
Esta postagem pode ser vista como uma reformulação do material de restauração por meio do aprendizado profundo para meus amigos ou novatos. Já escrevi mais de 10 posts relacionados a abordagens para restauração de imagens usando aprendizado profundo. Agora é a hora de uma rápida visão geral do que os leitores desses artigos aprenderam, bem como de escrever uma introdução rápida para iniciantes que desejam se divertir conosco.
Terminologia

Figura: 1. Um exemplo de imagem de entrada danificada (esquerda) e resultado de restauração (direita). Imagem retirada da página Github do autor A
entrada corrompida mostrada na Figura 1 normalmente identifica: a) pixels inválidos, ausentes ou orifícios como pixels localizados em áreas a serem preenchidas; b) pixels corretos, restantes, reais que podemos usar para preencher os que faltam. Observe que podemos pegar os pixels corretos e preencher os espaços associados correspondentes.
Introdução
A maneira mais fácil de preencher as partes ausentes é copiando e colando. A ideia principal é primeiro pesquisar para encontrar as peças mais semelhantes de uma imagem a partir de seus pixels restantes ou encontrá-las em um grande conjunto de dados com milhões de imagens e, em seguida, inserir as peças diretamente nas peças que faltam. No entanto, o algoritmo de pesquisa pode ser demorado e inclui métricas de medição de distância geradas manualmente. A generalização do algoritmo e sua eficiência ainda precisam ser melhoradas.
Com abordagens de aprendizado profundo na era de big data, temos abordagens orientadas a dados para restaurações de aprendizado profundo. Com essas abordagens, geramos pixels perdidos com boa consistência e texturas finas. Vamos dar uma olhada em 10 abordagens de aprendizado profundo bem conhecidas para restauração de imagens. Tenho certeza de que você pode entender os outros artigos quando entender estes 10. Vamos começar.
Codificador de contexto (primeiro algoritmo de restauração baseado em GAN, 2016)

