
Olhando para trás, posso dizer que todas as ações de posicionamento desde então são movimentos forçados. E somente agora pelo décimo quinto ano, podemos configurar a infraestrutura conforme necessário.
Agora, estamos em quatro data centers fisicamente diferentes, conectados por um anel de óptica escura, colocando cinco pools de recursos independentes lá. E aconteceu que, se um meteorito cair em uma das passagens, três dessas piscinas cairão imediatamente e as duas restantes não puxarão a carga. Então começamos um reequilíbrio completo para colocar as coisas em ordem.
Primeiro data center
No início, não havia data center. Havia um velho sistemista no dormitório da Universidade Estadual de Moscou. Então, quase imediatamente - hospedagem compartilhada na Masterhost (eles ainda estão vivos, inferno). O tráfego para o local com a programação do trem dobrava a cada 4 semanas; logo, mudamos para o KVM-VPS, isso aconteceu por volta de 2005. Em algum momento, encontramos restrições de tráfego, pois era necessário manter um equilíbrio entre as entradas e as saídas. Tínhamos duas instalações e trocamos alguns arquivos pesados de um para o outro todas as noites, a fim de manter as proporções necessárias.
Em março de 2009, havia apenas VPS. Isso é bom, decidimos mudar para a colocação. Compramos um par de servidores físicos de ferro (um deles é o da parede, cujo corpo armazenamos como memória). Colocamos o Fiord no data center (e eles ainda estão vivos, demônios). Por quê? Como não estava longe do escritório da época, um amigo recomendou e eu tive que me levantar rapidamente. Além disso, era relativamente barato.
Compartilhar a carga entre os servidores era simples: cada um tinha um back-end, MySQL com replicação mestre-escravo, a frente estava no mesmo local que a réplica. Bem, isto é quase sem divisão por tipo de carga. Logo eles também começaram a sentir falta, compraram um terço.
Por volta de 1º de outubro de 2009, percebemos que já existem mais servidores, mas, para o novo ano, nos deitaremos... As previsões de tráfego mostraram que a capacidade possível será cortada com uma margem. E encontramos o desempenho do banco de dados. Havia um mês e meio para se preparar antes do crescimento do tráfego. Este foi o momento das primeiras otimizações. Compramos alguns servidores exclusivamente para o banco de dados. Eles se concentraram em discos rápidos com uma velocidade de rotação de 15 krpm (não me lembro exatamente o motivo pelo qual não usamos SSDs, mas provavelmente eles tinham um limite baixo no número de operações de gravação e, ao mesmo tempo, custavam como um avião). Dividimos a frente, as costas, as bases, ajustamos as configurações do nginx, MySQL e redimensionamos para otimizar as consultas SQL. Sobreviveu.

Agora, estamos em um par de data centers de nível III e no nível II pela interface do usuário (com um balanço no T3, mas sem certificados). Mas o Fiord nunca foi um T-II. Eles tinham problemas de sobrevivência, havia situações da categoria "todos os fios de energia em um coletor e houve um incêndio, e o gerador dirigiu por três horas". Em geral, decidimos nos mudar.
