Acontece que em 1998 entrei na pós-graduação na Academia Agrícola do Estado da Rússia e escolhi AI / ML como o tema de meu trabalho científico. Esses foram os tempos difíceis da próxima era do gelo das redes neurais. Foi nessa época que Yang Lecun publicou seu famoso trabalho "Gradient-Based Learning Applied to Document Recognition" sobre os princípios da organização de redes convolucionais, o que, em minha opinião, foi apenas o começo de um novo degelo. É engraçado que naquela época eu estivesse trabalhando em alguns elementos semelhantes, porque dizem que a ideia, quando chegar a hora, está no ar. No entanto, nem todo mundo é dado para trazê-lo à vida. Eu, infelizmente, nunca levei meu trabalho em defesa, mas sempre quis terminar algum dia.
Fonte:Hitecher
E agora, depois de 20 anos, quando comecei a trabalhar como professor na Universidade Federal do Sul e ao mesmo tempo lecionar no programa de formação complementar "Samsung IT School", tive uma segunda chance. A Samsung ofereceu o SFU para ser o primeiro a lançar a faixa de treinamento "Samsung IT Academy" em inteligência artificial para solteiros e mestres. Tive algumas preocupações de que seria possível implementar todo o currículo na íntegra, mas respondi com entusiasmo à oferta de leitura do curso. Percebi que o círculo estava fechado e ainda tinha uma segunda chance de fazer o que antes havia falhado. Deve-se observar aqui que o curso Samsung AI / ML é um dos melhores cursos abertos em russo disponíveis gratuitamente na plataforma Stepik ( https://stepik.org/org/srr) Porém, no caso de um curso universitário, além do curso teórico / prático, foi acrescentada a parte do projeto. Ou seja, o currículo anual da “Samsung IT Academy” foi considerado dominado no caso de estudar dois módulos “Redes Neurais e Visão Computacional”, “Redes Neurais e Processamento de Texto” com obtenção dos certificados Stepik adequados, bem como a implementação de um projeto individual. O curso terminou com a defesa de projetos de alunos, para os quais foram convidados especialistas, incl. funcionários do Centro de Inteligência Artificial de Moscou Samsung.
E desde setembro de 2019, iniciamos um curso no Instituto de Altas Tecnologias e Piezotécnica do SFedU. Claro, um número bastante grande de alunos veio para o HYIP e, posteriormente, houve uma grave evasão. O programa não era muito complicado, mas volumoso - era necessário conhecimento:
- álgebra Linear,
- teoria da probabilidade,
- cálculo diferencial,
- a linguagem de programação Python.
É claro que todos os conhecimentos e habilidades exigidos não vão além do currículo do programa de graduação do 3º ano da universidade. Darei alguns exemplos, daqueles que são mais complicados:
- Encontre a derivada da função de ativação da tangente hiperbólica
 e expresse o resultado em termos de...
e expresse o resultado em termos de...
- Encontre a derivada da função de ativação sigmóide
 e expresse o resultado em termos da sigmóide...
e expresse o resultado em termos da sigmóide...
- No gráfico de cálculos mostrado na Fig. 1 apresenta uma função complexa com parâmetros ... Por conveniência, adicionou resultados intermediários de operações como... É necessário determinar a que derivada será igual por parâmetro

Para ser honesto, eu rapidamente estudei algo, especialmente de algoritmos modernos para trabalhar com redes neurais, com alunos. Inicialmente, presumia-se que os próprios alunos iriam estudar vídeo-aulas do curso online da Samsung no Stepik, e na sala de aula apenas fazeríamos workshops. No entanto, tomei a decisão de ler a teoria também. Essa decisão se deve ao fato de que com o professor você pode resolver um assunto incompreensível, discutir as ideias que surgiram, etc. Os alunos receberam tarefas práticas na forma de trabalhos de casa. A abordagem acabou sendo acertada - em sala de aula se conseguiu um clima animado, vi que os alunos em geral tiveram bastante sucesso no domínio do material.
Um mês depois, mudamos suavemente de um modelo de neurônio para as primeiras arquiteturas simples totalmente conectadas, de regressão simples para classificação multiclasse, de computação de gradiente simples para algoritmos de otimização de gradiente descendente SGD, ADAM, etc. Concluímos a primeira metade do curso com redes convolucionais e arquiteturas de rede profunda modernas. A tarefa final do primeiro módulo de Visão por Computador foi participar da competição " Dirty vs Cleaned " em Kaggle com a superação do limite de precisão de 80%.
Outro fator, na minha opinião, importante: não éramos fechados dentro da universidade. Os organizadores das pistas realizaram webinars e master classes para nós com especialistas convidados dos laboratórios da Samsung. Esses eventos aumentaram a motivação dos alunos, e a minha, para ser honesto :). Por exemplo, houve um evento interessante de orientação profissional - uma ponte online entre os públicos do SFedU, da Moscow State University e da Samsung, onde funcionários do Moscow AI Center Samsung falaram sobre as tendências modernas no desenvolvimento de IA / ML e responderam às perguntas dos alunos.
