
Foto de Richard Jacobs em Unsplash
Em novembro de 2020, iniciamos uma grande migração para atualizar nosso cluster PostgreSQL de 9.6 para 12.4. Neste post, vou dar uma rápida visão geral de nossa arquitetura no Coffee Meets Bagel, explicar como o tempo de inatividade do upgrade foi reduzido para menos de 30 minutos e compartilhar o que aprendemos ao longo do caminho.
Arquitetura
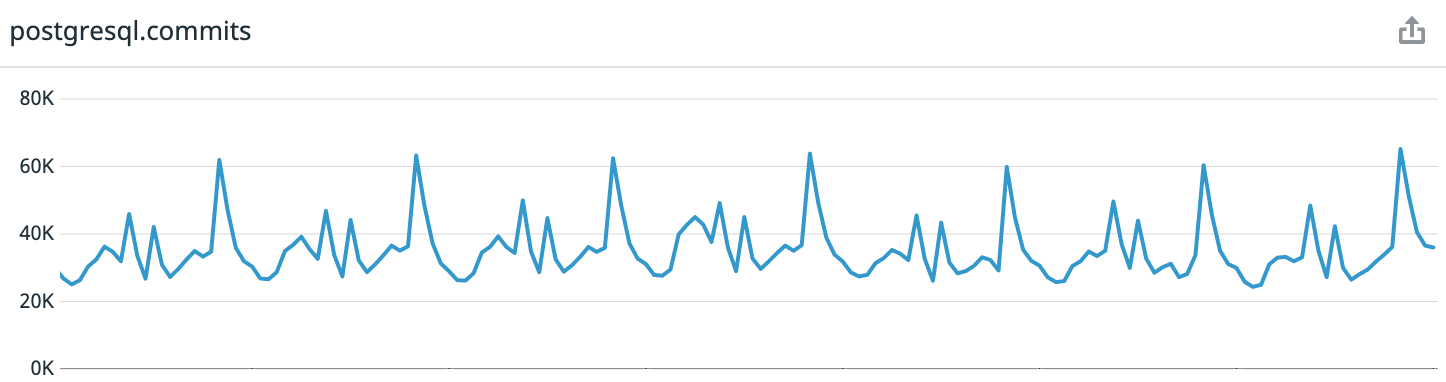
Para referência: Coffee Meets Bagel é um aplicativo de namoro romântico com um sistema de curadoria. Todos os dias, nossos usuários recebem um lote limitado de candidatos de alta qualidade ao meio-dia em seu fuso horário. Isso leva a padrões de carga altamente previsíveis. Se você olhar os dados da última semana desde o momento da redação do artigo, obtemos uma média de 30 mil transações por segundo, no pico - até 65 mil.
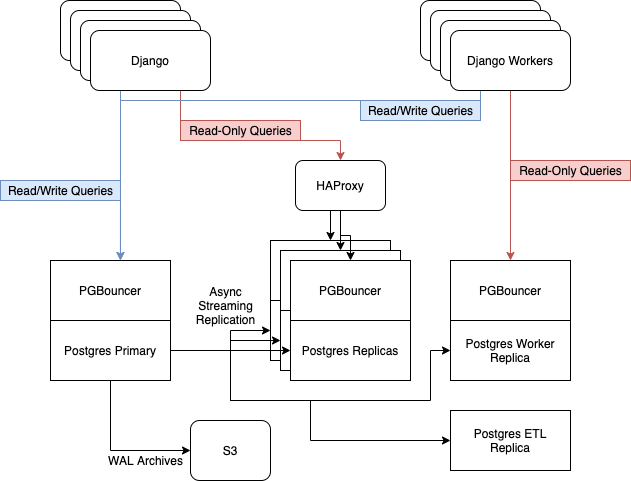
Antes da atualização, tínhamos 6 servidores Postgres em execução em instâncias i3.8xlarge na AWS. Eles continham um nó mestre, três réplicas para servir o tráfego da web somente leitura, balanceado com HAProxy, um servidor para trabalhadores assíncronos e um servidor para ETL [ Extract, Transform, Load ] e Business Intelligence....
Contamos com a replicação de streaming embutida do Postgres para manter nossa frota de réplicas atualizada.
Razões para o upgrade
Nos últimos anos, ignoramos visivelmente nossa camada de dados e, como resultado, ela está um pouco desatualizada. Especialmente muitas "muletas" foram pegas pelo nosso servidor principal - ele está online há 3,5 anos. Nós corrigimos várias bibliotecas e serviços do sistema sem parar o servidor.

Meu candidato ao subreddit r / uptimeporn
Como resultado, um monte de coisas estranhas se acumularam e deixam você nervoso. Por exemplo, novos serviços
systemd
não são iniciados. Tive que configurar o lançamento do agente
datadog
na sessão
screen
. Às vezes, o SSH parava de responder quando a carga do processador estava acima de 50% e o próprio servidor enviava regularmente solicitações de banco de dados.
