
Já existem algumas publicações sobre o coprocessador Apple Matrix (AMX). Mas a maioria não é muito clara para todos. Vou tentar explicar as nuances do coprocessador em uma linguagem compreensível.
Por que a Apple não está falando muito sobre esse coprocessador? O que há de tão secreto nisso? E se você leu sobre o motor neural no SoC M1, pode ter dificuldade em entender o que há de tão incomum no AMX.
Mas primeiro, vamos lembrar as coisas básicas ( se você sabe bem o que são matrizes, e tenho certeza de que há muitos desses leitores em Habré, então você pode pular a primeira seção, - aprox. Tradução ).
O que é uma matriz?
Para simplificar, esta é uma tabela com números. Se você trabalhou no Microsoft Excel, significa que lidou com a semelhança de matrizes. A principal diferença entre matrizes e tabelas comuns com números está nas operações que podem ser realizadas com elas, bem como em sua essência específica. A matriz pode ser pensada de muitas formas diferentes. Por exemplo, como strings, é um vetor linha. Ou como uma coluna, então é, logicamente, um vetor de coluna.

Podemos adicionar, subtrair, dimensionar e multiplicar matrizes. A adição é a operação mais simples. Você apenas adiciona cada item separadamente. A multiplicação é um pouco mais complicada. Aqui está um exemplo simples.
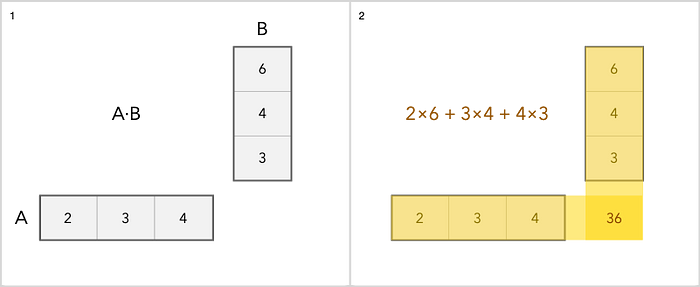
Quanto a outras operações com matrizes, você pode ler sobre isso aqui .
Por que estamos falando sobre matrizes?
O fato é que são amplamente utilizados em:
• Processamento de imagens.
• Aprendizado de máquina.
• Escrita à mão e reconhecimento de voz.
• Compressão.
• Trabalhe com áudio e vídeo.
Quando se trata de aprendizado de máquina, essa tecnologia requer processadores poderosos. E apenas adicionar alguns núcleos ao chip não é uma opção. Agora os kernels estão "afiados" para certas tarefas.