A segunda parte do curso, dedicada ao processamento de texto, começou com uma teoria geral da análise linguística. Em seguida, os alunos foram apresentados aos modelos vetoriais e de texto TF-IDF e, em seguida, à semântica de distribuição e ao word2vec. Com base nos resultados, vários workshops interessantes foram realizados: gerando embeddings word2wec, gerando nomes e slogans. Em seguida, passamos à teoria e prática do uso de redes convolucionais e recorrentes para análise de texto.
Por enquanto, a questão é que publiquei um artigo no periódico VAK e comecei a preparar o próximo, reunindo gradualmente material para uma nova dissertação. Meus alunos também não ficaram parados, mas começaram a trabalhar em seus primeiros projetos. Os alunos escolheram os tópicos por conta própria e, como resultado, obtiveram 7 projetos de graduação em diferentes áreas de aplicação de redes neurais:
- « » , .
- « » .
- « » .
- « » .
- « » .
- « » .
- « » , .

Todos os projetos foram defendidos, mas o grau de complexidade e elaboração foi diferente, o que, com toda a razão, se refletiu nas estimativas dos projetos. Com base nos resultados da defesa, quatro projetos foram selecionados para a competição anual Samsung IT Academy . E posso dizer com orgulho que o júri premiou dois dos nossos projetos com os primeiros lugares. A seguir darei uma breve descrição desses projetos, com base nos materiais fornecidos pelos meus alunos Grateful Alexander, Krikunov Stanislav e Pandov Vyacheslav, pelos quais muito obrigado a eles. Acredito que as soluções que eles demonstraram podem muito bem ser avaliadas como um trabalho de pesquisa sério.
1º lugar na nomeação "Artificial Intelligence" do concurso "Samsung IT Academy".
"Monitoramento da atividade física humana", Alexander Grateful, Stanislav Krikunov
O projeto era criar um aplicativo móvel que identifica e quantifica a atividade física em treinamento usando sensores de telefones móveis. Agora, existem muitos aplicativos móveis que podem reconhecer a atividade física de uma pessoa: Google Fit, Nike Training Club, MapMyFitness e outros. No entanto, esses aplicativos não podem reconhecer certos tipos de exercícios e contar o número de repetições.
Um dos autores do projeto Grateful Alexander, meu graduado em 2015 do programa Samsung IT School, e eu, não sem orgulho, nos regozijamos que o conhecimento adquirido sobre desenvolvimento móvel na escola foi aplicado dessa forma.
Como a atividade física é reconhecida? Vamos começar explicando como o tempo do exercício é determinado. Para detectar o início e o fim dos exercícios, os alunos decidiram utilizar o módulo de aceleração calculado como a raiz da soma dos quadrados das acelerações ao longo dos eixos. Um certo limite foi escolhido, com o qual o valor de aceleração atual foi comparado. Se o limite for ultrapassado (a derivada da aceleração é positiva), consideramos que o exercício começou. Se a aceleração atual estiver abaixo do limite (a derivada da aceleração é negativa), consideramos que o exercício acabou. Infelizmente, essa abordagem não permite o processamento em tempo real. Uma possível melhoria é a utilização de uma janela deslizante sobre os dados com o cálculo do resultado a cada etapa do turno.
O conjunto de dados foi coletado pelos próprios autores. Ao realizar 7 exercícios diferentes, foram usados 3 tipos de smartphones (Android versões 4.4, 9.0, 10.0). O smartphone foi preso à mão por meio de um bolso especial. Um total de 1.800 repetições foram realizadas por três voluntários. Durante a execução, erros na técnica podem surgir por qualquer motivo, portanto, foi realizado um procedimento de limpeza da amostra. Para isso, as distribuições de correlações cruzadas foram construídas para todos os tipos de exercícios. Em seguida, para cada exercício, foi selecionado um limite de correlação, abaixo do qual o exercício é considerado inadequado e é excluído da amostra.
O mesmo exercício, dependendo da repetição, tem um tempo de execução diferente. Para combater isso, decidiu-se interpolar os dados com um número fixo de amostras, independentemente de quantas saíssem dos sensores. Recebido 50 - o dobro da taxa de amostragem, calculando as posições intermediárias como a média aritmética das vizinhas. Recebeu 200 - descarte a cada 2 contagens. Nesse caso, o número de amostras será constante. Da mesma forma, para qualquer razão entre o número de entrada de amostras e o número de saída desejado.
