
O que está acontecendo no campo das redes condicionais sem perdas
Ao longo dos anos, quando a mídia de transmissão de dados experimentou um rápido desenvolvimento, os engenheiros conseguiram encontrar muitos fenômenos que impedem a implementação bem-sucedida de redes de armazenamento e clusters de computação de alto desempenho em Ethernet: perdas, entrega de informação não garantida, deadlocks, microburst e outras coisas desagradáveis.
Como resultado, foi considerado correto construir uma rede dedicada de referência para um cenário específico:
- IB para clusters de computação de alta carga;
- FC para rede de armazenamento clássica;
- Ethernet para tarefas de serviço.
As tentativas de alcançar versatilidade se assemelhavam à ilustração.

Para algumas tarefas, os vetores podem coincidir (semelhante ao de um cisne e um lagostim), e a versatilidade situacional foi alcançada, embora com menor eficiência do que na escolha de um cenário altamente especializado.
Hoje, a Huawei vê o futuro em fábricas convergentes multitarefa e oferece a seus clientes uma solução AI Fabric projetada, por um lado, para cenários de aumento de desempenho de rede sem perda (até 200 Gbps por porta de servidor em 2020) e, por outro lado, para aumentar o desempenho do aplicativos (migração para RoCEv2).
A propósito, tivemos uma postagem detalhada separada sobre o componente técnico do AI Fabric .
O que precisa de otimização
Antes de falar sobre algoritmos, faz sentido esclarecer o que exatamente eles foram projetados para melhorar.
ECN estático leva ao fato de que, com um aumento no número de servidores de envio com um único destinatário, surge um padrão de tráfego subótimo (para dizer o mínimo, estamos lidando com o chamado modelo incast muitos para um).
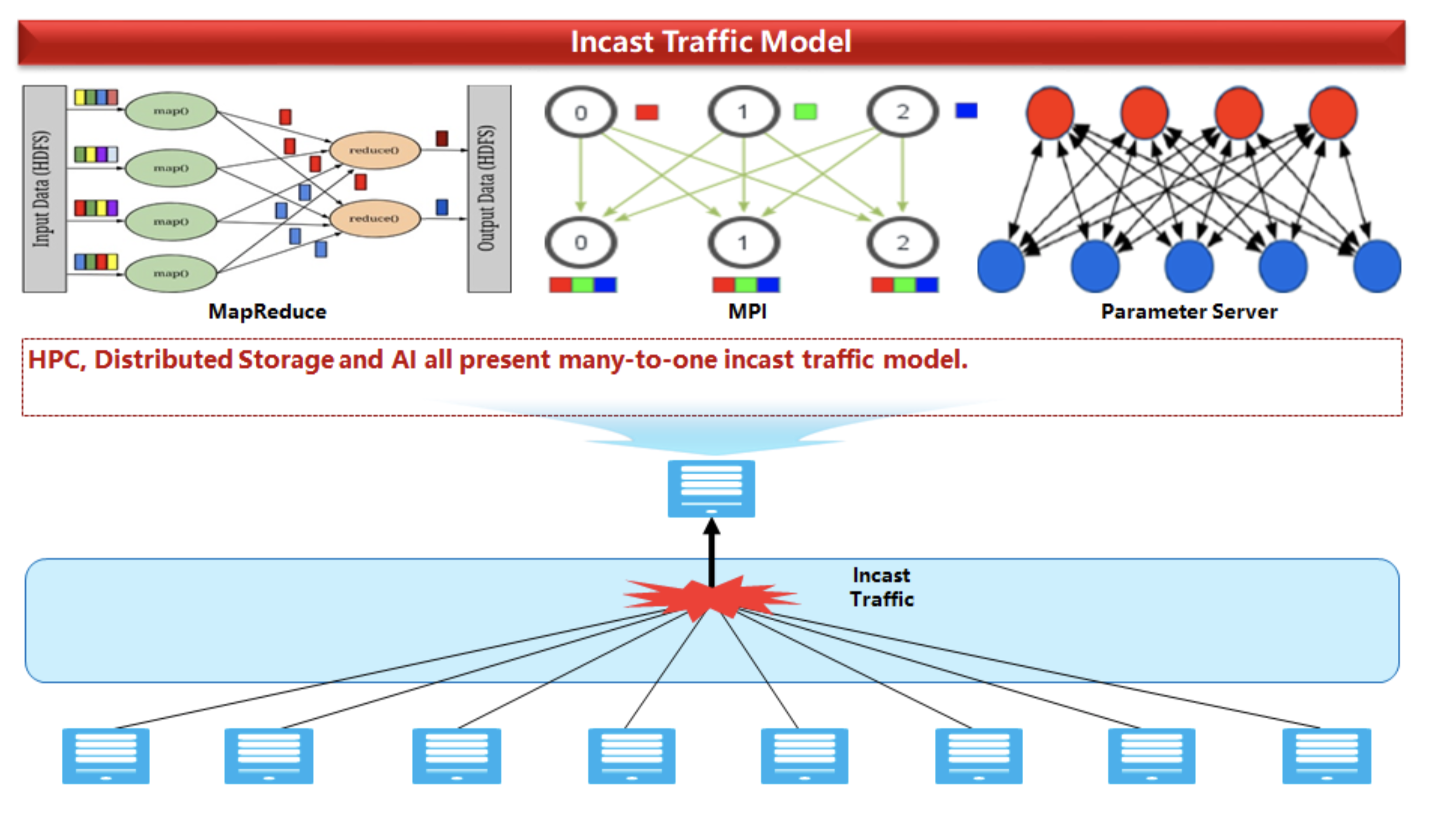
Na Ethernet tradicional , temos que equilibrar manualmente as chances de perda na rede e o baixo desempenho da própria rede.

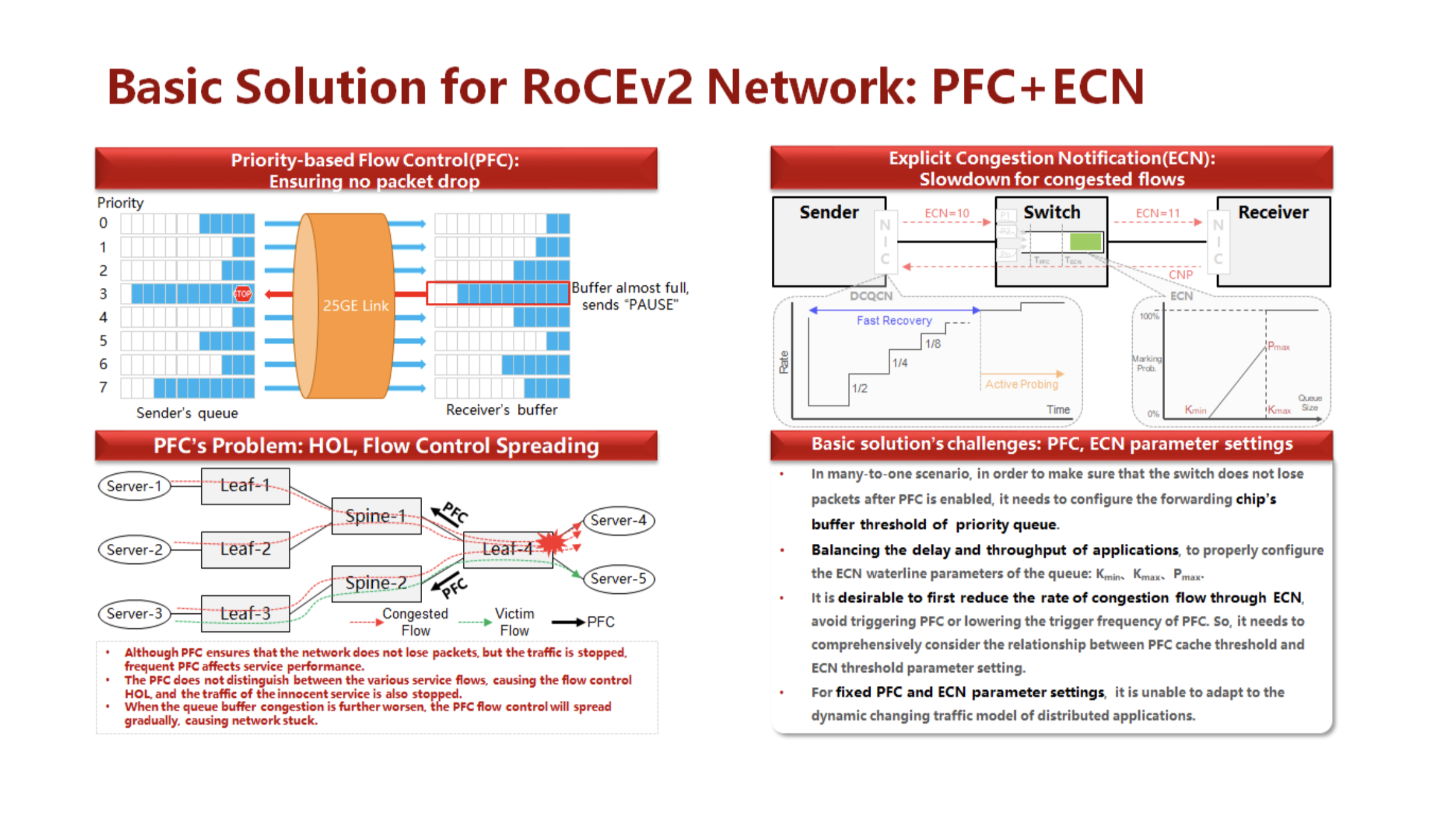
Veremos os mesmos pré-requisitos também ao usar o pacote PFC / ECN no caso de implementação sem ajuste constante (veja a figura abaixo).
Para resolver os problemas descritos, usamos o algoritmo AI ECN, cuja essência é alterar os limites ECN em tempo hábil. Sua aparência é mostrada no diagrama abaixo.
