
Tomaremos como base os scripts do Apêndice B - Exemplo de gráfico de mitologia grega da documentação de referência de gráfico do SAP HANA para uma plataforma típica do SAP HANA implantada localmente no data center. O principal objetivo deste exemplo é mostrar os recursos analíticos do SAP HANA, para mostrar como você pode analisar o relacionamento de objetos e eventos usando algoritmos de gráfico. Não vamos nos aprofundar nessa tecnologia em detalhes, a idéia principal ficará clara a partir da apresentação posterior. Qualquer pessoa interessada pode descobrir isso sozinha testando os recursos do SAP HANA express edition ou fazer um curso gratuito Analisando dados conectados com o SAP HANA Graph .
Vamos colocar os dados na nuvem relacional do SAP HANA Cloud e ver as possibilidades de analisar o parentesco dos heróis gregos. Lembre-se, em "Mitos e lendas da Grécia antiga" havia muitos personagens e, no meio, você não lembra quem é o filho e o irmão de quem? Aqui faremos um memorando para nós mesmos e nunca o esqueceremos.
Primeiro, crie uma instância do SAP HANA Cloud. Isso é bastante simples, você precisa preencher os parâmetros do sistema futuro e aguardar alguns minutos enquanto a instância é implantada para você (Fig. 1).

Figura 1
Portanto, pressionamos o botão Criar instância e, diante de nós, a primeira página do assistente, onde é necessário especificar o nome abreviado da instância, definir uma senha e uma descrição de (Figura 2)
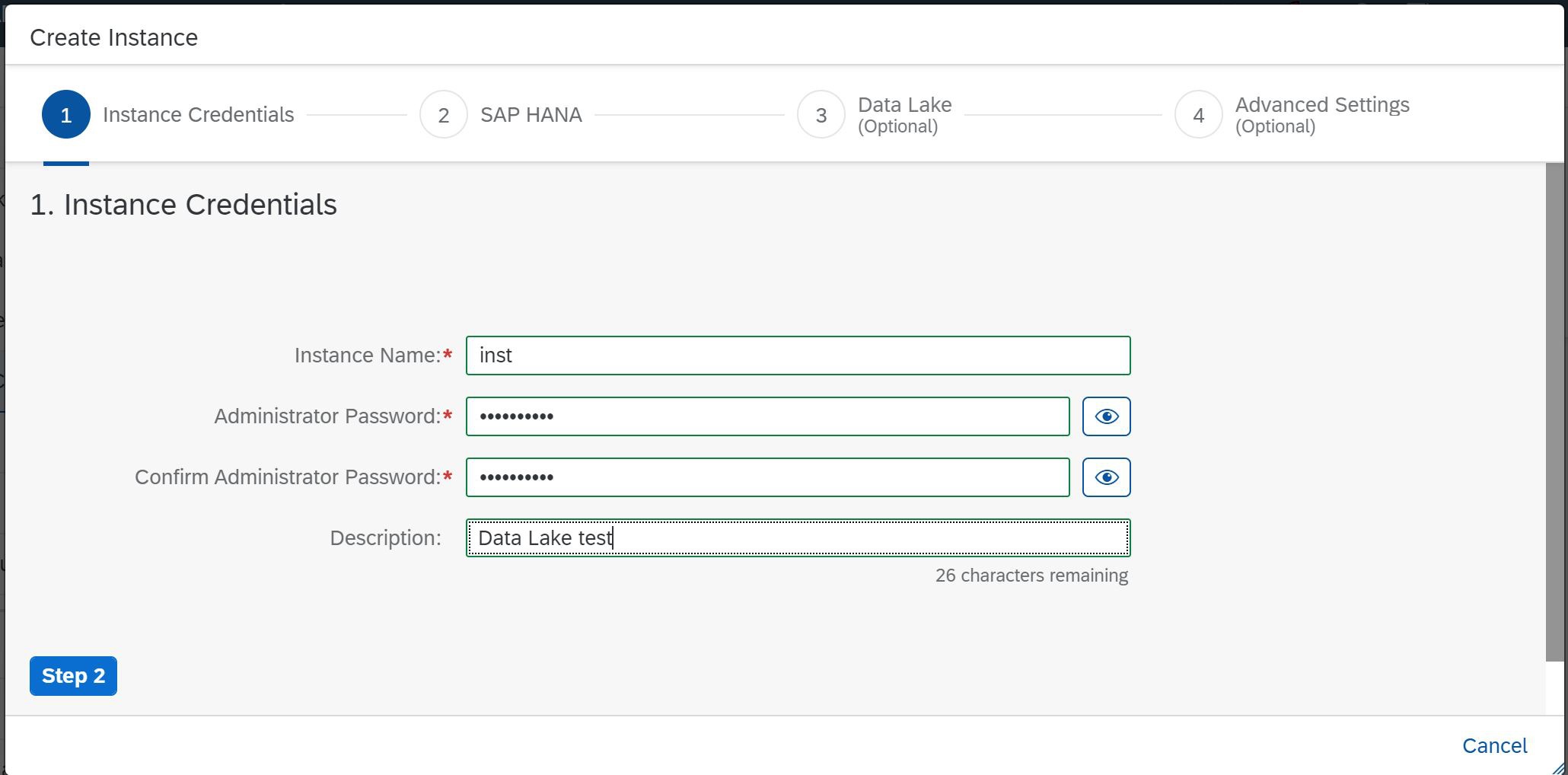
Figura 2
Clicamos no botão Etapa 2, agora nossa tarefa é especificar os parâmetros da futura instância do SAP HANA. Aqui você pode definir apenas o tamanho da RAM do futuro sistema, todos os outros parâmetros serão determinados automaticamente (fig. 3).

