Hoje, quero falar sobre outra coisa - sobre algo que não pertence às melhores práticas, com a ajuda de que é muito fácil dar um tiro no pé e tornar uma consulta executada anteriormente mais lenta, ou não executar mais devido a um erro ... É sobre dicas e guias de plano.
Dicas são dicas para o otimizador de consultas, uma lista completa pode ser encontrada no MSDN . Algumas delas são realmente dicas (por exemplo, você pode especificar OPTION (MAXDOP 4)) para que a consulta possa ser executada com um grau máximo de paralelismo = 4, mas não há garantia de que o SQL Server gere um plano paralelo com essa dica.
A outra parte é um guia direto para a ação. Por exemplo, se você escrever OPTION (HASH JOIN), o SQL Server criará um plano sem NESTED LOOPS e MERGE JOINs. E você sabe o que acontecerá se for impossível criar um plano apenas com junções de hash? O otimizador dirá isso - não consigo criar um plano e a consulta não será executada.
O problema é que não se sabe ao certo (pelo menos para mim) quais dicas são dicas que o otimizador pode usar; e quais dicas são dicas manuais que podem causar falha na solicitação se algo der errado. Certamente já existe alguma coleção pronta onde isso é descrito, mas, de qualquer forma, não é uma informação oficial e pode mudar a qualquer momento.
O Guia de Plano é uma coisa (que eu não sei traduzir corretamente) que permite vincular um conjunto específico de dicas a uma solicitação específica, cujo texto você conhece. Isso pode ser relevante se você não puder influenciar diretamente o texto da solicitação gerado pelo ORM, por exemplo.
As dicas e os guias de plano não são, de forma alguma, práticas recomendadas, mas é uma boa prática omitir as dicas e esses guias, porque a distribuição de dados pode mudar, os tipos de dados podem mudar e um milhão a mais de coisas podem acontecer, devido às quais suas consultas com dicas funcionarão pior do que sem elas e, em alguns casos, pararão de funcionar completamente. Você deve estar cem por cento consciente do que está fazendo e por quê.
Agora, uma pequena explicação de por que eu entrei nisso.
Eu tenho uma mesa larga com um monte de campos nvarchar de tamanhos diferentes - de 10 a max. E há várias consultas nessa tabela, que CHARINDEX procura ocorrências de substrings em uma ou mais dessas colunas. Por exemplo, há uma solicitação que se parece com isso:
SELECT *
FROM table
WHERE CHARINDEX(N' ', column)>1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET x ROWS FETCH NEXT y ROWS ONLYA tabela possui um índice clusterizado no ID e um índice não clusterizado não exclusivo na coluna. Como você mesmo entende, não há sentido em tudo isso, pois em WHERE usamos CHARINDEX, que definitivamente não é SARGable. Para evitar possíveis problemas com o SB, vou simular essa situação no banco de dados aberto StackOverflow2013, que pode ser encontrado aqui .
Considere a tabela dbo.Posts, que possui apenas um índice clusterizado por ID e uma consulta como esta:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYPara corresponder ao meu banco de dados real, eu crio um índice na coluna Título:
CREATE INDEX ix_Title ON dbo.Posts (Title);Como resultado, é claro, obtemos um plano de execução absolutamente lógico, que consiste em varrer o índice clusterizado na direção oposta:
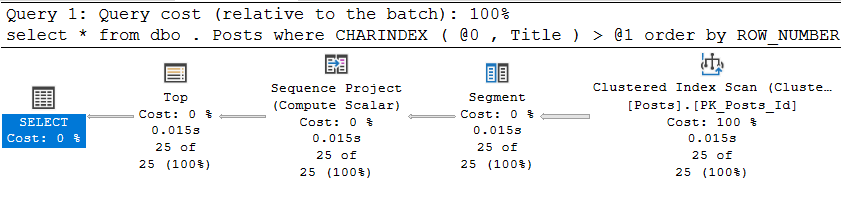

e, reconhecidamente, ele é executado muito bem:
Tabela 'Posts'. Contagem de varreduras 1, leituras lógicas 516, leituras físicas 0, leituras de read-ahead 0, leituras lógicas de lob 0, leituras físicas de lob 0, leituras de lob de leitura antecipada 0.
