
Um pouco sobre mim: Também sou um desenvolvedor iniciante, estou fazendo o curso "Desenvolvedor Python". Este material não foi compilado como resultado de sensoriamento remoto, mas na ordem de autodesenvolvimento. Meu código pode ser bastante ingênuo e, portanto, fique à vontade para deixar seus comentários nos comentários. Se eu ainda não te assustei, por favor, sob o corte :)
Analisaremos um exemplo prático de normalização de uma tabela plana contendo dados duplicados para o estado de 3NF ( terceira forma normal ).
Desta tabela:
Tabela de dados

vamos fazer esse banco de dados:
Diagrama de conexão DB
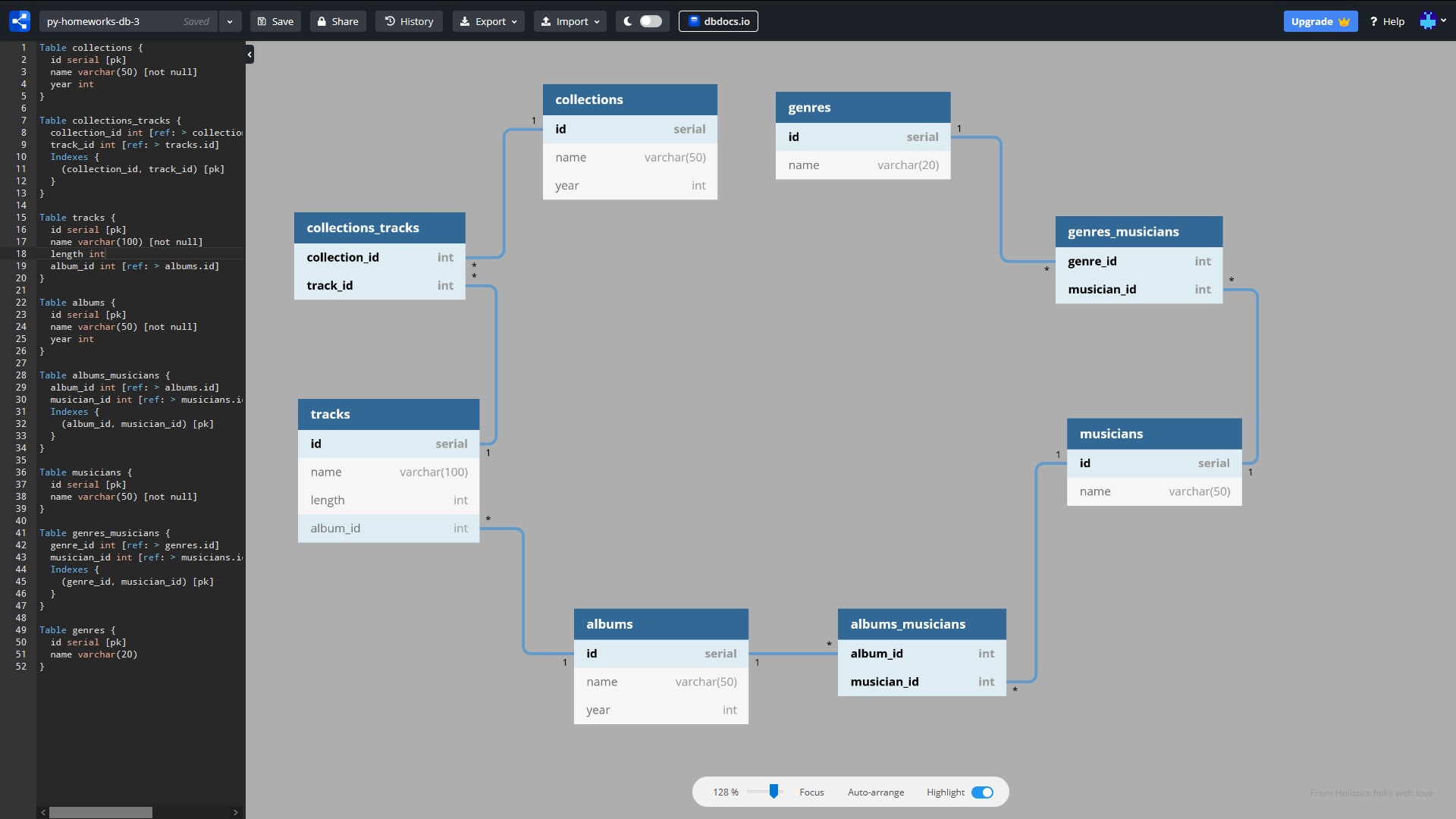
Para os impacientes: o código pronto para ser executado está neste repositório . Esquema de banco de dados interativo aqui . Uma folha de dicas para escrever consultas ORM está no final do artigo.