Figura 3
Vemos que agora temos a oportunidade de escolher o valor mínimo de 30 GB e o valor máximo de 900 GB. Selecionamos 30 GB e é determinado automaticamente que, com essa quantidade de memória, são necessários dois processadores virtuais para suportar cálculos e 120 GB para armazenar dados em disco. Mais espaço é alocado aqui, pois podemos usar a tecnologia SAP HANA Native Storage Extension (NSE). Se você escolher um tamanho de memória maior, por exemplo, 255 GB, serão necessários 17 processadores virtuais e 720 GB de memória em disco (Fig. 4).
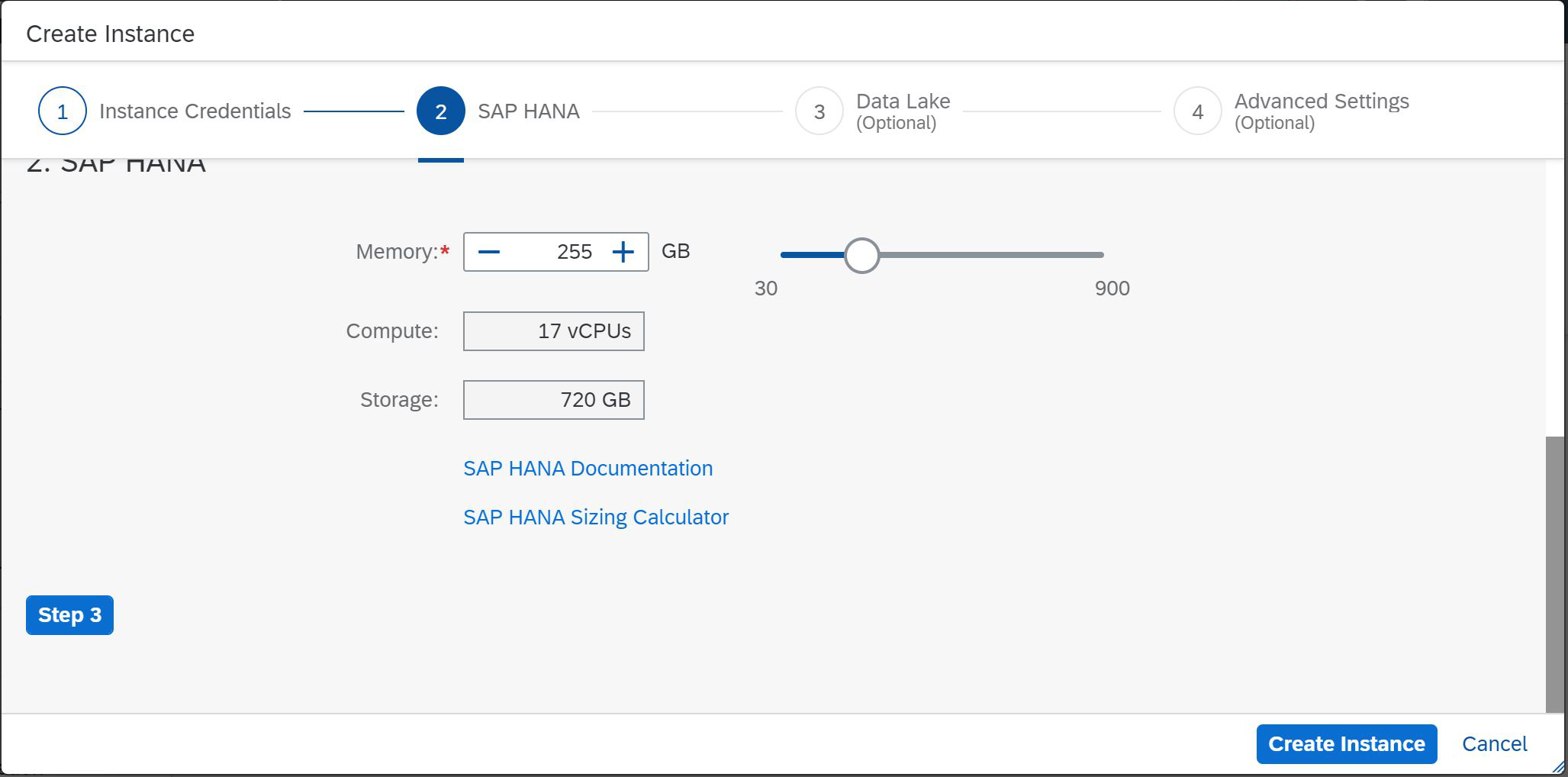
Figura 4
Mas não precisamos de tanta memória para o exemplo. Retornamos os parâmetros aos seus valores originais e clicamos na Etapa 3. Agora devemos escolher se deseja usar o data lake. A resposta é óbvia para nós. Claro que vamos. Este é o experimento que queremos realizar (Fig. 5).

Figura 5
Nesta etapa, temos muito mais oportunidades e liberdade para criar uma instância do data lake. Você pode escolher o tamanho dos recursos de computação e armazenamento em disco necessários. Os parâmetros dos componentes / nós usados serão selecionados automaticamente. O próprio sistema determinará os recursos de computação necessários para os nós "coordenador" e "trabalhando". Se você quiser saber mais sobre esses componentes, é melhor recorrer aos recursos do SAP IQ e ao data lake do SAP HANA Cloud. E seguimos em frente, clique na Etapa 4.
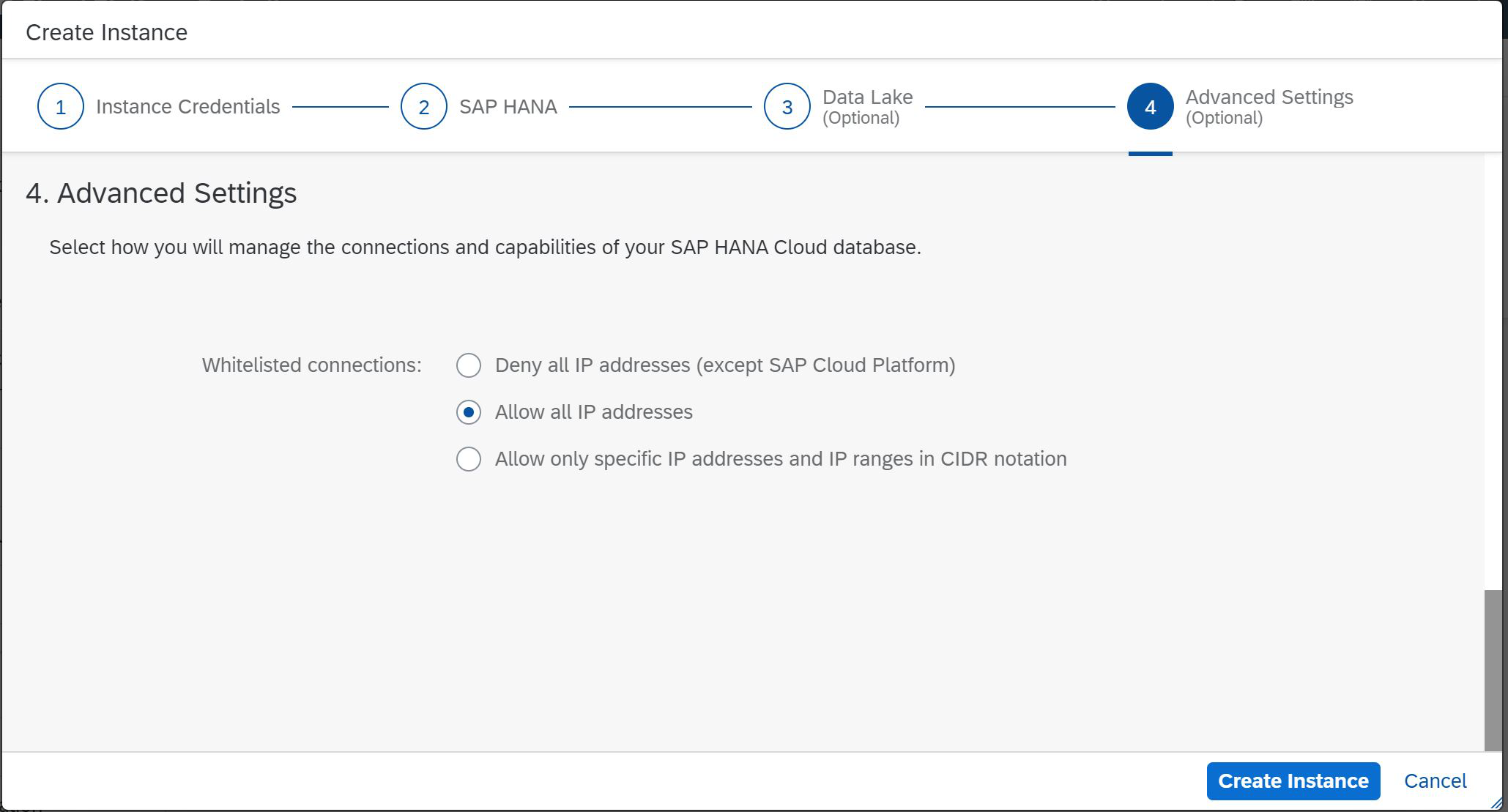
Figura 6
Nesta etapa, determinaremos ou limitaremos os endereços IP que podem acessar a instância futura do SAP HANA. Como você pode ver, este é o último passo do nosso assistente (Fig. 6). Resta clicar em Criar instância e servir um pouco de café.