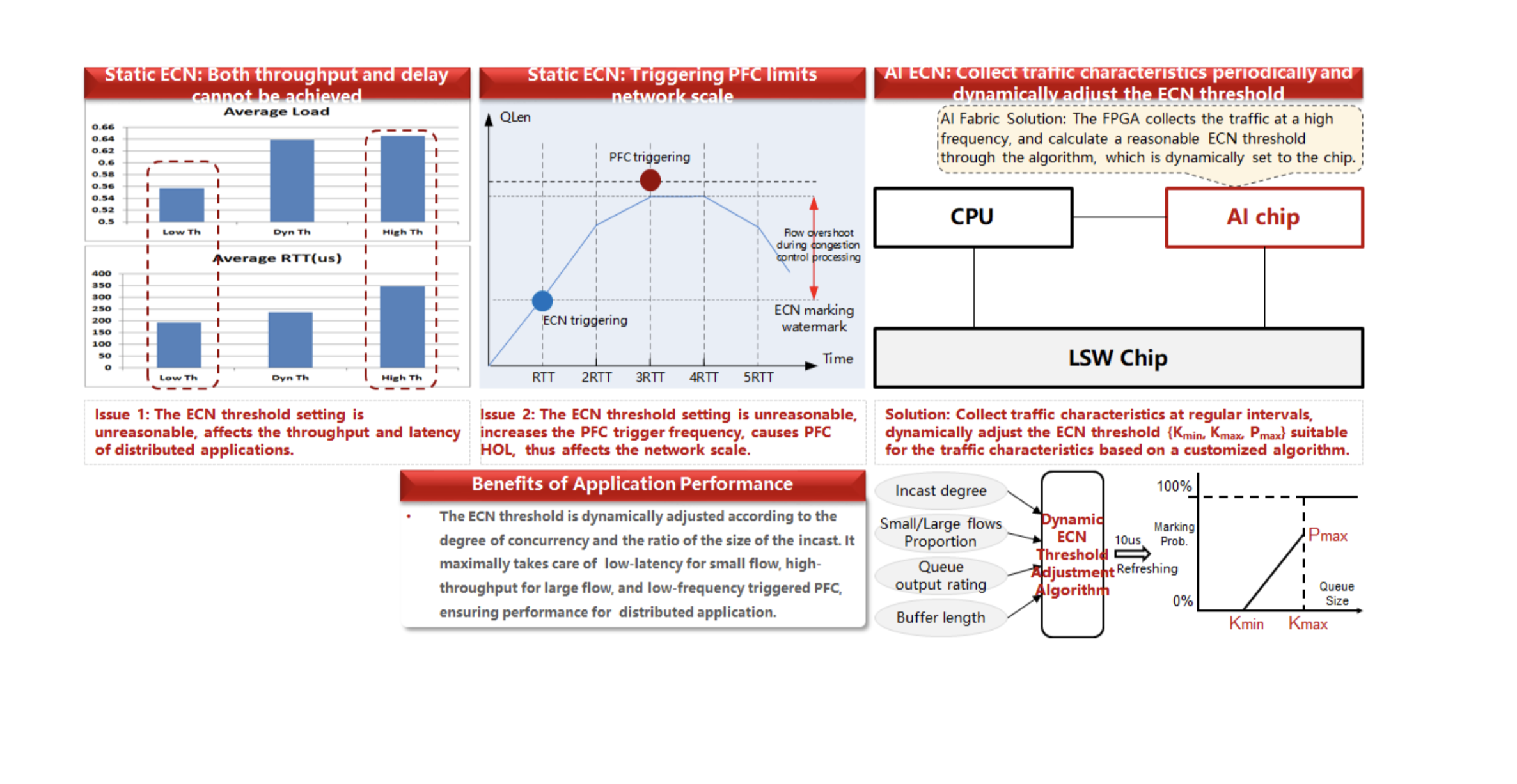
Anteriormente, quando usávamos o conjunto de processadores Broadcom chipset + Ascend 310 AI, tínhamos um número limitado de opções para ajustar esses parâmetros.
Podemos chamar condicionalmente essa variante de Software AI ECN, uma vez que a lógica é feita em um chip separado e já está “derramada” em um chipset comercial.Os modelos equipados com o chipset Huawei P5 têm "capacidades de IA" muito mais amplas (especialmente na versão mais recente), devido ao fato de que uma parte significativa da funcionalidade necessária está implementada nele.

Como usamos algoritmos
Usando o Ascend 310 (ou o módulo integrado do P-card), começamos a analisar o tráfego e compará-lo a um benchmark de aplicativos conhecidos.

No caso de aplicativos conhecidos, os indicadores de tráfego são otimizados em tempo real; no caso de aplicativos desconhecidos, ocorre a transição para a próxima etapa.

Pontos chave:
- A aprendizagem de reforço DDQN, a exploração, o acúmulo de um grande número de configurações de linha de base e a exploração da melhor estratégia de conformidade ECN são realizadas.
- O Classificador CNN identifica cenários e determina se o limite DDQN recomendado é confiável.
- Se o limite DDQN recomendado não for confiável, um método heurístico é usado para corrigi-lo para garantir que a solução seja generalizada.
Essa abordagem permite que você ajuste os mecanismos para trabalhar com aplicativos desconhecidos e, se realmente desejar, pode definir um modelo para seu aplicativo usando a API Northbound para o sistema de gerenciamento de switch.

Pontos chave:
- DDQN acumula um grande número de amostras de memória de configuração de linha de base e examina profundamente o estado da rede e a lógica de reconciliação de configuração de linha de base para aprender as políticas.
- O classificador de rede neural CNN identifica cenários para evitar riscos que podem surgir quando configurações ECN não confiáveis são recomendadas em cenários desconhecidos.
O que nós temos
Após esse ciclo de adaptação e alteração de limites e configurações de rede adicionais, torna-se possível se livrar de vários tipos de problemas de uma vez.
- Problemas de desempenho: baixa largura de banda, longa latência, perda de pacotes, jitter.
