
Existem muitas abordagens para construir o código do aplicativo para evitar que a complexidade do projeto cresça com o tempo. Por exemplo, a abordagem orientada a objetos e muitos padrões anexados permitem, se não manter a complexidade do projeto no mesmo nível, pelo menos mantê-lo sob controle durante o desenvolvimento e disponibilizar o código para o novo programador da equipe.
Como você pode gerenciar a complexidade de um projeto de transformação ETL no Spark?
Não é tão simples assim.
Como é na vida real? O cliente se oferece para criar um aplicativo que coleta uma vitrine. Parece ser necessário executar o código através do Spark SQL e salvar o resultado. Durante o desenvolvimento, descobriu-se que construir este mart requer 20 fontes de dados, das quais 15 são semelhantes, o resto não. Essas fontes devem ser combinadas. Então, acontece que para metade deles, você precisa escrever seus próprios procedimentos de montagem, limpeza e normalização.
E uma vitrine simples, após uma descrição detalhada, começa a se parecer com isto:
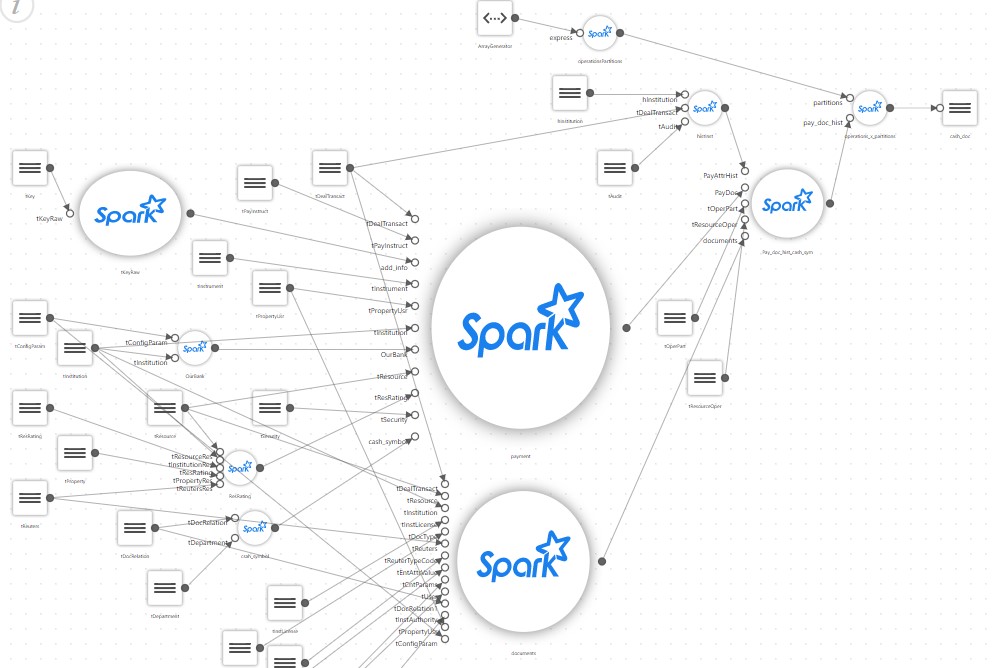
Como resultado, um projeto simples que deveria ter executado apenas um script SQL que coleta a vitrine no Spark adquire seu próprio configurador, um bloco para ler um grande número de arquivos de configuração, seu próprio branch de mapeamento, tradutores de algumas regras especiais etc.
No meio do projeto, verifica-se que apenas o autor pode suportar o código resultante. E ele passa a maior parte do tempo pensando. Enquanto isso, o cliente pede para coletar mais algumas vitrines e novamente com base em centenas de fontes. Ao mesmo tempo, devemos lembrar que o Spark geralmente não é muito adequado para criar suas próprias estruturas.
Por exemplo, o Spark foi projetado para fazer o código parecer algo assim (pseudocódigo):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)
Em vez disso, você deve fazer algo assim:
var Source1 = readSourceProps(“source1”) var sql = readSQL(“destTable”) writeSparkData(source1, sql)
Ou seja, mover blocos de código para procedimentos separados e tentar escrever algo próprio, universal, que pode ser personalizado por configurações.
Ao mesmo tempo, a complexidade do projeto permanece no mesmo nível, é claro, mas apenas para o autor do projeto, e apenas por um curto período de tempo. Qualquer programador convidado levará muito tempo para dominar, e o principal é que não funcionará atrair para o projeto pessoas que só conhecem SQL.
Isso é lamentável, já que o próprio Spark é uma ótima maneira de desenvolver aplicativos ETL para quem só conhece SQL.
E no decorrer do desenvolvimento do projeto, descobriu-se que uma coisa simples se transformou em algo complexo.
Agora imagine um projeto real, onde existem dezenas, ou mesmo centenas, de vitrines como na imagem, e eles usam tecnologias diferentes, por exemplo, algumas delas podem ser baseadas na análise de dados XML e outras em dados de streaming.
