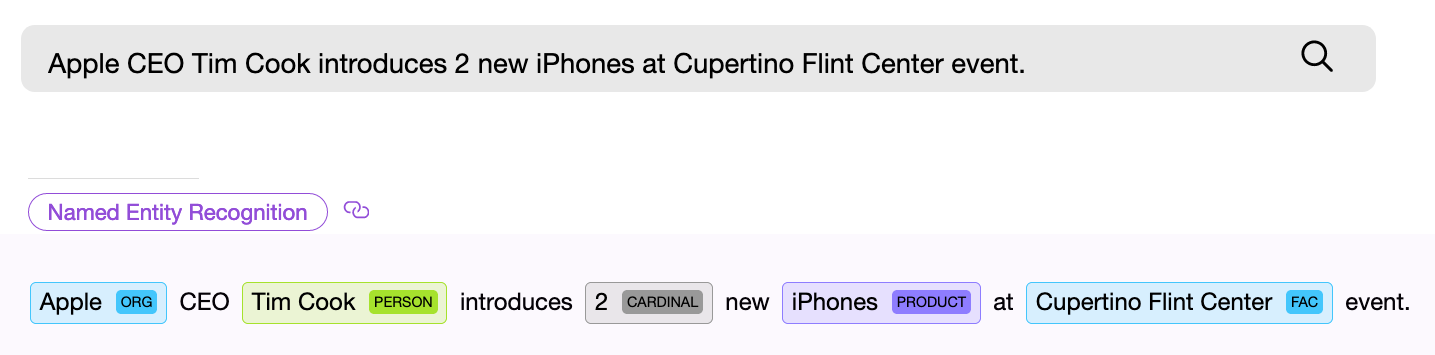
O componente NER (reconhecimento de entidade nomeada), ou seja, um componente de software para busca de entidades nomeadas, deve localizar um objeto no texto e, se possível, obter alguma informação dele. Exemplo - "Dê-me vinte e duas máscaras." O componente NER numérico encontra a frase “vinte e dois” no texto dado e extrai dessas palavras o valor normalizado numérico - “ 22 ”, agora este valor pode ser usado.
Os componentes do NER podem ser baseados em redes neurais ou funcionar com base em regras e quaisquer modelos internos. Componentes genéricos do NER geralmente usam o segundo método.
Vamos considerar várias soluções prontas para encontrar entidades padrão no texto. Nesta postagem, vamos nos concentrar em bibliotecas gratuitas ou livres com restrições e também falar sobre o que foi feito no projeto Apache NlpCraft dentro da estrutura desta edição. A lista abaixo não é uma visão geral detalhada e detalhada, da qual já existe um número suficiente na rede, mas sim uma breve descrição das principais características, prós e contras do uso dessas bibliotecas.
Fornecedores de componentes NER
Apache OpenNlp
O Apache OpenNlp fornece um conjunto razoavelmente padronizado de componentes NER para o idioma inglês, lidando com datas, horas, geografia, organizações, porcentagens numéricas e pessoas. Um pequeno conjunto também está disponível para outros idiomas (espanhol, holandês).
Entrega:
biblioteca Java. O Apache OpenNlp não fornece modelos com o projeto principal. Eles estão disponíveis para download separadamente.
Prós:
licença Apache. Os modelos foram testados em muitas implementações.
Desvantagens:
Aparentemente, os modelos foram removidos do projeto principal por um motivo. Tem-se a impressão de que o trabalho neles foi interrompido ou está avançando em um ritmo deprimente, uma vez que não se vêem novos modelos ou mudanças nos existentes há muito tempo. Como os usuários do Apache OpenNlp podem criar e treinar seus próprios modelos, é possível que essa tarefa seja deixada totalmente para eles.
Stanford Nlp
Stanford NLP é um produto dinâmico e em constante evolução, de excelente qualidade e ampla gama de possibilidades. Para o idioma inglês, foi adicionado suporte para reconhecimento das seguintes entidades: pessoa, local, organização, misc, dinheiro, número, ordinal, porcentagem, data, hora, duração, conjunto. Além disso, o componente integrado Regex NER permite que você encontre com um alto grau de precisão entidades como: e-mail, url, cidade, estado_ou_province, país, nacionalidade, religião, cargo (trabalho), ideologia, criminal_charge, causa_of_death, handle. Mais detalhes no link . Foi anunciado o suporte NER limitado para alemão, espanhol e chinês. A qualidade do reconhecimento pode ser testada usando a demonstração online .
