Em minha palestra, lembrei da evolução do Python na empresa: desde os primeiros serviços empacotados em pacotes deb e lançados no bare metal, até um repositório mono complexo com seu próprio sistema de compilação e nuvem. Mais na história serão Django, Flask, Tornado, Docker, PyCharm, IPv6 e outras coisas que encontramos ao longo dos anos.
- Deixe-me dizer-lhe sobre mim. Eu vim para a Yandex em 2008. No começo, eu fazia serviços de conteúdo, em particular o Yandex.Afisha. Eu escrevi lá em Python, reescrevemos o serviço do Perl e de outras tecnologias divertidas.
Então mudei para serviços internos. O departamento de serviços internos foi gradualmente transformado no gerenciamento de interfaces e serviços de pesquisa para organizações. Muito tempo se passou, de um desenvolvedor simples que cresci até o chefe do desenvolvimento python da nossa divisão, cerca de 30 pessoas.
Um ponto importante: a empresa é muito grande e não posso falar por todos os Yandex. Claro, eu me comunico com colegas de outros departamentos, sei como eles vivem. Mas basicamente só posso falar sobre nosso departamento, sobre nossos produtos. Meu relatório se concentrará nisso. Às vezes, vou lhe dizer que em outro lugar do Yandex eles fazem isso e aquilo. Mas não será sempre.
O Python é usado em muitos lugares da empresa: qualquer tecnologia, qualquer pilha de tecnologia, qualquer idioma. Tudo o que vem à mente em algum lugar da empresa está na forma de um experimento ou em outra coisa. E em qualquer serviço Yandex Yandex, definitivamente haverá Python em um ou outro componente.
Tudo o que direi é minha interpretação dos eventos. Não pretendo ser absolutamente objetivo. Tudo isso, inclusive através das minhas mãos, era emocionalmente colorido. Toda a minha experiência é tão pessoal.

Como o relatório será estruturado? Para facilitar a percepção de informações, e para mim contar, decidi dividir toda a evolução de 2007 para o momento atual em várias épocas. O relatório será estritamente estruturado por essas épocas. A era significa uma mudança fundamental na infraestrutura ou na abordagem do desenvolvimento. Se nossa infraestrutura de ferro muda e, ao mesmo tempo, mudamos a maneira como desenvolvemos serviços, que ferramentas usamos, esta é uma era. É claro que eu tive que me ajustar um pouco. É claro que tudo não aconteceu de forma síncrona e houve lacunas entre essas mudanças, mas tentei ajustar tudo sob uma linha do tempo, apenas para torná-la mais compacta.
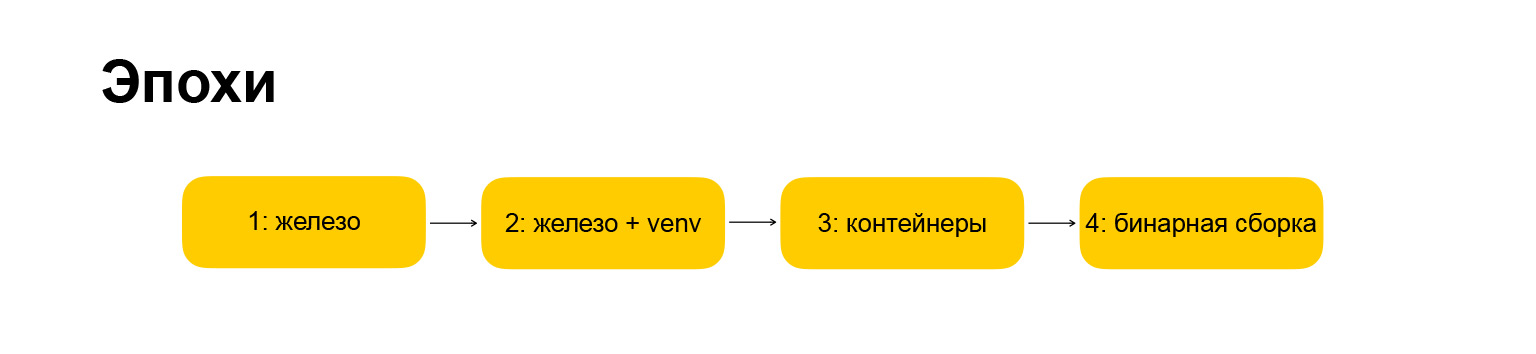
Em que época tínhamos? Aqui também tudo é protegido por direitos autorais, todos os nomes são meus. A primeira era é chamada de "hardware", foi assim que começamos quando cheguei à empresa. Porque tudo mudou um pouco. A era tornou-se "ferro + venv". Além disso, revelarei o que está oculto por trás desses nomes. Primeiro, quero lhe dar um guia sobre o que vou lhe dizer.
A próxima era são os “contêineres”, tudo fica mais ou menos claro aqui. A era em que estamos nos movendo no momento é "montagem binária", também vou falar sobre isso.

