Melodia obsessiva (vermes ingleses.) - um fenômeno conhecido e às vezes irritante. Depois que um deles fica preso na cabeça, pode ser difícil se livrar dele. A pesquisa mostrou que a chamada interação com a composição original , seja ouvindo ou cantando, ajuda a afastar a melodia intrusiva. Mas e se você não consegue lembrar o nome da música, mas só consegue cantarolar a melodia?
Ao usar os métodos existentes de comparação de uma melodia cantada com sua gravação polifônica de estúdio original, surgem várias dificuldades. O som de uma gravação ao vivo ou em estúdio com letras, backing vocals e instrumentos pode ser muito diferente do que uma pessoa canta. Além disso, por engano ou por projeto, nossa versão pode não ter exatamente o mesmo tom, tom, andamento ou ritmo. É por isso que tantas abordagens atuais para a consulta por sistema de zumbido mapeiam uma melodia cantada para um banco de dados de melodias pré-existentes ou outras versões cantadas dessa música, em vez de identificá-la diretamente. No entanto, esse tipo de abordagem geralmente se baseia em um banco de dados limitado que requer atualização manual. Hum to Search
lançado em outubroé um novo sistema de pesquisa do Google com aprendizado de máquina que permite que uma pessoa encontre uma música cantando ou apressando-a. Ao contrário dos métodos existentes, esta abordagem cria um embedding a partir do espectrograma da música, contornando a representação intermediária. Isso permite que o modelo compare nossa melodia diretamente com a gravação original (polifônica), sem precisar ter uma melodia diferente ou versão MIDI de cada faixa. Também não precisa usar lógica complexa feita à mão para extrair a melodia. Esta abordagem simplifica muito o banco de dados do Hum to Search, permitindo que você adicione constantemente embeddings de faixas originais de todo o mundo, até mesmo os lançamentos mais recentes.
Como funciona
Muitos sistemas de reconhecimento de música existentes o convertem em um espectrograma antes de processar uma amostra de áudio para encontrar uma correspondência mais correta. No entanto, há um problema em reconhecer uma melodia cantada - geralmente contém relativamente pouca informação, como neste exemplo da música "Bella Ciao" . A diferença entre a versão cantada e o mesmo segmento da gravação de estúdio correspondente pode ser visualizada usando os espectrogramas mostrados abaixo:

Visualização do trecho cantado e sua gravação em estúdio
Dada a imagem da esquerda, a modelo deve encontrar o áudio que corresponda à imagem da direita em um acervo de mais de 50 milhões de imagens semelhantes (correspondendo a segmentos de gravações de estúdio de outras músicas). Para fazer isso, o modelo deve aprender a focar na melodia dominante e ignorar os backing vocals, instrumentos e timbre da voz, bem como as diferenças decorrentes de ruído de fundo ou reverberação. Para determinar a olho nu a melodia dominante que pode ser usada para comparar os dois espectrogramas, você pode procurar semelhanças nas linhas na parte inferior das imagens acima.
Tentativas anteriores de implementar o reconhecimento de música, em particular música em cafés ou clubes, demonstraram como o aprendizado de máquina pode ser aplicado a esse problema. Now Playing , lançado em 2017 para telefones Pixel, usa uma rede neural profunda integrada para reconhecer músicas sem a necessidade de uma conexão de servidor, e Sound Search , que mais tarde desenvolveu a tecnologia, usa reconhecimento baseado em servidor para pesquisar com rapidez e precisão mais de 100 milhões de músicas. Também precisamos aplicar o que aprendemos nesses lançamentos para reconhecer a música de uma biblioteca igualmente grande, mas já das passagens cantadas.
Configurar o aprendizado de máquina
O primeiro passo na evolução do Hum to Search foi mudar os modelos de reconhecimento de música usados em Now Playing e Sound Search para trabalhar com gravações de melodias. Basicamente, muitos mecanismos de pesquisa semelhantes (como reconhecimento de imagem) funcionam de maneira semelhante. No processo de treinamento, a rede neural recebe um par (melodia e a gravação original) como entrada e cria seus embeddings, que posteriormente serão usados para combinar com a melodia cantada.

