
Hoje vamos falar sobre um tópico aparentemente simples, como dados relacionais e relacionados.
Apesar de toda a sua simplicidade, noto que às vezes as pessoas ficam realmente confusas sobre eles - decidi corrigir isso escrevendo uma explicação curta e informal do que são e por que são necessários.
Discutiremos o que é o modelo relacional e o SQL relacionado e a álgebra relacional. Em seguida, vamos passar a exemplos de dados relacionados do Wikidat e, em seguida, RDF, SPARQL e uma pequena conversa sobre Datalog e representação lógica de dados. No final, as conclusões - quando aplicar o modelo relacional e quando o lógico coerente.
O principal objetivo da nota é descrever quando faz sentido aplicar o quê e por quê. Como há muitos conceitos difíceis convergentes em um só lugar, então é claro que seria possível escrever um livro para cada um - mas nossa tarefa hoje é dar uma ideia do tema e vamos analisá-lo informalmente usando exemplos simples.
Se você tiver alguma dúvida sobre como um difere do segundo e por que precisa de dados vinculados (LinkedData), seja bem-vindo em cat.

Dados relacionais
Vamos começar com uma definição
padrão.Um banco de dados relacional é uma coleção de dados com relacionamentos predefinidos entre eles. Esses dados são organizados como um conjunto de tabelas que consistem em colunas e linhas. As tabelas armazenam informações sobre os objetos representados no banco de dados.
Quando aplicado:
- Modelagem de domínio fixo
- O esquema de dados muda pouco ou as mudanças afetam imediatamente um grupo significativo de registros
- Consultas básicas - categorias de filtragem por campos-chave de registros, agregação, geração de relatórios e análises com base em indicadores estatísticos, etc.
Nessa situação, a unidade de modelagem é a tabela e os relacionamentos entre as tabelas (como chaves estrangeiras). Na verdade, uma tabela é um predicado com atributos fixos, ou seja, sempre sabemos a aridade de um predicado tabular.
Vamos tomar uma chave estrangeira como um exemplo de relações de restrição: a chave “p (_, X, _) → q (_, Y, _)”, que define restrições na forma X \ subconjunto Y, onde X é um atributo da relação p e Y atributo de relacionamento q.

Mais importante ainda, no mundo dos dados relacionais, temos tudo uma mesa! E as operações usam uma tabela como entrada e retornam uma tabela, por exemplo:

Linguagem de dados relacionais: SQL e álgebra relacional
A álgebra relacional (álgebra de Codd) é essencialmente um conjunto de operações em tabelas que retornam tabelas. Ou seja, para você, o elemento central da modelagem são justamente as tabelas fixas e suas transformações.
A linguagem SQL é uma superestrutura declarativa e implementação concreta das idéias da álgebra relacional.
Um exemplo de uma consulta simples e os operadores relacionais correspondentes da álgebra.