Figura 7
O processo é iniciado (Fig. 7) e com muito pouco tempo, apenas tivemos tempo para tomar café forte, apesar da madrugada. E quando mais você pode experimentar com segurança o sistema e prender chips diferentes? Então, nosso sistema é criado (Fig. 8).

Figura 8
Temos duas opções: abra o SAP HANA Cockpit ou o SAP HANA Database Explorer. Sabemos que o segundo produto pode ser lançado a partir do Cockpit. Portanto, abrimos o SAP HANA Cockpit, ao mesmo tempo e vemos o que está lá. Mas primeiro, você precisará especificar o usuário e sua senha. Observe que o usuário do sistema não está disponível para você; você deve usar o DBADMIN. Nesse caso, especifique a senha que você definiu ao criar a instância, como na Fig. 9.
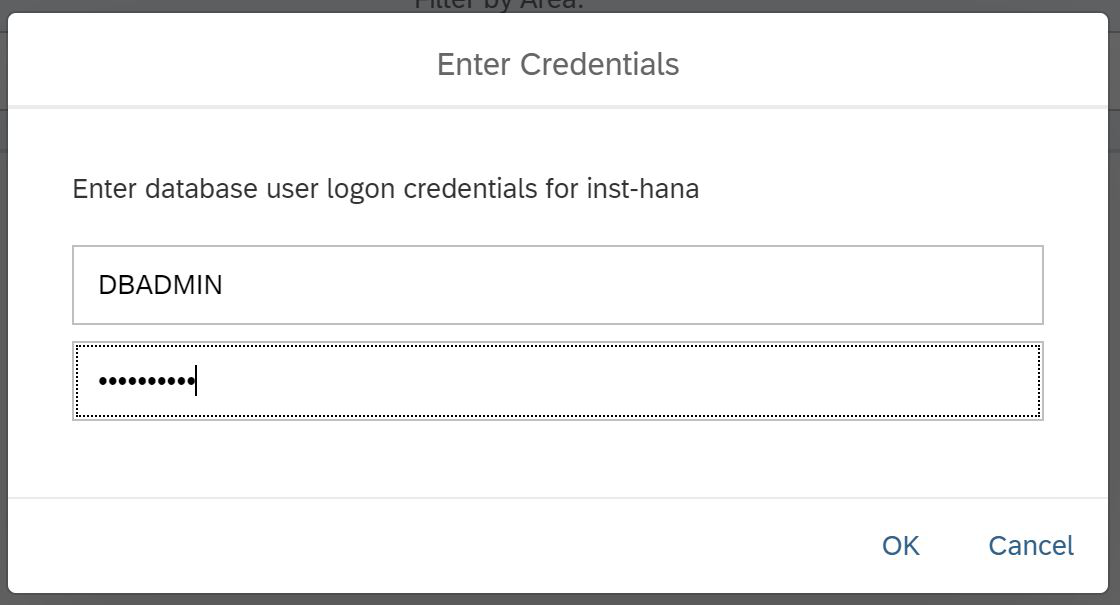
Figura 9
Entramos no Cockpit e vimos a interface tradicional do SAP na forma de blocos, quando cada um deles é responsável por sua tarefa. No canto superior direito, vemos um link para o SQL Console (Fig. 10).
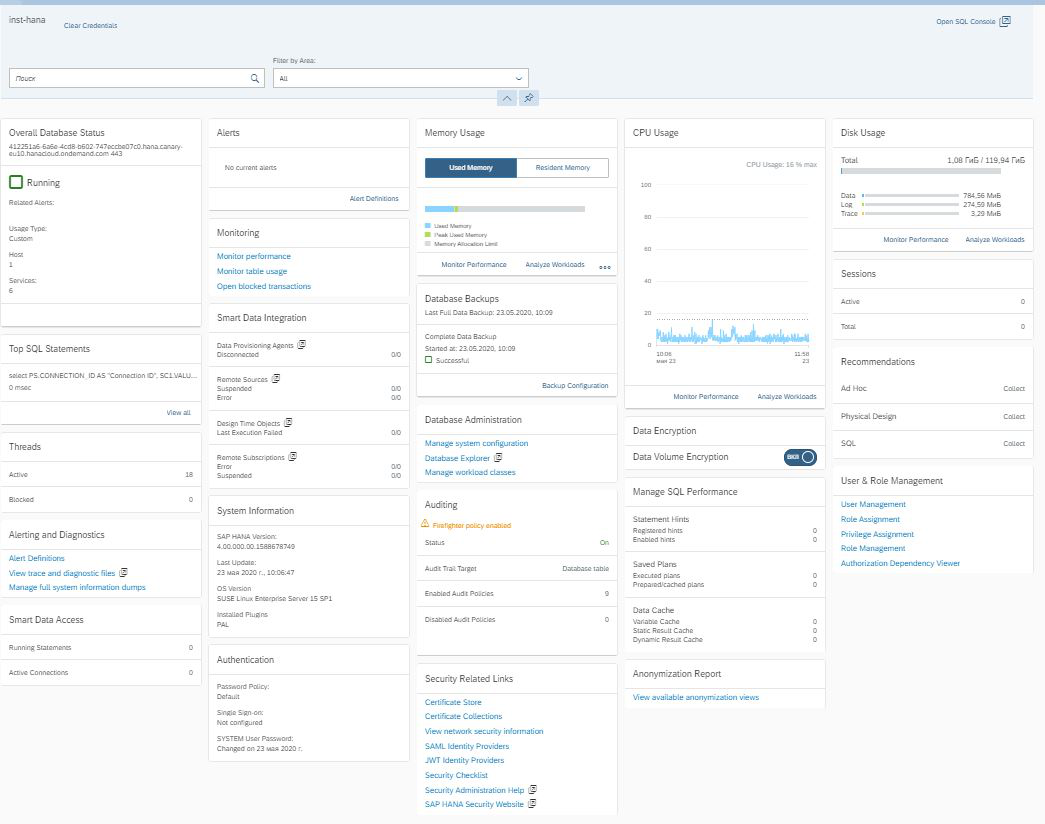
Figura 10
É ela quem nos permite acessar o SAP HANA Database Explorer.
A interface desta ferramenta é semelhante ao SAP Web IDE, mas apenas para trabalhar com objetos de banco de dados. Antes de tudo, é claro, estamos interessados em como entrar no data lake. Afinal, agora abrimos uma ferramenta para trabalhar com o HANA. Iremos para o item Fonte remota no navegador e veremos um link para o lago (SYSRDL, RDL - Lago de Dados de Relação). Aqui está o acesso desejado (Fig. 11).

