
Este artigo descreve os detalhes técnicos dos problemas que causaram a falha do Slack em 12 de maio de 2020. Para mais informações sobre o processo de resposta a esse incidente, consulte a cronologia de Ryan Katkov, "Ambas as mãos no controle remoto" .
Em 12 de maio de 2020, o Slack sofreu seu primeiro acidente significativo em muito tempo. Em breve, publicamos um resumo do incidente , mas é uma história bastante interessante, por isso gostaríamos de nos aprofundar nos detalhes técnicos com mais detalhes.
Os usuários notaram o tempo de inatividade às 16h45, mas a história realmente começou por volta das 20h30. A equipe de engenharia de confiabilidade do banco de dados recebeu um aviso sobre um aumento significativo na carga de parte da infraestrutura. Ao mesmo tempo, a equipe de tráfego recebeu avisos de que não estamos fazendo algumas solicitações de API.
O aumento da carga do banco de dados foi causado pela implantação de uma nova configuração, o que causou um bug de desempenho de longa data. A alteração foi rapidamente identificada e revertida - era um sinalizador para uma função que fazia uma implantação gradual; portanto, o problema foi resolvido rapidamente. O incidente teve pouco impacto nos clientes, mas durou apenas três minutos, e a maioria dos usuários ainda conseguiu enviar mensagens com sucesso durante essa breve falha matinal.
Uma das conseqüências do incidente foi uma expansão significativa da nossa camada principal de aplicativos da web. Nosso CEO Stuart Butterfield escreveu sobre alguns dos impactos da quarentena e do auto-isolamento no uso do Slack. Como resultado da pandemia, lançamos significativamente mais instâncias no nível de aplicativos da Web do que em fevereiro deste ano. Escalamos rapidamente quando os trabalhadores são carregados, como aconteceu aqui - mas eles esperaram muito mais tempo para que algumas consultas ao banco de dados fossem concluídas, o que causou uma carga maior. Durante o incidente, aumentamos o número de instâncias em 75%, o que resultou no maior número de hosts de aplicativos da web que já executamos até hoje.
Tudo parecia estar funcionando bem pelas próximas oito horas - até que um número incomumente alto de erros de HTTP 503 apareceu . Lançamos um novo canal de resposta a incidentes, e o engenheiro de aplicativos da Web de plantão aumentou manualmente a frota de aplicativos da Web como uma mitigação inicial. Curiosamente, isso não ajudou em nada. Percebemos muito rapidamente que algumas das instâncias de aplicativos da web estavam sob carga pesada, enquanto as demais não. Inúmeros estudos começaram a investigar o desempenho de aplicativos da web e o balanceamento de carga. Após alguns minutos, identificamos o problema.
Por trás do balanceador de carga da camada 4, há um conjunto de instâncias HAProxy para distribuir solicitações para a camada de aplicativos da web. Usamos o Consul para descoberta de serviço e um modelo de consul para renderizar listas de back-end de aplicativos da web saudáveis para os quais o HAProxy deve encaminhar solicitações.
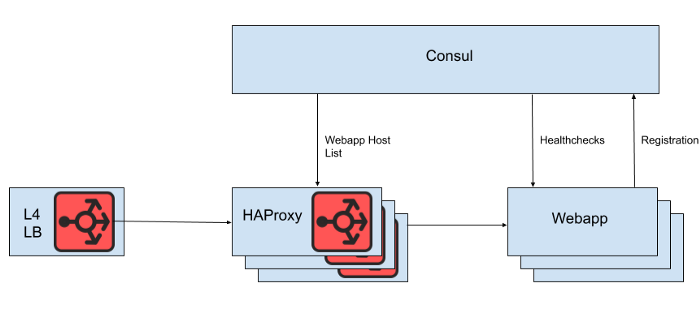
FIG. 1. Uma visualização de alto nível da arquitetura de balanceamento de carga do Slack
No entanto, não renderizamos a lista de hosts de aplicativos da web diretamente do arquivo de configuração HAProxy, porque a atualização da lista nesse caso requer uma reinicialização do HAProxy. O processo de reinicialização do HAProxy envolve a criação de um processo completamente novo, mantendo o antigo até concluir o processamento das solicitações atuais. Reinicializações muito frequentes podem levar à execução de muitos processos HAProxy e a um desempenho ruim. Essa limitação entra em conflito com o objetivo de dimensionar automaticamente a camada de aplicativos da web, que é trazer novas instâncias para produção o mais rápido possível. Portanto, estamos usando a API do HAProxy Runtimepara gerenciar o estado do servidor HAProxy sem reiniciar toda vez que o servidor da camada da web entra ou sai. Vale ressaltar que o HAProxy pode se integrar à interface DNS do Consul, mas isso aumenta o atraso devido ao TTL do DNS, limita o uso de tags Consul e o gerenciamento de respostas DNS muito grandes geralmente leva a situações e erros de borda dolorosos.