Para a rede neural, optou-se por aplicar dados no domínio da frequência. Como a massa corporal de uma pessoa é muito grande, pode-se esperar que as frequências características do sinal fiquem na região de baixa frequência do espectro na maioria dos exercícios padrão. Nesse caso, as altas frequências podem ser consideradas um jitter durante a execução ou ruído dos sensores. O que isso significa? Isso significa que podemos encontrar o espectro do sinal usando o FFT e usar apenas 10-20% dos dados para análise. Por que tão pouco? Visto que 1) o espectro é simétrico, você pode cortar imediatamente metade dos componentes 2) informações básicas - apenas 20-40% da parte informativa do espectro. Essas suposições descrevem exercícios de força lenta especialmente bem.
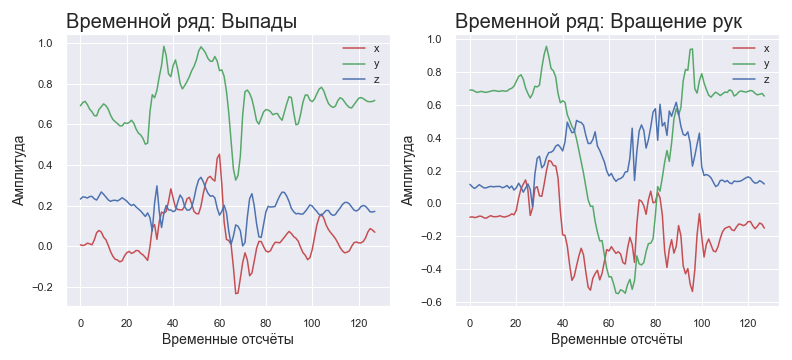
Séries temporais normalizadas para diferentes exercícios
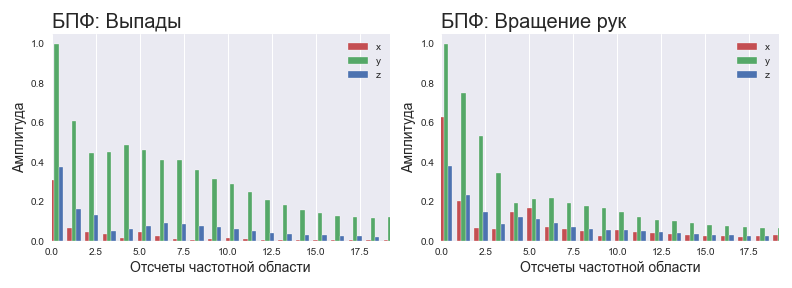
Espectro normalizado para diferentes exercícios
Antes do processamento pela rede neural, o espectro de dados é normalizado para o valor máximo entre os três eixos para ajustar todas as amostras de exercícios na faixa de amplitude 0-1. Neste caso, as proporções entre os eixos são preservadas.
A rede neural realiza a tarefa de classificar exercícios. Isso significa que ele produz um vetor de probabilidades para todos os exercícios da lista pela qual foi treinado. O índice do elemento máximo neste vetor é o número do exercício realizado. Além disso, se a confiança no exercício realizado for inferior a 85%, considera-se que nenhum dos exercícios foi realizado. A rede consiste em 3 camadas: 4 convolucionais, 3 totalmente conectadas, o número de neurônios de saída é igual ao número de exercícios que queremos reconhecer. Na arquitetura, para economizar recursos computacionais, apenas convoluções com tamanho de núcleo de 3x3 são usadas. A arquitetura relativamente simples da rede é justificada pelos recursos de computação limitados dos smartphones, em nossa tarefa, o reconhecimento com um mínimo de atraso é necessário.

Descrição da arquitetura da rede neural
A estratégia de treinamento da rede neural é treinar por períodos usando a normalização em lote para os dados de treinamento até que a função de perda na amostra de treinamento alcance seu valor mínimo.
Resultados: com desempenho de exercícios mais ou menos de alta qualidade, a confiança da rede é de 95-99%. No conjunto de validação, a precisão foi de 99,8%.
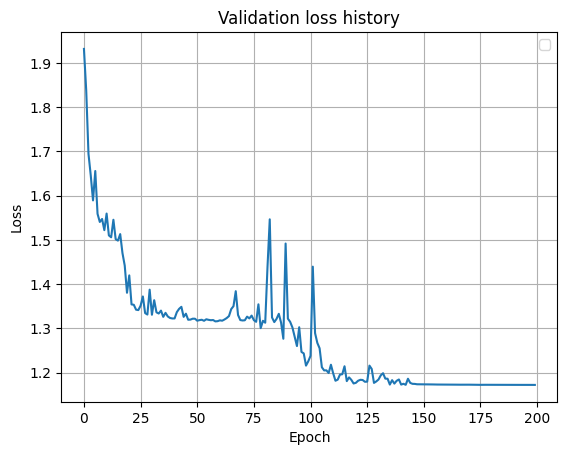
Erro durante o treinamento em um conjunto de validação

Matriz de erro para uma
rede neural A rede neural foi construída em um aplicativo móvel e mostrou resultados semelhantes aos do treinamento.