Figura 11
Seguindo em frente, não precisamos trabalhar com um administrador. Precisamos criar um usuário de teste, com o qual experimentaremos o mecanismo de gráficos HANA, mas colocaremos os dados em um lago de dados relacionais.
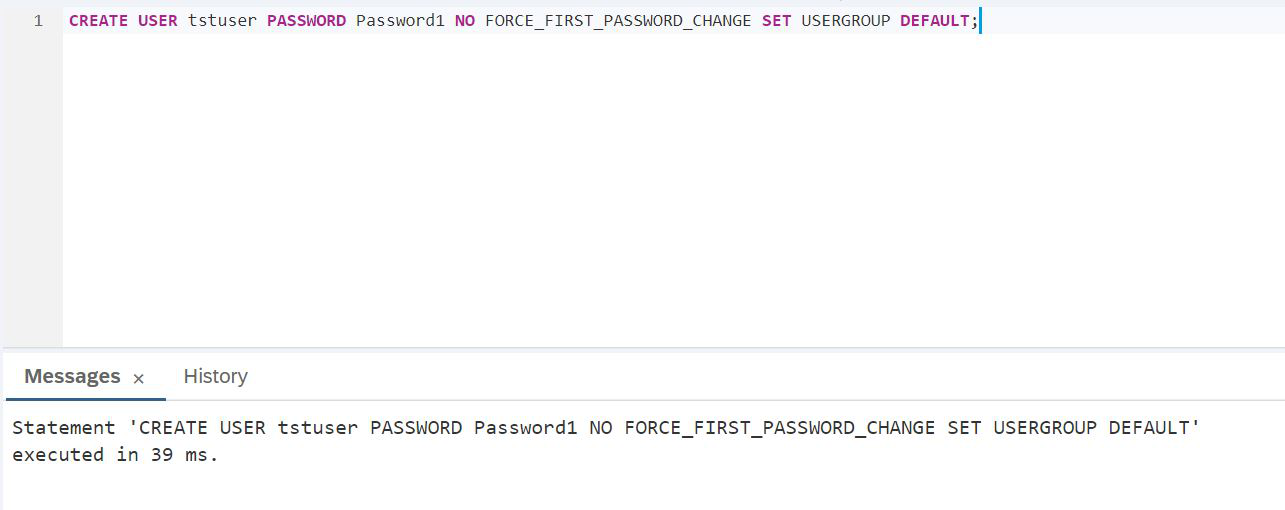
ROTEIRO:
CREATE USER tstuser PASSWORD Password1 NO FORCE_FIRST_PASSWORD_CHANGE SET USERGROUP DEFAULT;Planejamos trabalhar com o data lake, por isso é imperativo conceder direitos, por exemplo, HANA_SYSRDL # CG_ADMIN_ROLE, para que você possa criar livremente objetos, faça o que quisermos.
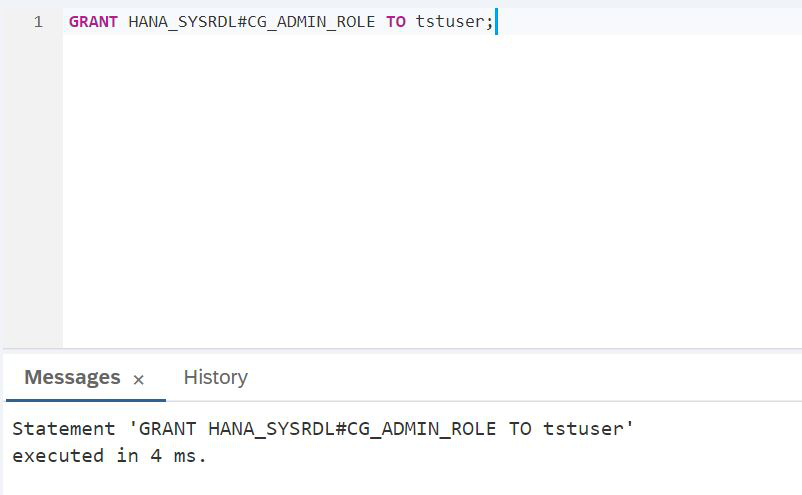
ROTEIRO:
GRANT HANA_SYSRDL#CG_ADMIN_ROLE TO tstuser;Agora que o trabalho sob o administrador do SAP HANA está concluído, o SAP HANA Database Explorer pode ser fechado e precisamos fazer login com o novo usuário criado: tstuser. Para simplificar, vamos voltar ao cockpit do SAP HANA e encerrar a sessão de administração. Para fazer isso, no canto superior esquerdo, existe um link Clear Credentials (Fig. 12).

Figura 12
Depois de clicar nele, precisamos fazer login novamente, mas agora sob o usuário tstuser (Figura 13).
Figura 13
E podemos abrir o SQL Console novamente para retornar ao SAP HANA Database Explorer, mas com um novo usuário (Figura 14).

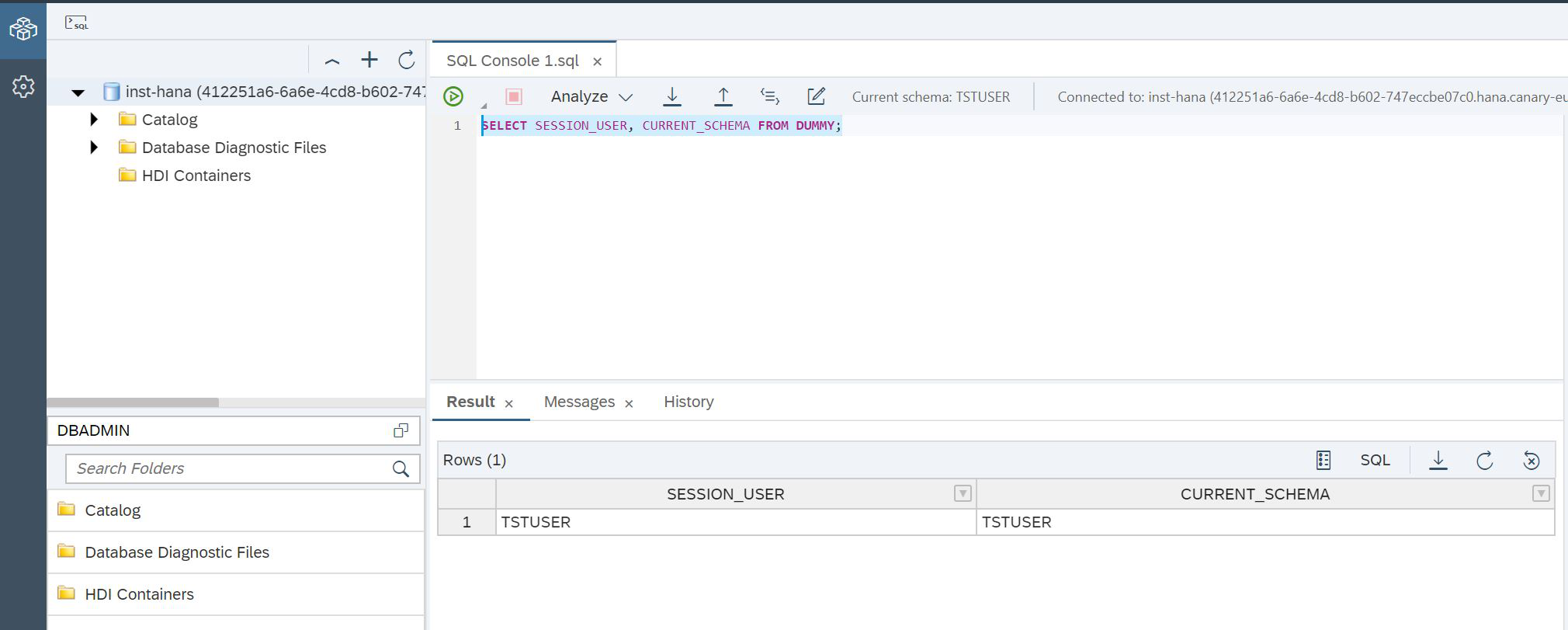
Figura 14
SCRIPT:
SELECT SESSION_USER, CURRENT_SCHEMA FROM DUMMY;É isso, agora temos certeza de que estamos trabalhando com o HANA com o usuário certo. É hora de criar tabelas no data lake. Para fazer isso, existe um procedimento especial SYSRDL # CG.REMOTE_EXECUTE, no qual você precisa passar um parâmetro - uma linha = comando. Usando essa função, criamos uma tabela no data lake (Fig. 15), na qual todos os nossos personagens serão armazenados: heróis, deuses gregos e titãs.