O número de transistores no processador é limitado, portanto, o número de tarefas / módulos que podem ser adicionados ao chip também é limitado. Em geral, você pode simplesmente adicionar mais núcleos ao processador, mas isso apenas irá acelerar os cálculos padrão que já são rápidos. Portanto, a Apple decidiu seguir um caminho diferente e destacar os módulos para processamento de imagens, decodificação de vídeo e tarefas de aprendizado de máquina. Esses módulos são coprocessadores e aceleradores.
Qual é a diferença entre o coprocessador Apple Matrix e o Neural Engine?
Se você estava interessado no Neural Engine, provavelmente sabe que ele também executa operações de matriz para trabalhar com problemas de aprendizado de máquina. Mas se sim, então por que você também precisa do coprocessador Matrix? Talvez seja a mesma coisa? Estou confundindo alguma coisa? Deixe-me esclarecer a situação e dizer qual é a diferença, explicando por que as duas tecnologias são necessárias.
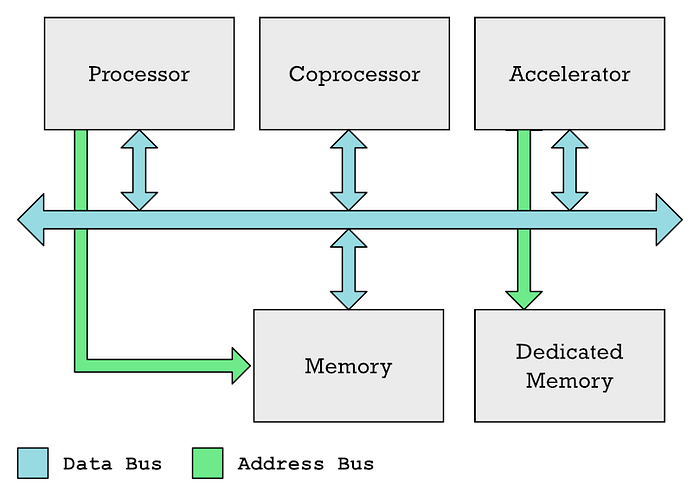
A unidade de processamento principal (CPU), coprocessadores e aceleradores geralmente podem se comunicar por meio de um barramento de dados comum. A CPU geralmente controla o acesso à memória, enquanto um acelerador como uma GPU geralmente tem sua própria memória dedicada.
Admito que em meus artigos anteriores usei os termos "coprocessador" e "aceleradores" alternadamente, embora não sejam a mesma coisa. Então, GPU e Neural Engine são diferentes tipos de aceleradores.
Em ambos os casos, você tem áreas especiais de memória que a CPU deve preencher com os dados que deseja processar, além de outra área de memória que a CPU preenche com uma lista de instruções que o acelerador deve executar. O processador leva tempo para concluir essas tarefas. Você tem que coordenar tudo isso, preencher os dados e então aguardar o recebimento dos resultados.
E esse mecanismo é adequado para tarefas de grande escala, mas para tarefas pequenas isso é um exagero.

Essa é a vantagem dos coprocessadores sobre os aceleradores. Os coprocessadores observam o fluxo de instruções do código de máquina que vêm da memória (ou em particular do cache) para a CPU. O coprocessador é forçado a responder às instruções específicas que foi forçado a processar. Enquanto isso, a CPU geralmente ignora essas instruções ou ajuda a torná-las mais fáceis de manipular pelo coprocessador.
A vantagem é que as instruções executadas pelo coprocessador podem ser incluídas no código normal. No caso da GPU, tudo é diferente - os programas shader são colocados em buffers de memória separados, que devem então ser explicitamente transferidos para a GPU. Você não poderá usar um código normal para isso. E é por isso que o AMX é ótimo para tarefas simples de processamento de matriz.
O truque aqui é que você precisa definir as instruções na arquitetura do conjunto de instruções (ISA) do seu microprocessador. Assim, ao usar um coprocessador, há uma integração mais estreita com o processador do que ao usar um acelerador.
Os criadores do ARM, a propósito, há muito resistem em adicionar instruções personalizadas ao ISA. E esta é uma das vantagens do RISC-V. Mas em 2019, os desenvolvedores desistiram, afirmando o seguinte: “As novas instruções são combinadas com as instruções ARM padrão. Para evitar a fragmentação de software e manter um ambiente de desenvolvimento de software consistente, a ARM espera que os clientes usem instruções personalizadas principalmente em chamadas de biblioteca. "
Esta pode ser uma boa explicação para a falta de descrição das instruções do AMX na documentação oficial. A ARM simplesmente espera que a Apple inclua instruções nas bibliotecas fornecidas pelo cliente (neste caso, a Apple).
Qual é a diferença entre um coprocessador de matriz e um SIMD vetorial?
Em geral, não é tão difícil confundir um coprocessador de matriz com a tecnologia SIMD vetorial, que é encontrada na maioria dos processadores modernos, incluindo ARM. SIMD significa Single Instruction Multiple Data.