Até agora, tudo o que cobrimos são as coisas clássicas que sabemos de qualquer curso de banco de dados.
Dados vinculados e gráficos de conhecimento
Vamos apenas imaginar o que acontecerá se tivermos novas propriedades e isso acontecer, talvez em tempo real? Ou seja, o domínio não é fixo - mas flexível e extensível ?
Em tal situação, é claro, podemos adicionar tabelas e colunas às tabelas injetando NULL ou valores padrão. Mas além de ser tecnicamente inconveniente, também não é uma ferramenta adequada do ponto de vista de modelagem.
Imagine que você está modelando a vida das pessoas em todos os seus aspectos possíveis. Mesmo duas pessoas diferentes terão um conjunto bastante diferente de propriedades-chave e isso é absolutamente normal!
Você não tem uma lista fixa de como um personagem em particular será descrito. O Escritor e o Jogador de Futebol são duas Pessoas que possuem muitas propriedades importantes, mas, no entanto, diferentes.
Vamos começar com o escritor Douglas Adams - as propriedades principais são bem típicas para qualquer pessoa - aqui e abaixo usaremos o Wikidata como um exemplo de LinkedData.
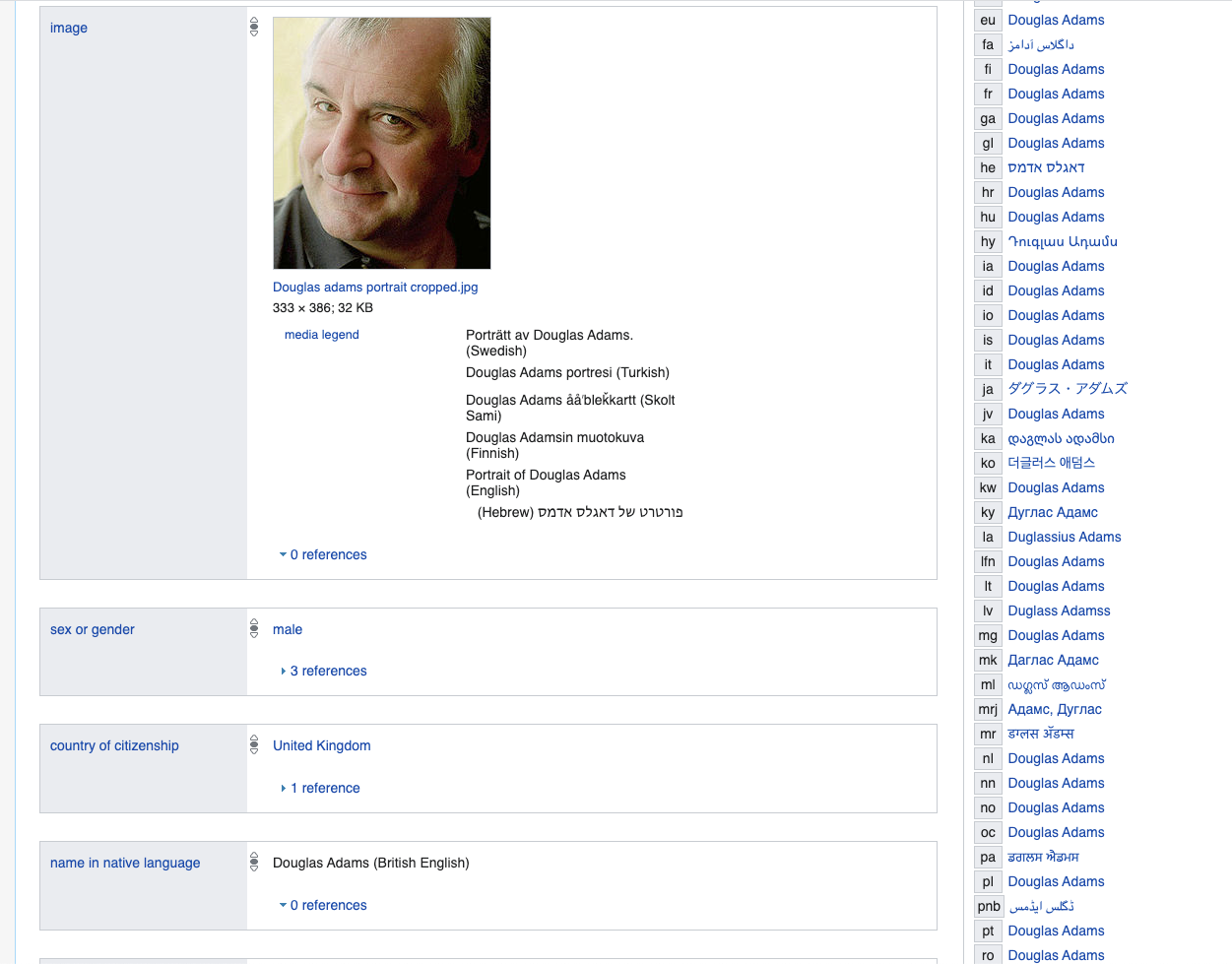
www.wikidata.org/wiki/Q42
Mas vamos cavar um pouco mais fundo e
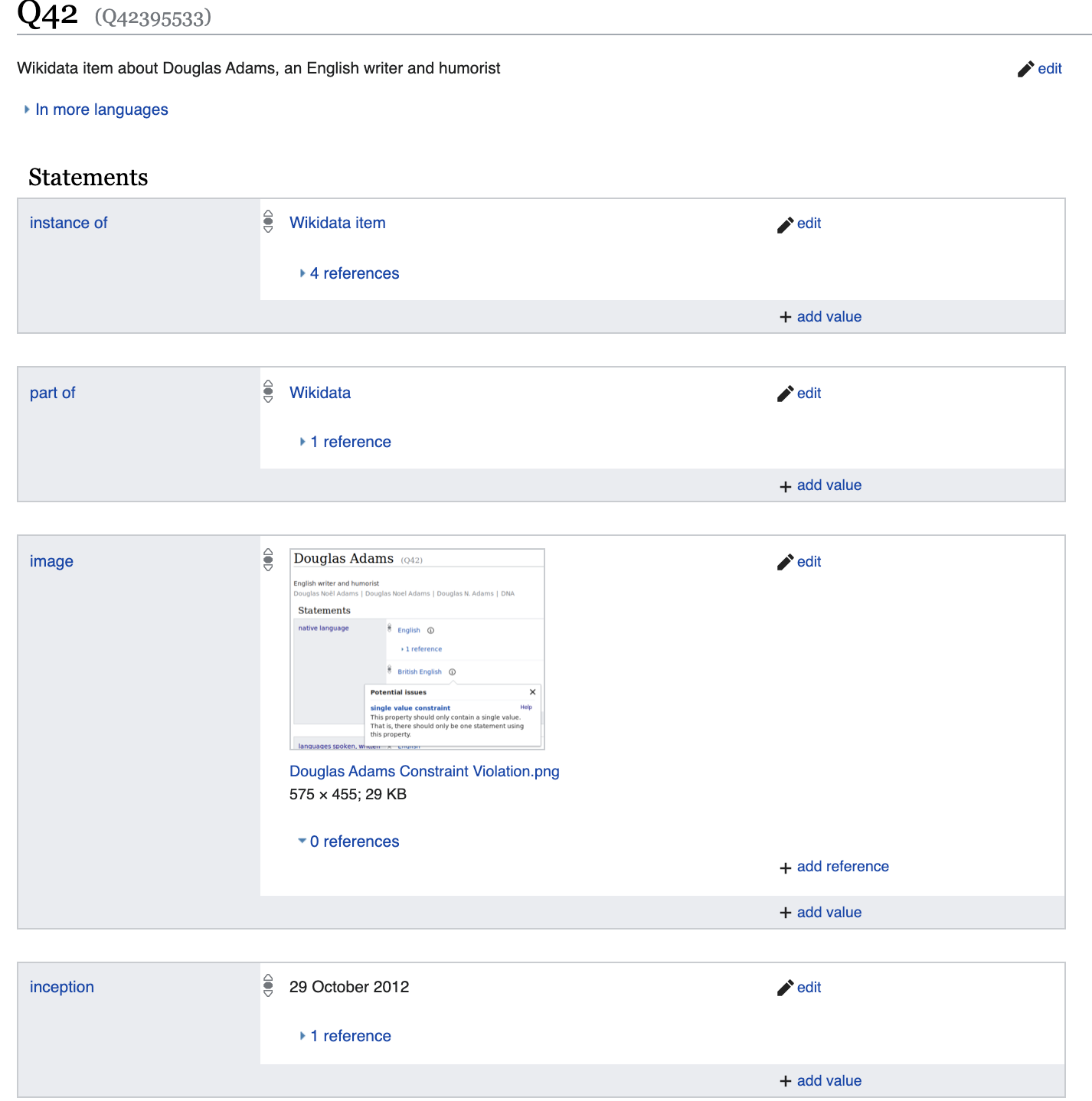
ver um conjunto de propriedades que serão significativamente diferentes, por exemplo, de Diego Maradonna.
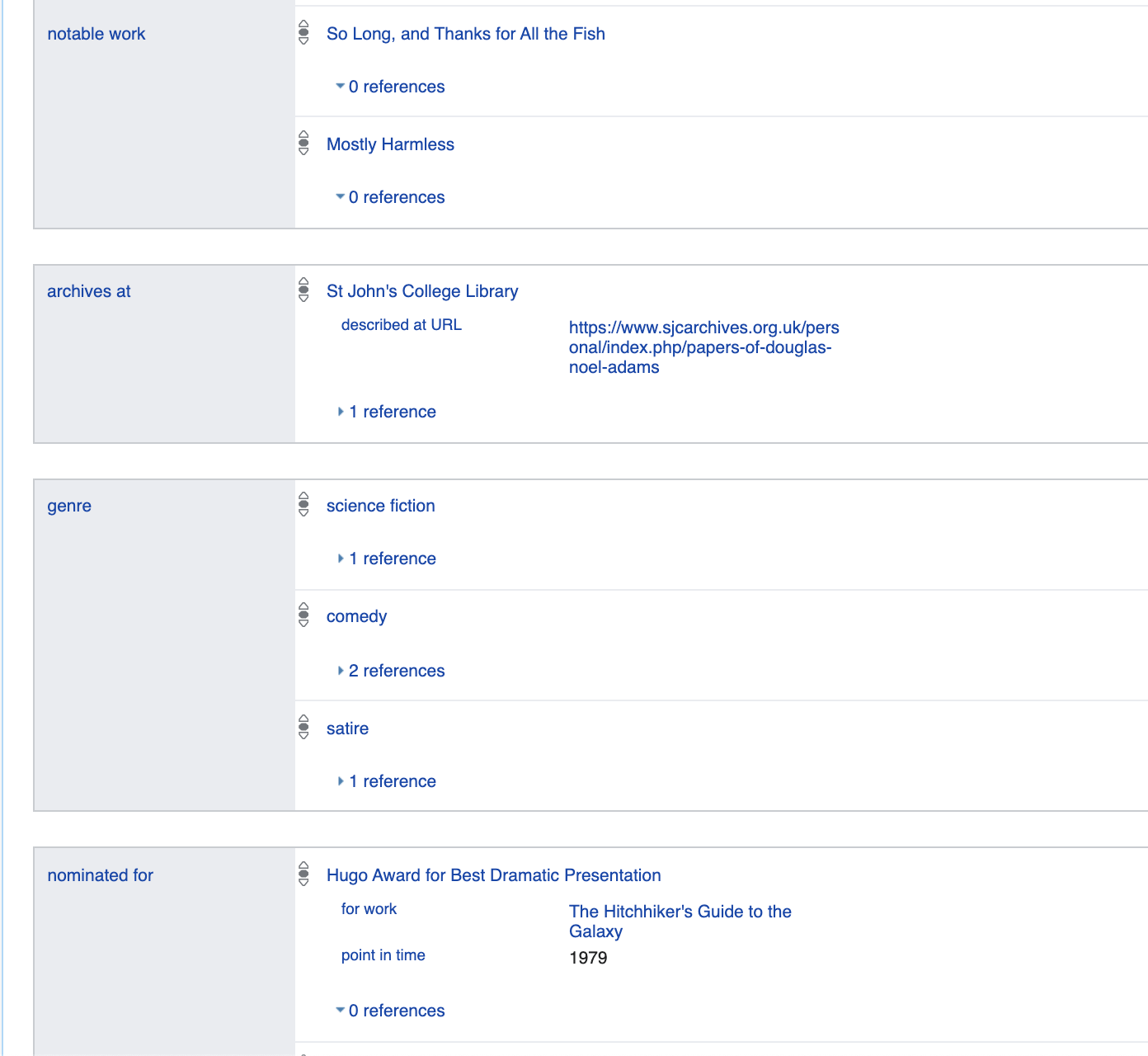
Vamos falar um pouco mais sobre as propriedades listadas aqui. Por exemplo, gênero: masculino é

