Trazemos a sua atenção a tradução de uma pesquisa interessante da empresa Crowdstrike. O material é dedicado ao uso da linguagem Rust no campo da Data Science (em relação à análise de malware) e demonstra como o Rust pode competir nesse campo, mesmo com o NumPy e o SciPy, sem mencionar o Python puro .

Gostar de ler!
Python é uma das linguagens de programação de ciência de dados mais populares e por boas razões. O Python Package Index (PyPI) possui inúmeras bibliotecas impressionantes de ciência de dados, como NumPy, SciPy, Natural Language Toolkit, Pandas e Matplotlib. Com uma abundância de bibliotecas de análise de alta qualidade disponíveis e uma extensa comunidade de desenvolvedores, o Python é a escolha óbvia para muitos cientistas de dados.
Muitas dessas bibliotecas são implementadas em C e C ++ por razões de desempenho, mas fornecem interfaces de função externa (FFIs) ou ligações do Python para que as funções possam ser chamadas do Python. Essas implementações de linguagem de nível inferior destinam-se a mitigar algumas das deficiências mais visíveis do Python, principalmente em termos de tempo de execução e consumo de memória. Se você pode limitar o tempo de execução e o consumo de memória, a escalabilidade é bastante simplificada, o que é fundamental para reduzir custos. Se pudermos escrever código de alto desempenho que resolva problemas de ciência de dados, a integração desse código com o Python será uma vantagem significativa.
Ao trabalhar na interseção da ciência de dados e análise de malwarenão é necessária apenas uma execução rápida, mas também o uso eficiente de recursos compartilhados, novamente, para dimensionamento. O dimensionamento é um dos principais problemas do big data, como lidar com milhões de executáveis com eficiência em várias plataformas. Obter bom desempenho em processadores modernos requer paralelismo, geralmente implementado usando multithreading; mas também é necessário melhorar a eficiência da execução do código e do consumo de memória. Ao resolver esses problemas, pode ser difícil equilibrar os recursos do sistema local e é ainda mais difícil implementar corretamente sistemas multithread. A essência do C e C ++ é que a segurança do thread não é fornecida. Sim, existem bibliotecas externas específicas da plataforma, mas garantir a segurança do encadeamento é obviamente um dever do desenvolvedor.
A análise de malware é inerentemente perigosa. O software malicioso geralmente manipula as estruturas de dados no formato de arquivo de maneiras não intencionais, prejudicando os utilitários de análise. Uma armadilha relativamente comum que nos espera em Python é a falta de boa segurança de tipo. O Python, que aceita valores generosamente
Nonequando esperado em seu lugar bytearray, pode entrar em um caos completo, o que só pode ser evitado preenchendo o código com verificações None. Tais premissas de "digitação de pato" geralmente levam a falhas.
Mas há Rust. O Rust está posicionado de várias maneiras como a solução ideal para todos os problemas em potencial descritos acima: o tempo de execução e o consumo de memória são comparáveis aos de C e C ++, e é fornecida uma ampla segurança de tipo. O Rust também oferece comodidades adicionais, como fortes garantias de segurança de memória e sem sobrecarga de tempo de execução. Como não existe essa sobrecarga, facilita a integração do código Rust com o código de outras linguagens, em particular o Python. Neste artigo, faremos um rápido tour pelo Rust para ver se vale o hype associado a ele.
Exemplo de aplicativo para ciência de dados
A ciência de dados é uma área de assunto muito ampla, com muitos aspectos aplicados, e é impossível discutir todos eles em um artigo. Uma tarefa simples para a ciência de dados é calcular a entropia informacional para sequências de bytes. Uma fórmula geral para calcular a entropia em bits é fornecida na Wikipedia :
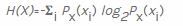
Para calcular a entropia para uma variável aleatória
X, primeiro contamos quantas vezes cada valor de byte possível ocorre 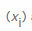 e depois dividimos esse número pelo número total de elementos encontrados para calcular a probabilidade de encontrar um valor específico
e depois dividimos esse número pelo número total de elementos encontrados para calcular a probabilidade de encontrar um valor específico 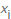 , respectivamente
, respectivamente 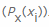 . Em seguida, contamos o valor negativo da soma ponderada das probabilidades de um determinado valor xi ocorrer , bem como as chamadas informações próprias
. Em seguida, contamos o valor negativo da soma ponderada das probabilidades de um determinado valor xi ocorrer , bem como as chamadas informações próprias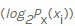 . Como estamos calculando a entropia em bits, ela é usada aqui
. Como estamos calculando a entropia em bits, ela é usada aqui 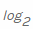 (observe a raiz 2 para bits).
(observe a raiz 2 para bits).
Vamos dar uma chance ao Rust e ver como ele lida com a computação de entropia versus o Python puro, bem como algumas das bibliotecas populares do Python mencionadas acima. Essa é uma estimativa simplificada do desempenho potencial da ciência de dados da Rust; esse experimento não é uma crítica ao Python ou às excelentes bibliotecas que ele contém. Nesses exemplos, geraremos nossa própria biblioteca C a partir do código Rust que podemos importar do Python. Todos os testes foram executados no Ubuntu 18.04.
Pure Python
Vamos começar com uma simples função Python pura (c
entropy.py) para calcular a entropia bytearray, usando apenas o módulo matemático da biblioteca padrão. Essa função não é otimizada, portanto, tomemos como ponto de partida para modificações e medições de desempenho.
import math
def compute_entropy_pure_python(data):
"""Compute entropy on bytearray `data`."""
counts = [0] * 256
entropy = 0.0
length = len(data)
for byte in data:
counts[byte] += 1
for count in counts:
if count != 0:
probability = float(count) / length
entropy -= probability * math.log(probability, 2)
return entropy
Python com NumPy e SciPy
Sem surpresa, o SciPy fornece uma função para calcular a entropia. Mas primeiro, usaremos uma função
unique()do NumPy para calcular as frequências de bytes. Comparar o desempenho da função de entropia SciPy com outras implementações é um pouco injusto, pois a implementação SciPy tem funcionalidade adicional para calcular a entropia relativa (distância Kullback-Leibler). Novamente, faremos um test drive (espero que não seja muito lento) para ver qual será o desempenho das bibliotecas Rust compiladas importadas do Python. Manteremos a implementação SciPy incluída em nosso script entropy.py.
import numpy as np
from scipy.stats import entropy as scipy_entropy
def compute_entropy_scipy_numpy(data):
""" bytearray `data` SciPy NumPy."""
counts = np.bincount(bytearray(data), minlength=256)
return scipy_entropy(counts, base=2)Python com Ferrugem
Em seguida, exploraremos nossa implementação Rust um pouco mais, em comparação com implementações anteriores, por uma questão de ser sólida e sólida. Vamos começar com o pacote de biblioteca padrão gerado com o Cargo. As seções a seguir mostram como modificamos o pacote Rust.
cargo new --lib rust_entropy
Cargo.tomlComeçamos com um arquivo de manifesto obrigatório
Cargo.tomlque define o pacote Cargo e especifica um nome de biblioteca rust_entropy_lib. Usamos o contêiner público cpython (v0.4.1) disponível em crates.io, no Rust Package Registry. Neste artigo, estamos usando o Rust v1.42.0, a versão estável mais recente disponível no momento da redação deste documento.
[package] name = "rust-entropy"
version = "0.1.0"
authors = ["Nobody <nobody@nowhere.com>"] edition = "2018"
[lib] name = "rust_entropy_lib"
crate-type = ["dylib"]
[dependencies.cpython] version = "0.4.1"
features = ["extension-module"]lib.rs
A implementação da biblioteca Rust é bastante direta. Como em nossa implementação pura do Python, inicializamos a matriz de contagens para todos os valores de bytes possíveis e iteramos sobre os dados para preencher as contagens. Para concluir a operação, calcule e retorne a soma negativa de probabilidades multiplicada por
probabilidades.
use cpython::{py_fn, py_module_initializer, PyResult, Python};
///
fn compute_entropy_pure_rust(data: &[u8]) -> f64 {
let mut counts = [0; 256];
let mut entropy = 0_f64;
let length = data.len() as f64;
// collect byte counts
for &byte in data.iter() {
counts[usize::from(byte)] += 1;
}
//
for &count in counts.iter() {
if count != 0 {
let probability = f64::from(count) / length;
entropy -= probability * probability.log2();
}
}
entropy
}
Tudo o que resta
lib.rsé um mecanismo para chamar uma função Rust pura do Python. Incluímos lib.rsuma (compute_entropy_cpython())função ajustada ao CPython para chamar nossa função Rust "pura" (compute_entropy_pure_rust()). Ao fazer isso, nos beneficiamos apenas da manutenção de uma única implementação pura do Rust e do fornecimento de um wrapper compatível com o CPython.
/// Rust CPython
fn compute_entropy_cpython(_: Python, data: &[u8]) -> PyResult<f64> {
let _gil = Python::acquire_gil();
let entropy = compute_entropy_pure_rust(data);
Ok(entropy)
}
// Python Rust CPython
py_module_initializer!(
librust_entropy_lib,
initlibrust_entropy_lib,
PyInit_rust_entropy_lib,
|py, m | {
m.add(py, "__doc__", "Entropy module implemented in Rust")?;
m.add(
py,
"compute_entropy_cpython",
py_fn!(py, compute_entropy_cpython(data: &[u8])
)
)?;
Ok(())
}
);Chamando o código de ferrugem do Python
Finalmente, chamamos a implementação Rust do Python (novamente, de
entropy.py). Para fazer isso, primeiro importamos nossa própria biblioteca de sistema dinâmico compilada a partir do Rust. Em seguida, simplesmente chamamos a função de biblioteca fornecida que especificamos anteriormente ao inicializar o módulo Python usando uma macro py_module_initializer!em nosso código Rust. Nesta fase, temos apenas um módulo Python ( entropy.py), que inclui funções para chamar todas as implementações do cálculo da entropia.
import rust_entropy_lib
def compute_entropy_rust_from_python(data):
"" bytearray `data` Rust."""
return rust_entropy_lib.compute_entropy_cpython(data)Estamos construindo o pacote da biblioteca Rust acima no Ubuntu 18.04 usando o Cargo. (Esse link pode ser útil para usuários do OS X).
cargo build --releaseQuando terminamos a montagem, renomeamos a biblioteca resultante e a copiamos para o diretório em que nossos módulos Python estão localizados, para que possa ser importada dos scripts. A biblioteca criada com o Cargo é nomeada
librust_entropy_lib.so, mas você precisa renomeá-la para rust_entropy_lib.sopoder importar com êxito para esses testes.
Verificação de desempenho: resultados
Medimos o desempenho de cada implementação de função usando pontos de interrupção pytest, calculando a entropia para mais de 1 milhão de bytes aleatórios. Todas as implementações são mostradas nos mesmos dados. Os benchmarks (também incluídos em entropy.py) são mostrados abaixo.
# ### ###
# w/ NumPy
NUM = 1000000
VAL = np.random.randint(0, 256, size=(NUM, ), dtype=np.uint8)
def test_pure_python(benchmark):
""" Python."""
benchmark(compute_entropy_pure_python, VAL)
def test_python_scipy_numpy(benchmark):
""" Python SciPy."""
benchmark(compute_entropy_scipy_numpy, VAL)
def test_rust(benchmark):
""" Rust, Python."""
benchmark(compute_entropy_rust_from_python, VAL)Por fim, criamos scripts de driver simples separados para cada método necessário para calcular a entropia. A seguir, há um script de driver representativo para testar a implementação pura do Python. O arquivo contém
testdata.bin1.000.000 de bytes aleatórios usados para testar todos os métodos. Cada método repete o cálculo 100 vezes para facilitar a captura de dados de uso da memória.
import entropy
with open('testdata.bin', 'rb') as f:
DATA = f.read()
for _ in range(100):
entropy.compute_entropy_pure_python(DATA)As implementações para SciPy / NumPy e Rust mostraram bom desempenho, superando facilmente uma implementação Python pura não otimizada por mais de 100 vezes. A versão Rust teve um desempenho apenas um pouco melhor que a versão SciPy / NumPy, mas os resultados confirmaram nossas expectativas: o Python puro é muito mais lento que as linguagens compiladas, e as extensões escritas no Rust podem competir com sucesso com seus colegas C (superando-os mesmo em tais microteste).
Existem também outros métodos para melhorar a produtividade. Nós poderíamos usar módulos
ctypesou cffi. Você pode adicionar dicas de tipo e usar o Cython para gerar uma biblioteca que você pode importar do Python. Todas essas opções exigem que sejam consideradas as compensações específicas da solução.

Também medimos o uso de memória para cada implementação de recurso usando o aplicativo GNU
time(para não confundir com o comando shell interno time). Em particular, medimos o tamanho máximo do conjunto de residentes.
Enquanto nas implementações puras de Python e Rust os tamanhos máximos para essa parte são bastante semelhantes, a implementação SciPy / NumPy consome significativamente mais memória para esse benchmark. Provavelmente, isso se deve a recursos adicionais carregados na memória durante a importação. Seja como for, chamar o código Rust do Python não parece introduzir uma sobrecarga significativa na memória.

Resultado
Estamos extremamente impressionados com o desempenho que obtemos ao chamar Rust do Python. Em nossa avaliação francamente breve, a implementação do Rust foi capaz de competir no desempenho com a implementação base C dos pacotes SciPy e NumPy. A ferrugem parece ser ótima para o processamento eficiente em larga escala.
A ferrugem mostrou não apenas excelentes tempos de execução; Note-se que a sobrecarga de memória nesses testes também foi mínima. Essas características de tempo de execução e uso de memória parecem ideais para fins de escalabilidade. O desempenho das implementações SciPy e NumPy C FFI é definitivamente comparável, mas com o Rust obtemos vantagens adicionais que C e C ++ não nos oferecem. As garantias de segurança de memória e segurança de threads são um benefício muito atraente.
Enquanto C fornece um tempo de execução comparável ao Rust, o próprio C não fornece segurança de thread. Existem bibliotecas externas que fornecem essa funcionalidade para C, mas é de responsabilidade do desenvolvedor garantir que elas sejam usadas corretamente. O Rust monitora problemas de segurança de encadeamento, como corridas, em tempo de compilação - graças ao seu modelo de propriedade - e a biblioteca padrão fornece um conjunto de mecanismos de simultaneidade, como tubos, bloqueios e ponteiros inteligentes contados por referência.
Não estamos defendendo a portabilidade do SciPy ou do NumPy para o Rust, pois essas bibliotecas Python já estão bem otimizadas e suportadas por comunidades interessantes de desenvolvedores. Por outro lado, é altamente recomendável transportar código de Python puro para Rust que não seja fornecido em bibliotecas de alto desempenho. No contexto de aplicativos de ciência de dados usados para análise de segurança, o Rust parece ser uma alternativa competitiva ao Python, devido às suas garantias de velocidade e segurança.