Como será estruturada cada época? Isso também é importante, porque eu queria fazer uma narração rítmica, para que cada seção fosse estritamente estruturada e mais fácil de entender. A era é descrita pela infraestrutura, pelas estruturas que usamos, como trabalhamos com dependências, que tipo de ambiente de desenvolvimento temos e pelos prós e contras dessa ou daquela abordagem.
(Pausa técnica.) Eu contei a introdução, como o relatório será estruturado, vamos para a história em si.
Idade 1: ferro
O primeiro serviço que comecei a fazer quando entrei na empresa foi chamado "Where Everybody Goes". Foi o satélite Afisha, o primeiro grande serviço no Django.
Grisha Bakunovbobukposso dizer por que ele decidiu transferir o Django para o Yandex - em geral, aconteceu. Começamos a prestar serviços no Django.
Eu vim e eles me disseram: vamos aonde todo mundo vai. Então já havia algum tipo de base. Liguei-me e consideramos uma espécie de experimento - funcionará ou não. O experimento acabou sendo bem-sucedido. Todos concordaram que é possível criar serviços da Web no Yandex em Python e Django. Bem! Nossa infraestrutura está pronta para isso, as pessoas estão prontas, o mundo também está pronto. Vamos distribuir ainda mais o Python e o Django por toda a empresa. Começamos a fazer isso. Reescreva Yandex.Afisha, tempo. Então - o programa de TV. Então tudo correu como um nevoeiro, eles começaram a reescrever tudo.
Naquela época, a infraestrutura Yandex parecia que todo o back-end estava escrito principalmente nos profissionais. Obviamente, a mudança para o Python acelerou muito o desenvolvimento em muitos lugares, e isso foi bem recebido pela empresa e pela gerência. Vamos agora falar sobre a infraestrutura - onde esses serviços funcionavam, o que eles estavam usando e tudo mais.

Estes eram carros de ferro, daí o nome desta época. O que são máquinas de ferro? Eles são apenas servidores no data center. Existem muitos servidores, todos eles combinados em um cluster de, digamos, 15 máquinas. Havia 30, depois 50, 100. E tudo isso no Debian ou Ubuntu. Naquela época, havíamos migrado do Debian para o Ubuntu. Lançamos todos os aplicativos por meio de um processo init padrão. Tudo era padrão, como faziam naquela época. Para nossos aplicativos se comunicarem no servidor da Web, usamos o protocolo FastCGI e a biblioteca flup. Se você usa o Python há muito tempo, provavelmente já ouviu falar dele. Mas agora, tenho certeza de que você não o usa, porque está desatualizado e era uma coisa muito estranha, funcionou muito lentamente.
Naquele momento, obviamente, não havia um terceiro Python, escrevemos no Python 2.3. Em seguida, eles migraram para o 2.4. Tempos selvagens. Eu nem quero pensar neles, porque a língua, as comunidades e o ecossistema pareciam completamente diferentes, embora também fosse legal, e muitos foram atraídos por isso na época. Pessoalmente, ele me mergulhou no mundo do Python - que, apesar das peculiaridades e peculiaridades, mesmo assim ficou claro que o Python é uma tecnologia promissora, você pode investir seu tempo lá.
Um ponto importante: então não usamos nginx, não usamos Apache, mas usamos um servidor web chamado Lighttpd. Se você trabalha com serviços da Web há muito tempo, provavelmente já ouviu falar sobre isso. Em um ponto, ele era muito popular.

Dos frameworks, nós realmente usamos o Django. Começamos a fazer ótimos serviços no Django. Em algum lugar da empresa estava CherryPy, em algum lugar - Web.py. Você pode ter ouvido falar sobre essas estruturas também. Agora, eles não estão na vanguarda, há muito que são adiados por estruturas mais jovens e mais ousadas. Então eles tinham seu próprio nicho, mas acabaram morrendo mais cedo ou mais tarde, paramos de fazer qualquer coisa com eles. Eles começaram a fazer tudo no Django.
Nesse ponto, o Python se tornou tão difundido na empresa que se espalhou para além do nosso departamento: serviços da Web em Python e Django começaram a ser feitos em todos os lugares da empresa.

Vamos continuar trabalhando com dependências. E aqui está uma coisa que você provavelmente também encontrou se veio trabalhar para uma grande empresa: a corporação já possui uma infraestrutura estabelecida, é preciso se adaptar a ela. O Yandex tinha uma infraestrutura deb, repositórios internos de pacotes deb. Acreditava-se que o desenvolvedor do Yandex sabia compilar este pacote deb. Fomos forçados a integrar esse fluxo, montamos nossos projetos na forma de pacotes deb completos e, em seguida, como um pacote deb, colocamos tudo isso nos servidores de que eu estava falando e os colocamos em clusters na forma de pacotes deb.
Como resultado, todas as dependências e bibliotecas, o mesmo Django, também tivemos que empacotar nos pacotes deb. Para fazer isso, criamos nossa própria infraestrutura, elevamos o repositório interno e aprendemos como fazê-lo. Esta não é uma lição muito original: se você tentou criar um pacote RPM ou deb, então você sabe disso. RPM é um pouco mais simples, deb é mais complicado. Mesmo assim, você não poderá sair da rua e começar a fazê-lo com um clique. Você precisa cavar um pouco.
Nós criamos pacotes de deb há muitos anos depois disso. E parece-me que nem todos que fizeram isso para o trabalho precisam entender o que estava acontecendo sob o capô. Eles simplesmente tiraram um do outro, copiaram espaços em branco, modelos e não cavaram profundamente. Mas aqueles que descobriram o que estava acontecendo no interior tornaram-se colegas muito úteis e muito exigentes: se de repente algo não acontecesse, todos os procuravam por conselhos e pediam nuances e ajuda na depuração. Foi um momento divertido, porque eu estava interessado em descobrir o que havia dentro. Assim, ele ganhou uma popularidade barata entre os colegas.