Vamos concordar que no texto do artigo usaremos a palavra “Tabela” ao invés de “Relacionamento”, e a palavra “Campo” ao invés de “Atributo”. Na atribuição, precisamos colocar uma mesa com arquivos de música no banco de dados, eliminando a redundância de dados. A tabela original (formato CSV) contém os seguintes campos (faixa, gênero, músico, álbum, duração, álbum_ano, coleção, coleção_ano). As conexões entre eles são as seguintes:
- cada músico pode cantar em vários gêneros, assim como vários músicos podem se apresentar em um gênero (relação de muitos para muitos)
- um ou vários músicos podem participar da criação de um álbum (relação muitos para muitos)
- uma faixa pertence a apenas um álbum (relacionamento um para muitos)
- faixas podem ser incluídas em várias coleções (relação muitos para muitos)
- a faixa não pode ser incluída em nenhuma coleção.
Para simplificar, digamos que os nomes dos gêneros, dos artistas, dos álbuns e das coleções não se repitam. Os nomes das faixas podem ser repetidos. Projetamos 8 tabelas no banco de dados:
- gêneros (gêneros)
- genres_musicians (tabela de teste)
- músicos (músicos)
- albums_musicians (tabela intermediária)
- álbuns (álbuns)
- trilhas
- coleções_tracks (tabela de teste)
- coleções (coleções)
* esse esquema é teste, tirado de uma das DZ, tem alguns inconvenientes - por exemplo, não há conexão entre as faixas e o músico, assim como a faixa com o gênero. Mas isso não é essencial para o aprendizado e omitiremos essa desvantagem.
Para o teste, criei dois bancos de dados no Postgres local: "TestSQL" e "TestORM", acesso a eles: teste de login e senha. Vamos finalmente escrever algum código!
Crie conexões e tabelas
Crie conexões com o banco de dados
* read_data clear_db .
DSN_SQL = 'postgresql://test:test@localhost:5432/TestSQL'
DSN_ORM = 'postgresql://test:test@localhost:5432/TestORM'
# CSV .
DATA = read_data('data/demo-data.csv')
print('Connecting to DB\'s...')
# , .
engine_orm = sa.create_engine(DSN_ORM)
Session_ORM = sessionmaker(bind=engine_orm)
session_orm = Session_ORM()
engine_sql = sa.create_engine(DSN_SQL)
Session_SQL = sessionmaker(bind=engine_sql)
session_sql = Session_SQL()
print('Clearing the bases...')
# . .
clear_db(sa, engine_sql)
clear_db(sa, engine_orm)
Nós criamos tabelas da maneira clássica usando SQL
* read_query . .
print('\nPreparing data for SQL job...')
print('Creating empty tables...')
session_sql.execute(read_query('queries/create-tables.sql'))
session_sql.commit()
print('\nAdding musicians...')
query = read_query('queries/insert-musicians.sql')
res = session_sql.execute(query.format(','.join({f"('{x['musician']}')" for x in DATA})))
print(f'Inserted {res.rowcount} musicians.')
print('\nAdding genres...')
query = read_query('queries/insert-genres.sql')
res = session_sql.execute(query.format(','.join({f"('{x['genre']}')" for x in DATA})))
print(f'Inserted {res.rowcount} genres.')
print('\nLinking musicians with genres...')
# assume that musician + genre has to be unique
genres_musicians = {x['musician'] + x['genre']: [x['musician'], x['genre']] for x in DATA}
query = read_query('queries/insert-genre-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, value in genres_musicians.items():
res += session_sql.execute(query.format(value[1], value[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding albums...')
# assume that albums has to be unique
albums = {x['album']: x['album_year'] for x in DATA}
query = read_query('queries/insert-albums.sql')
res = session_sql.execute(query.format(','.join({f"('{x}', '{y}')" for x, y in albums.items()})))
print(f'Inserted {res.rowcount} albums.')
print('\nLinking musicians with albums...')
# assume that musicians + album has to be unique
albums_musicians = {x['musician'] + x['album']: [x['musician'], x['album']] for x in DATA}
query = read_query('queries/insert-album-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, values in albums_musicians.items():
res += session_sql.execute(query.format(values[1], values[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding tracks...')
query = read_query('queries/insert-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['track'], item['length'], item['album'])).rowcount
print(f'Inserted {res} tracks.')
print('\nAdding collections...')
query = read_query('queries/insert-collections.sql')
res = session_sql.execute(query.format(','.join({f"('{x['collection']}', {x['collection_year']})" for x in DATA if x['collection'] and x['collection_year']})))
print(f'Inserted {res.rowcount} collections.')
print('\nLinking collections with tracks...')
query = read_query('queries/insert-collection-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['collection'], item['track'])).rowcount
print(f'Inserted {res} connections.')
session_sql.commit()
Na verdade, criamos diretórios em pacotes (gêneros, músicos, álbuns, coleções) e, em seguida, vinculamos o restante dos dados e construímos manualmente as tabelas intermediárias. Execute o código e veja se o banco de dados foi criado. O principal é não se esquecer de chamar commit () na sessão.
Agora estamos tentando fazer o mesmo, mas usando a abordagem ORM. Para trabalhar com ORM, precisamos descrever classes de dados. Para isso, iremos criar 8 classes (uma para cada tabela).
Lista de classes de banco de dados
.
Base = declarative_base()
class Genre(Base):
__tablename__ = 'genres'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(20), unique=True)
# Musician genres_musicians
musicians = relationship("Musician", secondary='genres_musicians')
class Musician(Base):
__tablename__ = 'musicians'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
# Genre genres_musicians
genres = relationship("Genre", secondary='genres_musicians')
# Album albums_musicians
albums = relationship("Album", secondary='albums_musicians')
class GenreMusician(Base):
__tablename__ = 'genres_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('genre_id', 'musician_id'),)
#
genre_id = sa.Column(sa.Integer, sa.ForeignKey('genres.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Album(Base):
__tablename__ = 'albums'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
year = sa.Column(sa.Integer)
# Musician albums_musicians
musicians = relationship("Musician", secondary='albums_musicians')
class AlbumMusician(Base):
__tablename__ = 'albums_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('album_id', 'musician_id'),)
#
album_id = sa.Column(sa.Integer, sa.ForeignKey('albums.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Track(Base):
__tablename__ = 'tracks'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(100))
length = sa.Column(sa.Integer)
# album_id ,
album_id = sa.Column(sa.Integer, ForeignKey('albums.id'))
# Collection collections_tracks
collections = relationship("Collection", secondary='collections_tracks')
class Collection(Base):
__tablename__ = 'collections'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50))
year = sa.Column(sa.Integer)
# Track collections_tracks
tracks = relationship("Track", secondary='collections_tracks')
class CollectionTrack(Base):
__tablename__ = 'collections_tracks'
# ,
__table_args__ = (PrimaryKeyConstraint('collection_id', 'track_id'),)
#
collection_id = sa.Column(sa.Integer, sa.ForeignKey('collections.id'))
track_id = sa.Column(sa.Integer, sa.ForeignKey('tracks.id'))
Precisamos apenas criar uma classe base Base para o estilo declarativo de descrever tabelas e herdar dela. Toda a mágica dos relacionamentos de tabela está no uso correto de relacionamento e chave estrangeira. O código indica em qual caso criamos qual relacionamento. O principal é não se esquecer de registrar o relacionamento em ambos os lados do relacionamento muitos para muitos.