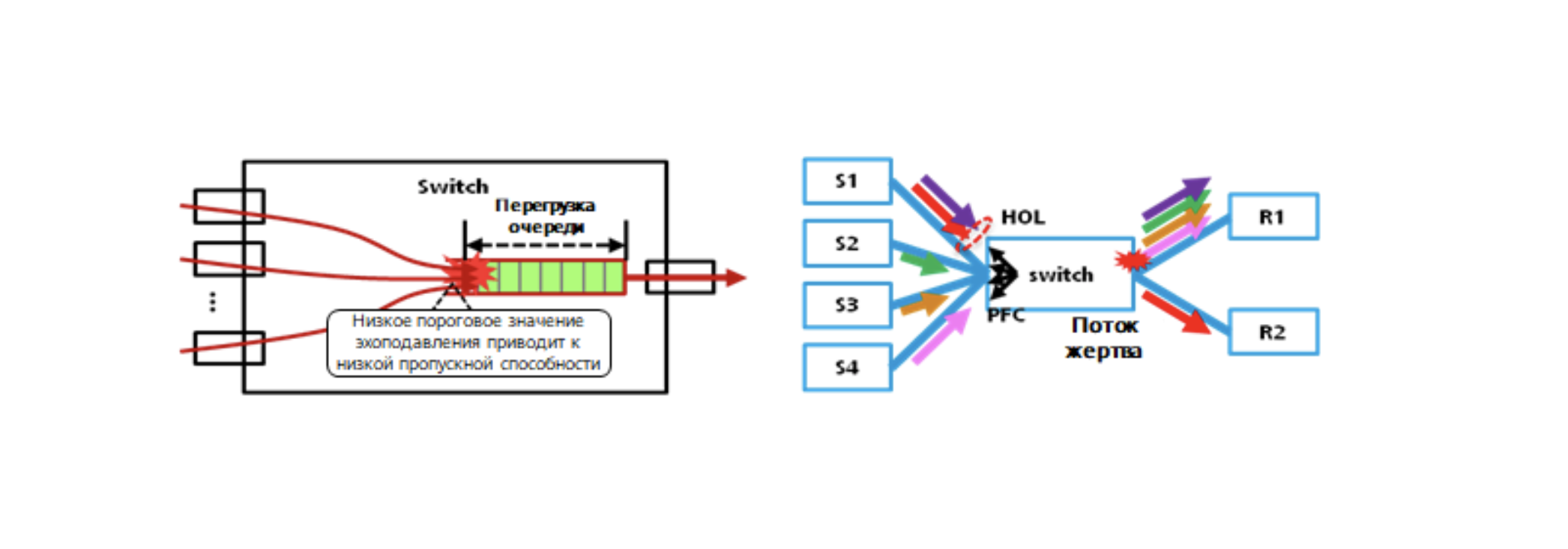
- Problemas de PFC: impasse de PFC, HOL, tempestades, etc. A tecnologia de PFC causa muitos problemas de nível de sistema.
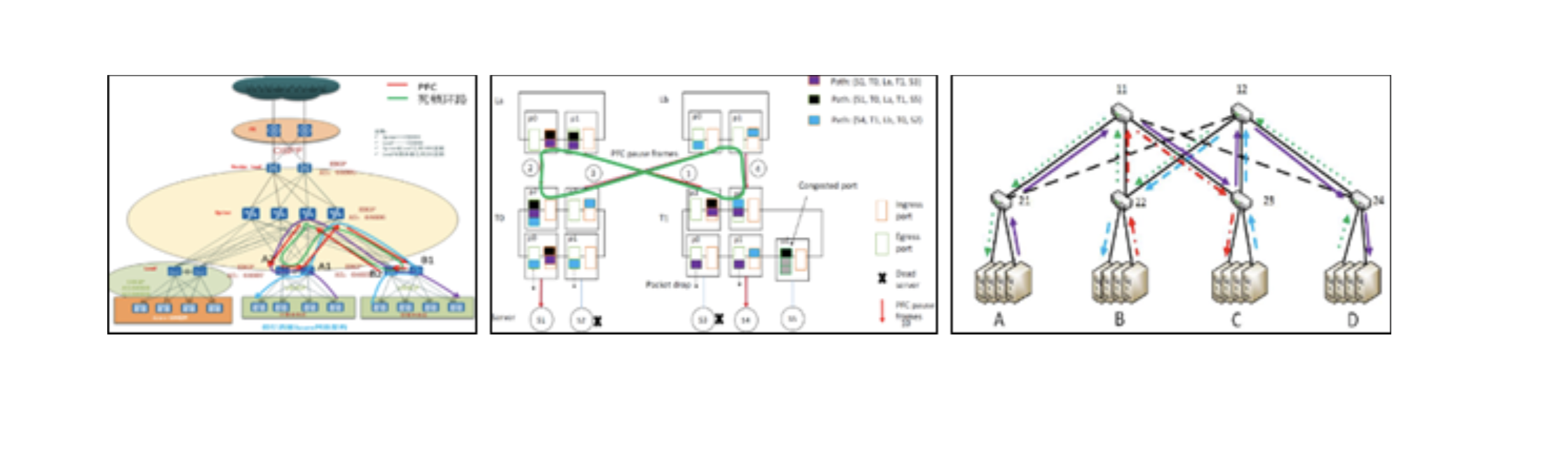
- Desafios do aplicativo RDMA: IA / computação de alto desempenho, armazenamento distribuído e combinações. Os aplicativos RDMA são sensíveis ao desempenho da rede.