Tempos de execução do SQL Server:
Tempo de CPU = 16 ms
Mas o que acontece se, em vez da palavra comum 'Dados', procurarmos algo mais raro? Por exemplo, N'Aptana '(não faz ideia do que é). O plano, é claro, permanecerá o mesmo, mas as estatísticas de execução, ahem, mudarão um pouco:
Tabela 'Posts'. Contagem de varredura 1, leituras lógicas 253191, leituras físicas 113, leituras de leitura antecipada 224602, leituras lógicas de lob 0, leituras físicas de lob 0, leituras de leitura antecipada de lob 0.
Tempos de Execução do SQL Server:
Tempo de CPU = 2563 ms
E isso também é lógico - a palavra é muito menos comum e o SQL Server precisa varrer muito mais dados para encontrar 25 linhas. Mas de alguma forma não é legal, certo?
E eu estava criando um índice não clusterizado. Talvez fosse melhor se o SQL Server o usasse? Ele próprio não vai usá-lo, então eu adiciono uma dica:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Title)));E, de alguma forma, algo é completamente triste. Estatísticas de execução:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 5, logical reads 109312, physical reads 5, read-ahead reads 104946, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 35031 ms
e o plano:

agora o plano de execução é paralelo e possui dois tipos, ambos com derramamentos no tempdb. A propósito, preste atenção à primeira classificação, que é realizada após uma verificação de índice não em cluster, antes da Pesquisa de Chave - esta é uma otimização especial do SQL Server que tenta reduzir o número de pesquisas de chave de E / S Aleatória - executadas em ordem crescente da chave de índice em cluster. Você pode ler mais sobre isso aqui .
A segunda classificação é necessária para selecionar 25 linhas em ordem decrescente. A propósito, o SQL Server pode ter adivinhado que terá que classificar por ID novamente, apenas em ordem decrescente e fazer pesquisas de chave na direção "oposta", classificando em ordem decrescente, e não crescente, a chave de índice clusterizada no início.
Não forneço estatísticas sobre a execução de uma consulta com uma dica em um índice não clusterizado com uma pesquisa pela entrada 'Data'. No meu disco rígido meio morto em um laptop, demorou mais de 16 minutos e não pensei em tirar uma captura de tela. Desculpe, não quero mais esperar tanto.
Mas e o pedido? A varredura de índice em cluster é o sonho final e você não pode fazer nada mais rápido?
E se eu tentasse evitar todos os tipos, pensei e criei um índice não clusterizado, que, em geral, contradiz o que geralmente é considerado a melhor prática para índices não clusterizados:
CREATE INDEX ix_Id_Title ON dbo.Posts (Id DESC, Title);Agora usamos a dica para dizer ao SQL Server para usá-lo:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Id_Title)));Ah, funcionou bem:

Tabela 'Posts'. Contagem de varredura 1, leituras lógicas 6259, leituras físicas 0, leituras antecipadas 7816, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tempos de Execução do SQL Server:
Tempo de CPU = 1734 ms
O ganho no tempo do processador não é grande, mas é preciso ler muito menos - não é ruim. E os frequentes 'Dados'?
Tabela 'Posts'. Contagem de varreduras 1, leituras lógicas 208, leituras físicas 0, leituras de leitura antecipada 0, leituras lógicas de lob 0, leituras físicas de lob 0, leituras de leitura antecipada de lob 0.
Tempos de execução do SQL Server:
Tempo de CPU = 0 ms
Uau, isso também é bom. Agora, como a solicitação vem do ORM e não podemos alterar seu texto, precisamos descobrir como "fixar" esse índice na solicitação. E o guia do plano vem em socorro.
O procedimento armazenado sp_create_plan_guide ( MSDN ) é usado para criar um guia de plano .
Vamos considerar em detalhes:
sp_create_plan_guide [ @name = ] N'plan_guide_name'
, [ @stmt = ] N'statement_text'
, [ @type = ] N'{ OBJECT | SQL | TEMPLATE }'
, [ @module_or_batch = ]
{
N'[ schema_name. ] object_name'
| N'batch_text'
| NULL
}
, [ @params = ] { N'@parameter_name data_type [ ,...n ]' | NULL }
, [ @hints = ] {
N'OPTION ( query_hint [ ,...n ] )'
| N'XML_showplan'
| NULL
} nome - nome claro e exclusivo do guia de plano
stmt- este é o pedido ao qual você precisa adicionar a dica. É importante saber aqui que esse pedido deve ser escrito EXATAMENTE o mesmo que o pedido que vem do aplicativo. Espaço estranho? O Guia do Plano não será utilizado. Quebra de linha errada? O Guia do Plano não será utilizado. Para facilitar as coisas para você, existe um "truque de vida" ao qual voltarei um pouco mais tarde (e que encontrei aqui ).