A criação direta de tabelas usando a abordagem ORM é feita chamando:
Base.metadata.create_all(engine_orm)
E é aí que entra a mágica, literalmente todas as classes declaradas no código por meio da herança do Base tornam-se tabelas. Imediatamente, não vi como especificar as instâncias de quais classes deveriam ser criadas agora e quais deveriam ser adiadas para criação posterior (por exemplo, em outro banco de dados). Certamente existe tal maneira, mas em nosso código todas as classes herdadas de Base são instanciadas de uma vez, mantenha isso em mente.
O preenchimento de tabelas usando a abordagem ORM tem a seguinte aparência:
Preencher tabelas com dados via ORM
print('\nPreparing data for ORM job...')
for item in DATA:
#
genre = session_orm.query(Genre).filter_by(name=item['genre']).scalar()
if not genre:
genre = Genre(name=item['genre'])
session_orm.add(genre)
#
musician = session_orm.query(Musician).filter_by(name=item['musician']).scalar()
if not musician:
musician = Musician(name=item['musician'])
musician.genres.append(genre)
session_orm.add(musician)
#
album = session_orm.query(Album).filter_by(name=item['album']).scalar()
if not album:
album = Album(name=item['album'], year=item['album_year'])
album.musicians.append(musician)
session_orm.add(album)
#
# ,
#
track = session_orm.query(Track).join(Album).filter(and_(Track.name == item['track'],
Album.name == item['album'])).scalar()
if not track:
track = Track(name=item['track'], length=item['length'])
track.album_id = album.id
session_orm.add(track)
# ,
if item['collection']:
collection = session_orm.query(Collection).filter_by(name=item['collection']).scalar()
if not collection:
collection = Collection(name=item['collection'], year=item['collection_year'])
collection.tracks.append(track)
session_orm.add(collection)
session_orm.commit()
Você deve preencher cada livro de referência (gêneros, músicos, álbuns, coleções) por peça. No caso de consultas SQL, foi possível gerar adições de dados em lote. Mas as tabelas intermediárias não precisam ser criadas explicitamente, os mecanismos internos do SQLAlchemy são responsáveis por isso.
Consultas de banco de dados
Na atribuição, precisamos escrever 15 consultas usando técnicas SQL e ORM. Aqui está uma lista das questões colocadas em ordem crescente de dificuldade:
- título e ano de lançamento dos álbuns lançados em 2018;
- título e duração da faixa mais longa;
- o nome das faixas, cuja duração não seja inferior a 3,5 minutos;
- títulos de coleções publicadas no período de 2018 a 2020 inclusive;
- performers cujo nome consiste em 1 palavra;
- o nome das faixas que contêm a palavra "me".
- o número de performers em cada gênero;
- o número de faixas incluídas nos álbuns 2019-2020;
- duração média da faixa para cada álbum;
- todos os artistas que não lançaram álbuns em 2020;
- títulos de coleções em que um determinado artista está presente;
- o nome dos álbuns em que há intérpretes de mais de 1 gênero;
- o nome das faixas que não estão incluídas nas coleções;
- o (s) artista (s) que escreveram a faixa mais curta (teoricamente, pode haver várias dessas faixas);
- o nome dos álbuns que contêm o menor número de faixas.
Como você pode ver, as questões acima implicam tanto na seleção e concatenação simples de tabelas, quanto no uso de funções agregadas.
Abaixo são fornecidas soluções para cada uma das 15 consultas em duas opções (usando SQL e ORM). No código, as solicitações vêm em pares para mostrar que os resultados são idênticos na saída do console.
