
Simulador de injeção de falha AWS (FIS)- uma ferramenta que permite implementar cenários previamente conhecidos de falha interna do sistema nos serviços da AWS. Pelo que? - para que as equipes possam traçar cenários para sua eliminação e, em geral, avaliar o comportamento de seu produto nas condições propostas. O sistema oferecerá imediatamente vários modelos com cenários de falha, por exemplo, lentidão dos servidores, sua falha, erro de acesso ao banco de dados ou travamento. Ao mesmo tempo, o FIS garantirá que o experimento não vá muito longe e, quando certos parâmetros forem alcançados, o teste será interrompido e o sistema voltará ao normal. O principal slogan do novo produto da gigante da nuvem é "aumentar a resiliência e o desempenho usando a tecnologia do caos controlado". O lançamento do novo sistema de testes está programado para 2021.
A AWS também oferece testes e sistemas virtualizados distribuídos que são menos dependentes de um único host. A especificidade de uma falha em um sistema distribuído é que o problema pode ser cíclico e ter uma estrutura mais complexa. O novo recurso da AWS permitirá que você pesquise vulnerabilidades não apenas na infraestrutura de monólitos, mas também em sistemas e aplicativos distribuídos.
Vamos ver por que isso é importante e legal.
A engenharia do caos é um processo de teste de simulação em que o principal golpe no sistema vem de dentro e afeta a infraestrutura do projeto. A equipe simula situações em que a parte de infraestrutura do projeto se depara com problemas técnicos e outros, por exemplo, com um ponto ou diminuição sistêmica de desempenho nas instâncias. Isso também pode incluir travamentos de servidor, falhas de API e outros pesadelos de back-end que a equipe pode enfrentar a qualquer momento ou, pior ainda, no dia em que a próxima versão for lançada.
Ainda não há uma definição inequívoca de engenharia do caos, então aqui estão algumas das opções mais populares e, em nossa opinião, precisas. A engenharia do caos é: "uma abordagem que envolve experimentar com um sistema de produção para garantir que ele possa suportar vários distúrbios que ocorrem durante a operação" e "um experimento para mitigar os efeitos da falha".
Por que o AWS Fault Injection Simulator é necessário
Os desenvolvedores da ferramenta citam vários motivos pelos quais o FIS será útil para as equipes ao testar e preparar seus sistemas.
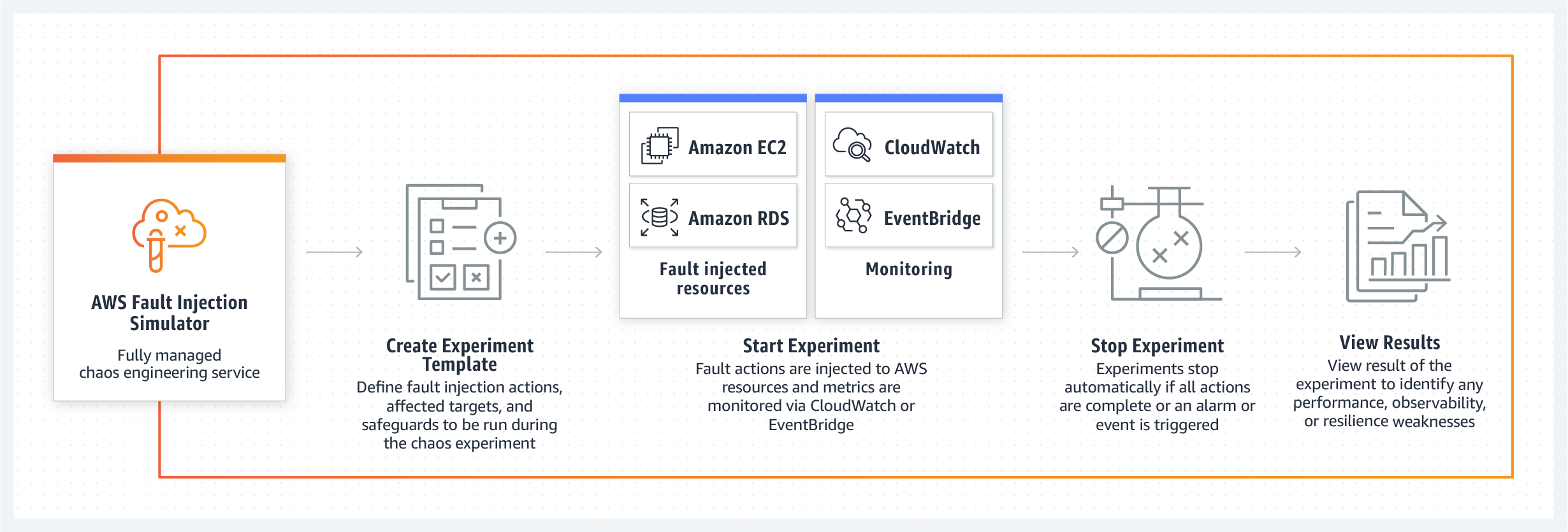
Desempenho do sistema, resiliência e transparência são uma das mensagens principais da equipe AWS FIS.