Escolheu outro data center, Caravan. Desafio: como mover servidores sem tempo de inatividade? Decidimos morar em dois data centers por um tempo. Felizmente, o tráfego dentro do sistema naquela época não era tanto quanto agora, foi possível direcionar o tráfego através da VPN entre locais por algum tempo (especialmente fora de temporada). Tráfego equilibrado. Aumentou gradualmente a parte da Caravana, depois de um tempo, mudou-se completamente para lá. E agora temos um data center restante. E você precisa de dois, já entendemos isso, graças às falhas no fiorde. Olhando para trás nesses momentos, posso dizer que o TIER III também não é uma panacéia, a capacidade de sobrevivência será de 99,95, mas a disponibilidade é diferente. Portanto, um data center para disponibilidade de 99,95 ou superior definitivamente não é suficiente. Stordata foi
escolhido em segundo, e já havia a possibilidade de um link óptico com o site Caravan. Conseguiu esticar o primeiro núcleo. Assim que eles começaram a carregar o novo data center, a Caravan anunciou que eles eram fodidos. Eles tiveram que deixar o local porque o prédio foi demolido. Já. Surpresa! Existe um site novo, eles oferecem para extinguir tudo, erguer os racks com equipamentos com guindastes (já tínhamos 2,5 racks de ferro), traduzir, ligá-lo e tudo funcionará ... 4 horas para tudo ... contos de fadas ... já estou em silêncio que até temos uma hora de inatividade não se encaixava, mas aqui a história teria se arrastado por pelo menos um dia. E tudo isso foi servido no espírito de "Tudo se foi, o gesso é removido, o cliente está saindo!" Em 29 de setembro, a primeira ligação, e em 10 de outubro, eles queriam pegar tudo e pegar. Em 3 a 5 dias, tivemos que desenvolver um plano de mudança e, em 3 etapas,desligando 1/3 do equipamento por vez, com preservação total do serviço e tempo de atividade, transporte os carros para Stordata. Como resultado, o tempo de inatividade foi de 15 minutos em um serviço não crítico.
Então, novamente, ficamos com um data center.
Neste momento, estamos cansados de ficar com os servidores debaixo do braço e jogar com os motores. Além disso, cansado de fazer o ferro em si no data center. Eles começaram a olhar para as nuvens públicas.
De 2 a 5 (quase) data centers
Começou a procurar opções com nuvens. Fomos a Krok, experimentamos, testamos e concordamos com os termos. Ficamos na nuvem, que fica no data center do Compressor. Fez um anel de óptica escura entre Stordata, Compressor e escritório. Em todos os lugares tem seu uplink e dois ombros de óptica. Cortar qualquer um dos raios não destrói a rede. A perda de um uplink não destrói a rede. Temos o status LIR, temos nossa própria sub-rede, anúncios BGP, reservamos a rede, beleza. Não vou descrever exatamente como eles entraram na nuvem do ponto de vista da rede, mas havia nuances.
Portanto, temos 2 data centers.
A Krok também possui um data center em Volochaevskaya, eles expandiram sua nuvem para lá e se ofereceram para transferir parte de nossos recursos para lá. Mas lembrando a história da Caravana, que, de fato, nunca se recuperou após a demolição do data center, eu queria pegar recursos de nuvem de diferentes fornecedores para reduzir o risco de a empresa deixar de existir (o país é tal que esse risco não pode ser ignorado). Portanto, eles não se envolveram com Volochaevskaya naquela época. Bem, outro segundo fornecedor faz mágica com os preços. Porque quando você pode pegar e sair elasticamente, isso dá uma forte posição negocial nos preços.
Analisamos diferentes opções, mas a escolha caiu em #CloudMTS. Havia várias razões para isso: a nuvem nos testes provou ser boa, os caras também sabem como trabalhar com a rede (afinal, uma operadora de telecomunicações) e a política de marketing muito agressiva de capturar o mercado, como resultado, preços interessantes.
Total de 3 data centers.
Afinal, conectamos Volochaevskaya também - eram necessários recursos adicionais e, no Compressor, já estava um pouco cheio. Em geral, redistribuímos a carga entre as três nuvens e nossos equipamentos no Stordat.
4 data centers. E já em termos de vitalidade em todos os lugares T3. Parece que nem todo mundo tem certificados, mas não vou dizer com certeza.