E também o espaço livre no disco começou a se aproximar de valores perigosos. Como mencionei acima, o Postgres foi executado em instâncias i3.8xlarge no EC2 que têm 7,6 TB de armazenamento NVMe. Ao contrário do EBS, o tamanho do disco não pode ser alterado dinamicamente aqui - o que foi originalmente definido será. E preenchemos cerca de 75% do disco. Ficou claro que o tamanho da instância precisaria ser alterado para suportar o crescimento futuro.
Nossos requisitos
- Tempo de inatividade mínimo. Estabelecemos uma meta de 4 horas de tempo total de inatividade, incluindo interrupções não planejadas causadas por erros de atualização.
- Construa um novo cluster de banco de dados em novas instâncias para substituir a frota atual de servidores antigos.
- Vá para i3.16xlarge para espaço para crescer.
Conhecemos três maneiras de atualizar o Postgres: fazendo backup e restaurando a partir dele, pg_upgrade e replicação lógica pglógica.
Abandonamos imediatamente o primeiro método, restaurando a partir de um backup: para nosso conjunto de dados de 5,7 TB, demoraria muito. Com sua velocidade, o pg_upgrade não atendia aos requisitos 2 e 3: é uma ferramenta de migração na mesma máquina. Portanto, escolhemos a replicação lógica.
Nosso processo
Já foi escrito o suficiente sobre os principais recursos do pglógico. Portanto, em vez de repetir verdades comuns, simplesmente apresentarei artigos que se mostraram úteis para mim:
- Atualização de versão principal com tempo de inatividade mínimo ;
- Atualizando PostgreSQL de 9.4 para 10.3 com pglogical ;
- Desmistificando pglógico - Tutorial .
Criamos um novo servidor Postgres 12 primário e usamos o pglogical para sincronizar todos os nossos dados. Quando ele foi sincronizado e passou a replicar as mudanças recebidas, começamos a adicionar réplicas de streaming para ele. Depois de configurar a nova réplica de streaming, nós a incluímos no HAProxy e removemos uma da versão antiga 9.6.
Este processo continuou até que os servidores Postgres 9.6 fossem completamente desligados, exceto o mestre. A configuração assumiu o seguinte formato.

Depois foi a vez da troca de cluster (failover), para a qual solicitamos a janela de manutenção. O processo de mudança também está bem documentado na Internet, então falarei apenas sobre as etapas gerais:
- Transferência do site para a modalidade de trabalho técnico;
- Alterar os registros DNS do mestre para um novo servidor;
- Sincronização forçada de todas as sequências de chaves primárias;
- Início manual do ponto de verificação (
CHECKPOINT
) no antigo mestre. - No novo assistente - executando alguns procedimentos de validação e teste de dados;
- Habilitando o site.
No geral, a transição correu bem. Apesar dessas grandes mudanças em nossa infraestrutura, não houve tempo de inatividade não planejado.
Lições aprendidas
Com o sucesso geral da operação, alguns problemas foram encontrados ao longo do caminho. O pior deles quase matou nosso mestre Postgres 9.6 ...
Lição nº 1: a sincronização lenta pode ser perigosa
Vamos começar com um contexto: como funciona a linguagem pglógica? O processo do remetente no provedor (neste caso, nosso antigo wizard 9.6) decodifica o log WAL write-ahead, busca as alterações lógicas e as envia para o assinante.
Se o assinante ficar para trás, o provedor armazenará os segmentos do WAL para que, quando o assinante o alcançar, nenhum dado seja perdido.
Na primeira vez que uma tabela é adicionada ao fluxo de replicação, o pglogical deve primeiro sincronizar os dados da tabela. Isso é feito com o comando Postgres
COPY
. Depois disso, os segmentos WAL começam a se acumular no provedor para que as mudanças durante a operação
COPY
acabou sendo transferido para o assinante após a sincronização inicial, garantindo nenhuma perda de dados.
Na prática, isso significa que, ao sincronizar uma grande tabela em um sistema com uma carga pesada de gravação / alteração, você deve monitorar cuidadosamente o uso do disco. Na primeira tentativa de sincronizar nossa mesa maior (4 TB), a equipe e a operadora
COPY
trabalharam por mais de um dia. Durante esse tempo, o nó do fornecedor acumulou mais de um terabyte de logs WAL proativos.
Como você deve se lembrar do que foi dito, nossos antigos servidores de banco de dados tinham apenas dois terabytes de espaço livre em disco. Estimamos, com base na quantidade de disco do servidor do assinante, que apenas um quarto da tabela foi copiado. Portanto, o processo de sincronização teve que ser interrompido imediatamente - o disco no mestre teria terminado antes.