Além do ecossistema de dependências, também há trabalho com código compartilhado. Já no início, havia um crescimento explosivo no número de projetos, e era necessário trabalhar com código comum, criar bibliotecas comuns e assim por diante. Começamos a criar um código aberto interno. Criamos a funcionalidade geral da autorização, trabalhando com logs, com outras coisas comuns, APIs internas, armazenamentos internos. Fizemos tudo isso na forma de bibliotecas, colocamos no repositório interno. No início, eram repositórios SVN, depois GitHub interno.
E no final eles empacotaram todas essas dependências, todas essas bibliotecas também estão no deb, carregadas em um único repositório. A partir disso, um ambiente de pacote desse tipo foi formado. Se você iniciou um novo projeto, poderá colocar várias bibliotecas lá, obter uma base de funcionalidade e iniciar o projeto imediatamente na infraestrutura Yandex. Foi muito confortável.

Como era nosso servidor típico? Classicamente. Existem dependências do sistema, dependências e aplicativos python. Várias coisas se seguem disso. Antes de tudo, todos os aplicativos executados no mesmo servidor e, portanto, no mesmo cluster devem ter as mesmas dependências. Como se você instalar um sistema de pacotes, sempre haverá uma versão, não poderá haver várias, você deverá sincronizar.
Quando existem poucos projetos, você ainda pode fazê-lo de alguma forma. Quando há muito, tudo se torna muito complicado. Eles são feitos por equipes diferentes, é difícil para eles concordarem. Cada equipe deseja atualizar antecipadamente para alguma biblioteca ou deseja atualizar a estrutura. E todo mundo deveria seguir isso. Com o tempo, isso cria muitos problemas. Isso nos levou a abandonar esse esquema, a avançar para a próxima era. Mas vou falar sobre isso um pouco mais tarde.
Vamos falar sobre o ambiente de desenvolvimento. Mas existe uma compreensão tão expandida do ambiente de desenvolvimento. É assim que você começa a trabalhar, como escreve código, como depura, como trabalha com ele, onde você testa, como executa, onde executa testes e tudo mais.

Quando entrei na empresa, estávamos todos trabalhando em servidores de desenvolvimento remotos. Ou seja, você tem algum tipo de área de trabalho, no Windows ou Linux, não importa. Você acessa um servidor remoto com o Debian correto e o repositório de pacotes correto. E você trabalha, executa vim, Emacs, escreve código, faz depuração.
Isso não é muito conveniente, mas então não conhecíamos outra vida em particular. Aqueles que tiveram sorte, que tinham um desktop ou laptop com Linux, poderiam tentar fazer isso localmente. Mas também não havia instruções especiais, nada. Um pouco de tempo selvagem. Pessoas especiais que na época viviam em Windows e Macs e queriam desenvolver localmente, criaram uma máquina virtual, dentro da qual o Linux. Eles escreveram o código dentro dessa máquina virtual e o lançaram. Mais precisamente, eles escreveram o código no sistema host, executaram o código dentro da máquina virtual e de alguma forma encaminharam o sistema de arquivos para lá, para que tudo fosse sincronizado. Tudo funcionou muito mal, mas de alguma forma sobreviveu.
Quais são os prós e os contras desta época, essa abordagem do desenvolvimento? De fato - desvantagens sólidas:
- Como eu disse, os agrupamentos gerais estavam apertados.
- Todos os projetos no cluster tinham que ter as mesmas dependências.
- . , , Django . , . 15-20 . . , , — . X, . , . - , - , . . , , . .
- O Yandex dependia da infraestrutura do Debian. Nós o apoiamos, construímos pacotes, mantivemos um repositório interno. E isso, é claro, também não é muito bom, nem muito conveniente, nem muito flexível. Você depende de coisas estranhas que não foram feitas para a empresa. O Debian como uma solução de código aberto, como uma distribuição Linux, foi criado para outras tarefas.
Vamos falar um pouco mais sobre o Django. Por que começamos a usá-lo? Eu pensei antes do relatório, sentado em uma cadeira, que, há 11 anos, falei em uma conferência em Kiev com o mesmo tópico "Por que devo usar o Django?" Então eu também gostei. Eu era um desenvolvedor admirado que leu a documentação, fez meu primeiro projeto e parece-lhe que tudo, agora essa ferramenta é universal para tudo e você pode, eu não sei, nem martelar pregos nela.
Mas demorou muito tempo. Eu ainda amo o Django, ainda é muito usado em nosso departamento e em geral na empresa. Por exemplo, mesmo antes do outono de 2018, Alice tinha o Django em seu back-end. Agora ela não está mais lá, mas para começar rapidamente, seus colegas a escolheram. Como algumas das vantagens ainda são válidas - um grande ecossistema, ainda existem muitos especialistas. Existem todas as baterias que você precisa.
E há ampla flexibilidade. Quando você está apenas começando a trabalhar com o Django, parece que isso o restringe, amarra na mão, requer um certo fluxo de trabalho com ele. Mas se você se aprofundar um pouco mais, muitas coisas poderão ser desativadas, alteradas, configuradas. E se você usar isso com habilidade, poderá obter todas as vantagens associadas à estrutura Python mais popular. Você pode ignorar todos os contras. Existem também muitos deles, mas eles podem ser interrompidos de uma maneira ou de outra.
Idade 2: ferro + venv
Terminamos de falar sobre essa época. Até o final de 2011, passamos para a próxima era, "Iron + venv". Você já conhece o hardware, agora precisa contar o que aconteceu, de onde vem o nome venv. Digressão lírica: venv não surgiu porque máquinas virtuais apareceram. Por que entre aspas? Porque começamos a tentar todos os tipos de coisas parecidas com contêineres, como OpenVZ ou LXC. Então eles foram muito mal desenvolvidos, não como agora. Eles realmente não voaram conosco. Ainda vivíamos em clusters comuns, ainda tínhamos que existir junto com outros projetos ombro a ombro nas mesmas máquinas. Estávamos procurando uma solução.