Figura: 2. Arquitetura de rede do codificador contextual (CE).
O codificador de contexto (CE, 2016) [1] é a primeira implementação de uma restauração baseada em GAN. Este trabalho cobre conceitos básicos úteis de tarefas de restauração. O conceito de "contexto" está associado ao entendimento da imagem como tal, a essência da ideia do codificador é camadas totalmente conectadas por canais (a camada intermediária da rede é mostrada na Figura 2). Semelhante a uma camada padrão totalmente conectada, o ponto principal é que todos os locais de item na camada anterior contribuirão para cada local de item na camada atual. Assim, a rede aprende a relação entre todos os arranjos dos elementos e obtém uma representação semântica mais profunda de toda a imagem. O CE é considerado uma linha de base, você pode ler mais sobre isso no meu post [ aqui ].
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS, 2016) [3] pode ser visto como uma versão estendida do CE [1]. Os autores deste artigo usaram CE modificado para prever as partes ausentes em uma imagem e uma rede de textura para decorar a previsão para melhorar a qualidade das partes ausentes do modelo preenchido. A ideia da rede de texturas é retirada da tarefa de transferência do estilo. Queríamos estilizar os pixels existentes mais semelhantes aos pixels gerados para melhorar os detalhes da textura local. Eu diria que este trabalho é uma versão inicial de uma estrutura de rede grosseira a fina de dois estágios. A primeira rede de conteúdo (ou seja, aqui CE) é responsável por reconstruir / prever as partes que faltam, e a segunda rede (ou seja, a rede de textura) é responsável por refinar as partes preenchidas.
Além da perda típica de reconstrução de pixel (isto é, perda de L1) e perda adversária padrão, o conceito de perda de textura proposto neste artigo desempenha um papel importante em trabalhos posteriores sobre restauração de imagem. Na verdade, a perda de textura está associada à perda de percepção e perda de estilo, que são amplamente utilizadas em muitas tarefas de geração de imagens, como transferência de estilo neural. Para saber mais sobre este artigo, você pode consultar meu post anterior [ aqui ].
GLCIC (marco na restauração da aprendizagem profunda, 2017)
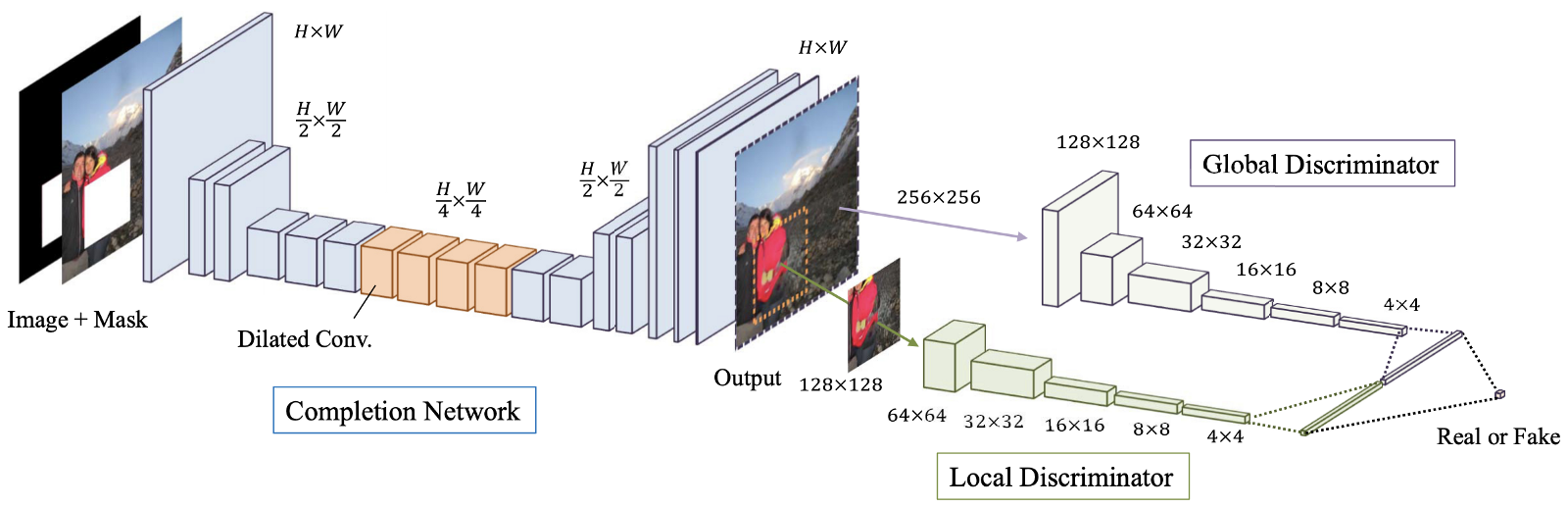
Figura: 4. Uma visão geral do modelo proposto, que consiste em uma rede de terminais (rede “Geradora”), bem como discriminadores globais e locais.
Completação de imagem globalmente e localmente consistente (GLCIC, 2017) [4] é um marco na restauração de imagens de aprendizagem profunda, pois define uma rede convolucional estendida totalmente convolucional para esta área e é de fato uma arquitetura de rede típica na restauração de imagens. Usando convoluções avançadas, a rede é capaz de entender o contexto de uma imagem sem o uso de caras camadas totalmente conectadas e, portanto, pode lidar com imagens de tamanhos diferentes.
Além da rede totalmente convolucional com convoluções estendidas, dois discriminadores em duas escalas também foram treinados junto com a rede do gerador. O discriminador global olha para a imagem inteira, enquanto o discriminador local olha para a área central sendo preenchida. Com discriminadores globais e locais, a imagem preenchida tem melhor consistência global e local. Observe que muitos dos artigos mais recentes sobre restauração de imagens seguem este design de discriminador multi-escala. Se você estiver interessado, leia meu post anterior [ aqui ] para mais informações.
Restauração baseada em patch GAN (variação GLCIC, 2018)

Figura: 5. Proposta de arquitetura de ResNet gerador e discriminador PGGAN.
A restauração baseada em patch usando GANs [5] pode ser considerada uma variante do GLCIC [4]. Simplificando, dois conceitos avançados, aprendizagem residual [6] e PatchGAN [7], são incorporados ao GLCIC para melhorar ainda mais o desempenho. Os autores deste artigo combinaram junção residual e convolução estendida para formar um bloco residual estendido. O discriminador GAN tradicional foi substituído pelo discriminador PatchGAN para promover melhores detalhes de textura local e consistência global.
A principal diferença entre o discriminador GAN tradicional e o discriminador PatchGAN é que o discriminador GAN tradicional fornece apenas um rótulo preditivo (0 a 1) para indicar o realismo do sinal de entrada, enquanto o discriminador PatchGAN fornece uma matriz de rótulos (também 0 a 1 ) para indicar o realismo de cada área local do sinal de entrada. Observe que cada elemento da matriz representa uma área local dos dados de entrada. Você também pode conferir uma visão geral do aprendizado residual e do PatchGAN [ visitando este meu post ].
Shift-Net (Deep Learning Copy and Paste, 2018)

Figura: 6. Arquitetura de rede Shift-Net. A camada de junção-deslizamento é adicionada na resolução de 32x32.
O Shift-Net [8] tira proveito das modernas CNNs baseadas em dados e do método tradicional de "copiar e colar" de reparticionamento profundo de elementos usando a camada de junção de deslocamento proposta. Existem duas idéias principais neste artigo.
Em primeiro lugar, os autores propuseram uma perda de marco que faz com que os elementos decodificados das partes faltantes (dada a parte oculta da imagem) fiquem próximos aos elementos codificados das partes faltantes (dado o bom estado da imagem). Como resultado, o processo de decodificação pode compensar as partes ausentes com sua estimativa razoável na imagem em boas condições (isto é, a fonte da verdade para as partes ausentes).
Em segundo lugar, a camada de deslocamento de junção proposta permite que a rede pegue emprestado com eficiência informações fornecidas por seus vizinhos mais próximos fora das partes ausentes para refinar a estrutura semântica global e os detalhes da textura local das partes geradas. Simplificando, fornecemos links pertinentes para refinar nossa avaliação. Acho que os leitores interessados em restauração de imagens acharão útil consolidar as idéias sugeridas neste artigo. Eu recomendo fortemente que você leia o post anterior [ aqui ] para detalhes.
DeepFill v1 (Breakthrough Image Restoration, 2018)

Figura: 7. Arquitetura de rede do framework proposto.
A restauração gerativa com atenção contextual (CA, 2018), também chamada de DeepFill v1 ou CA [9], pode ser considerada uma versão estendida ou variante do Shift-Net [8]. Os autores desenvolvem a ideia de copiar e colar e oferecem uma camada de atenção contextual que é diferenciável e totalmente convolutiva.
Semelhante à camada de deslocamento de junção em [8], combinando os elementos gerados dentro dos pixels ausentes e as características fora dos pixels ausentes, podemos descobrir a contribuição de todos os elementos fora dos pixels ausentes para cada local dentro dos pixels ausentes. Portanto, a combinação de todos os elementos externos pode ser usada para refinar os elementos gerados dentro dos pixels ausentes. Em comparação com a camada de junção de cisalhamento, que procura apenas os recursos mais semelhantes (ou seja, uma atribuição difícil e não diferenciável), a camada CA neste artigo usa uma atribuição suave e diferenciável, na qual todos os recursos têm seus próprios pesos para indicar sua contribuição para cada lugar dentro de pixels ausentes. Para saber mais sobre atenção contextual, leia meu post anterior [ aqui], você encontrará exemplos mais específicos.
GMCNN (CNNs multicolunas para restauração de imagem, 2018)

Figura: 8. A arquitetura da rede proposta.
Redes Neurais Convolucionais Multicolunas Gerativas (GMCNN, 2018) [10] estendem a importância de campos receptivos suficientes para restauração de imagem e oferecem novas funções de perda para melhorar ainda mais os detalhes de textura local do conteúdo gerado. Conforme mostrado na Figura 9, há três ramificações / colunas e cada ramificação usa três tamanhos de filtro diferentes. A utilização de vários campos receptivos (tamanhos de filtros) se deve ao fato de que o tamanho do campo receptivo é importante para a tarefa de restauração da imagem. Uma vez que não há pixels vizinhos locais, é necessário tomar emprestado informações de locais distantes espacialmente para preencher os pixels ausentes locais.
Para as funções de perda propostas, a ideia básica por trás da perda Implicit Diversified Markov Random Field (ID-MRF) é direcionar os fragmentos gerados de elementos para encontrar seus vizinhos mais próximos fora das áreas ignoradas como referências, e esses vizinhos mais próximos devem ser diversificado o suficiente para que mais detalhes de textura local possam ser modelados. Na verdade, essa perda é uma versão aprimorada da perda de textura usada no MSNPS [3]. Eu recomendo fortemente que você leia meu post [ aqui ] para uma explicação detalhada dessa perda.
PartialConv (empurra as limitações de restauração por meio de aprendizado profundo para vazios irregulares, 2018)

