a proporção de objetos reconhecidos como objetos de uma classe positiva que previmos corretamente.
Quando um cliente precisava de um único dígito, uma combinação de precisão e perfeição, fornecíamos a média harmônica, ou medida F. Saiba mais sobre métricas.
Após um ciclo, obtivemos os seguintes resultados:
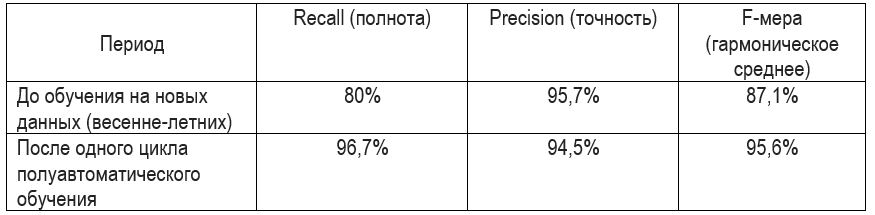
A completude de 80% antes de qualquer alteração se deve ao fato de um grande número de novos departamentos ter sido adicionado ao sistema, surgiram novas visualizações. Além disso, a estação mudou; antes disso, "pessoas de outono-inverno" eram apresentadas no conjunto de dados de treinamento.
Após o primeiro ciclo, a completude passou a 96,7%. Comparado com o primeiro artigo, a completude chegou a 90%. Tais mudanças devem-se ao fato de que agora o número de pessoas nos departamentos diminuiu, elas começaram a se sobrepor muito menos (as jaquetas volumosas acabaram) e a variedade de chapéus diminuiu.
Por exemplo, antes da norma era quase o mesmo número de pessoas que na imagem abaixo.

É assim que as coisas são agora.

Resumindo, vamos citar as vantagens da automação:
- Automação parcial do processo de marcação.
- ( ).
- ( ).
- . .
- . , .
A desvantagem é o fator humano por parte do designer da marcação - ele pode não ser responsável o suficiente pela marcação, portanto, marcação com sobreposição ou uso de conjuntos dourados - tarefas com uma resposta predeterminada, que são necessárias apenas para controlar a qualidade da marcação, são necessárias. Em muitas tarefas mais complexas, o analista deve verificar pessoalmente a marcação - nessas tarefas o modo automático não funcionará.
Em geral, a prática de reciclagem automática provou ser viável. Essa automação pode ser considerada como um mecanismo adicional que permite manter a qualidade do reconhecimento em um bom nível durante a operação adicional do sistema.
Autores do artigo: Tatiana Voronova (tvoronova), Elvira Dyaminova (elviraa)