Solicitações e sua breve descrição
print('\n1. All albums from 2018:')
query = read_query('queries/select-album-by-year.sql').format(2018)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).filter_by(year=2018):
print(item.name)
print('\n2. Longest track:')
query = read_query('queries/select-longest-track.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1):
print(f'{item.name}, {item.length}')
print('\n3. Tracks with length not less 3.5min:')
query = read_query('queries/select-tracks-over-length.sql').format(310)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc()):
print(f'{item.name}, {item.length}')
print('\n4. Collections between 2018 and 2020 years (inclusive):')
query = read_query('queries/select-collections-by-year.sql').format(2018, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).filter(2018 <= Collection.year,
Collection.year <= 2020):
print(item.name)
print('\n5. Musicians with name that contains not more 1 word:')
query = read_query('queries/select-musicians-by-name.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Musician).filter(Musician.name.notlike('%% %%')):
print(item.name)
print('\n6. Tracks that contains word "me" in name:')
query = read_query('queries/select-tracks-by-name.sql').format('me')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(Track.name.like('%%me%%')):
print(item.name)
print('Ok, let\'s start serious work')
print('\n7. How many musicians plays in each genres:')
query = read_query('queries/count-musicians-by-genres.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(
Genre.id):
print(f'{item.name}, {len(item.musicians)}')
print('\n8. How many tracks in all albums 2019-2020:')
query = read_query('queries/count-tracks-in-albums-by-year.sql').format(2019, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020):
print(f'{item[0].name}, {item[1].year}')
print('\n9. Average track length in each album:')
query = read_query('queries/count-average-tracks-by-album.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(
Album.id):
print(f'{item[0].name}, {item[1]}')
print('\n10. All musicians that have no albums in 2020:')
query = read_query('queries/select-musicians-by-album-year.sql').format(2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
for item in session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(
Musician.name.asc()):
print(f'{item}')
print('\n11. All collections with musician Steve:')
query = read_query('queries/select-collection-by-musician.sql').format('Steve')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(
Musician.name == 'Steve').order_by(Collection.name):
print(f'{item.name}')
print('\n12. Albums with musicians that play in more than 1 genre:')
query = read_query('queries/select-albums-by-genres.sql').format(1)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(
Genre.name)) > 1).group_by(Album.id).order_by(Album.name):
print(f'{item.name}')
print('\n13. Tracks that not included in any collections:')
query = read_query('queries/select-absence-tracks-in-collections.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
# Important! Despite the warning, following expression does not work: "Collection.id is None"
for item in session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None):
print(f'{item.name}')
print('\n14. Musicians with shortest track length:')
query = read_query('queries/select-musicians-min-track-length.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(func.min(Track.length))
for item in session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(
Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name):
print(f'{item[0].name}, {item[1]}')
print('\n15. Albums with minimum number of tracks:')
query = read_query('queries/select-albums-with-minimum-tracks.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
for item in session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name):
print(f'{item.name}')
Para quem não quer mergulhar na leitura do código, tentarei mostrar como o SQL "bruto" e sua alternativa se parecem em uma expressão ORM, vamos lá!
Folha de referências para correspondência de consultas SQL e expressões ORM
1. título e ano de lançamento dos álbuns de 2018:
SQL
select name
from albums
where year=2018
ORM
session_orm.query(Album).filter_by(year=2018)
2. título e duração da faixa mais longa:
SQL
select name, length
from tracks
order by length DESC
limit 1
ORM
session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1)
3. o nome das faixas, cuja duração não é inferior a 3,5 minutos:
SQL
select name, length
from tracks
where length >= 310
order by length DESC
ORM
session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc())
4. os nomes das coleções publicadas no período de 2018 a 2020 inclusive:
SQL
select name
from collections
where (year >= 2018) and (year <= 2020)
ORM
session_orm.query(Collection).filter(2018 <= Collection.year, Collection.year <= 2020)
* note que daqui em diante, a filtragem é especificada usando filter, e não usando filter_by.