. 9. , .
(PartialConv ou PConv) [11] expande os limites do aprendizado profundo na restauração de imagens, oferecendo uma maneira de lidar com imagens latentes com vários orifícios irregulares. Obviamente, a ideia principal deste artigo é a dobra parcial. Ao usar o PConv, os resultados da convolução dependerão apenas dos pixels permitidos, portanto, temos controle sobre as informações transmitidas na rede. Este é o primeiro trabalho de restauração de imagens a tratar de vazios irregulares. Observe que os modelos de restauração anteriores foram treinados em imagens danificadas corretas, portanto, esses modelos não são adequados para imagens de restauração com vazios incorretos.
Eu forneci um exemplo simples para explicar claramente como a dobra parcial é realizada em meu post anterior [ aqui] Visite o link para detalhes. Espero que você aproveite.
EdgeConnect - Outlines First, Colors Then, 2019

Figura: 10. Arquitetura de rede EdgeConnect. Como você pode ver, existem dois geradores e dois discriminadores.
EdgeConnect[12]: Restauração de imagem generativa usando Adversarial Edge Learning (EdgeConnect) [12] apresenta uma maneira interessante de resolver o problema de restauração de imagem. A ideia principal deste artigo é dividir a tarefa de restauração em duas etapas simplificadas, ou seja, prever as bordas e completar a imagem com base no mapa de bordas previsto. As bordas nas áreas ausentes são previstas primeiro e, em seguida, a imagem é concluída de acordo com a previsão das bordas. A maioria dos métodos usados neste artigo foi abordada em minhas postagens anteriores. Uma boa olhada em como várias técnicas podem ser usadas juntas para moldar uma nova abordagem para restauração de imagens de aprendizado profundo. Talvez você desenvolva seu próprio modelo de restauração. Por favor, veja minha postagem anterior [aqui ] para saber mais sobre este artigo.
DeepFill v2 (Uma abordagem prática para restauração de imagens geradoras, 2019)

Figura: 11. Visão geral da arquitetura de rede do modelo para restauração gratuita.
Restauração de forma livre com convolução fechada(DeepFill v2 ou GConv, 2019) [13]. Este é talvez o algoritmo de restauração de imagem mais prático que pode ser usado diretamente em seus aplicativos. Pode ser pensado como uma versão aprimorada do DeepFill v1 [9], convolução parcial [11] e EdgeConnect [12]. A ideia principal do trabalho é a Convolução Gated, uma versão treinável da convolução parcial. Ao adicionar uma camada convolucional padrão adicional seguida por uma função sigmóide, é possível saber a validade de cada localização de pixel / objeto e, portanto, a entrada de esboço personalizado adicional também é permitida. Além da convolução bloqueada, SN-PatchGAN é usado para estabilizar ainda mais o treinamento do modelo GAN. Para saber mais sobre a diferença entre convolução parcial e convolução com portas, e comocomo a entrada de esboço do usuário adicional pode afetar os resultados da restauração, consulte meu último postaqui ].
Conclusão
Espero que agora você tenha um conhecimento básico sobre restauração de imagens. Acredito que a maioria das técnicas comuns usadas na restauração de imagens de aprendizado profundo foram abordadas em meus posts anteriores. Se você é um velho amigo meu, acho que agora está em posição de entender outro trabalho de restauração usando aprendizado profundo. Se você é iniciante, gostaria de recebê-lo. Eu espero que você ache este post útil. Na verdade, este post dá a você a oportunidade de se juntar a nós e aprender juntos.
Na minha opinião, ainda é difícil restaurar imagens com estruturas de cena complexas e um grande número de pixels ausentes (por exemplo, quando 50% dos pixels estão ausentes). Claro, outro desafio é a restauração de imagens de alta resolução. Todas essas tarefas podem ser chamadas de extremas. Acho que uma abordagem baseada nos últimos avanços em restauração pode resolver alguns desses problemas.
Links para artigos
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.

- Curso avançado "Machine Learning Pro + Deep Learning"
- Curso de Aprendizado de Máquina
- Treinamento para a profissão de ciência de dados
- Treinamento de analista de dados
- Curso de Python para Desenvolvimento Web
Mais cursos
Artigos recomendados
- Quanto ganha o cientista de dados: uma visão geral de salários e empregos em 2020
- Quanto ganha o analista de dados: uma visão geral de salários e empregos em 2020
- Como se tornar um cientista de dados sem cursos online
- 450 cursos gratuitos da Ivy League
- Machine Learning 5 9
- Machine Learning Computer Vision
- Machine Learning Computer Vision