AWS Fault Injection Simulator , , «» , .
Na verdade, os métodos de teste usuais são, em primeiro lugar, a simulação da carga externa no sistema. Por exemplo, simular um efeito habra ou um ataque DDoS externo em um sistema ou serviço. Na maioria das vezes, todos os principais sistemas de monitoramento estão ligados precisamente a esses nós, enquanto o rastreamento do comportamento da infraestrutura interna, muitas vezes, é limitado apenas a receber dados no estilo "down / down" ou a carga na CPU. Ao mesmo tempo, os maiores danos e as falhas mais poderosas dos últimos anos estão associados precisamente a falhas internas ou erros de infraestrutura. Basta lembrar o crash do CloudFlare no ano passado, quando, devido a uma série de falhas e erros, os desenvolvedores literalmente forçaram metade da Internet a “deitar-se” com suas próprias mãos.
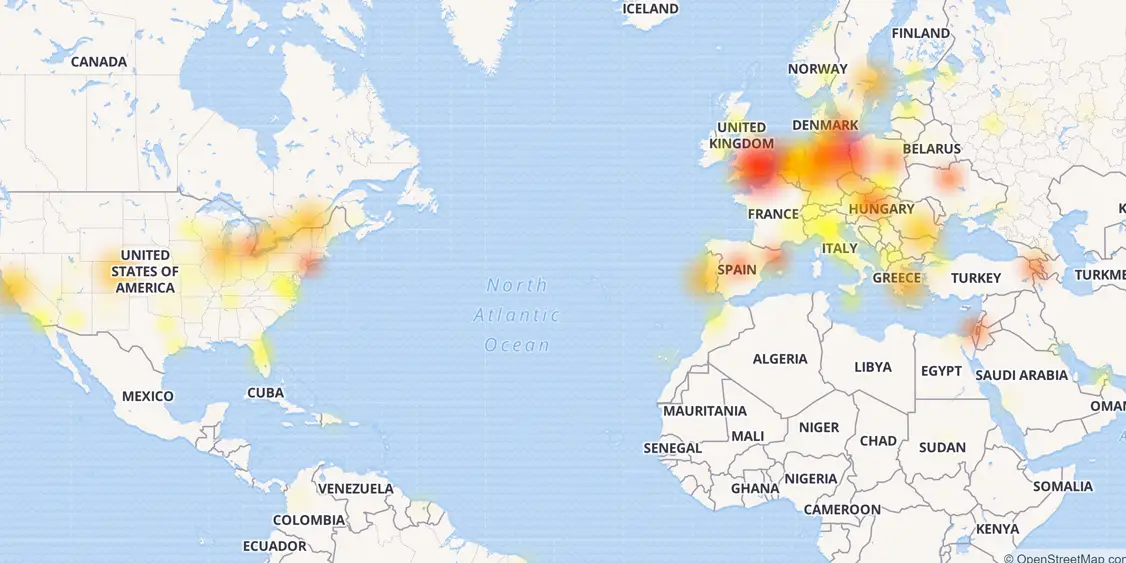
Mapa dessa falha CloudFlare
A nova ferramenta é capaz de trabalhar com modelos prontos para cenários de falha de banco de dados, API ou degradação de desempenho, bem como criar condições de teste cego aleatório em que problemas ocorrerão em uma sequência arbitrária em nós diferentes.
Outro ponto forte do novo kit de ferramentas AWS é a capacidade de controle do caos criado pela equipe no sistema. Os engenheiros garantem que, com a ajuda de seu painel de controle, os desenvolvedores podem interromper um cenário de falha controlada a qualquer momento e retornar o sistema ao seu estado original de funcionamento. O Fault Injection Simulator oferece suporte ao Amazon CloudWatch e a ferramentas de monitoramento de terceiros conectadas por meio do Amazon EventBridge, para que os desenvolvedores possam usar suas métricas para monitorar experimentos de caos controlados. Bem, e, claro, após a interrupção do teste, o administrador receberá um relatório completo sobre quais nós do sistema e em que sequência foram afetados pela falha, que no futuro ajudará a desenvolver um conjunto de medidas e procedimentos para localizar e eliminar problemas.