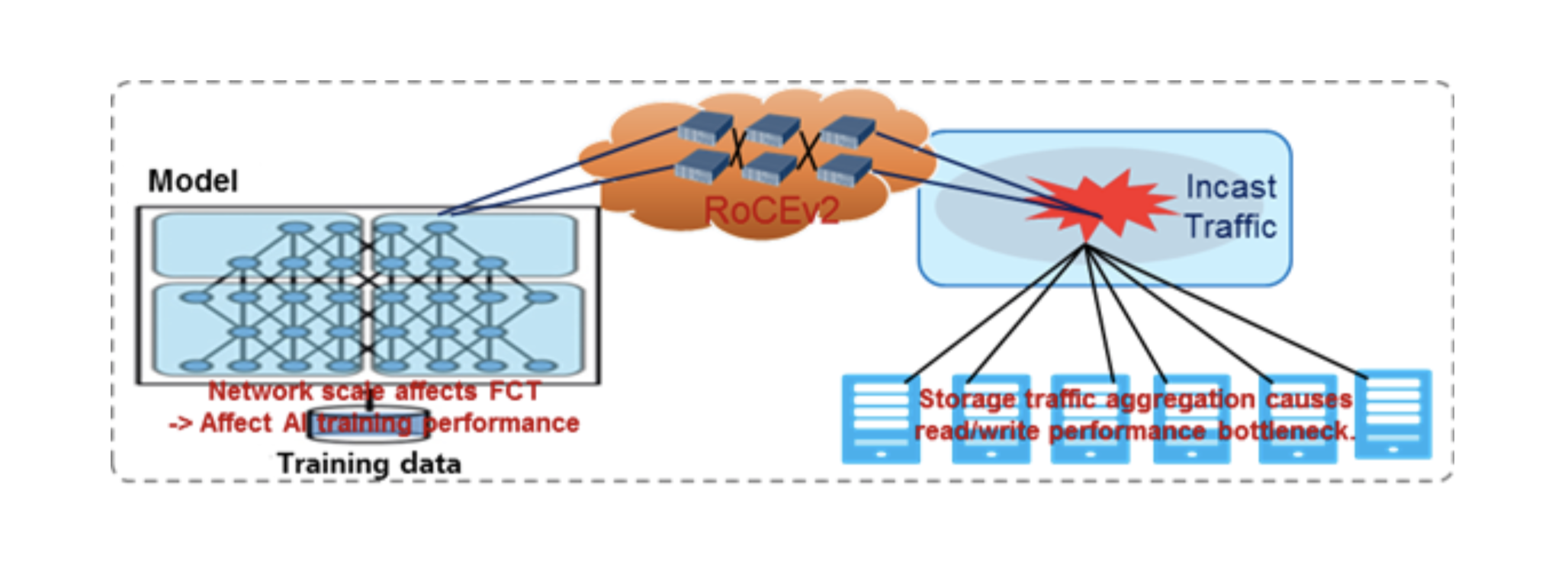
Resumo
Em última análise, algoritmos adicionais de aprendizado de máquina nos ajudam a resolver os problemas clássicos do ambiente de rede Ethernet "sem resposta". Assim, estamos um passo mais perto de um ecossistema de serviços de rede ponta a ponta transparentes e convenientes - em oposição a um conjunto de tecnologias e produtos díspares.
***
As soluções da Huawei continuam aparecendo em nossa biblioteca online . Incluindo os tópicos abordados nesta postagem (por exemplo, antes de construir soluções de IA de tamanho real para vários cenários de data centers "inteligentes"). Você pode encontrar uma lista de nossos webinars para as próximas semanas aqui .