Fornecem:
Biblioteca Java. Os modelos podem ser baixados do mavens junto com o projeto.
Não encontrei em nenhum lugar uma lista ou descrição detalhada dos componentes do NER para outros idiomas além do inglês. Links 1 , 2 - exemplos do processo de treinamento de seus próprios componentes NER para diferentes idiomas são fornecidos. Simplificando, a capacidade de usar outros idiomas é anunciada, mas você tem que mexer.
Prós:
O sentimento de trabalhar com o projeto como um todo e com modelos prontos é o mais positivo, o projeto vive e se desenvolve, a qualidade do reconhecimento é boa ("bom" é um conceito condicional, existem métricas que caracterizam a qualidade do reconhecimento dos componentes NER, mas este problema está além do escopo do artigo).
Desvantagens:
Além do caos com os documentos, eles são pequenos. Para quem é importante, preste atenção na licença. A GNU General Public License é diferente do Apache , então, por exemplo, você não pode adicionar um produto com esta licença a produtos licenciados sob Apache, etc.
API de linguagem do Google
A API de idioma do Google para inglês oferece suporte à seguinte lista de entidades: pessoa, local, organização, evento, obra_de_art, consumidor_bom, outro, número_do_telefone, endereço, data, número, preço.
Plataforma:
API REST, SaaS. Bibliotecas cliente prontas sobre REST estão disponíveis (Java, C #, Python, Go, etc.).
Prós:
Um grande conjunto de componentes NER, desenvolvimento e qualidade são fornecidos pelo conhecido gigante da Internet.
Contras: a
partir de certos volumes, o uso é pago .
Spacy
Esta biblioteca fornece um dos mais amplos conjuntos de entidades com suporte para reconhecimento, consulte o link para obter uma lista das entidades com suporte .
Plataforma:
Python.
Infelizmente, a falta de experiência pessoal de uso industrial não me permite adicionar uma descrição real dos prós e contras desta biblioteca. Além disso, uma visão geral detalhada das soluções PNL Python já foi publicada no habr.
Todas as bibliotecas acima permitem que você treine seus próprios modelos. Além disso, todos eles (exceto Apache OpenNlp) permitem extrair valores normalizados das entidades encontradas, ou seja, por exemplo, obter o número “173” da entidade numérica “cento e setenta e três” encontrada na consulta.
Como podemos ver, existem muitas opções para resolver o problema de encontrar entidades nomeadas, a direção do seu desenvolvimento é óbvia - ampliando a lista de linguagens suportadas e um conjunto de entidades reconhecidas, melhorando a qualidade do reconhecimento.
Abaixo está um resumo do que o projeto Apache NlpCraft trouxe para essa área já altamente desenvolvida.
Recursos adicionais fornecidos pela NlpCraft
- Componentes próprios do NER para novas entidades, soluções melhoradas para algumas já existentes.
- Integração de componentes NER de todas as bibliotecas acima dentro da estrutura de uso do produto.
- Suporte para "entidades compostas", que permite aos usuários criar facilmente novos componentes personalizados com base nos existentes.
Agora, sobre tudo isso com um pouco mais de detalhes.
Componentes proprietários NER
Os componentes NER nativos do Apache NlpCraft são componentes para reconhecer datas, números, geografia, coordenadas, classificação e correspondência de diferentes entidades. Alguns deles são únicos, outros são apenas uma implementação aprimorada de soluções existentes (a precisão do reconhecimento foi aumentada, campos de valor adicionais foram adicionados, etc.).
Integração de soluções existentes
Todas as soluções acima são integradas para uso com Apache NlpCraft.
Ao trabalhar com um projeto, o usuário só precisa conectar o módulo necessário e especificar na configuração quais componentes NER devem ser usados na busca por entidades de um determinado modelo.
Abaixo está um exemplo de uma configuração que usa quatro componentes NER diferentes de dois provedores ao pesquisar no texto:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Leia mais sobre como usar o Apache NlpCraft aqui . Uma conta válida de desenvolvedor do Google é necessária para usar a API de idioma do Google.