FIG. 2. Como um conjunto de back-end de aplicativos da web é gerenciado em um único servidor Slack HAProxy
No nosso estado HAProxy, definimos modelos para servidores HAProxy. De fato, esses são "slots" que os aplicativos de aplicativos da web podem ocupar. Quando uma instância de um novo aplicativo Web é lançada ou a antiga começa a falhar, o catálogo de serviços do Consul é atualizado. O consul-template imprime uma nova versão da lista de hosts, e um programa separado de gerenciamento de haproxy-server-state desenvolvido no Slack lê essa lista de hosts e usa a HAProxy Runtime API para atualizar o estado HAProxy.
Executamos M Pools de Instâncias HAProxy simultâneos e Pools de aplicativos da Web, cada um em uma zona de disponibilidade da AWS separada. O HAProxy é configurado com N "slots" para back-end de aplicativos da web em cada AZ, fornecendo um total de N * M back-end que podem ser direcionados a todos os AZs. Alguns meses atrás, esse número era mais do que suficiente - nunca lançamos nada nem perto de tantas instâncias do nosso nível de aplicativo da web. No entanto, após o incidente matinal do banco de dados, lançamos um pouco mais do que as instâncias de aplicativos da web N * M. Se você pensa nos slots HAProxy como um jogo gigante de cadeiras, algumas dessas instâncias de aplicativos da Web ficam sem espaço. Isso não foi um problema - temos capacidade de serviço mais que suficiente.
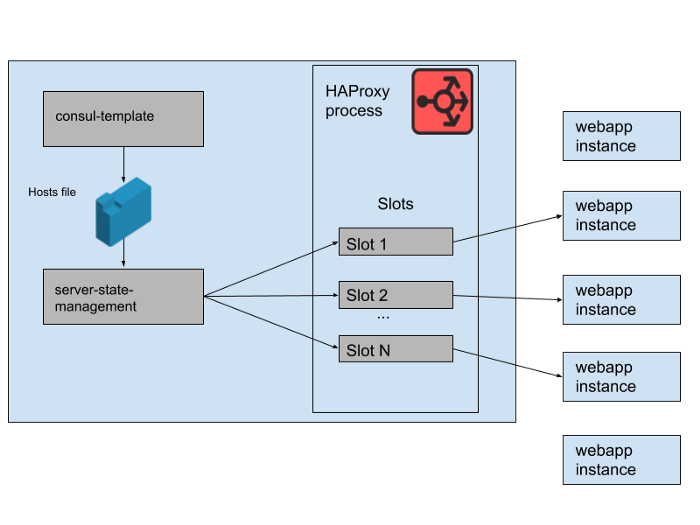
FIG. 3. "Slots" no processo HAProxy com algumas instâncias redundantes de aplicativos da web que não recebem tráfego
No entanto, houve um problema durante o dia. Houve um erro no programa que sincronizou a lista de hosts gerada pelo consul-template com o estado do servidor HAProxy. O programa sempre tentava encontrar um slot para novas instâncias de aplicativos da web antes de liberar espaços ocupados por instâncias antigas de aplicativos da web que não funcionam mais. Este programa começou a gerar erros e a sair mais cedo porque não conseguiu encontrar nenhum slot vazio, o que significava que as instâncias HAProxy em execução não estavam atualizando seu estado. À medida que o dia avançava, o grupo de escalonamento automático de aplicativos da web aumentava e diminuía, e a lista de back-end no estado HAProxy se tornava cada vez mais obsoleta.