O SIMD permite aumentar o desempenho do sistema quando você precisa realizar a mesma operação em vários elementos, o que está intimamente relacionado às matrizes. Em geral, as instruções SIMD, incluindo instruções ARM Neon ou Intel x86 SSE ou AVX, são freqüentemente usadas para acelerar a multiplicação de matrizes.
Mas o motor de vetor SIMD faz parte do núcleo do microprocessador, assim como ALU (Arithmetic Logic Unit) e FPU (Floating Point Unit) fazem parte da CPU. Bem, já o decodificador de instrução no microprocessador "decide" qual bloco funcional ativar.

Mas o coprocessador é um módulo físico separado e não faz parte do núcleo do microprocessador. Anteriormente, por exemplo, o 8087 da Intel era um chip separado destinado a acelerar as operações de ponto flutuante.

Você pode achar estranho que alguém desenvolva um sistema tão complexo, com um chip separado que processa os dados que vão da memória para o processador a fim de detectar uma instrução de ponto flutuante.
Mas o baú abre simplesmente. O fato é que o processador 8086 original tinha apenas 29.000 transistores. O 8087 já contava com 45.000 unidades, em última análise, as tecnologias permitiram a integração de FPUs no chip principal, dispensando coprocessadores.
Mas por que AMX não faz parte do núcleo M1 Firestorm não está totalmente claro. Talvez a Apple tenha simplesmente decidido mover elementos ARM não padrão para fora do processador principal.
Mas por que o AMX não é muito falado?
Se o AMX não está descrito na documentação oficial, como poderíamos descobrir sobre ele? Obrigado ao desenvolvedor Dougall Johnson, que fez uma engenharia reversa maravilhosa do M1 e descobriu o coprocessador. Seu trabalho é descrito aqui . No final das contas, a Apple criou bibliotecas e / ou estruturas especializadas como o Accelerate para operações matemáticas relacionadas a matrizes . Tudo isso inclui os seguintes elementos:
• vImage - processamento de imagem de nível superior, como conversão entre formatos, manipulação de imagens.
• BLASÉ uma espécie de padrão da indústria para álgebra linear (o que chamamos de matemática que trata de matrizes e vetores).
• BNNS - usado para executar redes neurais e treinar.
• vDSP - processamento de sinal digital. Transformadas de Fourier, convolução. Estas são operações matemáticas realizadas durante o processamento de uma imagem ou qualquer sinal contendo som.
• LAPACK - Funções de álgebra linear de nível superior , como resolver equações lineares.
Johnson entendeu que essas bibliotecas usariam o coprocessador AMX para acelerar os cálculos. Para isso, desenvolveu um software especializado para análise e monitoramento das ações da biblioteca. Por fim, ele conseguiu localizar instruções de código de máquina AMX não documentadas.
E a Apple não documenta tudo isso porque a ARM LTD. tenta não anunciar muita informação. O fato é que, se as funções personalizadas forem realmente amplamente utilizadas, isso pode levar à fragmentação do ecossistema ARM, conforme discutido acima.
A Apple tem a oportunidade, sem realmente anunciar tudo isso, mais tarde para alterar o funcionamento dos sistemas, se necessário - por exemplo, excluir ou adicionar instruções AMX. Para os desenvolvedores, a plataforma Accelerate é suficiente, o sistema fará o resto sozinho. Conseqüentemente, a Apple pode controlar o hardware e o software para ele.
Benefícios do coprocessador Apple Matrix
Há muito aqui, uma excelente visão geral das capacidades do elemento foi feita pela Nod Labs, que é especializada em aprendizado de máquina, inteligência e percepção. Em particular, eles realizaram testes de desempenho comparativos entre AMX2 e NEON.
Como se viu, AMX realiza as operações necessárias para realizar operações com matrizes duas vezes mais rápido. Isso não significa, é claro, que o AMX seja o melhor, mas para aprendizado de máquina e computação de alto desempenho - sim.
O resultado final é que o coprocessador da Apple é uma tecnologia impressionante que dá ao Apple ARM uma vantagem em aprendizado de máquina e computação de alto desempenho.
