
Como posso economizar em custos de nuvem ao trabalhar com o Kubernetes? Não existe uma solução certa, mas este artigo fornece várias ferramentas para ajudá-lo a gerenciar recursos com mais eficiência e reduzir os custos de computação em nuvem.
Eu escrevi este artigo com o Kubernetes para AWS em mente, mas ele se aplicará (quase) da mesma maneira para outros provedores de nuvem. Suponho que o (s) seu (s) cluster (s) já tenha (s) o dimensionamento automático ( cluster-autoscaler ) configurado . A remoção de recursos e a redução de escala de sua implantação economizarão apenas se você também reduzir sua frota de nós de trabalho (instâncias do EC2).
Este artigo abordará:
- limpando recursos não utilizados ( kube-janitor )
- redução de escala fora do horário comercial ( kube-downscaler )
- usando escala automática horizontal (HPA),
- reduzindo a reserva de recursos em excesso ( kube-resource-report , VPA)
- usando instâncias Spot
Limpar recursos não utilizados
Trabalhar em um ambiente de ritmo acelerado é ótimo. Queremos que as organizações técnicas acelerem . Entrega mais rápida de software também significa mais implantações de relações públicas, ambientes de visualização, protótipos e soluções de análise. Tudo implantável no Kubernetes. Quem tem tempo para limpar manualmente as implantações de teste? É fácil esquecer a exclusão do experimento há uma semana. A conta da nuvem eventualmente aumentará devido ao fato de termos esquecido de fechar:

(Henning Jacobs:
Vida:
(citado) Corey Quinn:
Mito: Sua conta da AWS é uma função do número de seus usuários.
Fato: Sua conta da AWS é uma função do número de seus engenheiros.
Ivan Kurnosov (em resposta):
Fato real: Sua conta da AWS é uma função, dependendo do número de coisas que você esqueceu de desativar / excluir.)
O Kubernetes Janitor (kube-janitor) ajuda a limpar seu cluster. A configuração do zelador é flexível para uso global e local:
- Regras gerais para todo o cluster podem definir o tempo de vida máximo (TTL) para implantações de PR / teste.
- Recursos individuais podem ser anotados usando janitor / ttl, por exemplo, para remover automaticamente o pico / protótipo após 7 dias.
Regras gerais são definidas no arquivo YAML. Seu caminho é passado através de um parâmetro
--rules-filepara kube-janitor. Aqui está um exemplo de regra para excluir todos os namespaces -pr-em um nome em dois dias:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dO exemplo a seguir regula o uso do rótulo do aplicativo nos pods Deployment e StatefulSet para todos os novos Deployments / StatefulSet em 2020, mas ao mesmo tempo permite a execução de testes sem esse rótulo por uma semana:
- id: require-application-label
# deployments statefulsets "application"
resources:
- deployments
- statefulsets
# . http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dExecutando uma demonstração por tempo limitado por 30 minutos no cluster em que o kube-janitor está executando:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mOutra fonte de custos crescentes são os volumes persistentes (AWS EBS). Quando você exclui o Kubernetes StatefulSet, seus volumes permanentes (PVC - PersistentVolumeClaim) não são excluídos. Os volumes não utilizados do EBS podem facilmente levar a custos na ordem de centenas de dólares por mês. O Kubernetes Janitor possui um recurso para limpar PVCs não utilizados. Por exemplo, esta regra removerá todos os PVCs que não são montados pelo pod e não são referenciados por um StatefulSet ou CronJob:
# PVC, StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hO Kubernetes Janitor pode ajudar a manter seu cluster limpo e evitar os custos crescentes da computação em nuvem. Para obter instruções de implementação e configuração, siga o README do kube-janitor .
Menos zoom fora do escritório
Normalmente, os sistemas de teste e intermediários funcionam apenas durante o horário de trabalho. Alguns aplicativos de produção, como ferramentas administrativas / administrativas, também exigem disponibilidade limitada e podem ser desativados à noite.
O Kubernetes Downscaler (kube-downscaler) permite que usuários e operadores reduzam o tamanho do sistema após horas. Implantações e StatefulSets podem ser redimensionados para zero réplicas. CronJobs pode ser suspenso. O Kubernetes Downscaler é configurável para todo o cluster, um ou mais namespaces ou recursos individuais. Você pode definir "tempo ocioso" ou vice-versa "tempo de execução". Por exemplo, para minimizar a escala durante a noite e nos fins de semana:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
#
- --exclude-namespaces=kube-system,infra
# kube-downscaler, Postgres Operator,
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeAqui está um gráfico para dimensionar os nós dos trabalhadores de cluster no fim de semana:

A redução de ~ 13 a 4 nós dos trabalhadores certamente faz uma diferença considerável na fatura da AWS.
Mas e se eu precisar trabalhar durante o "tempo de inatividade" do cluster? Certas implementações podem ser permanentemente excluídas do dimensionamento adicionando a anotação downscaler / exclude: true. As implantações podem ser excluídas temporariamente usando a anotação de downscaler / excluir até com um carimbo de hora absoluto no formato AAAA-MM-DD HH: MM (UTC). Se necessário, o cluster inteiro pode ser redimensionado implementando um pod anotado
downscaler/force-uptime, por exemplo, executando o nginx dummy:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h #
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueConsulte o kube-downscaler README para obter instruções de implementação e opções adicionais.
Usar escalonamento automático horizontal
Muitos aplicativos / serviços lidam com um esquema de carregamento dinâmico: às vezes, seus módulos estão ociosos e, às vezes, estão funcionando com capacidade total. Não é econômico operar com uma frota constante de lareiras para lidar com o pico máximo de carga. O Kubernetes suporta a escala automática horizontal por meio do recurso HorizontalPodAutoscaler (HPA). O uso da CPU geralmente é uma boa métrica para dimensionar:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationO Zalando criou um componente para conectar facilmente métricas personalizadas para dimensionamento: O Kube Metrics Adapter (kube-metrics-adapter) é um adaptador universal de métricas para o Kubernetes que pode coletar e manter métricas personalizadas e externas para dimensionamento horizontal da lareira. Ele suporta o dimensionamento com base nas métricas do Prometheus, filas SQS e outras personalizações. Por exemplo, para dimensionar a implementação de uma métrica customizada representada pelo próprio aplicativo como JSON em / metrics, use:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueConfigurar a escala automática horizontal com HPA deve ser uma das ações padrão para melhorar a eficiência dos serviços sem estado. O Spotify tem uma apresentação com suas experiências e práticas recomendadas para HPA: Escale suas implantações, não sua carteira .
Reserva Redundante Reduzida de Recursos
As cargas de trabalho do Kubernetes determinam suas necessidades de CPU / memória através de "solicitações de recursos". Os recursos da CPU são medidos em núcleos virtuais ou mais frequentemente em "milicores", por exemplo, 500m implica 50% de vCPU. Os recursos de memória são medidos em bytes e sufixos comuns podem ser usados, por exemplo, 500Mi, o que significa 500 megabytes. As solicitações de recursos "bloqueiam" a capacidade nos nós de trabalho, ou seja, um módulo com uma solicitação de CPU de 1000m em um nó com 4 vCPUs deixará apenas 3 vCPUs disponíveis para outros módulos. [1]
Folga (excesso de reserva)É a diferença entre os recursos solicitados e o uso real. Por exemplo, um pod que solicita 2 GiB de memória, mas usa apenas 200 MiB, possui ~ 1,8 GiB de memória "em excesso". Excesso custa dinheiro. Pode-se estimar aproximadamente que 1 GiB de excesso de memória custa ~ US $ 10 por mês. [2] O
Kubernetes Resource Report (kube-resource-report) exibe reservas em excesso e pode ajudá-lo a determinar possíveis economias:

Kubernetes Resource Reportmostra excesso agregado por aplicativo e equipe. Isso permite encontrar locais onde as demandas de recursos podem ser reduzidas. O relatório HTML gerado fornece apenas uma captura instantânea do uso de recursos. Você deve observar o uso da CPU / memória ao longo do tempo para determinar solicitações de recursos adequadas. Aqui está o diagrama da Grafana para um serviço "típico" com uma grande carga de CPU: todos os pods usam significativamente menos de 3 núcleos de CPU solicitados:
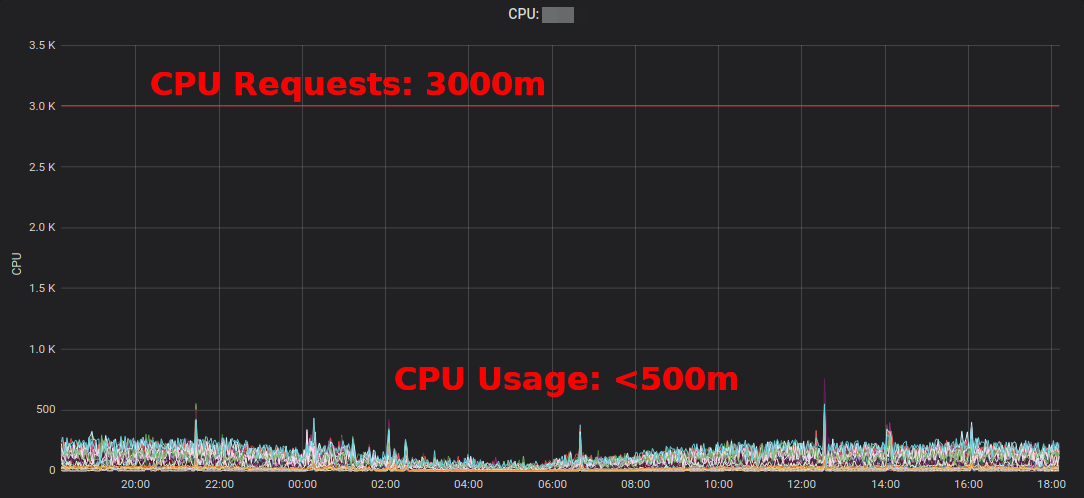
Reduzir a solicitação de CPU de 3000m para ~ 400m libera recursos para outras cargas de trabalho e permite reduzir o cluster.
“A utilização média da CPU das instâncias do EC2 geralmente varia na faixa de um único por cento”, escreve Corey Quinn . Considerando que para EC2, estimar o tamanho correto pode ser uma má decisãoAlterar algumas solicitações de recursos do Kubernetes em um arquivo YAML é fácil e pode trazer grandes economias.
Mas realmente queremos que as pessoas alterem valores nos arquivos YAML? Não, carros podem fazer muito melhor! O VPA ( Vertical Pod Autoscaler ) da Kubernetes faz exatamente isso: adapta solicitações de recursos e restrições para se adequar à carga de trabalho. Aqui está um exemplo de um gráfico de solicitações de CPU do Prometheus (linha azul fina) adaptadas pelo VPA ao longo do tempo:

Zalando usa o VPA em todos os seus clusters para componentes de infraestrutura. Aplicativos não críticos também podem usar o VPA.
Cachinhos Douradosby Fairwind é uma ferramenta que cria um VPA para cada implantação em um espaço para nome e exibe a recomendação do VPA em seu painel. Ele pode ajudar os desenvolvedores a estabelecer as solicitações corretas de processador / memória para seus aplicativos:

escrevi um pequeno post sobre o VPA em 2019 e o VPA foi discutido recentemente na comunidade de usuários finais do CNCF .
Usando instâncias spot do EC2
Por último, mas não menos importante, os custos do AWS EC2 podem ser reduzidos usando instâncias Spot como nós de trabalho do Kubernetes [3] . As instâncias spot estão disponíveis com até 90% de desconto no preço sob demanda. A execução do Kubernetes no EC2 Spot é uma boa combinação: você precisa especificar vários tipos de instâncias diferentes para obter maior disponibilidade, o que significa que você pode obter um nó maior pelo mesmo preço ou preço mais baixo e que a capacidade aumentada pode ser consumida pelas cargas de trabalho do contêiner do Kubernetes.
Como executo o Kubernetes no EC2 Spot? Existem várias opções: use um serviço de terceiros, como o SpotInst (agora chamado de "Spot", não me pergunte o porquê), ou apenas adicione o Spot AutoScalingGroup (ASG) ao seu cluster. Por exemplo, aqui está um snippet do CloudFormation para um Spot ASG “otimizado para capacidade” com vários tipos de instância:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"Algumas notas sobre o uso do Spot com o Kubernetes:
- Você precisa lidar com conclusões Spot, por exemplo, drenando um nó em uma parada de instância
- Zalando usa o fork do dimensionamento automático de cluster oficial com prioridades de pool de nós
- Nós spot podem ser forçados a aceitar "registros" de cargas de trabalho para execução no Spot
Resumo
Espero que você ache algumas das ferramentas apresentadas aqui úteis para reduzir sua conta de computação em nuvem. Você também pode encontrar a maior parte do conteúdo nas palestras e slides do DevOps Gathering 2019 no YouTube .
Quais são suas práticas recomendadas para economizar custos na nuvem no Kubernetes? Entre em contato no Twitter (@try_except_) .
[1] De fato, menos de 3 vCPUs permanecerão utilizáveis, pois a largura de banda do host é reduzida pelos recursos reservados do sistema. O Kubernetes distingue entre a capacidade do nó físico e os recursos "alocados" ( Nó Alocável ).
[2] Exemplo de cálculo: uma cópia de m5.large com 8 GiB de memória é de ~ 84 USD por mês (eu-central-1, On Demand), ou seja, O bloqueio de 1/8 nós é aproximadamente ~ $ 10 por mês.
[3] Existem muitas outras maneiras de reduzir sua conta do EC2, como instâncias reservadas, plano de poupança etc. - Não abordarei esses tópicos aqui, mas você definitivamente deve conferir!
Saiba mais sobre o curso.