
Os problemas que o aprendizado de máquina resolve hoje geralmente são complexos e incluem um grande número de recursos (recursos). Devido à complexidade e diversidade dos dados iniciais, o uso de modelos simples de aprendizado de máquina muitas vezes não permite atingir os resultados necessários, portanto, modelos complexos e não lineares são usados em casos reais de negócios. Esses modelos têm uma desvantagem significativa: devido à sua complexidade, é quase impossível ver a lógica pela qual o modelo atribuiu essa classe particular à operação da conta. A interpretabilidade do modelo é especialmente importante quando os resultados de seu trabalho precisam ser apresentados ao cliente - ele provavelmente desejará saber com base em quais critérios as decisões são tomadas para seu negócio.
, sklearn, xgboost, lightGBM (). , . , , ? ? , . SHAP. SHAP . , .
. , . 213 , .
kaggle .
:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()

, , , , .
, () , , . , , , .
.
:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()

, , . : ? . , , . , , SHAP. , , : 20 . 50 .
:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
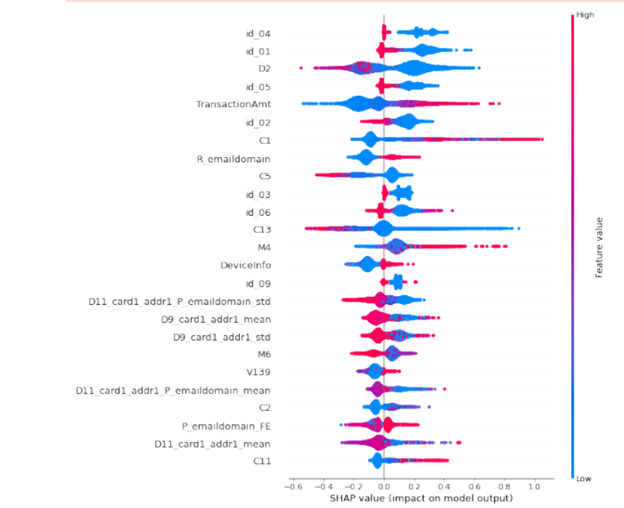
, . 2 . «0», «1». , . , . , , , : , , . , email.
Com base nos dados obtidos, é possível iluminar o modelo, ou seja, deixar apenas os parâmetros que têm impacto significativo nos resultados de predição do nosso modelo. Além disso, torna-se possível avaliar a importância dos recursos para determinados subgrupos de dados, por exemplo, clientes de diferentes regiões, transações em diferentes horários do dia, etc. Além disso, esta ferramenta pode ser usada para analisar casos individuais, para exemplo, para analisar "outliers" e valores extremos. SHAP também pode ajudar a encontrar zonas de queda ao classificar fenômenos negativos. Essa ferramenta, em combinação com outras abordagens, tornará os modelos mais leves, de melhor qualidade e os resultados interpretáveis.