- Artigo de Pesquisa
- Pytorch : YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 ( repositório principal - use para reproduzir resultados)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet : YOLOv4-tiny, YOLOv4-CSP, YOLOv4x-MISH
- Estrutura YOLOv4-CSP
O Scaled YOLO v4 é a rede neural mais precisa ( 55,8% AP ) no conjunto de dados Microsoft COCO de qualquer rede neural publicada até o momento. E também é o melhor em termos de proporção de velocidade para precisão em toda a faixa de precisão e velocidade de 15 FPS a 1774 FPS . No momento, é a rede neural Top1 para detecção de objetos.
O YOLO v4 dimensionado supera as redes neurais em precisão:
- Google EfficientDet D7x / DetectoRS ou SpineNet-190 (autotreinamento em dados extras)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
Mostramos que as abordagens de rede YOLO e Cross-Stage-Partial (CSP) são as melhores em termos de precisão absoluta e proporção de precisão para velocidade.
Gráfico de precisão (eixo vertical) e latência (eixo horizontal) na GPU Tesla V100 (Volta) com lote = 1 sem usar TensorRT:
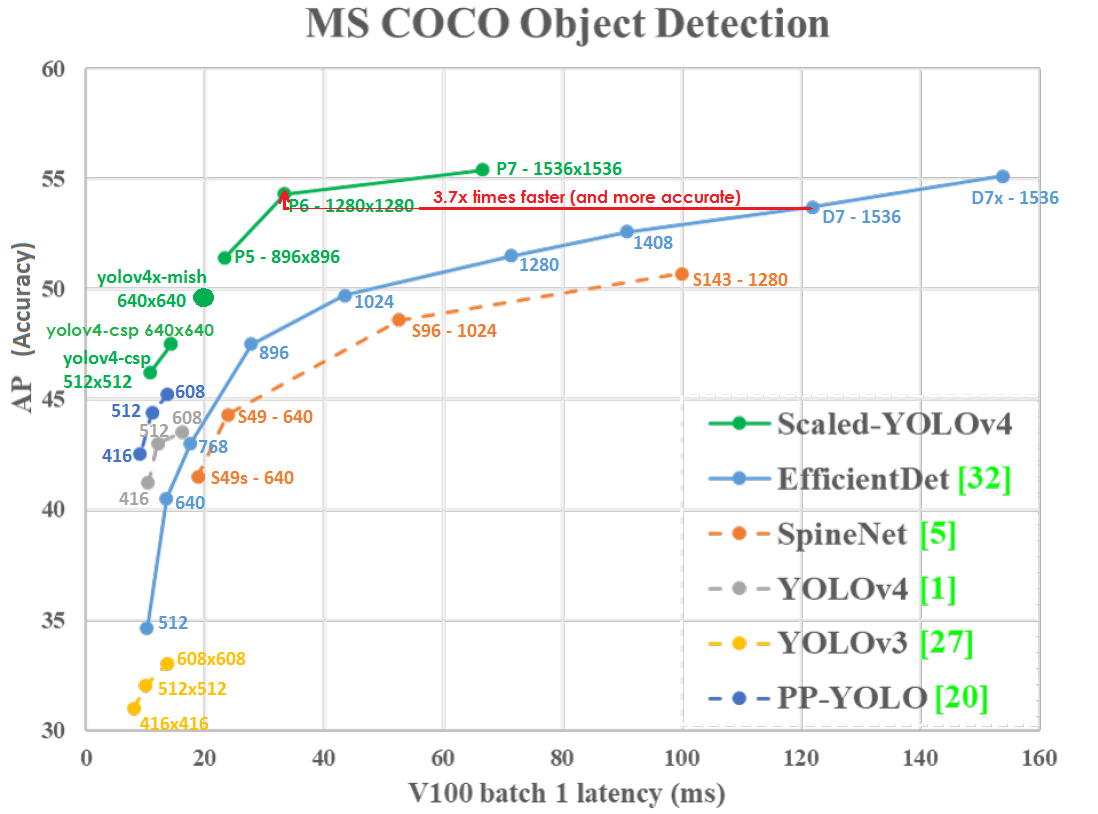
Mesmo em resolução de rede mais baixa, Scaled-YOLOv4-P6 (1280x1280) 30 FPS é ligeiramente mais preciso e 3,7x mais rápido do que EfficientDetD7 (1536x1536) 8,2 FPS. Essa. YOLOv4 faz melhor uso da resolução da rede.
O YOLO v4 escalado está na curva de otimização de Pareto - não importa qual outra rede neural você use, sempre haverá essa rede YOLOv4, que é mais precisa com a mesma velocidade ou mais rápida com a mesma precisão, ou seja, YOLOv4 é o melhor em termos de velocidade e precisão.
O YOLOv4 dimensionado é mais preciso e rápido do que as redes neurais:
- Google EfficientDet D0-D7x
- Google SpineNet S49s - S143
- Baidu Paddle-Paddle PP YOLO
- E muitos outros
O YOLO v4 dimensionado é uma série de redes neurais construídas a partir da rede YOLOv4 aprimorada e dimensionada. Nossa rede neural foi treinada do zero sem o uso de pesos pré-treinados (Imagenet ou qualquer outro).
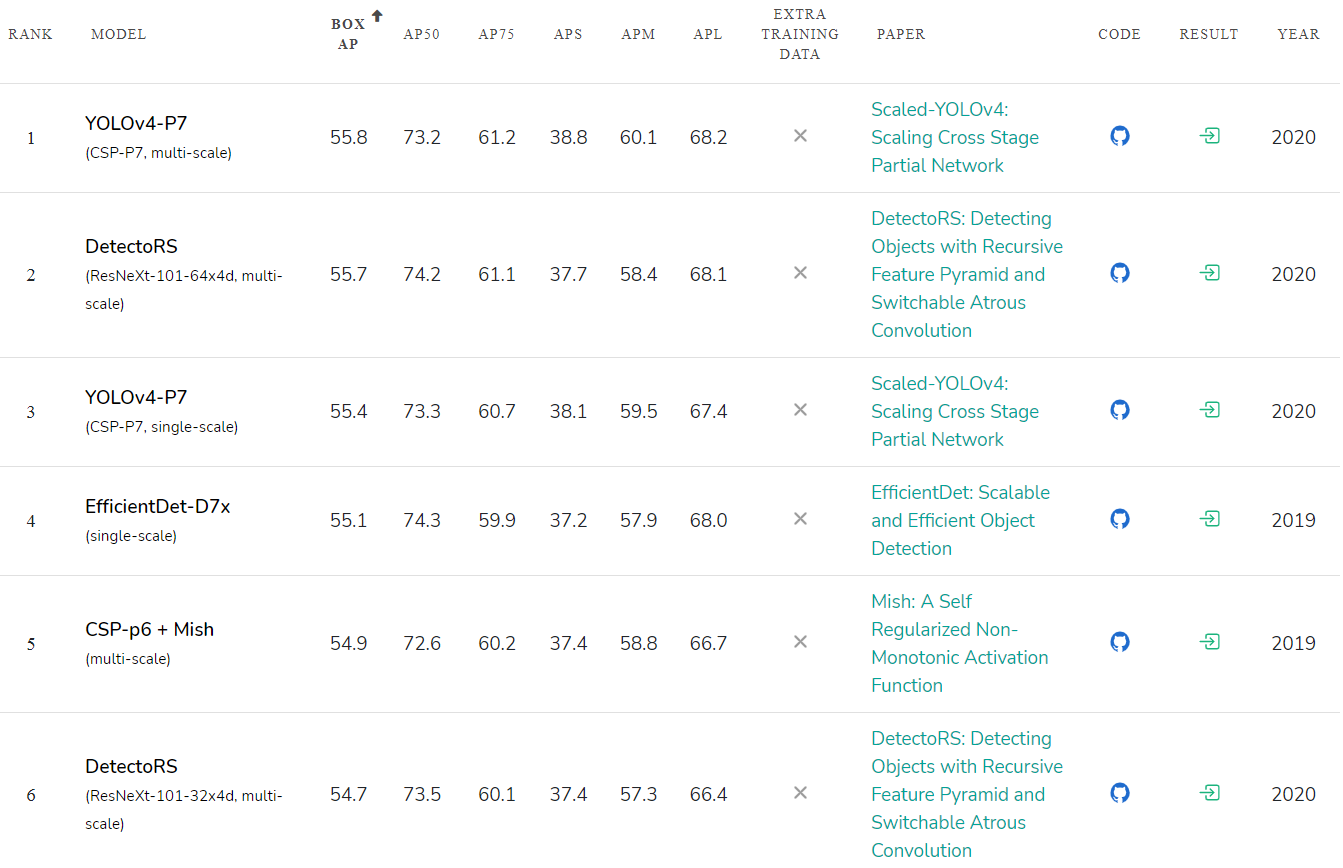
Classificação de precisão de redes neurais publicadas: paperswithcode.com/sota/object-detection-on-coco :
YOLOv4-tiny velocidade da rede neural atinge 1774 FPS em uma GPU RTX 2080Ti de jogos usando TensorRT + tkDNN (lote = 4, FP16): github. com / ceccocats / tkDNN
YOLOv4-tiny pode ser executado em tempo real a 39 FPS / latência de 25ms no JetsonNano (416x416, fp16, lote = 1) tkDNN / TensorRT:

O YOLOv4 escalado usa os recursos de computadores paralelos, como GPUs e NPUs, com muito mais eficiência. Por exemplo, GPU V100 (Volta) tem desempenho: 14 TFLops - 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
Se testarmos ambos os modelos na GPU V100 com lote = 1 , com parâmetros --hparams = mixed_precision = true e sem --tensorrt = FP32 , então:
- YOLOv4-CSP (640x640) - 47,5% AP - 70 FPS - 120 BFlops (60 FMA)
Com base em BFlops, deveria ser 933 FPS = (112.000 / 120), mas na realidade obtemos 70 FPS, ou seja, usado 7,5% GPU = (70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
Essa. eficiência das operações de computação em dispositivos com computação paralela massiva, como GPUs usados no YOLOv4-CSP (7,5 / 1,6) = 4,7x melhor do que a eficiência das operações usadas no EfficientDetD3
Normalmente, as redes neurais são executadas na CPU apenas em tarefas de pesquisa para facilitar a depuração, e a característica BFlops atualmente é apenas de interesse acadêmico. Em tarefas do mundo real, a velocidade e a precisão reais são importantes, não o desempenho no papel. A velocidade real do YOLOv4-P6 é 3,7x mais rápida do que EfficientDetD7 no GPU V100. Portanto, dispositivos com grande paralelismo GPU / NPU / TPU / DSP com muito mais velocidade, preço e dissipação de calor ideais são quase sempre usados:
- GPU incorporada (Jetson Nano / Nx)
- Mobile-GPU / NPU / DSP (Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge (Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-motors TPU 144 TOPS-8bit)
- Cloud GPU (nVidia A100 / V100 / TitanV)
- Cloud NPU (Google-TPU, Huawei Ascend, Intel Habana, Qualcomm AI 100, ...)
Além disso, ao usar redes neurais na Web - geralmente a GPU é usada por meio do WebGL, WebAssembly, bibliotecas WebGPU, neste caso - o tamanho do modelo pode importar: github.com/tensorflow/tfjs#about-this-repo
Usando dispositivos e algoritmos com problemas paralelismo é um caminho sem saída para o desenvolvimento, porque é impossível reduzir o tamanho da litografia menor que o tamanho de um átomo de silício para aumentar a frequência do processador:
- O melhor tamanho atual para a fabricação de dispositivos semicondutores é de 5 nanômetros.
- O tamanho da rede cristalina do silício é de 0,5 nanômetros.
- O raio atômico do silício é de 0,1 nanômetro.
A solução são computadores com paralelismo maciço: em um único cristal ou em vários cristais conectados por um intermediário. Portanto, é imperativo criar redes neurais que usem com eficiência máquinas de computação massivamente paralelas, como GPUs e NPUs.
Melhorias no YOLOv4 com escala em relação ao YOLOv4:
- O YOLOv4 dimensionado usou técnicas de dimensionamento de rede ideais para obter redes YOLOv4-CSP -> P5 -> P6 -> P7
- Arquitetura de rede aprimorada: o backbone é otimizado e o pescoço (PAN) usa conexões parciais cruzadas (CSP) e ativação Mish
- A média móvel exponencial (EMA) é usada durante o treinamento - este é um caso especial de SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- Para cada resolução da rede, uma rede neural separada é treinada (no YOLOv4, apenas uma rede neural foi treinada para todas as resoluções)
- Normalizadores aprimorados em camadas [yolo]
- Ativações alteradas para largura e altura, o que permite um treinamento de rede mais rápido
- Use o parâmetro [net] letter_box = 1 (preserva a proporção da imagem de entrada) para redes de alta resolução (para todas, exceto yolov4-tiny.cfg)
Arquitetura de rede neural YOLOv4 com escala (exemplos de três redes: P5, P6, P7): A