Por exemplo, mudamos de init para upstart systemd e, um pouco mais tarde, obtivemos flexibilidade no lançamento de nossos aplicativos. Abandonamos o FastCGI e começamos a usar a interface WSGI para comunicação com o servidor da Web ou HTTP. Nesse ponto, já estávamos usando Python mais ou menos moderno, o ecossistema já estava muito bem desenvolvido. Mudamos para o nginx como um servidor web, em geral tudo estava bem.

Também começamos a adaptar novas estruturas para nós mesmos. Por exemplo, eles começaram a usar o Tornado. É claro que naquela época o Flask já havia aparecido, depois de 2012 o Flask já estava muito na moda, popular e o Django ameaçou jogar fora o pedestal de estruturas populares em Python. E, claro, começou a usar o aipo. Como quando os projetos crescem, seu número aumenta, eles ficam mais carregados, resolvem mais problemas, processam mais dados, e você precisa de uma estrutura para a execução offline de tarefas em um grande cluster de computação. Claro, começamos a usar o aipo para isso. Mas mais sobre isso mais tarde.

O que mudou drasticamente é como funciona com dependências. Começamos a coletar um ambiente virtual. Naquela época, a comunidade python chegou ao ponto de que é possível não colocar bibliotecas python no sistema, mas criar um ambiente virtual, colocar todas as dependências python necessárias e esse ambiente será completamente independente. Pode haver o maior número possível de ambientes virtuais em uma máquina. Isso é isolamento, um vício muito conveniente. Você ainda usa. E também adaptamos tudo. Como resultado, o que fizemos? Criamos um ambiente virtual e colocamos todas as dependências python lá, empacotamos em um pacote deb e já o rolamos para o servidor.
Como resultado, todos os projetos pararam de interferir entre si, dependendo da dependência geral do sistema, eles poderiam escolher facilmente qual versão da estrutura ou biblioteca usar. É muito conveniente. Também houve alterações no código comum. Como abandonamos parcialmente a infraestrutura Debian e, em particular, paramos de instalar dependências python com pacotes deb, precisávamos de algo onde pudéssemos descarregar todo o nosso código comum e bibliotecas comuns e de onde poderíamos colocá-los.

Link do slide
Naquela época, já havia várias implementações do PyPI, ou seja, um repositório de pacotes python, implementações escritas, em particular, no Django. E nós escolhemos um deles. Chama-se Localshop, aqui está um link. Este repositório ainda está vivo, já existem cerca de mil pacotes internos. Ou seja, entre 2011 e 2012, uma empresa do tamanho de Yandex gerou cerca de mil bibliotecas diferentes, utilitários escritos em Python, que se acredita serem reutilizados em outros projetos. Você pode estimar a escala.
Todas as bibliotecas são publicadas neste repositório interno. E, a partir daí, eles são instalados no Python ou há uma infraestrutura automática especial que os transforma no Debian. É tudo mais ou menos automatizado, conveniente. Paramos de desperdiçar tantos recursos na manutenção da infraestrutura Debian. Mais ou menos funcionou.
E este é um passo qualitativo. Aqui está um diagrama com o que eu estava falando.
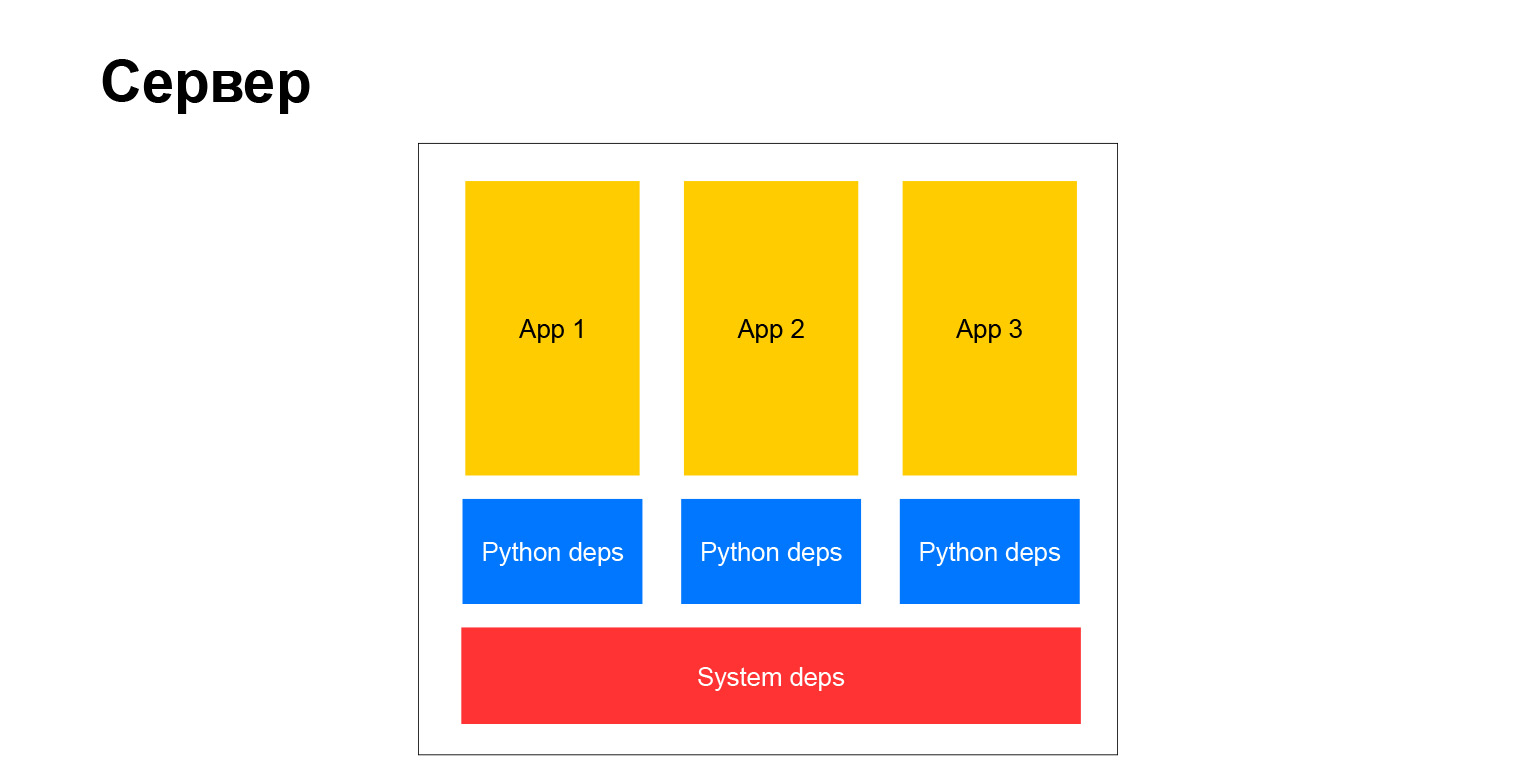
Ou seja, os vícios em python finalmente deixaram de ser os mesmos para todos. Os sistemas ainda permanecem, mas não existem muitos. Por exemplo, um driver de banco de dados, um analisador XML exigia libs binárias do sistema. Em geral, naquela época, não podíamos nos livrar dessas dependências.

O ambiente de desenvolvimento também mudou. Desde o venv, o ambiente virtual tornou-se disponível e funcionou em todos os lugares naquele momento, poderíamos construir nosso projeto em geral em qualquer plataforma local. Isso tornou a vida muito mais fácil. Não havia mais necessidade de se preocupar com o Debian, nenhuma máquina virtual era necessária. Você pode simplesmente pegar qualquer sistema operacional, digitar venv virtual e instalar alguma coisa. E funcionou.
Quais são as vantagens deste esquema? Como vivemos por um longo tempo - talvez um pouco mais de três anos - com essa configuração de parâmetros, ficou mais fácil viver em clusters-hostels. Isso é realmente conveniente. Ou seja, não somos mais dependentes dessas atualizações globais para qualquer Django em toda a empresa. Poderíamos selecionar com mais precisão as versões que melhor se adequam a nós, atualizar dependências críticas com mais frequência se corrigirem vulnerabilidades ou algo mais. E foi uma maneira muito correta, gostamos e nos salvou de tudo.
Mas também havia desvantagens. As dependências do sistema ainda permaneciam comuns. Às vezes disparava, outras atrapalhava. Mais uma vez, irei um pouco além do escopo de nosso departamento e falarei sobre a empresa. Como a empresa é grande, nem todos acompanharam essas épocas conosco. Naquela época, a empresa continuava a usar pacotes deb para trabalhar com dependências python. Vamos falar um pouco mais detalhadamente por que começamos a usar essas ou outras estruturas. Em particular, Tornado.

Precisávamos de uma estrutura assíncrona, agora temos tarefas para ela. O terceiro Python e seu assíncio ainda não existiam, ou estavam em um estado inicial, não era muito confiável usá-los ainda. Portanto, tentamos escolher qual estrutura assíncrona usar. Havia várias opções: Gevent e Twisted. Provavelmente, havia mais deles, mas escolhemos entre eles. O Twisted já foi usado pela empresa - por exemplo, o back-end Yandex.Taxi foi escrito em Twisted. Mas nós olhamos para eles e decidimos que o Twisted não parece pitônico, nem mesmo o PEP-8. E Gevent - existe algum tipo de hack com uma pilha python dentro. Vamos usar o Tornado.
Não nos arrependemos. Ainda usamos o Tornado em alguns serviços - naqueles que ainda não reescrevemos para o terceiro Python. Ao longo dos anos, a estrutura provou que é compacta, confiável e confiável.
E, claro, Aipo. Eu já falei parcialmente sobre isso. Precisávamos de uma estrutura para a execução distribuída de tarefas adiadas. Nós conseguimos.

Foi muito conveniente que o aipo tenha suporte para diferentes corretores. Utilizamos ativamente este b para várias tarefas que tentam encontrar um ou outro corretor correto. Em algum lugar estava Mongo, em algum lugar SQS, em algum lugar Redis. Mas tentamos escolher de acordo com a necessidade e conseguimos.
Apesar do fato de haver muitas reclamações sobre o Aipo, como ele está escrito por dentro, como depurar, que tipo de registro existe, ele funciona bastante. O aipo ainda é usado ativamente em quase todos os projetos do nosso departamento, e até onde eu sei, fora do nosso projeto. Aipo - must-have. Se você precisar adiar a execução de tarefas, todos usarão o aipo. Ou, a princípio, eles não aceitam, tentam pegar outra coisa, mas ainda assim procuram o aipo.
Vamos para a próxima era. Já estamos nos aproximando do presente, mais moderno. Aqui, o nome da época fala por si.
Idade 3: contêineres