MTS tinha uma nuance. Nada além do MGTS poderia ir até lá na última milha. Ao mesmo tempo, não foi possível extrair totalmente a óptica escura do MGTS do datacenter para o datacenter (por muito tempo, é caro e, se eu não os confundir, eles não fornecem esse serviço). Eu tive que fazer isso com uma junta, produzindo dois feixes do data center para os poços mais próximos, onde existe nosso fornecedor de óptica escura Mastertel. Eles têm uma extensa rede de ótica em toda a cidade e, se houver alguma coisa, apenas soldam a rota desejada e oferecem uma veia. Enquanto isso, a Copa do Mundo chegou à cidade, de repente, como neve no inverno, e o acesso aos poços em Moscou foi fechado. Estávamos esperando que esse milagre terminasse, e podemos lançar nosso link. Parece que era necessário deixar o data center do MTS com a ótica na mão, assobiando para alcançar a escotilha desejada e abaixá-la lá. Condicionalmente. Eles fizeram três meses e meio. Mais precisamente, o primeiro feixe foi feito rapidamente,no início de agosto (lembro que a Copa do Mundo terminou em 15 de julho). Mas tive que mexer no segundo ombro - a primeira opção significava que era necessário desenterrar a estrada Kashirskoe, para a qual estava bloqueada por uma semana (durante a reconstrução, algum túnel foi bloqueado, onde estão as comunicações, é necessário desenterrá-lo). Felizmente, encontramos uma alternativa: outra rota, a mesma geo-independente. Aconteceu duas veias desse data center em diferentes pontos de nossa presença. O anel óptico se transformou em um anel com uma caneta.Aconteceu duas veias desse data center em diferentes pontos de nossa presença. O anel óptico se transformou em um anel com uma alça.Aconteceu duas veias desse data center em diferentes pontos de nossa presença. O anel óptico se transformou em um anel com uma alça.
Olhando um pouco à frente, direi que eles nos colocam de qualquer maneira. Felizmente, no início da operação, quando pouco foi transferido. Um incêndio explodiu em um poço, e enquanto os instaladores estavam xingando em espuma, no segundo poço alguém puxou um conector para olhar (de alguma forma, era de um novo design). Matematicamente, a probabilidade de uma falha simultânea era insignificante. Nós praticamente o pegamos. Na verdade, tivemos sorte no Fiord - a fonte de alimentação principal foi cortada lá e, em vez de ligá-lo novamente, alguém confundiu o interruptor e desligou a linha de backup.
Não havia apenas requisitos técnicos para a distribuição de carga entre locais: não há milagres, e uma política de marketing agressiva com bons preços implica certas taxas de crescimento no consumo de recursos. Por isso, lembramos o tempo todo qual porcentagem de recursos deve ser enviada ao MTS. Redistribuímos todo o resto entre outros data centers de maneira mais ou menos uniforme.
Seu ferro de novo
A experiência de usar nuvens públicas nos mostrou que é conveniente usá-las quando você precisa adicionar recursos rapidamente, para experimentos, para um piloto etc. Quando usado sob carga constante, acaba por ser mais caro do que torcer o ferro. Mas não podíamos mais abandonar a ideia de contêineres, migrações contínuas de máquinas virtuais dentro de um cluster etc. Escrevemos automação para extinguir alguns carros à noite, mas ainda assim a economia não deu certo. Como não tínhamos experiência suficiente para oferecer suporte a uma nuvem privada, tivemos que aumentá-la.
Estávamos procurando uma solução que permitisse obter uma nuvem no seu hardware com relativa facilidade. Naquela época, nunca trabalhávamos com servidores Cisco, apenas com uma pilha de rede, isso era um risco. Dellah tem um hardware simples e familiar, tão confiável quanto um fuzil de assalto Kalashnikov. Temos isso há anos, e ainda temos algum lugar. Mas a idéia por trás do Hyperflex é que ele é compatível com a hiperconvergência da solução final. E na Della tudo vive em roteadores comuns, e há nuances. Em particular, o desempenho não é tão legal quanto nas apresentações devido à sobrecarga. Quero dizer, eles podem ser configurados corretamente e será super, mas decidimos que esse não é o nosso negócio e deixamos a Dell ser preparada por aqueles que consideram isso uma vocação. Como resultado, escolhemos o Cisco Hyperflex. Essa opção ganhou em conjunto como a mais interessante: menos hemorróidas na instalação e operação,e tudo correu bem durante os testes. No verão de 2019, lançamos o cluster em batalha. Tínhamos um rack meio vazio no Compressor, ocupado na maior parte apenas com equipamentos de rede e o colocamos lá. Assim, obtivemos o quinto "data center" - fisicamente, quatro, mas os pools de recursos acabaram sendo cinco.