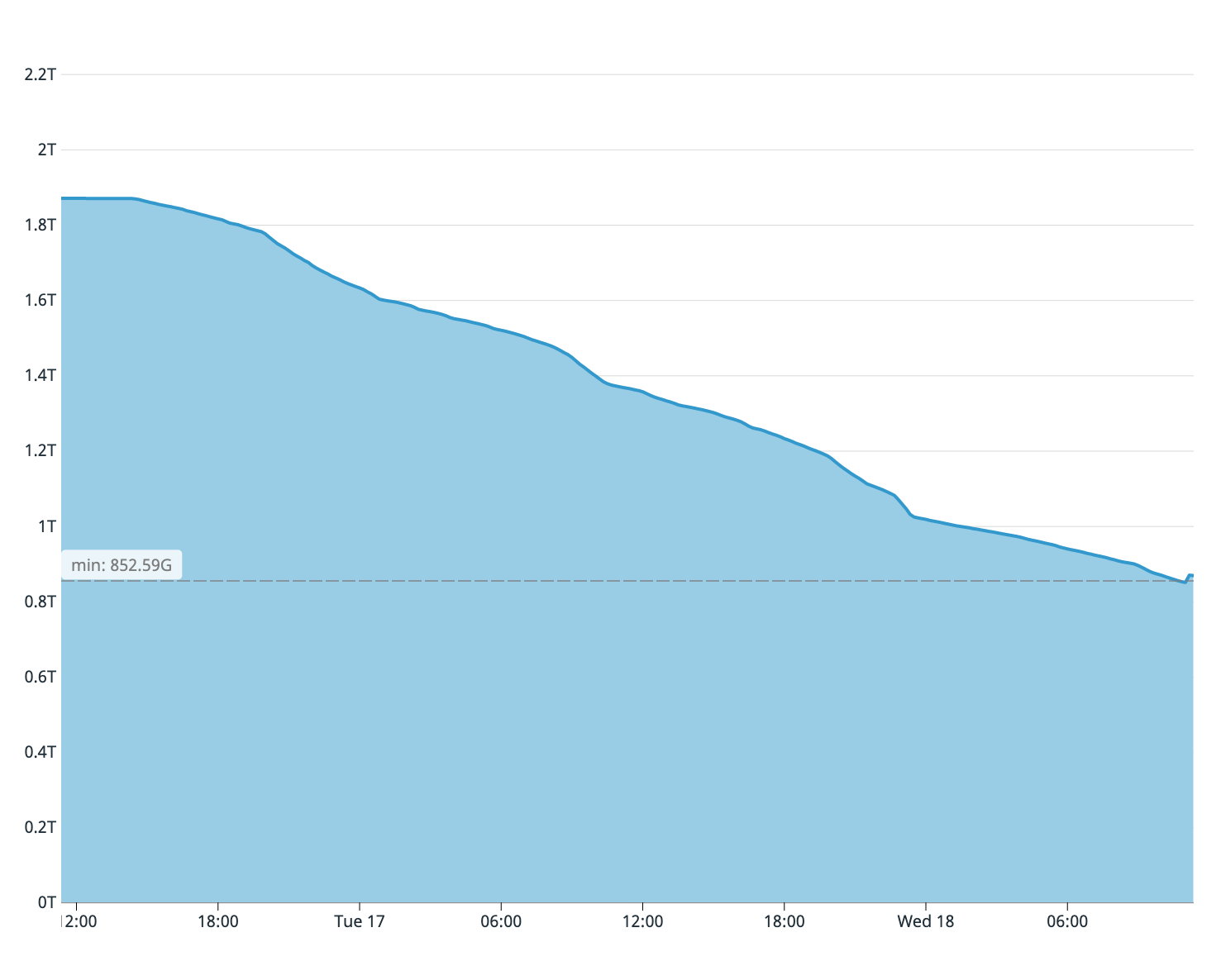
Espaço em disco disponível no assistente antigo na primeira tentativa de sincronização
Para acelerar o processo de sincronização, fizemos as seguintes alterações no banco de dados do assinante:
- Removidos todos os índices da tabela sincronizada;
fsynch
comutado paraoff
;- Alterado
max_wal_size
para50GB
; - Alterado
checkpoint_timeout
para1h
.
Essas quatro etapas aceleram significativamente o processo de sincronização no Assinante, e nossa segunda tentativa de sincronização da tabela é concluída em 8 horas.
Lição # 2: cada mudança de linha é registrada como um conflito
Quando o pglogical detecta um conflito, o aplicativo deixa uma "
CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote
" entrada nos logs .
No entanto, descobriu-se que cada alteração de linha processada pelo assinante era registrada como um conflito. Em algumas horas de replicação, o banco de dados do assinante deixou gigabytes de arquivos de log conflitantes.
Este problema foi resolvido definindo um parâmetro
pglogical.conflict_log_level = DEBUG
no arquivo
postgresql.conf
.
Sobre o autor
 Tommy Lee é engenheiro de software sênior da Coffee Meets Bagel. Antes disso, ele trabalhou para a Microsoft e Wave HQ, um fabricante canadense de sistemas de automação contábil.
Tommy Lee é engenheiro de software sênior da Coffee Meets Bagel. Antes disso, ele trabalhou para a Microsoft e Wave HQ, um fabricante canadense de sistemas de automação contábil.