Temos uma nuvem compatível com o docker internamente. No interior, não o tempo de execução do docker, mas o desenvolvimento interno. Mas, ao mesmo tempo, as imagens do docker podem ser implantadas lá. Isso nos ajudou muito, porque conseguimos usar todo o ecossistema docker para desenvolvimento e teste. Poderíamos usar todo tipo de brindes e, depois de receber a imagem testada, carregá-la nessa nuvem. Começou lá em cima e funcionou como deveria.
Naquela época, já éramos independentes do SO que estava dentro do contêiner. Você pode escolher qualquer. É claro que não usamos demônios comuns, mas, por exemplo, um supervisor. Posteriormente, todos mudaram para o uWSGI - descobriu-se que o uWSGI não apenas sabe como executar seus aplicativos da web e fornecer uma interface para o servidor da web neles. Também é apenas uma boa coisa genérica para iniciar processos.
Existe, no entanto, uma configuração um pouco estranha, mas, em geral, é conveniente. Nos livramos da essência desnecessária e começamos a fazer tudo através do uWSGI. Também o usamos para se comunicar com o servidor web. As peculiaridades de nossa nuvem são tais que não podemos usar o protocolo uWSGI para se comunicar com o balanceador, que é representado globalmente na nuvem, como um componente. Mas isso não é assustador. Dentro do uWSGI, o servidor HTTP é muito bem implementado, funciona de maneira rápida e confiável.

E as estruturas? A estrutura do Falcon apareceu e reescrevemos a mesma Alice com o Django no Falcon, porque havia um certo número de APIs - era necessário que trabalhassem rapidamente, mas ao mesmo tempo não eram muito complicadas.
O Django em algum momento se tornou um pouco redundante e, a fim de aumentar a velocidade e livrar-se de uma dependência tão grande, uma grande biblioteca, decidimos reescrevê-lo no Falcon.
E, claro, assíncio. Começamos a escrever novos serviços no terceiro Python e reescrever os antigos no terceiro Python. Somente em nosso departamento, existem agora cerca de 30 serviços escritos em Python. São 30 produtos completos, com back-end, front-end e sua infraestrutura. O processador de dados fornece serviços para consumidores internos e externos.
Mas a empresa, como você sabe, possui milhares de serviços Python, e eles são diferentes. Eles estão em estruturas diferentes, em Python diferente, mais antigas e mais recentes. Agora a empresa usa quase todas as estruturas modernas que você conhece. Django, Flask, Falcon, algo mais, assíncrono - Tornado, Torcido, assíncrono. Tudo é usado e benéfico.
Vamos voltar à estrutura da época - como começamos a trabalhar com dependências.

Tudo é simples aqui. Agora não podemos usar o ambiente virtual. Não precisamos de pacotes deb. No momento da criação da imagem, simplesmente instalamos tudo o que precisamos com o pip. Está completamente isolado. Nós não incomodamos ninguém. E muito conveniente. Qualquer dependência do sistema, você pode escolher qualquer imagem base do Debian, Ubuntu, qualquer que seja. Nós gostamos. Plena liberdade.
Mas, de fato, a liberdade completa, como você sabe, tem um segundo lado. Quando você tem uma empresa grande, e mais ainda quando deseja promover métodos e métodos comuns de desenvolvimento, métodos de teste e abordagens de documentação - neste momento, você se depara com o fato de que esse zoológico, por um lado, ajuda em algum lugar. Por outro lado, pelo contrário, complica. Ele não pode injetar facilmente, por exemplo, alguma biblioteca em todos os serviços, porque os serviços são diferentes. Eles têm versões diferentes de Python, Django ou alguma outra estrutura. Isso complica as coisas. Mas, no final, um servidor típico começou a se parecer com isso.
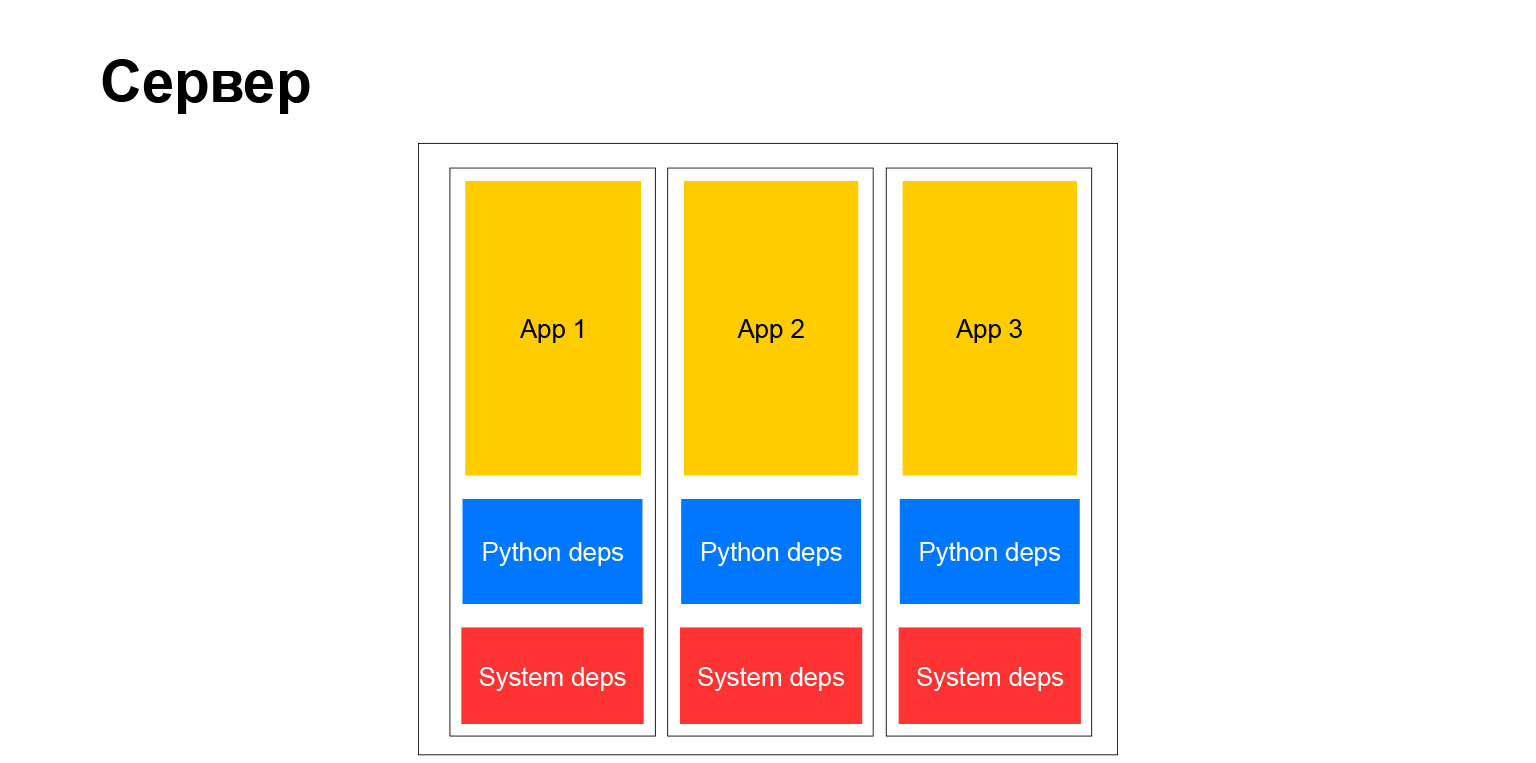
Sim, este é um servidor. Temos contêineres completamente independentes. Cada um deles tem seu próprio ambiente de sistema, e nossos aplicativos funcionam. Muito confortavelmente. Mas como eu disse, há desvantagens.
Vamos voltar à janela de encaixe por um momento. Começamos a usar o docker para desenvolvimento, isso nos ajudou muito.