Pegamos, calculamos o volume da carga constante e o volume da variável. Eles transformaram a constante em uma carga sobre o ferro. Mas para que, no nível do hardware, ofereça vantagens à nuvem em resiliência e redundância.
O período de retorno do projeto de ferro está nos preços médios de nossas nuvens para o ano.
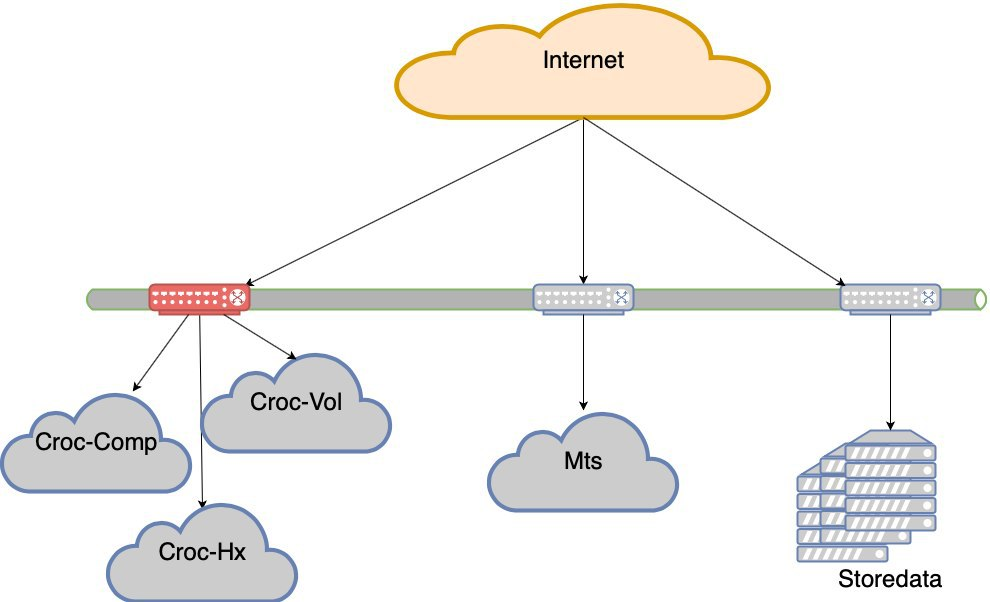
Você está aqui
Neste momento, terminamos os movimentos forçados. Como você pode ver, não tínhamos muitas opções econômicas e carregávamos constantemente o que tínhamos de suportar por algum motivo. Isso levou a uma situação estranha em que a carga é desigual. A falha de qualquer segmento (e o segmento com os data centers da Croc é mantido por dois Nexuses em um gargalo) é uma perda de experiência do usuário. Ou seja, o site será preservado, mas haverá dificuldades óbvias com a acessibilidade.
Houve uma falha no MTS com todo o data center. Havia mais dois nos outros. De tempos em tempos, nuvens caíam, controladores de nuvem ou algum problema complexo de rede. Em resumo, perdemos os data centers de tempos em tempos. Sim, por um curto período de tempo, mas ainda desagradável. Em algum momento, eles deram como certo que os data centers estavam caindo.