Configurando o treinamento da rede neural
Para garantir o reconhecimento do que estamos cantando, os encaixes de pares de áudio com a mesma melodia devem estar localizados próximos um do outro, mesmo que tenham acompanhamento instrumental e vozes cantadas diferentes. Os pares de áudio contendo melodias diferentes devem estar distantes. No processo de treinamento, a rede recebe esses pares de áudio até aprender a criar embeddings com essa propriedade.
Em última análise, o modelo treinado será capaz de gerar embeddings para nossas músicas, semelhantes aos embeddings de gravações originais de músicas. Nesse caso, encontrar a música certa é apenas uma questão de pesquisar no banco de dados por embeddings semelhantes calculados com base em gravações de áudio de música popular.
Dados de treinamento
Como o treinamento do modelo exigia pares de músicas (gravadas e cantadas), o primeiro desafio era obter dados suficientes. Nosso conjunto de dados original consistia principalmente de fragmentos cantados (poucos deles continham apenas o zumbido de um motivo sem palavras). Para tornar o modelo mais confiável, durante o treinamento, aplicamos aumento a esses fragmentos: mudamos o tom e o ritmo em uma ordem aleatória. O modelo resultante funcionou bem o suficiente para exemplos em que a música foi cantada em vez de cantarolada ou assobiada.
Para melhorar o desempenho do modelo em melodias sem palavras, geramos dados de treinamento adicionais com "zumbido" artificial do conjunto existente de dados de áudio. Para isso, usamos SPICE , um modelo de extração de pitch desenvolvido por nossa equipe estendida como parte de um projetoFreddieMeter . O SPICE extrai os valores de pitch de um determinado áudio, que usamos para gerar uma melodia que consiste em tons de áudio distintos. A primeira versão deste sistema transformou a passagem original aqui neste .
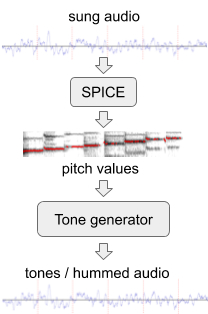
Gerando "zumbido" a partir de um fragmento de áudio cantado.
Mais tarde, melhoramos a abordagem substituindo um gerador de tons simples por uma rede neural que gera um som que lembra um zumbido real de um motivo sem palavras. Por exemplo, o trecho acima pode ser transformado em um "zumbido" ou apito .
Na última etapa, comparamos os dados de treinamento mixando e combinando trechos de áudio. Quando, por exemplo, encontramos fragmentos semelhantes de dois artistas diferentes, os alinhamos com nossos modelos preliminares e, portanto, fornecemos ao modelo um par adicional de fragmentos de áudio da mesma melodia.
Melhorando o modelo
No treinamento do modelo Hum to Search, começamos com a perda de trigêmeos , que se mostrou excelente em uma variedade de tarefas de classificação, como classificação de imagens e música gravada . Se for fornecido um par de áudio que corresponda à mesma melodia (os pontos R e P no espaço de incorporação mostrado abaixo), a função de perda de tripleto ignora certas partes dos dados de treinamento derivados da outra melodia. Isso ajuda a melhorar o comportamento de aprendizagem quando o modelo encontra outra melodia que é muito simples e já está longe de R e P (consulte o ponto E). E também quando for muito complexo para o estágio atual de treinamento do modelo e acabar muito próximo de R (ver ponto H).

Exemplos de segmentos de áudio renderizados como pontos no espaço
Descobrimos que podemos melhorar a precisão do modelo levando em consideração dados de treinamento adicionais (pontos H e E), nomeadamente formulando o conceito geral de confiança do modelo em uma série de exemplos: quão confiante é o modelo de que todos os dados, com o qual ela trabalhou pode ser classificada corretamente? Ou ela encontrou exemplos que não correspondem ao seu entendimento atual? Com base nisso, adicionamos uma função de perda que aproxima a confiança do modelo de 100% em todas as áreas do espaço de incorporação, resultando em melhor qualidade e precisão da memória de nosso modelo .
As alterações mencionadas, especificamente a combinação de dados de aumento e treinamento, permitiram que o modelo de rede neural usado na pesquisa do Google reconhecesse as músicas cantadas. O sistema atual atinge um alto nível de precisão com base em um banco de dados de mais de meio milhão de músicas que atualizamos constantemente. Esta coleção de faixas tem espaço para crescer, com mais músicas de todo o mundo por vir.
Para testar esse recurso, abra a versão mais recente do Google app, clique no ícone do microfone e diga "Que música é esta" ou clique em "Encontrar uma música". Agora você pode cantarolar ou assobiar uma melodia! Esperamos que Hum to Search ajude você a se livrar de melodias intrusivas ou apenas encontre e ouça uma faixa sem inserir seu nome.