O Docker está disponível para todas as plataformas. Você pode testar, usar o docker-compondo, fazer um enxame do docker e tentar emular seu ambiente de produção em pequenos clusters para testar algo. Talvez teste de carga. Começamos a usar isso ativamente.
O Docker também está muito bem integrado a todos os tipos de ambientes de desenvolvimento. Por exemplo, estou desenvolvendo no PyCharm e na maioria dos meus colegas também. Há suporte interno para o docker, com seus prós e contras, mas, em geral, tudo funciona.
Tornou-se muito conveniente, demos um passo qualitativo e é nesta fase que estamos agora. É conveniente desenvolver usando a janela de encaixe, embora nossa nuvem de destino, onde implantaremos nossos aplicativos, não seja um Docker Runtime completo, tenha algumas limitações. Mas isso ainda não nos impede de usar o Docker Engine localmente e em tarefas relacionadas.
Vamos resumir esta época. Prós - isolamento completo, uma cadeia de ferramentas conveniente para desenvolvimento e, como eu disse, suporte a IDE.
Há também desvantagens. O Docker está em toda parte, mas se não for Linux, funciona um pouco estranho. Desenvolvedores Yandex que possuem uma janela de encaixe para instalação no MacBook. E há recursos, por exemplo, o IPv6 funciona estranhamente, ou você precisa ajustá-lo de alguma forma. E em nossa empresa, o IPv6 é muito difundido. Há muito que faltava endereços IPv4, portanto toda a infraestrutura interna está amplamente ligada ao IPv6. E quando o IPv6 não funciona no seu laptop ou dentro da janela de encaixe, que está no laptop, você sofre e não pode realmente fazer nada, então precisamos contorná-lo.