Eu gostaria de, de alguma forma, manter a complexidade do projeto em um nível aceitável. Como isso pode ser feito?
A solução pode ser usar uma abordagem de ferramenta e baixo código, quando o ambiente de desenvolvimento decidir por você, o que assume toda a complexidade, oferecendo alguma abordagem conveniente, como, por exemplo, descrito neste artigo .
Este artigo descreve as abordagens e os benefícios do uso da ferramenta para resolver esses tipos de problemas. Em particular, Neoflex oferece sua própria solução Neoflex Datagram, que é usado com sucesso por diferentes clientes.
Mas nem sempre é possível usar esse aplicativo.
O que fazer?
Neste caso, usamos uma abordagem que é convencionalmente chamada de Orc - Object Spark, ou Orka, como você preferir.
Os dados iniciais são os seguintes:
Há um cliente que fornece um local de trabalho onde há um conjunto padrão de ferramentas, a saber: Hue para desenvolver código Python ou Scala, editores de Hue para depuração de SQL por meio de Hive ou Impala e também Editor de fluxo de trabalho Oozie. Isso não é muito, mas o suficiente para resolver problemas. É impossível adicionar algo ao ambiente, é impossível instalar novas ferramentas, por vários motivos.
Então, como você desenvolve aplicativos ETL que, como de costume, crescerão em um grande projeto, no qual centenas de tabelas de fonte de dados e dezenas de mercados de destino estarão envolvidos, sem se afogar em complexidade e sem escrever muito?
Uma série de providências são usadas para resolver o problema. Eles não são invenção deles, mas são inteiramente baseados na arquitetura do próprio Spark.
- Todas as junções, cálculos e transformações complexas são feitos por meio do Spark SQL. O otimizador do Spark SQL melhora a cada versão e funciona muito bem. Portanto, damos todo o trabalho de cálculo do Spark SQL ao otimizador. Ou seja, nosso código depende da cadeia SQL, onde a etapa 1 prepara os dados, a etapa 2 se junta, a etapa 3 calcula e assim por diante.
- Spark, Spark SQL. (DataFrame) Spark SQL.
- Spark Directed Acicled Graph, , , , , 2, 2.
- Spark lazy, , , .
Como resultado, todo o aplicativo pode ser muito simples.
Basta fazer um arquivo de configuração para definir uma lista de fontes de dados de nível único. Essa lista sequencial de fontes de dados é o objeto que descreve a lógica de todo o aplicativo.
Cada fonte de dados contém um link para SQL. No SQL, para a fonte atual, você pode usar uma fonte que não está no Hive, mas descrita no arquivo de configuração acima do atual.
Por exemplo, a fonte 2, quando traduzida para o código Spark, se parece com isto (pseudocódigo):
var df = spark.sql(“select * from t1”); df.saveAsTempTable(“source2”);
E a fonte 3 já pode ser assim:
var df = spark.sql(“select count(*) from source2”) df.saveAsTempTable(“source3”);
Ou seja, a fonte 3 vê tudo o que foi calculado antes dela.
E para as fontes que são showcases de destino, você deve especificar os parâmetros para salvar este showcase de destino.
Como resultado, o arquivo de configuração do aplicativo se parece com este:
[{name: “source1”, sql: “select * from t1”}, {name: “source2”, sql: “select count(*) from source1”}, ... {name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]
E o código do aplicativo se parece com isto:
List = readCfg(...) For each source in List: df = spark.sql(source.sql).saveAsTempTable(source.name) If(source.target == true) { df.write(“format”, source.format).save(source.path) }
Este é, de fato, todo o aplicativo. Nada mais é necessário, exceto por um momento.
Como depurar tudo isso?
Afinal, o próprio código nesse caso é muito simples, o que há para depurar, mas seria bom verificar a lógica do que está sendo feito. A depuração é muito simples - você deve passar por todos os aplicativos até a fonte que está sendo verificada. Para fazer isso, você precisa adicionar um parâmetro ao fluxo de trabalho do Oozie que permite interromper o aplicativo na fonte de dados necessária, imprimindo seu esquema e conteúdo no log.
Chamamos essa abordagem de Object Spark no sentido de que toda a lógica do aplicativo é desacoplada do código Spark e armazenada em um único arquivo de configuração bastante simples, que é o objeto de descrição do aplicativo.
O código permanece simples e, uma vez criado, até mesmo vitrines complexas podem ser desenvolvidas usando programadores que conhecem apenas SQL.
O processo de desenvolvimento é muito simples. No início, um programador Spark experiente está envolvido, que cria o código universal e, em seguida, o arquivo de configuração do aplicativo é editado adicionando-se novas fontes.
O que essa abordagem oferece:
- Você pode envolver programadores SQL no desenvolvimento;
- Dado o parâmetro no Oozie, depurar tal aplicativo se torna fácil e simples. Esta é a depuração de qualquer etapa intermediária. O aplicativo irá trabalhar tudo para a fonte desejada, calcule e pare;
- ( … ), , , , , . , Object Spark;
- , . . , , , XML JSON, -. , ;
- . , , , , .