Às 16h45, a maioria das instâncias HAProxy só conseguiu enviar solicitações para o conjunto de back-end disponível pela manhã, e esse conjunto de back-end antigos de aplicativos da Web agora era uma minoria. Fornecemos regularmente novas instâncias HAProxy, portanto, houve algumas novas com a configuração correta, mas a maioria tinha mais de oito horas e, portanto, ficou com um estado de back-end completo e desatualizado. Por fim, o serviço travou. Isso aconteceu no final de um dia útil nos Estados Unidos, porque é quando começamos a escalar a camada de aplicativos da Web à medida que o tráfego diminui. A escala automática encerraria as instâncias antigas de aplicativos da Web em primeiro lugar, o que significava que não havia o suficiente delas no estado do servidor do HAProxy para atender à demanda.
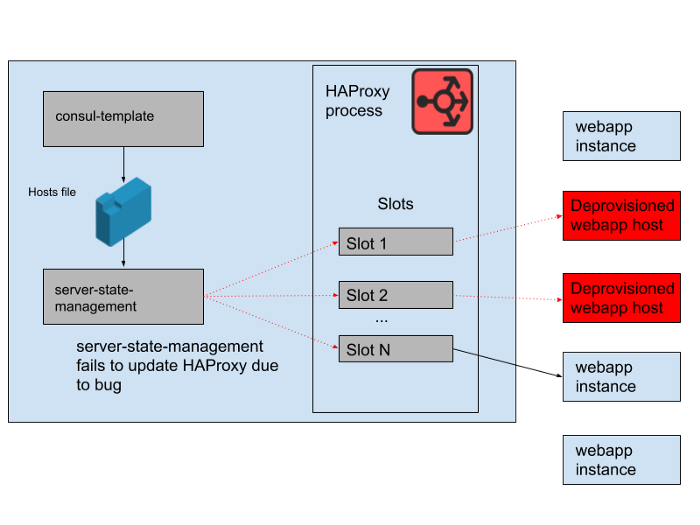
FIG. 4. O estado do HAProxy mudou com o tempo e os slots começaram a se referir principalmente a hosts
remotos.Quando descobrimos a causa da falha, ele foi rapidamente corrigido por uma reinicialização suave da frota HAProxy. Depois disso, perguntamos imediatamente: por que o monitoramento não detectou esse problema. Temos um sistema de alerta para essa situação específica, mas infelizmente não funcionou conforme o esperado. A falha no monitoramento não foi percebida, em parte porque o sistema "apenas funcionou" por um longo tempo e não exigiu nenhuma alteração. A implantação mais ampla do HAProxy da qual esse aplicativo faz parte também é relativamente estática. Em uma taxa lenta de mudança, menos engenheiros interagem com a infraestrutura de monitoramento e alerta.
Não reformulamos muito essa pilha HAProxy, porque estamos gradualmente transferindo todo o balanceamento de carga para o Envoy (recentemente transferimos o tráfego de soquete da Web para ele). O HAProxy tem servido bem e de maneira confiável por muitos anos, mas possui alguns problemas operacionais, como neste incidente. Substituiremos o pipeline complexo para gerenciar o estado do servidor HAProxy por nossa própria integração do Envoy com o plano de controle xDS para a descoberta do terminal. As versões mais recentes do HAProxy (desde a versão 2.0) também resolvem muitos desses problemas operacionais. No entanto, já confiamos no Envoy com a malha de serviço interna há algum tempo, então nos esforçamos para transferir o balanceamento de carga para ela também. Nosso teste inicial do Envoy + xDS em escala parece promissor, e essa migração deve melhorar o desempenho e a disponibilidade no futuro.A nova arquitetura de balanceamento de carga e descoberta de serviço é imune ao problema que causou essa falha.
Nós nos esforçamos para manter o Slack acessível e confiável, mas nesse caso falhamos. O Slack é uma ferramenta essencial para nossos usuários, e é por isso que nos esforçamos para aprender com cada incidente, independentemente de os clientes perceberem ou não. Lamentamos o inconveniente causado por essa falha. Prometemos usar esse conhecimento para melhorar nossos sistemas e processos.