Figura 15
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
CREATE TABLE "MEMBERS" (
"NAME" VARCHAR(100) PRIMARY KEY,
"TYPE" VARCHAR(100),
"RESIDENCE" VARCHAR(100)
);
END');E então criamos uma tabela na qual armazenaremos os relacionamentos desses caracteres (Fig. 16).

Figura 16
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
CREATE TABLE "RELATIONSHIPS" (
"KEY" INTEGER UNIQUE NOT NULL,
"SOURCE" VARCHAR(100) NOT NULL,
"TARGET" VARCHAR(100) NOT NULL,
"TYPE" VARCHAR(100),
FOREIGN KEY RELATION_SOURCE ("SOURCE") references "MEMBERS"("NAME") ON UPDATE RESTRICT ON DELETE RESTRICT,
FOREIGN KEY RELATION_TARGET ("TARGET") references "MEMBERS"("NAME") ON UPDATE RESTRICT ON DELETE RESTRICT
);
END');Não vamos lidar com questões de integração agora, essa é uma história separada. No exemplo original, existem comandos INSERT para criar os deuses gregos e seu parentesco. Nós usamos esses comandos. Só precisamos lembrar que estamos passando o comando através de um procedimento para o data lake, portanto, precisamos duplicar as aspas, como mostra a Fig. 17.

Figura 17
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Chaos'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Gaia'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Uranus'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Rhea'', ''titan'', ''Tartarus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Cronus'', ''titan'', ''Tartarus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Zeus'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Poseidon'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hades'', ''god'', ''Underworld'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hera'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Demeter'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Athena'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Ares'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Aphrodite'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hephaestus'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Persephone'', ''god'', ''Underworld'');
END');E a segunda tabela (Fig. 18)
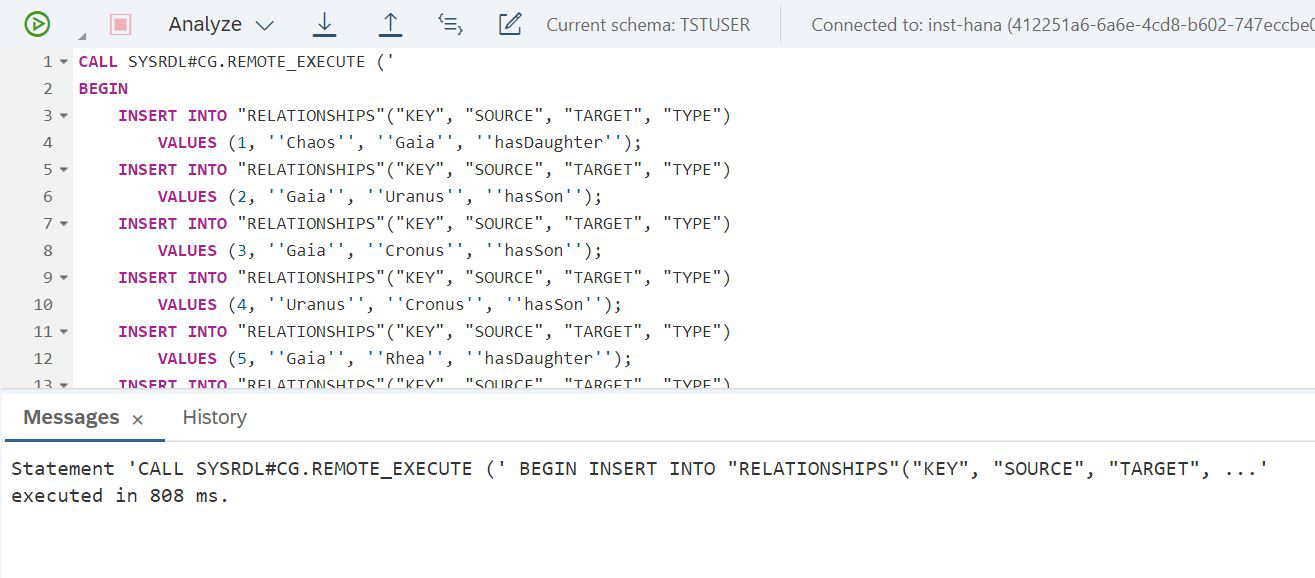
Figura 18
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (1, ''Chaos'', ''Gaia'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (2, ''Gaia'', ''Uranus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (3, ''Gaia'', ''Cronus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (4, ''Uranus'', ''Cronus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (5, ''Gaia'', ''Rhea'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (6, ''Uranus'', ''Rhea'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (7, ''Cronus'', ''Zeus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (8, ''Rhea'', ''Zeus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (9, ''Cronus'', ''Hera'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (10, ''Rhea'', ''Hera'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (11, ''Cronus'', ''Demeter'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (12, ''Rhea'', ''Demeter'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (13, ''Cronus'', ''Poseidon'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (14, ''Rhea'', ''Poseidon'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (15, ''Cronus'', ''Hades'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (16, ''Rhea'', ''Hades'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (17, ''Zeus'', ''Athena'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (18, ''Zeus'', ''Ares'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (19, ''Hera'', ''Ares'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (20, ''Uranus'', ''Aphrodite'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (21, ''Zeus'', ''Hephaestus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (22, ''Hera'', ''Hephaestus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (23, ''Zeus'', ''Persephone'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (24, ''Demeter'', ''Persephone'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (25, ''Zeus'', ''Hera'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (26, ''Hera'', ''Zeus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (27, ''Hades'', ''Persephone'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (28, ''Persephone'', ''Hades'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (29, ''Aphrodite'', ''Hephaestus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (30, ''Hephaestus'', ''Aphrodite'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (31, ''Cronus'', ''Rhea'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (32, ''Rhea'', ''Cronus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (33, ''Uranus'', ''Gaia'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (34, ''Gaia'', ''Uranus'', ''marriedTo'');
END');Agora vamos abrir a Fonte remota novamente. Com base na descrição das tabelas no data lake, precisamos criar tabelas virtuais no HANA (Fig. 19).
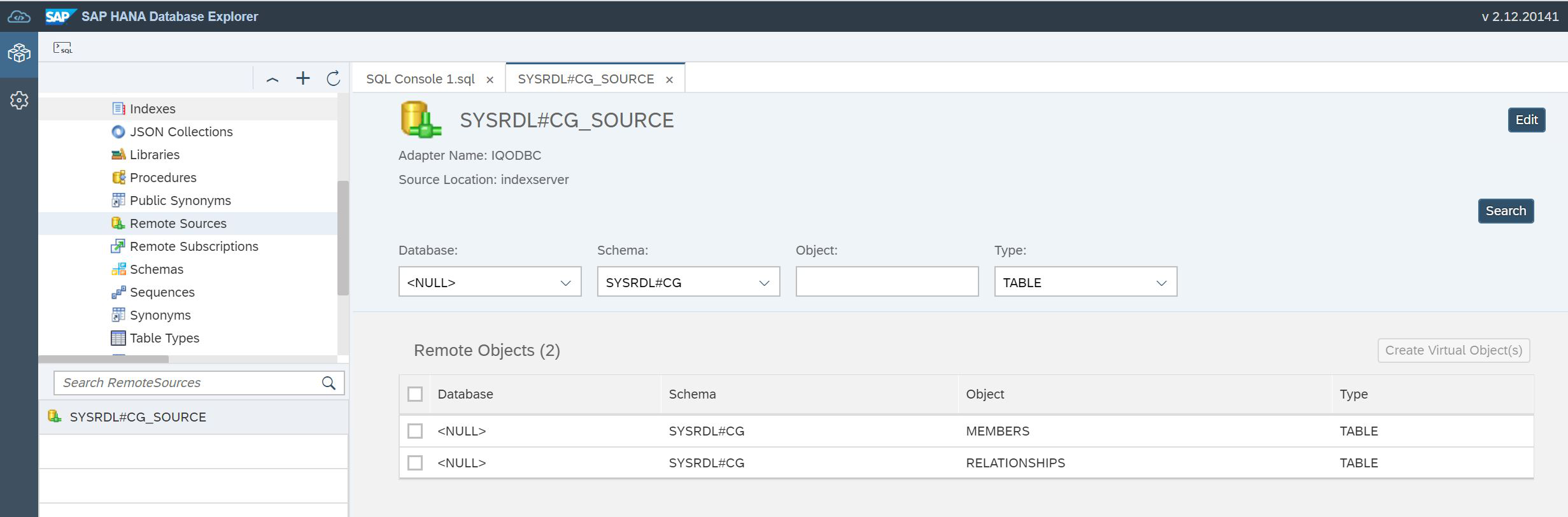
Figura 19
Encontramos as duas tabelas, defina as “caixas de seleção” opostas às tabelas e clique no botão Criar objeto (s) virtual (is), conforme mostrado na Fig. 20.
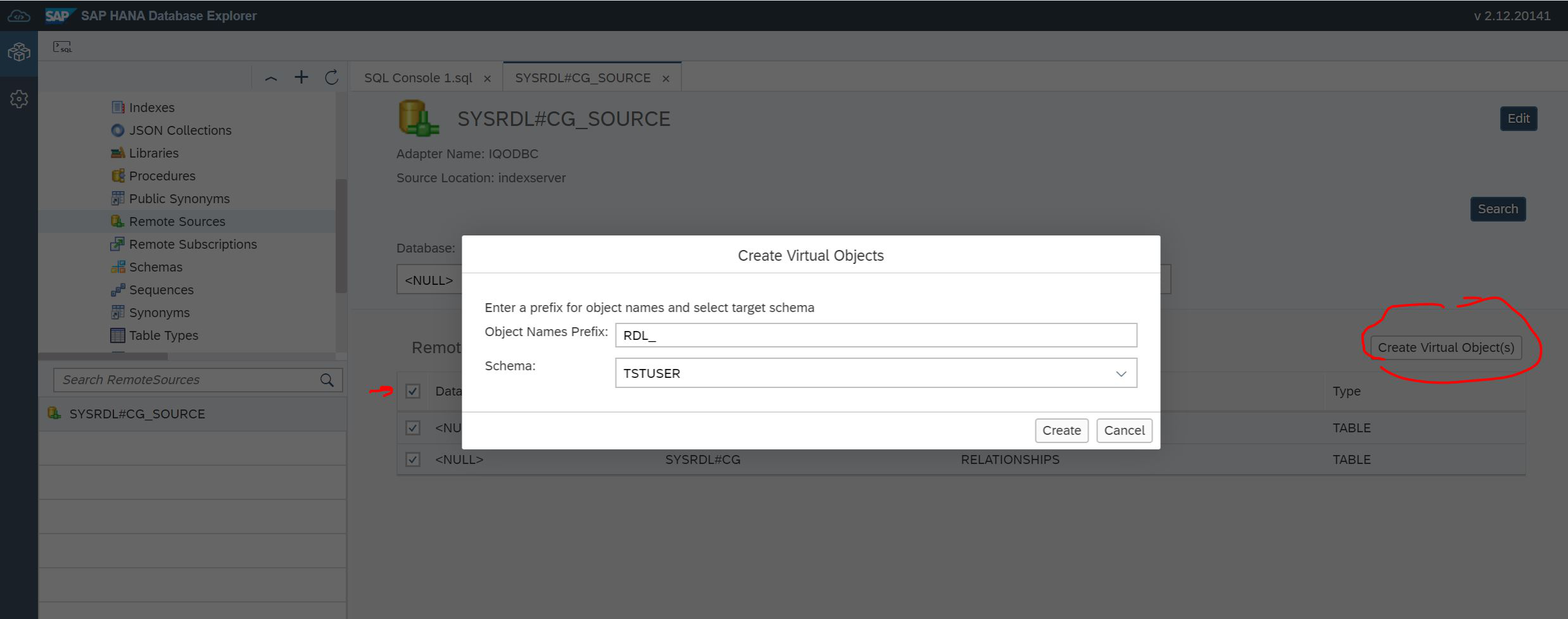
Figura 20
Temos a capacidade de especificar o esquema no qual as tabelas virtuais serão criadas. E é preciso especificar um prefixo para facilitar a localização dessas tabelas. Depois disso, podemos selecionar Tabela no navegador, ver nossas tabelas e ver os dados (Fig. 21).