Como os Senhores do Caos se originaram
Obviamente, esses testes de estresse do sistema são mais lógicos de serem realizados no período de pré-lançamento, a fim de garantir que a infraestrutura existente na AWS resistirá ao novo patch. Porém, na verdade, a técnica da engenharia do caos remonta a práticas mais antigas, cujo fundador é um dos gerentes da Amazon nos anos 2000, Jesse Robbins. Sua posição foi oficialmente chamada de "Mestre do Desastre", que em uma tradução patética pode ser confundida com "Senhor das Catástrofes", e em sua linguagem livre sua posição soava como "Mestre Lomaster".
 Foi Robbins - um ex-bombeiro / trabalhador de resgate - que
implementou o GameDay na Amazon... O objetivo da iniciativa Robbins era muito simples - fornecer às equipes de engenharia uma compreensão intuitiva de como lidar com um desastre, muito parecido com a sensação de treinamento em brigadas de incêndio. Foi para isso que o método de simulação global do caos total foi escolhido: tudo se quebra por todos os lados, simultânea ou sequencialmente, e cada tentativa de lidar com o fracasso leva a novos e novos problemas.
Foi Robbins - um ex-bombeiro / trabalhador de resgate - que
implementou o GameDay na Amazon... O objetivo da iniciativa Robbins era muito simples - fornecer às equipes de engenharia uma compreensão intuitiva de como lidar com um desastre, muito parecido com a sensação de treinamento em brigadas de incêndio. Foi para isso que o método de simulação global do caos total foi escolhido: tudo se quebra por todos os lados, simultânea ou sequencialmente, e cada tentativa de lidar com o fracasso leva a novos e novos problemas.
Quando uma pessoa despreparada se depara com a confusão dos elementos, ela, na maioria das vezes, cai em estupor ou em pânico. A maioria dos desenvolvedores e engenheiros não está psicologicamente pronta para uma situação em que a solução de um problema deve levar três dias e o nível de estresse ao redor está simplesmente fora da escala.
Robbins chama o resultado mais importante do GameDay de efeito psicológico de tais exercícios: eles desenvolvem a capacidade de aceitar o fato de que ocorrem interrupções em grande escala . É a aceitação do fato de que tudo ao seu redor está queimando e desmoronando, ele considera muito importante para o engenheiro, para que ele pudesse se recompor e finalmente começar a “apagar o fogo”. Uma pessoa não treinada irá, na melhor das hipóteses, correr em círculos e gritar "tudo está perdido".
Após a implementação da prática GameDay, descobriu-se que tais exercícios identificam perfeitamente problemas de arquitetura e gargalos que não são prestados atenção durante os testes clássicos e verificação.
Outra diferença significativa entre o GameDay e nossos exercícios usuais de "treinamento e ordem" é que poucas pessoas sabem o cenário específico e o que acontecerá em geral. As informações sobre os próximos "jogos" são fornecidas de forma muito geral e vaga, de modo que os participantes não puderam se preparar totalmente para este evento. Idealmente - anunciar apenas a data do próximo "dia do jogo" sem nenhum esclarecimento, apenas para que os participantes não confundam com um acidente real. É claro que essa metodologia não se aplica a uma grande empresa, por exemplo, GameDay não pode ser executado em todo Yandex ou Microsoft de uma vez.
Como resultado, a prática foi atualizada para o GameDay local e introduzida em todas as grandes empresas de TI existentes, por exemplo, Google, Flickr e muitos outros. Tem os seus próprios Masters of Disasters (bem, ou Master-Lommasters, como quiser), que organizam as falhas de formação e depois analisam os resultados obtidos em projectos específicos.
A principal dificuldade em implementar esta prática em todos os lugares reside em dois aspectos: como organizá-la e como coletar dados para que o GameDay não seja em vão. É por isso que, em empresas menores, essa técnica não era amplamente usada até recentemente (se é que foi usada). Em vez de GameDay e simulação de desastres, a empresa se concentrou mais em diferentes tipos de teste, CI / CD e outras metodologias para desenvolvimento ordenado e consistente. Ou seja, sobre o que evita a catástrofe como tal.
O novo kit de ferramentas da AWS permitirá que você enfrente o outro lado da interrupção: em vez de prevenção, o que é sem dúvida importante, o FIS permitirá que equipes de engenharia de todos os tamanhos treinem com eficácia para resolver interrupções na infraestrutura global. Afinal, a principal coisa que Robbins observa é que os desastres acontecem de qualquer maneira: eles não podem ser evitados.