5.executores cujo nome consiste em 1 palavra:
SQL
select name
from musicians
where not name like '%% %%'
ORM
session_orm.query(Musician).filter(Musician.name.notlike('%% %%'))
6. nome das faixas que contêm a palavra "me":
SQL
select name
from tracks
where name like '%%me%%'
ORM
session_orm.query(Track).filter(Track.name.like('%%me%%'))
7. número de artistas em cada gênero:
SQL
select g.name, count(m.name)
from genres as g
left join genres_musicians as gm on g.id = gm.genre_id
left join musicians as m on gm.musician_id = m.id
group by g.name
order by count(m.id) DESC
ORM
session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(Genre.id)
8. número de faixas incluídas nos álbuns 2019-2020:
SQL
select t.name, a.year
from albums as a
left join tracks as t on t.album_id = a.id
where (a.year >= 2019) and (a.year <= 2020)
ORM
session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020)
9. duração média da faixa para cada álbum:
SQL
select a.name, AVG(t.length)
from albums as a
left join tracks as t on t.album_id = a.id
group by a.name
order by AVG(t.length)
ORM
session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(Album.id)
10. todos os artistas que não lançaram álbuns em 2020:
SQL
select distinct m.name
from musicians as m
where m.name not in (
select distinct m.name
from musicians as m
left join albums_musicians as am on m.id = am.musician_id
left join albums as a on a.id = am.album_id
where a.year = 2020
)
order by m.name
ORM
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(Musician.name.asc())
11. Os nomes das compilações em que um artista específico (Steve) está presente:
SQL
select distinct c.name
from collections as c
left join collections_tracks as ct on c.id = ct.collection_id
left join tracks as t on t.id = ct.track_id
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
where m.name like '%%Steve%%'
order by c.name
ORM
session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(Musician.name == 'Steve').order_by(Collection.name)
12. o nome dos álbuns em que artistas de mais de 1 gênero estão presentes:
SQL
select a.name
from albums as a
left join albums_musicians as am on a.id = am.album_id
left join musicians as m on m.id = am.musician_id
left join genres_musicians as gm on m.id = gm.musician_id
left join genres as g on g.id = gm.genre_id
group by a.name
having count(distinct g.name) > 1
order by a.name
ORM
session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(Genre.name)) > 1).group_by(Album.id).order_by(Album.name)
13. Nome das faixas que não estão incluídas nas coleções:
SQL
select t.name
from tracks as t
left join collections_tracks as ct on t.id = ct.track_id
where ct.track_id is null
ORM
session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None)
* note que apesar do aviso no PyCharm, você precisa compor a condição de filtragem desta forma, se você escrever como sugerido pelo IDE ("Collection.id is None"), então não funcionará.
14. artista (s) que escreveram a faixa mais curta (teoricamente, podem haver várias faixas):
SQL
select m.name, t.length
from tracks as t
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
group by m.name, t.length
having t.length = (select min(length) from tracks)
order by m.name
ORM
subquery = session_orm.query(func.min(Track.length)) session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name)
15. o nome dos álbuns que contêm o menor número de faixas:
SQL
select distinct a.name
from albums as a
left join tracks as t on t.album_id = a.id
where t.album_id in (
select album_id
from tracks
group by album_id
having count(id) = (
select count(id)
from tracks
group by album_id
order by count
limit 1
)
)
order by a.name
ORM
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name)
Como você pode ver, as perguntas acima implicam tanto na seleção simples quanto na junção de tabelas, bem como o uso de funções agregadas e subconsultas. Tudo isso pode ser feito com SQLAlchemy tanto no modo SQL quanto no modo ORM. A variedade de operadores e métodos permite que você execute uma consulta de qualquer complexidade.
Espero que este material ajude os iniciantes de forma rápida e eficiente a começar a escrever consultas.