O estudo também testou outros modelos de aprendizado de máquina usados hoje para resolver problemas de classificação: regressão logística, florestas aleatórias, XG Boost. Para essas arquiteturas, regularização de Tikhonov (L2), validação cruzada e pesquisa em grade foram usadas para encontrar os parâmetros ideais. Como resultado, os indicadores de precisão foram os seguintes:
- Regressão logística: 99,4%
- Florestas aleatórias: 99,1%
- Boost XG: 97,5%
O conhecimento adquirido durante o treinamento na Samsung IT Academy ajudou os autores do projeto a expandir os horizontes de seus interesses e deu uma contribuição inestimável ao ingressar no programa de mestrado no Instituto de Ciência e Tecnologia Skolkovo. No momento, meus alunos estão fazendo pesquisas na área de aprendizado de máquina para sistemas de comunicação.
Código no GitHub
II « » «IT Samsung».
« »,
O trabalho da modelo está bem descrito neste slide:

Tudo começa com uma fotografia. Na implementação apresentada, ele vem de um bot do Telegram. Usando-o, o Dlib frontal_face_detector encontra todas as faces na imagem. Em seguida, 68 pontos-chave 2D de cada face são detectados usando Dlib shape_predictor_68_face_landmarks. Cada conjunto é normalizado da seguinte forma: centralizado (subtraindo a média de X e Y) e escalado (dividindo pelo máximo absoluto de X e Y). Cada coordenada do ponto normalizado pertence ao intervalo [-1, +1].
Em seguida, uma rede neural entra em ação, que prevê a profundidade de cada ponto-chave da face - a coordenada Z, usando as coordenadas normalizadas (X, Y). Este modelo foi treinado no conjunto de dados AFLW2000.
Além disso, esses pontos são conectados uns aos outros, formando uma máscara de malha. Também pode ser chamada de biometria facial. Os comprimentos dos segmentos de tal máscara são usados como uma das formas de definir emoções. A ideia é que cada segmento de linha tenha seu próprio lugar no vetor de segmento de linha e alguns deles dependendo da emoção. E cada emoção, em teoria, tem um número limitado de tais vetores. Essa hipótese foi confirmada no decorrer dos experimentos. Para treinar tal modelo, os seguintes conjuntos de dados foram usados: Cohn-Kanade +, JAFFE, RAF-DB.
Paralelamente, outra rede está aprendendo a classificar as emoções pela própria imagem. Imagens de rostos são cortadas dos retângulos encontrados com Dlib. Convertido em preto e branco de canal único e compactado em 48x48. Para treinar este modelo, os mesmos conjuntos de dados foram usados para o modelo biométrico. No entanto, o conjunto de dados FER2013 foi usado adicionalmente.
Em conclusão, entra em operação a terceira rede neural, cuja arquitetura combina as duas redes anteriores congeladas e pré-treinadas com uma camada treinada. Essas redes também substituem as últimas camadas totalmente conectadas. Em vez do “vetor de probabilidades” esperado pelo qual a classe de destino pode ser determinada, mais “recursos de baixo nível” são retornados. E a camada unificadora é treinada para interpretar essas informações na classe de destino.
Entre as "soluções semelhantes" estão as seguintes: EmoPy, DLP-CNN (RAF-DB), FER2013, EmotioNet. No entanto, é difícil fazer comparações porque eles foram treinados em dados diferentes.
Código no GitHub
Conclusão
Concluindo, gostaria de dizer que o curso piloto mostrou o seu valor e, neste ano letivo de 2020/21, o programa já está sendo ministrado em 23 universidades parceiras da Samsung IT Academy na Rússia e no Cazaquistão. A lista completa pode ser vista aqui . Este ano um grupo de mestres e bacharéis já está estudando conosco (há até um Ph.D. inteiro no grupo!) E até agora, em grande parte, o granito da ciência está roendo com sucesso. Ainda não foram encontradas ideias para um projeto individual, mas os alunos estão cheios de otimismo. Claro, na próxima competição de projetos individuais, a competição aumentará dez vezes, mas esperamos continuar recebendo notas altas pelas realizações de nossos alunos. E o mais importante, estou certo de que o conhecimento e a experiência adquiridos serão de grande ajuda para nossos graduados em seu desenvolvimento na área de TI.
2020 Rostov-on-Don. SFedU, Samsung IT Academy.

Dmitry Yatsenko
Professor titular do Departamento de Tecnologias de Informação e Medição, Faculdade de Alta Tecnologia, Southern Federal University,
Professor da Escola de TI Samsung,
Professor do curso AI IT da Samsung Academy.