tipo - indica onde a solicitação especificada em stmt. Se faz parte de um procedimento armazenado, deve ser OBJECT; se isso faz parte de um lote de várias solicitações, ou é uma solicitação ad-hoc ou um lote de uma solicitação, deve haver SQL. Se TEMPLATE for indicado aqui, esta é uma história separada sobre parametrização de consulta, sobre a qual você pode ler no MSDN .
@module_or_batch depende detipo. Se umtipo= 'OBJECT', este deve ser o nome do procedimento armazenado. Se umtipo= 'BATCH' - deve haver o texto do lote inteiro, especificado palavra por palavra com o que vem dos aplicativos. Espaço estranho? Bem, você já sabe. Se for NULL, consideramos que este é um lote de uma solicitação e corresponde ao especificado emstmt com todas as restrições.
params- todos os parâmetros que são passados para a solicitação junto com os tipos de dados devem ser listados aqui.
Finalmente, a @hints é a parte interessante, aqui você precisa especificar quais dicas adicionar à solicitação. Aqui você pode inserir explicitamente o plano de execução necessário no formato XML, se houver. Esse parâmetro também pode ser NULL, o que levará ao fato do SQL Server não usar dicas especificadas explicitamente na consulta emstmt.
Portanto, criamos um guia de plano para a consulta:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N''Data'', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY';
exec sp_create_plan_guide @name = N'PG_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = NULL
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'E tentamos executar a solicitação:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYUau, funcionou:
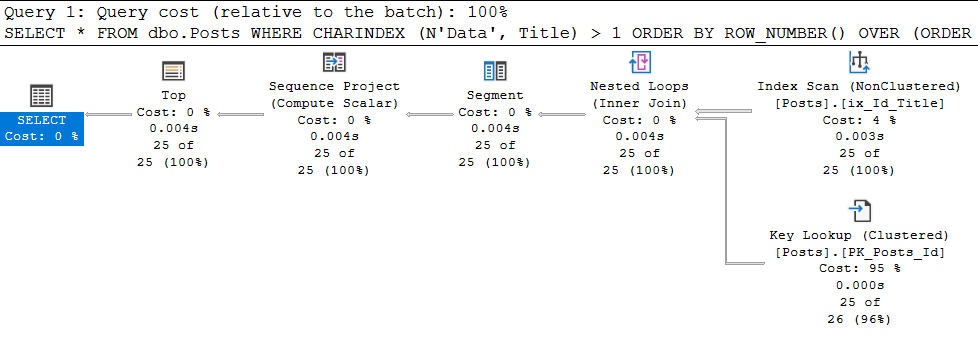
nas propriedades da última instrução SELECT, vemos:

Ótimo, o plano giude foi aplicado. E se você procurar por 'Aptana' agora? E tudo ficará ruim - retornaremos novamente à varredura do índice clusterizado com todas as consequências. Por quê? E porque, o guia de plano é aplicado a uma consulta ESPECÍFICA, cujo texto coincide um a um com a execução.
Felizmente para mim, a maioria dos pedidos no meu sistema é parametrizada. Não trabalhei com consultas não parametrizadas e espero não precisar. Para eles, você pode usar modelos (veja um pouco mais sobre TEMPLATE), pode ativar a PARAMETERIZAÇÃO FORÇADA no banco de dados ( não faça isso sem entender o que está fazendo !!! ) e, talvez, depois disso, poderá vincular o Guia de Planejamento. Mas eu realmente não tentei.