Figura 21
Nesta etapa, é importante prestar atenção ao filtro na parte inferior esquerda. Deve haver nosso nome de usuário ou nosso esquema TSTUSER.
Você está quase pronto. Criamos tabelas no lago e carregamos dados para elas. Para acessá-las no nível do HANA, temos tabelas virtuais. Estamos prontos para criar um novo objeto - um gráfico (Fig. 22).
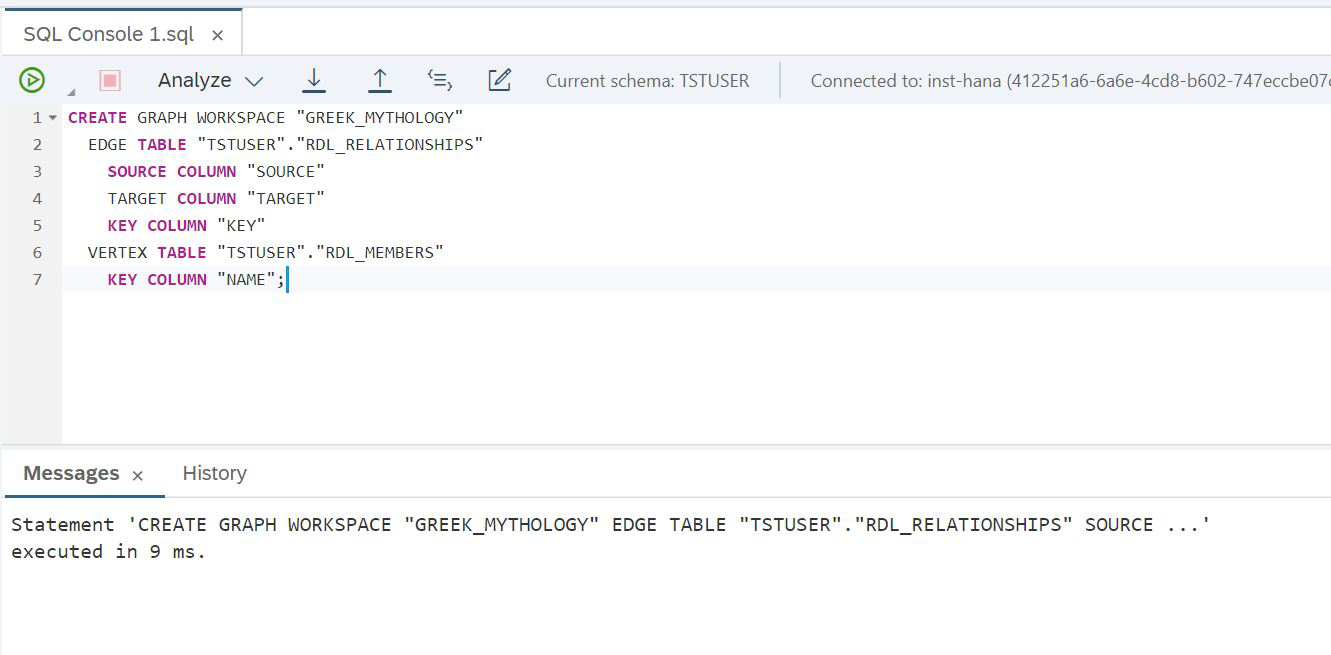
Figura 22
SCRIPT:
CREATE GRAPH WORKSPACE "GREEK_MYTHOLOGY"
EDGE TABLE "TSTUSER"."RDL_RELATIONSHIPS"
SOURCE COLUMN "SOURCE"
TARGET COLUMN "TARGET"
KEY COLUMN "KEY"
VERTEX TABLE "TSTUSER"."RDL_MEMBERS"
KEY COLUMN "NAME";Tudo funcionou, o gráfico está pronto. E imediatamente você pode tentar fazer uma consulta simples nos dados do gráfico, por exemplo, para encontrar todas as filhas do Caos e todas as filhas dessas filhas. Para fazer isso, Cypher, uma linguagem de análise de gráficos, nos ajudará. Foi criado especialmente para trabalhar com gráficos, conveniente, simples e ajuda a resolver problemas complexos. Só precisamos lembrar que o script Cypher precisa ser agrupado em uma consulta SQL usando uma função de tabela. Veja como nossa tarefa é resolvida nesse idioma (Fig. 23).

