A forma usual de paginação é por deslocamento ou número de página. Você faz uma solicitação como esta:
GET /api/products?page=10 {"items": [...100 products]}
e então este:
GET /api/products?page=11 {"items": [...another 100 products]}
No caso de um simples deslocamento, verifica-se
?offset=1000
e
?offset=1100
- os mesmos ovos, apenas de perfil. Aqui, vamos direto para a consulta SQL do tipo
OFFSET 1000 LIMIT 100
ou multiplicamos pelo tamanho da página (valor
LIMIT
). De qualquer forma, essa não é uma solução ideal, já que cada banco de dados tem que pular essas 1000 linhas. E para ignorá-los, você precisa identificá-los. Não importa se é PostgreSQL, ElasticSearch ou MongoDB, ele precisa ordenar, recalcular e jogá-los fora.
Este é um trabalho desnecessário. Mas ele se repete continuamente, já que esse design é fácil de implementar - você mapeia diretamente sua API para uma solicitação de banco de dados.
O que precisa ser feito? Podemos ver como os bancos de dados funcionam! Eles têm o conceito de cursor - é um ponteiro para uma string. Portanto, você pode dizer ao banco de dados: "Devolva 100 linhas depois disso ." E tal consulta é muito mais conveniente para o banco de dados, uma vez que existe uma grande probabilidade de você estar identificando uma linha por um campo com um índice. E você não precisa buscar e pular essas linhas, você passará por elas.
Exemplo:
GET /api/products {"items": [...100 products], "cursor": "qWe"}
A API retorna uma string (opaca), que pode ser usada para obter a próxima página:
GET /api/products?cursor=qWe {"items": [...100 products], "cursor": "qWr"}
Em termos de implementação, existem muitas opções. Normalmente, você tem alguns critérios de consulta, como a id do produto. Nesse caso, você o codifica com algum algoritmo reversível (digamos, identificadores hash ). E quando você recebe uma consulta com um cursor, você a decodifica e gera uma consulta como
WHERE id > :cursor LIMIT 100
.
Comparação de desempenho pequena. Aqui está o resultado do deslocamento: E aqui está o resultado da operação : Uma diferença de várias ordens de magnitude! Obviamente, os números reais dependem do tamanho da tabela, dos filtros e da implementação de armazenamento. Aqui está um ótimo artigo
=# explain analyze select id from product offset 10000 limit 100;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1114.26..1125.40 rows=100 width=4) (actual time=39.431..39.561 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1274406.22 rows=11437243 width=4) (actual time=0.015..39.123 rows=10100 loops=1)
Planning Time: 0.117 ms
Execution Time: 39.589 ms
where
=# explain analyze select id from product where id > 10000 limit 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..11.40 rows=100 width=4) (actual time=0.016..0.067 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1302999.32 rows=11429082 width=4) (actual time=0.015..0.052 rows=100 loops=1)
Filter: (id > 10000)
Planning Time: 0.164 ms
Execution Time: 0.094 ms
para obter mais informações técnicas, consulte o slide 42 para comparação de desempenho.
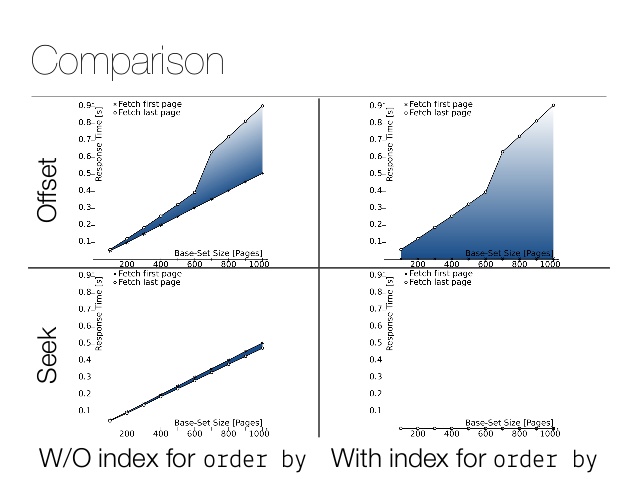
Obviamente, ninguém consulta produtos por ID - eles geralmente são consultados quanto a algum tipo de relevância (e então ID como um parâmetro decisivo ). No mundo real, a escolha de uma solução requer a observação de dados específicos. Os pedidos podem ser ordenados por identificador (visto que aumenta monotonicamente). Os itens da lista de compras futuras também podem ser classificados desta forma - no momento em que a lista foi compilada. No nosso caso, os produtos são carregados do ElasticSearch, que naturalmente suporta esse cursor.
A desvantagem é que você não pode criar um link de página anterior usando a API sem estado. No caso da paginação do usuário, não há como contornar esse problema. Portanto, se for importante ter botões para a página anterior / seguinte e "Ir diretamente para a página 10", será necessário usar o método antigo. Mas em outros casos, o método por cursor pode melhorar significativamente o desempenho, especialmente em tabelas muito grandes com paginação muito profunda.