Suporte de entidade composta
O suporte para entidades compostas é o mais interessante dos recursos acima, vamos abordá-lo com mais detalhes.
Uma entidade composta é uma entidade definida com base em outra. Vejamos um exemplo. Suponha que você esteja desenvolvendo um sistema de controle de PNL baseado em intent (consulte Alexa , Google Dialogflow , Alice , Apache Nlpraft etc.) e seu modelo funcione com geografia, mas apenas para os Estados Unidos. Você pode pegar qualquer componente de pesquisa geográfica como “ nlpcraft: city ” e usá-lo diretamente.
Além disso, quando o intent é acionado, na função correspondente (retorno de chamada), você deve verificar o valor do campo " país”, E se não atender às condições exigidas, encerre a função, evitando disparos falsos. Em seguida, você deve voltar à correspondência e tentar escolher outra função mais apropriada.
O que há de errado com essa abordagem:
- Você torna muito mais difícil trabalhar com funções chamadas transferindo o controle delas para o thread de trabalho principal e vice-versa. Além disso, vale a pena considerar que nem todos os sistemas de diálogo têm essa funcionalidade de transferência de controle.
- Você confunde a lógica de correspondência entre a intenção e o código do método executável.
Ok ... Você pode criar seu próprio componente NER do zero para encontrar cidades americanas, mas essa tarefa não é resolvida em cinco minutos.
Vamos tentar de forma diferente. Você pode complicar a intenção (nesses sistemas, quando possível) e pesquisar cidades, filtradas adicionalmente por país. Mas, repito, nem todos os sistemas fornecem a possibilidade de filtragem complexa por campos de elemento, além disso, você complica os intents, que devem ser tão claros e simples quanto possível, especialmente se houver muitos deles no projeto.
O Apache NlpCraft fornece um mecanismo para definir componentes NER nativos com base nos existentes. Abaixo está um exemplo de configuração (a sintaxe DSL completa está disponível aqui , um exemplo de criação de elementos está aqui ):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
Neste exemplo, descrevemos uma nova entidade nomeada "American city" - " custom: city: usa ", com base no já existente " nlpcraft: city " filtrado por um determinado critério.
Agora você pode criar intents com base no novo elemento criado, e as cidades fora dos Estados Unidos encontradas no texto não farão com que seus intents sejam acionados indesejadamente.
Outro exemplo:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
Neste exemplo, definimos a entidade nomeada “aeroporto da cidade nos Estados Unidos” - “ custom: aeroporto: eua ”. Ao definir este elemento, não apenas filtramos as cidades de acordo com sua afiliação estadual, mas também estabelecemos uma regra adicional segundo a qual o nome da cidade deve ser precedido por qualquer sinônimo que defina o conceito de “aeroporto”. (Leia mais sobre como criar sinônimos de elementos por meio de macros - aqui ).
Elementos compostos podem ser definidos com qualquer grau de aninhamento, ou seja, se necessário, você pode projetar novos elementos com base no recém-criado “ custom: airport: usa ”. Observe também que todos os valores normalizados das entidades pai, neste caso, o elemento base “ nlpcraft: city”Também estão disponíveis no elemento“ custom: airport: usa ”e podem ser usados no corpo da função da intenção acionada.
Claro, os “blocos de construção” podem ser definidos não apenas para todos os componentes padrão suportados de OpenNlp, Stanford, Google, Spacy e NlpCraft, mas também para componentes NER personalizados, expandindo suas capacidades e permitindo que você reutilize desenvolvimentos de software existentes.
Observe que, na verdade, você não produz novos componentes para cada nova tarefa, mas simplesmente os configura ou "mistura" sua funcionalidade em seus próprios elementos.
Assim, usando "entidades compostas", um desenvolvedor pode:
- Simplifique significativamente a lógica para construir intenções, transferindo-a parcialmente para blocos de construção reutilizáveis.
- Obtenha componentes NER com novo comportamento usando mudanças de configuração sem treinamento de modelo ou codificação.
- Reutilize soluções prontas com a qualidade esperada, contando com testes ou métricas existentes.
Conclusão
Espero que uma breve visão geral dos prós e contras dos componentes NER existentes seja útil para os leitores, e entender como o Apache NlpCraft pode expandir significativamente seus recursos e adaptar as soluções existentes para novas tarefas irá acelerar o processo de desenvolvimento de seus projetos.