Figura 23
SCRIPT:
SELECT * FROM OPENCYPHER_TABLE( GRAPH WORKSPACE "GREEK_MYTHOLOGY" QUERY
'
MATCH p = (a)-[*1..2]->(b)
WHERE a.NAME = ''Chaos'' AND ALL(e IN RELATIONSHIPS(p) WHERE e.TYPE=''hasDaughter'')
RETURN b.NAME AS Name
ORDER BY b.NAME
'
)Vamos verificar como a ferramenta visual de análise gráfica do SAP HANA funciona. Para fazer isso, selecione Graph Workspace no navegador (Fig. 24).
Figura 24
E agora você pode ver o nosso gráfico (Fig. 25).
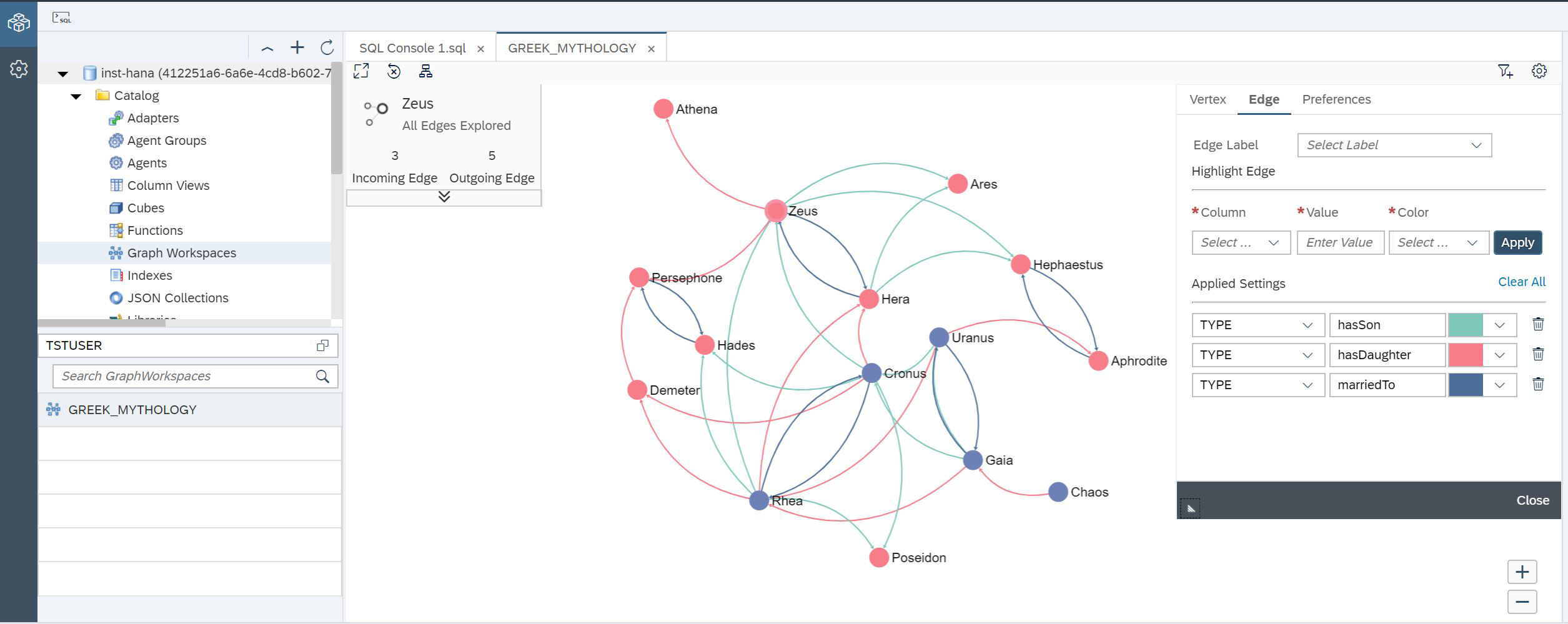
Figura 25.
Você vê o gráfico já "colorido". Fizemos isso usando as configurações no lado direito da tela. No canto superior esquerdo, são exibidas informações detalhadas sobre o nó atualmente selecionado.
Bem ... nós conseguimos. Os dados estão no data lake e os analisamos com ferramentas no SAP HANA. Uma tecnologia calcula os dados e a outra é responsável por armazená-los. Quando os dados do gráfico são processados, eles são solicitados no data lake e transferidos para o SAP HANA. Podemos acelerar nossos pedidos? Como tornar os dados armazenados na RAM e não carregados do data lake? Existe uma maneira simples, mas não muito agradável - crie uma tabela na qual carregar o conteúdo da tabela do data lake (Fig. 26).