Apesar disso, nós amamos muito o docker. É eficaz, tem um bom ecossistema. As pessoas vêm até nós da rua, dizemos - você pode encaixar? Eles - sim, eu posso. Tudo perfeitamente. Uma pessoa chega e literalmente imediatamente começa a ser útil, porque ela não precisa se aprofundar em como iniciar e como criar um projeto, como executar testes, como analisar a composição ou alguma saída de depuração. O homem já sabe tudo. Esse é um padrão de fato no mundo exterior, aumenta nossa eficiência, podemos fornecer recursos rapidamente aos usuários e não gastar dinheiro em infraestrutura.
Idade 4: construção binária
Mas já estamos nos aproximando da última era em que estamos apenas entrando. E aqui voltarei ao início do meu relatório, quando disse: você chega a uma grande corporação com suas próprias abordagens de infraestrutura. Com o Yandex também. Se antes era uma infraestrutura Debian, agora é diferente. A empresa possui um único repositório monolítico há algum tempo, onde todo o código é coletado gradualmente. Um mecanismo de construção, um mecanismo de teste distribuído, um monte de ferramentas e tudo o que ainda não usamos, mas estamos começando a usar, foi criado em torno dele. Ou seja, nossos projetos python também caem neste repositório. Tentamos coletar com as mesmas ferramentas. Porém, como essas ferramentas de um único repositório são direcionadas principalmente para C ++, Java e Go, há uma peculiaridade.
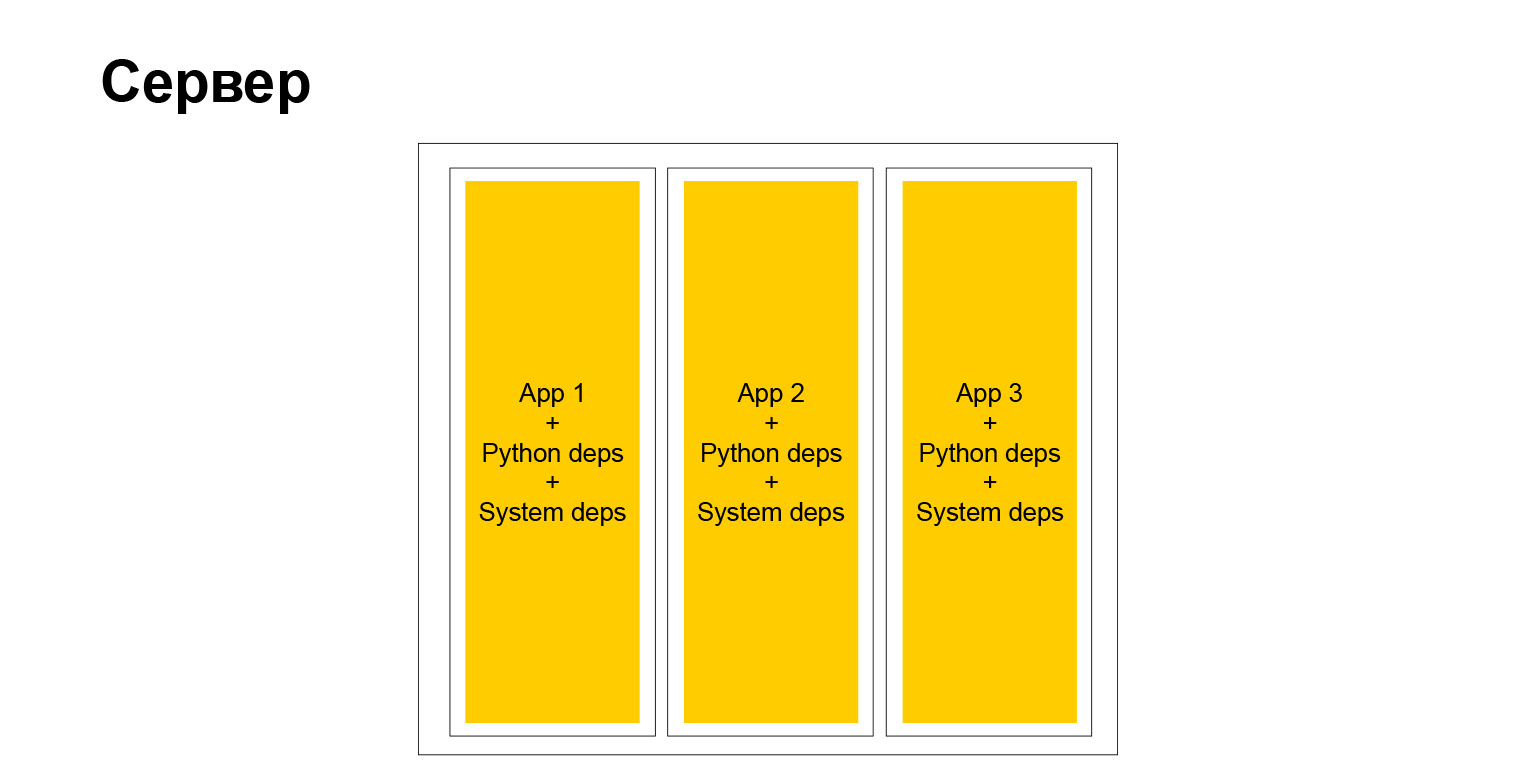
A peculiaridade é essa. Se agora o resultado da construção de nosso projeto é o Docker Engine, onde nosso código-fonte com todas as dependências está simplesmente localizado, chegamos à conclusão de que o resultado da construção de nosso projeto será apenas um binário. É apenas um binário, no qual há um interpretador python, código e nosso python e todas as outras dependências necessárias, eles estão estaticamente vinculados.
Acredita-se que você pode vir, lançar este binário em qualquer serviço Linux com uma arquitetura compatível e ele funcionará. E é verdade.
Parece um pouco não-nativo. A maioria das pessoas na comunidade python não faz isso, e tenho certeza que não. Isso tem seus prós e contras. Prós:
- . , , , , , . , . , , . .
- , , , . , , . , . , checkout , , . .
- , .
E, claro, há um sinal de menos: um ecossistema fechado. Um estranho precisa estar imerso em como tudo funciona, para dizer como funciona. Ele deve tentar e somente depois que isso se tornar eficaz. Estamos apenas no começo desse caminho. Talvez, se eu vier a esta conferência em um ou dois anos, eu possa lhe contar como passamos por essa transformação. Mas agora estamos otimistas em relação ao futuro e obedecemos a algumas regras corporativas internas, e gostamos mais do que não, porque teremos muitas vantagens internas.
conclusões
Eles são mais filosóficos. O relatório em si não é tanto técnico quanto filosófico.
- A evolução é inevitável. Se você prestar um serviço e ele viver por muito tempo, você o desenvolverá, evoluirá sua infraestrutura, da maneira que você o desenvolve.
- . , , , .
- . , Django, . , . , , , Django - , . , .
- Python-. , , -. , , . , , , , , : , . , .
O tópico é muito grande. Falei brevemente sobre como e o que fazemos, como o Python evoluiu em nosso país. Você pode pegar cada época, pegar cada ponto do slide e analisá-lo mais profundamente. E isso também é suficiente por 40 minutos - você pode conversar por muito tempo sobre dependências, código-fonte aberto interno e infraestrutura. Eu dei uma imagem geral. Se algum tópico for muito popular, poderei revelá-lo nas próximas reuniões ou conferências. Obrigado.