No meu caso, a solicitação é executada em algo assim:
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Aptana', @p1 = 0, @p2 = 25;Portanto, crio um guia de plano correspondente:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;';
exec sp_create_plan_guide @name = N'PG_paramters_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = N'@p0 nvarchar(250), @p1 int, @p2 int'
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'E, viva, tudo funciona como necessário:
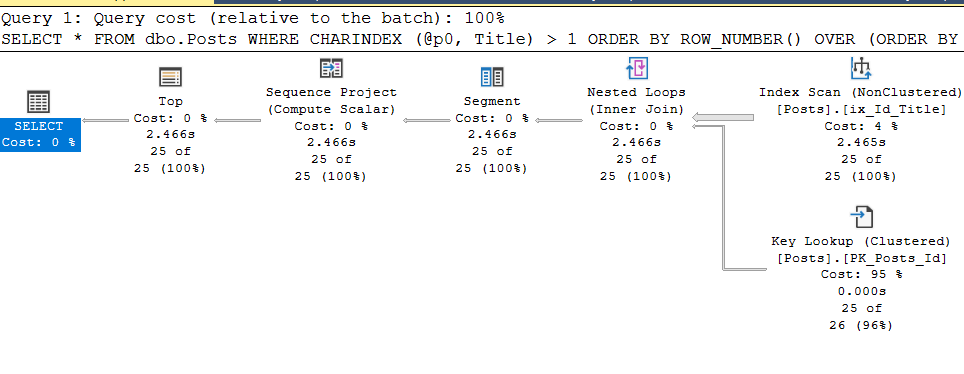

estando fora das condições da estufa, nem sempre é possível especificar corretamente o parâmetrostmtpara anexar um guia de plano a uma solicitação, e para isso existe um "truque de vida" que mencionei acima. Limpamos o cache do plano, excluímos os guias, executamos a consulta parametrizada novamente e obtemos seu plano de execução e seu plan_handle do cache.
Uma solicitação para isso pode ser usada, por exemplo, assim:
SELECT qs.plan_handle, st.text, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp
Agora podemos usar o procedimento armazenado sp_create_plan_guide_from_handle para criar um guia de plano a partir de um plano existente.
Toma como parâmetrosnome- o nome do guia criado, @plan_handle - o identificador do plano de execução existente e @statement_start_offset - que define o início da instrução no lote para o qual o guia deve ser criado.
Tentando:
exec sp_create_plan_guide_from_handle N'PG_dboPosts_from_handle'
, 0x0600050018263314F048E3652102000001000000000000000000000000000000000000000000000000000000
, NULL;E agora no SSMS, examinamos o que temos em Programmability -> Plan Guides:

Agora, o plano de execução atual foi "pregado" em nossa solicitação usando o Guia do Plano 'PG_dboPosts_from_handle', mas, o melhor de tudo, agora, como quase qualquer objeto no SSMS, podemos criar scripts e recriar da maneira que precisamos.
RMB, Script -> Solte AND Create e obtemos um script pronto no qual precisamos substituir o valor do parâmetro @hints pelo parâmetro de que precisamos, portanto, obtemos:
USE [StackOverflow2013]
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_control_plan_guide @operation = N'DROP', @name = N'[PG_dboPosts_from_handle]'
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_create_plan_guide @name = N'[PG_dboPosts_from_handle]', @stmt = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY', @type = N'SQL', @module_or_batch = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;',
@params = N'@p0 nvarchar(250), @p1 int, @p2 int',
@hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
GOExecutamos e reexecutamos a solicitação. Viva, tudo funciona:

se você substituir o valor do parâmetro, tudo funciona da mesma maneira.
Observe que apenas um guia pode corresponder a uma declaração. Se você tentar adicionar outro guia à mesma instrução, você receberá uma mensagem de erro.
A mensagem 10502, nível 16, estado 1, linha 1
não pode criar o guia de plano 'PG_dboPosts_from_handle2' porque a instrução especificada porstmte @module_or_batch, ou por @plan_handle e @statement_start_offset, correspondem ao guia de plano existente 'PG_dboPosts_from_handle' no banco de dados. Solte o guia de plano existente antes de criar o novo guia de plano.
A última coisa que gostaria de mencionar é o procedimento armazenado sp_control_plan_guide .
Com sua ajuda, você pode excluir, desativar e ativar os Guias de plano - um de cada vez, com o nome e todos os guias (não tenho certeza - tudo. Ou tudo no contexto do banco de dados em que o procedimento é executado) - os valores são usados para isso @ parâmetro de operação - DROP ALL, DISABLE ALL, ENABLE ALL. Um exemplo de uso da HP para um plano específico é dado logo acima - um Guia de plano específico com o nome especificado é excluído.
Era possível ficar sem dicas e um guia de plano?