conexão CSP é muito eficiente, simples e pode ser aplicada a qualquer rede neural. O resultado final é que
- metade do sinal de saída segue pelo caminho principal (gerando mais informações semânticas com um grande campo receptivo)
- e a outra metade do sinal segue um desvio (retendo mais informações espaciais com um pequeno campo receptivo)
O exemplo mais simples de uma conexão CSP (à esquerda é uma rede regular, à direita é uma rede CSP):

Um exemplo de uma conexão CSP em YOLOv4-CSP / P5 / P6 / P7
(à esquerda é uma rede regular, à direita está uma rede CSP):

Em YOLOv4-tiny existem 2 conexões CSP :

YOLOv4 é usado em vários campos e tarefas:
- Governo de Taiwan: Controle de tráfego www.taiwannews.com.tw/en/news/3957400 e youtu.be/IiU6wFmfVnk
- Amazon: Anti-Covid19 Distance-assistant github.com/amzn/distance-assistant e Amazon Neurochip / Amazon EC2 Inf1 instâncias: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- baseado-objeto-detecção-com-um-aws-neurônio-compilado-yolov4-modelo-em-aws-inferentia
- Laboratório de inovação da BMW: github.com/BMW-InnovationLab
E em muitas outras tarefas….
Existem implementações em várias estruturas:
- Pytorch : github.com/WongKinYiu/ScaledYOLOv4
- Darknet : github.com/AlexeyAB/darknet
- TensorFlow : github.com/hunglc007/tensorflow-yolov4-tflite
- o pip install yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- A estrutura da rede pode ser visualizada usando o utilitário Netron - Visualizador de redes neurais: github.com/lutzroeder/netron
Como compilar e executar o Cloud Object Detection gratuitamente :
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- vídeo: www.youtube.com/watch?v=mKAEGSxwOAY
Como compilar e executar o treinamento na nuvem gratuitamente :
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- vídeo: youtu.be/mmj3nxGT2YQ
Além disso, a abordagem YOLOv4 pode ser usada em outras tarefas, por exemplo, ao detectar objetos 3D:
- Código - Complex-YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- Código - YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch