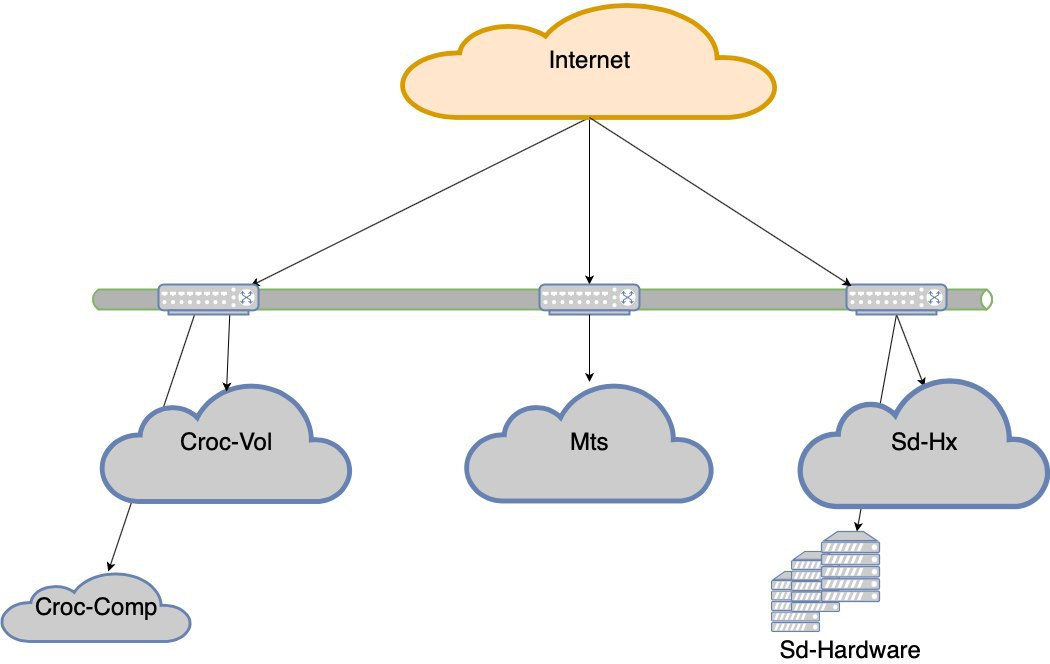
Decidimos ir para o nível de tolerância a falhas dos data centers.
Agora não vamos nos deitar se um dos cinco data centers falhar. Mas se perdermos o ombro de Croc, haverá rebaixamentos muito sérios. E assim nasceu o projeto de resiliência do data center. O objetivo é o seguinte: se o controlador de domínio morre, a rede morre antes dele ou o equipamento morre, o site deve funcionar sem intervenção manual. Além disso, após o acidente, temos que nos recuperar regularmente.
Quais são as armadilhas
Agora:
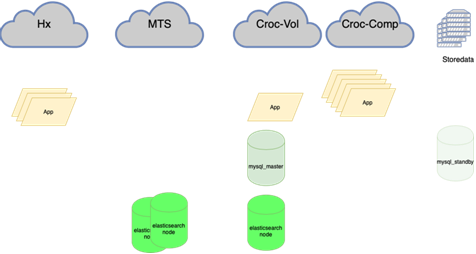
Preciso:
Agora:
Preciso:
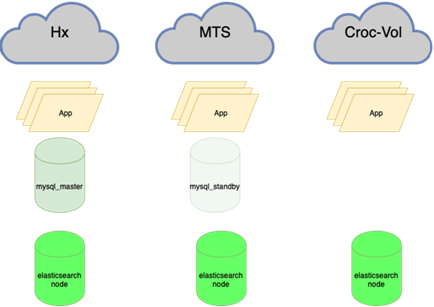
Elastic é resistente à perda de um nó:
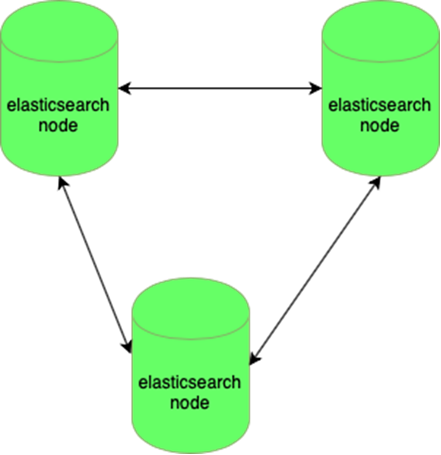
Os bancos de dados MySQL (muitos pequenos) são difíceis de gerenciar:
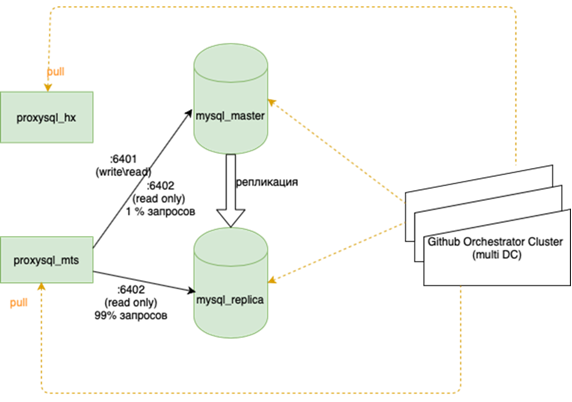
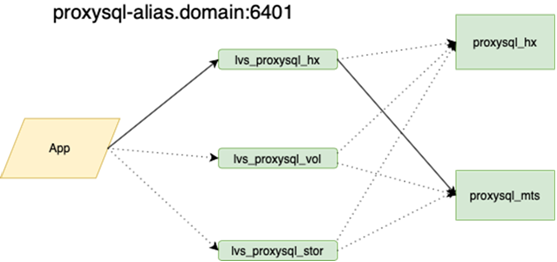
Meu colega, que fez o equilíbrio, escreverá sobre isso com mais detalhes. É importante que antes de pendurarmos isso, se perdemos o mestre, tivéssemos que ir para a reserva com as mãos e colocar a bandeira r / o = 0 lá, reconstruir todas as réplicas desse novo mestre com ansible, e há mais de duas delas na guirlanda principal dezenas, altere as configurações de aplicativos, implante as configurações e aguarde atualizações. Agora, o aplicativo é executado em um anycast-ip, que analisa o balanceador LVS. A configuração permanente não muda. Toda a topologia das bases da orquestra.
Agora, a óptica escura está estendida entre nossos data centers, o que nos permite acessar qualquer recurso em nosso anel como local. O tempo de resposta entre os datacenters e o tempo dentro de mais ou menos são os mesmos. Essa é uma diferença importante de outras empresas que estão construindo geoclusters. Estamos muito ligados ao nosso hardware e à nossa rede e não tentamos localizar solicitações dentro do data center. Por um lado, isso é legal, mas, por outro, se quisermos ir para a Europa ou China, não retiraremos nossa ótica sombria.
Isso significa reequilibrar quase tudo, especialmente bancos de dados. Existem muitos esquemas, quando o mestre ativo retém toda a carga para leitura e gravação e, ao lado dele, há uma réplica síncrona para troca rápida (não escrevemos em dois de uma vez, mas replicamos, caso contrário, não funciona muito bem). A base principal está em um datacenter e a réplica em outro. Cópias ainda parciais podem estar na terceira para aplicações individuais. Existem 10 a 15 casos, dependendo da época do ano. O Orchestrator é um cluster estendido entre data centers e 3 data centers. Aqui, contaremos mais detalhadamente quando você tiver forças para descrever como toda essa música toca.
Você precisará cavar os aplicativos. Isso agora é necessário: às vezes acontece que, se a conexão for interrompida, é correto pagar o antigo, abrir um novo. Mas, às vezes, as solicitações são repetidas em uma conexão já perdida em um loop até o processo morrer. A última coisa que pegaram foi a tarefa da coroa, um lembrete sobre o trem não foi escrito.
Em geral, ainda há algo a fazer, mas o plano é claro.