Em geral, se lhe parecer que o otimizador de consultas é estúpido e faz algum tipo de jogo, e você sabe qual a melhor, com uma probabilidade de 99%, está fazendo algum tipo de jogo (como no meu caso). No entanto, no caso em que você não tem a capacidade de influenciar diretamente o texto da solicitação, um guia de plano que permite adicionar uma dica à solicitação pode ser um salva-vidas. Suponha que tenhamos a capacidade de reescrever o texto da solicitação conforme necessário - isso pode mudar alguma coisa? Certo! Mesmo sem o uso de "exótico" na forma de pesquisa de texto completo, que, de fato, deve ser usada aqui. Por exemplo, essa consulta possui um plano completamente normal (para uma consulta) e estatísticas de execução:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tabela 'Posts'. Contagem de varredura 1, leituras lógicas 6250, leituras físicas 0, leituras de read-ahead 0, leituras lógicas de lob 0, leituras físicas de lob 0, leituras de read-ahead de lob 0.
Tempos de execução do SQL Server:
Tempo de CPU = 1500 ms
O SQL Server localiza primeiro os 25 identificadores necessários pelo índice "torto" do ix_Id_Title e só então faz uma pesquisa no índice clusterizado pelos identificadores selecionados - ainda melhor do que com o guia! Mas o que acontece se executarmos uma consulta em 'Dados' e exibirmos 25 linhas, começando na 20.000ª linha:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 20000 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tabela 'Posts'. Contagem de varreduras 1, leituras lógicas 5914, leituras físicas 0, leituras de read-ahead 0, leituras lógicas de lob 11, leituras físicas de lob 0, leituras de read-ahead de 0.
Tempos de Execução do SQL Server:
Tempo de CPU = 1453 ms
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Data', @p1 = 20000, @p2 = 25;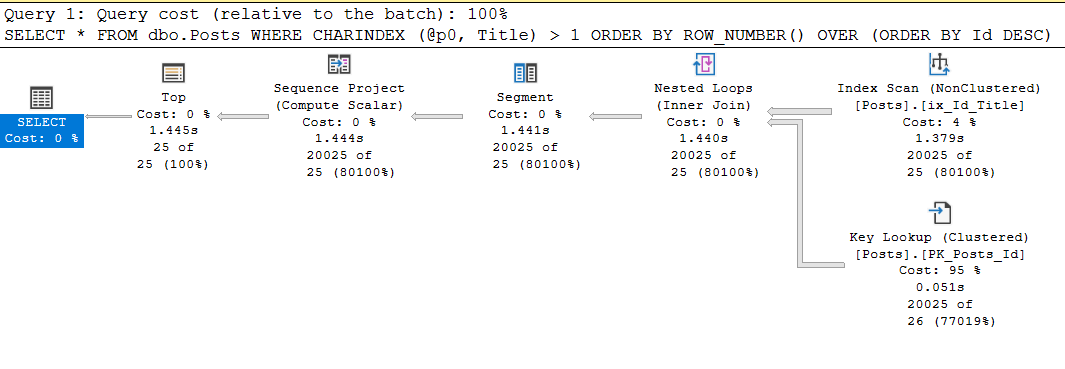
Table 'Posts'. Scan count 1, logical reads 87174, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1437 ms
Sim, o tempo do processador é o mesmo, uma vez que é gasto no charindex, mas a solicitação com o guia faz uma ordem de magnitude mais leituras, e isso pode se tornar um problema.
Deixe-me resumir o resultado final. Dicas e guias podem ajudar muito no aqui e agora, mas podem facilmente tornar as coisas ainda piores. Se você especificar explicitamente uma dica com um índice no texto da solicitação e excluir o índice, a consulta simplesmente não poderá ser executada. No meu SQL Server 2017, a consulta com o guia, após excluir o índice, é executada corretamente - o guia é ignorado, mas não posso ter certeza de que sempre será assim e em todas as versões do SQL Server.
Não há muitas informações sobre o guia de plano em russo, então decidi escrevê-lo eu mesmo. Você pode ler aquisobre limitações no uso de guias de plano, em particular sobre o fato de que algumas vezes uma indicação explícita do índice com uma dica usando o PG pode levar ao fato de que as solicitações cairão. Desejo que você nunca os use e, se precisar - bem, boa sorte - você sabe aonde isso pode levar.