essencialmente um reflexo do fato lógico: p21 (Q42, Q6581097).
Onde p21 → é gênero_identidade / 2 é um predicado binário
Q42 → Douglas Adams
Q6581097 → masculino
Assim, todos os dados são apresentados como predicados unários, por exemplo is_dead (Q42), ou como binário p21 (Q42, Q6581097).
Na verdade, este é outro paradigma do paradigma de modelagem - lógica de primeira ordem, mas em predicados unários e binários.
E aqui é muito fácil adicionar novos dados: tudo o que não é indicado na forma de um predicado sobre os objetos é falso, na literatura isso é conhecido como a suposição do mundo fechado .
Além disso, este formato permite uma metamodelagem absolutamente natural
https://www.wikidata.org/wiki/Q42395533
Existem várias consultas básicas de armazenamento e gravação para esses dados - vamos examinar as opções populares.
RDF e a linguagem de consulta SPARQL
RDF é uma linguagem formal para descrever dados relacionados para o processamento subsequente de consultas, ou seja, é um formato legível por máquina.
Na verdade, para ele, a chave é o conceito de um trigêmeo:

E aqui está um exemplo de registro de dados neste modelo (os prefixos determinam onde estão as "descrições" desses predicados).

Este formato de gravação permite representar graficamente dados sobre objetos - por exemplo, você pode escrever informações sobre a cidade de Berlim.

Para o formato RDF, eles criaram a linguagem de consulta SPARQL: que descreve essencialmente as restrições sobre predicados lógicos e diz qual variável deve ser extraída da expressão lógica:

O que realmente queremos encontrar é o valor da variável? País, de modo que member_of seja verdadeiro para member_of (? Country, q458) e q458 seja o ID da UE.
No código real, pode ser assim:
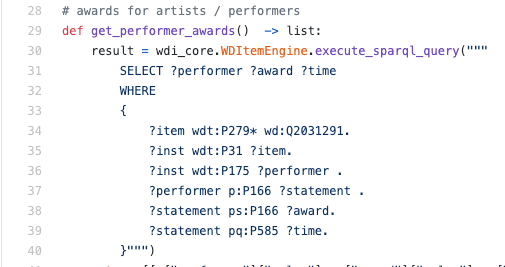
Total: RDF é um formato para representar dados na forma de triplos (predicados binários) e SPARQL é uma linguagem de consulta baseada em lógica para triplos.
Linguagem de consulta de registro de dados e derivados
Além disso, para escrever consultas para RDF (e não apenas para ele, mais sobre isso mais tarde), você pode usar Datalog - uma linguagem declarativa (frequentemente) que representa sintaticamente um subconjunto do Prolog (na maioria das vezes).
Nele, as consultas têm a seguinte aparência:
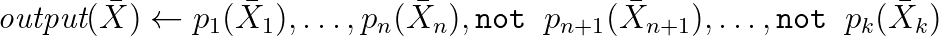
Freqüentemente, a sintaxe é estendida com a ajuda de agregações e outras coisas praticamente importantes. Na verdade, essas são regras de inferência tiradas da lógica e, com sua ajuda, você pode modelar a inferência de novas propriedades e gravar consultas em RDF. O seguinte é um exemplo do mundo real trabalhando com WikiData baseado em um dos dialetos

Outra vantagem importante das linguagens de consulta lógica baseadas em Datalog é que, para elas, RDF é simplesmente um formato para registrar fatos (declarações) de lógica binária. Eles também podem lidar com qualquer outra afirmação lógica - não necessariamente binária.
conclusões
Em primeiro lugar, os dados relacionais são adequados para modelar domínios fixos, onde o esquema muda com pouca frequência ou as mudanças afetam não apenas registros únicos, mas segmentos inteiros.
Em segundo lugar, as linguagens relacionais são adequadas para tarefas de modelagem onde você precisa extrair subtabelas, transformar e combinar as existentes - esta não é uma ferramenta ideal quando uma parte significativa do trabalho vai para o nível de modificação e / ou inferência em um registro particular.
Em terceiro lugar, se o domínio de modelagem é uma área abrangente, e até mutável, onde até mesmo os registros da mesma classe são notavelmente diferentes, dados coerentes são adequados.
Quarto, a representação padrão é RDF e faz sentido tentar primeiro. Aparafusando os bancos de dados necessários a ele e usando linguagens como SPARQ, você pode extrair os dados necessários.
Quinto, se a modelagem com trigêmeos se tornar complicada e inconveniente, você pode considerar a representação lógica dos dados e do Datalog como uma linguagem de consulta.