Figura 26
SCRIPT:
CREATE COLUMN TABLE MEMBERS AS (SELECT * FROM "TSTUSER"."RDL_MEMBERS")Mas há outra maneira - esse é o uso da replicação de dados na RAM do SAP HANA. Isso pode fornecer melhor desempenho para consultas SQL do que acessar dados armazenados em um data lake usando uma tabela virtual. Você pode alternar entre tabelas virtuais e de replicação. Para fazer isso, adicione uma tabela de réplicas à tabela virtual. Isso pode ser feito usando a instrução ALTER VIRTUAL TABLE. Depois disso, uma consulta usando uma tabela virtual acessa automaticamente a tabela de réplicas, localizada na RAM do SAP HANA. Vamos ver como fazer isso, vamos realizar um experimento. Executamos essa solicitação (Fig. 27).
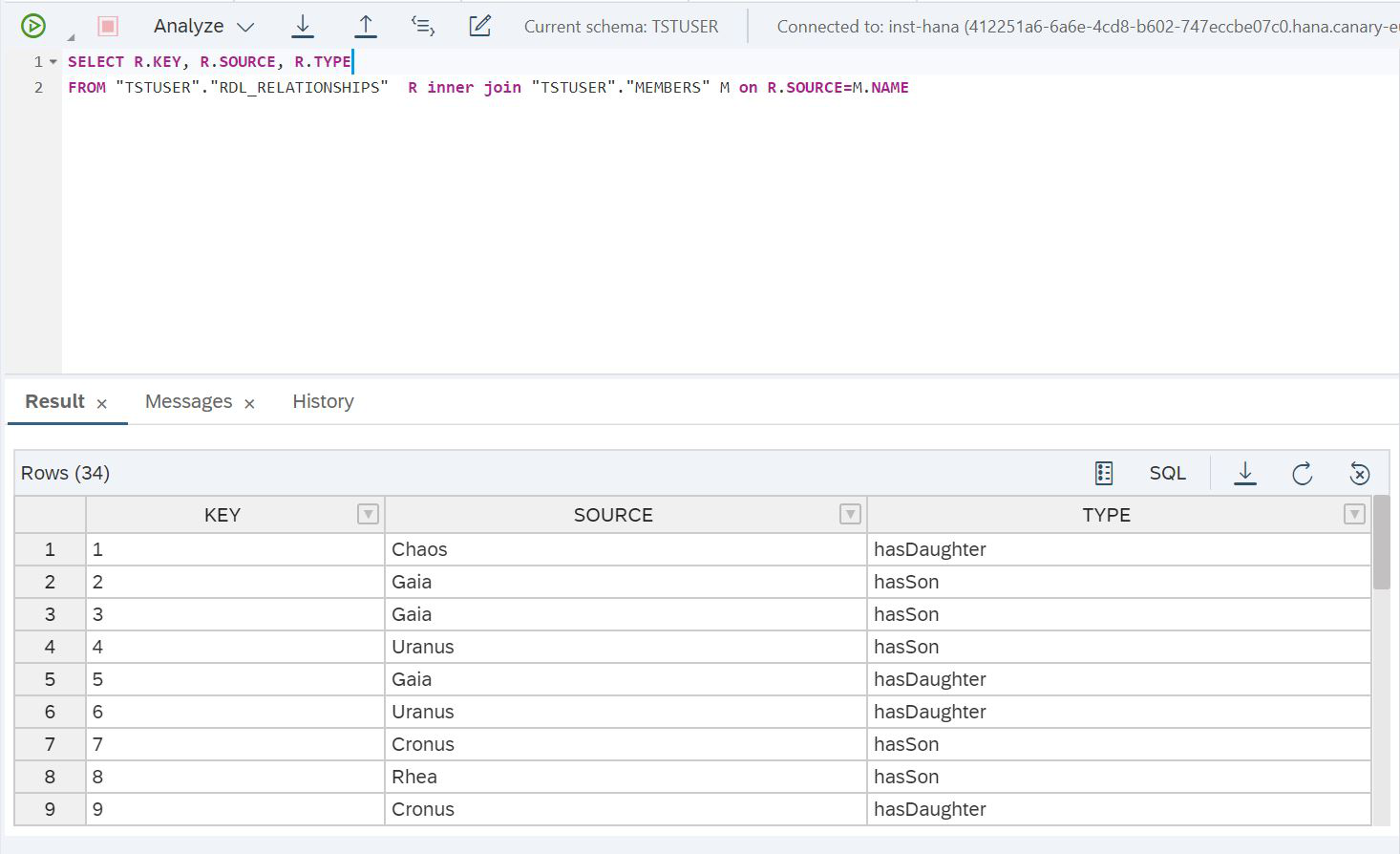
Figura 27
SCRIPT:
SELECT R.KEY, R.SOURCE, R.TYPE
FROM "TSTUSER"."RDL_RELATIONSHIPS" R inner join "TSTUSER"."MEMBERS" M on R.SOURCE=M.NAMEE vamos ver quanto tempo levou para concluir esta solicitação (Fig. 28).
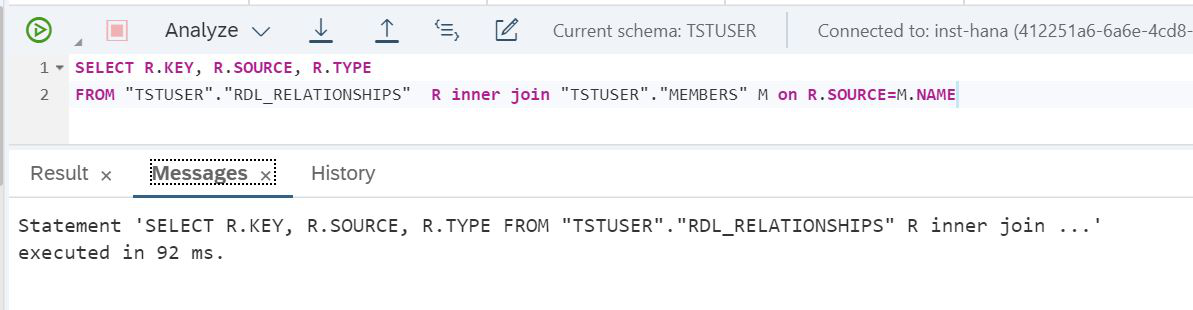
Figura 28
Podemos ver que demorou 92 milissegundos. Vamos ativar o mecanismo de replicação. Para fazer isso, você precisa criar ALTER VIRTUAL TABLE da tabela virtual, após a qual os dados do Lake serão replicados na RAM do SAP HANA.
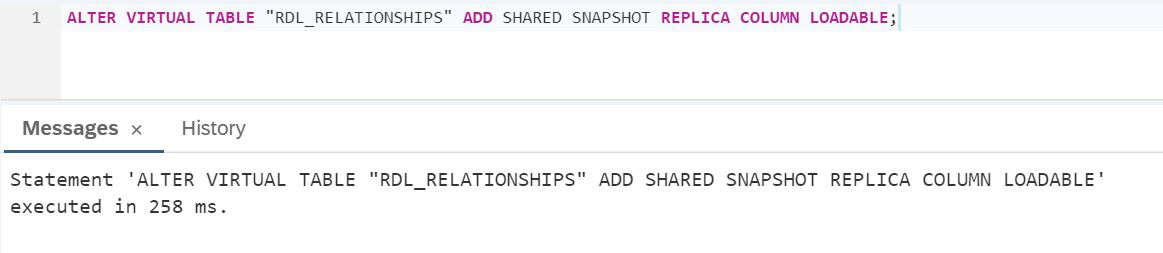
ROTEIRO:
ALTER VIRTUAL TABLE "RDL_RELATIONSHIPS" ADD SHARED SNAPSHOT REPLICA COLUMN LOADABLE;Vamos verificar o tempo de execução como na Figura 29.

Figura 29
Temos 7 milissegundos. Este é um ótimo resultado! Com o mínimo esforço, movemos os dados para a RAM. Além disso, se você concluiu a análise e está satisfeito com o desempenho, pode desativar a replicação novamente (Fig. 30).

Figura 30
SCRIPT:
ALTER VIRTUAL TABLE "RDL_RELATIONSHIPS" DROP REPLICA;Agora, os dados são novamente carregados do Lake somente sob demanda e a RAM do SAP HANA está livre para novas tarefas. Hoje, na minha opinião, fizemos um trabalho interessante e testamos o SAP HANA Cloud pela velocidade e organização fácil de um único ponto de acesso aos dados. O produto continuará evoluindo e esperamos uma conexão direta com o data lake no futuro próximo. O novo recurso fornecerá uma velocidade de download mais rápida de grandes quantidades de informações, rejeição de dados de serviço desnecessários e aumentará a produtividade das operações específicas do data lake. Criaremos e executaremos procedimentos armazenados diretamente na nuvem de dados usando a tecnologia SAP IQ, ou seja, poderemos aplicar lógica de processamento e de negócios onde os dados estão.
Alexander Tarasov, arquiteto de negócios sênior, SAP CIS