Por que o criamos?
Por muito tempo, nós do Rambler Group usamos uma arquitetura de rede de data center de três camadas, na qual cada projeto ou componente de infraestrutura residia em um vlan dedicado. Todo o tráfego - tanto entre vlans quanto entre data centers - passou por equipamentos de nível de ponta.
Equipamentos periféricos são roteadores caros, capazes de realizar muitas funções diferentes; portanto, as portas nele também são caras. Com o tempo, o tráfego horizontal cresceu (máquina a máquina - por exemplo, replicação de banco de dados, solicitações a vários serviços, etc.) e, em algum ponto, surgiu o problema de utilização de porta em roteadores de fronteira.
Uma das principais funções de tais dispositivos é a filtragem de tráfego. Como resultado, também ficou mais difícil gerenciar o ACL: era preciso fazer tudo manualmente, além disso, a execução da tarefa pelo departamento adjacente também demorava. Tempo adicional foi gasto na configuração de portas no nível de acesso. Foi necessário realizar não apenas ações manuais dos mesmos NOCs, mas também identificar potenciais problemas de segurança, pois os hosts mudam de localização, respectivamente, podem obter acesso ilegal às vlans de outras pessoas.
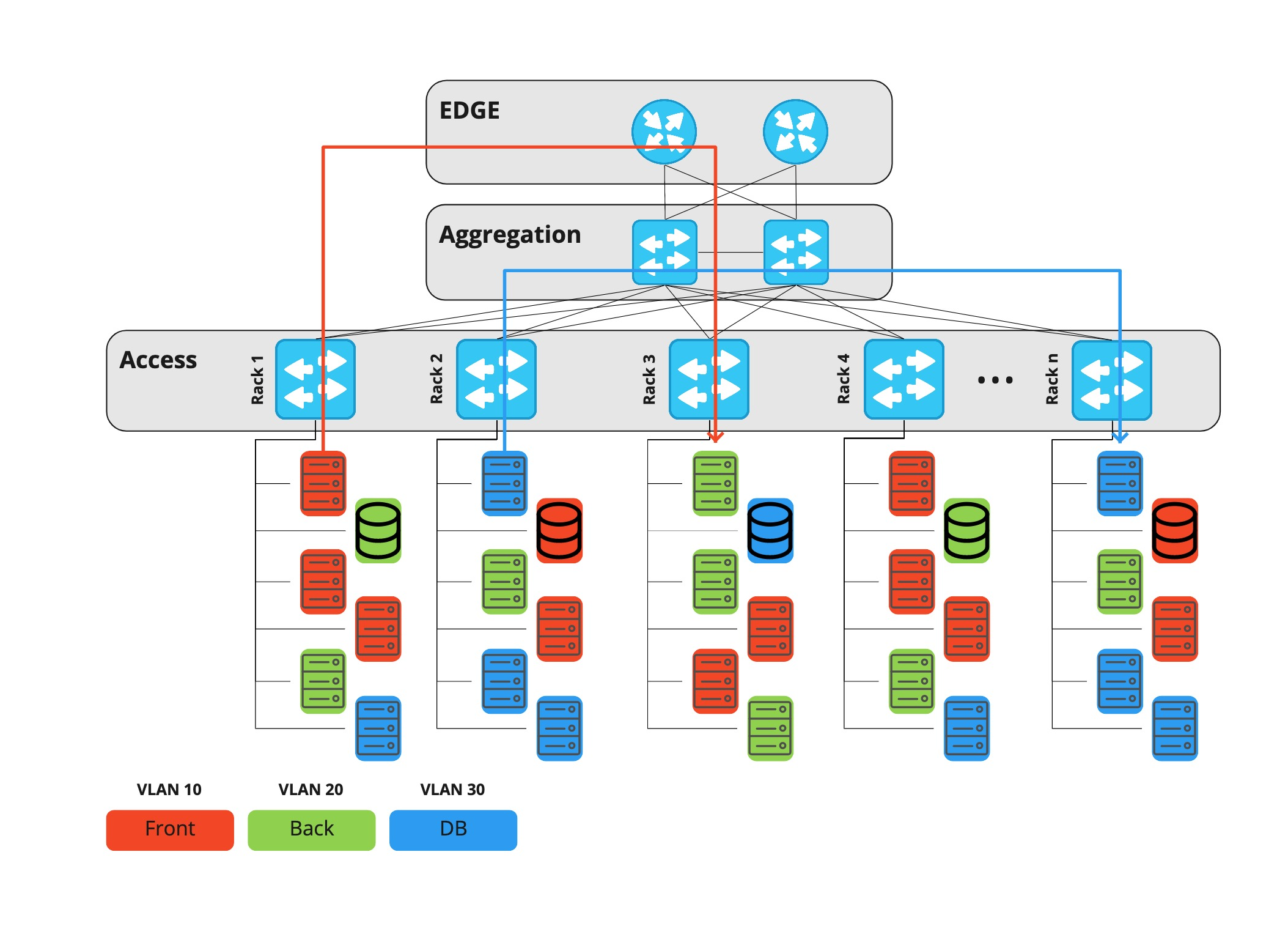
Chegou a hora de mudar alguma coisa, e as redes Clos ou, como também são chamadas, as fábricas IP vieram em seu socorro.

Apesar da semelhança externa, a diferença fundamental entre esta arquitetura e a anterior é que cada dispositivo, incluindo a camada folha, atua como um roteador, e o gateway padrão para o servidor é o Top-of-Rack. Assim, o tráfego horizontal entre quaisquer hosts de projetos diferentes agora pode passar pela camada da coluna vertebral, e não pela borda.
Além disso, no mesmo nível de coluna, podemos conectar data centers entre si, e não mais do que quatro dispositivos de rede agora estão no caminho entre dois servidores. O equipamento de ponta nesta arquitetura só é necessário para conectar operadoras de telecomunicações e só permite o tráfego vertical (de e para a Internet).
A principal característica da rede Klose é que ela carece de um local onde você pode filtrar o tráfego entre hosts. Portanto, esta função deve ser executada diretamente no servidor. Um firewall centralizado é um programa que filtra o tráfego no próprio host que recebe o tráfego.
Requisitos
A necessidade de implementar um firewall centralizado foi ditada por vários fatores ao mesmo tempo:
- consumidores finais e
- infraestrutura existente.
Portanto, os requisitos para a aplicação eram os seguintes:
- O firewall deve ser capaz de funcionar e criar regras no host e nas máquinas virtuais. Além disso, a lista de regras não deve ser diferente do ambiente em que o firewall está sendo executado. Ou seja, as regras são idênticas.
- . , – ssh, ( Prometheus), .
- , -.
- , – .
- .
- : « , ».
A nuvem do Rambler Group é bastante dinâmica: máquinas virtuais são criadas e removidas, servidores são instalados e desmontados. Portanto, não utilizamos acesso ponto a ponto, nossa infraestrutura possui o conceito de “grupo de hosts”.
Hostgroup é uma marcação de um grupo de servidores que descreve exclusivamente sua função. Por exemplo news-prod-coolstream-blue.
Isso leva a outro requisito: os usuários devem operar com entidades de alto nível - grupos de hosts, projetos e assim por diante.
Ideia e implementação
Tulling Um
firewall centralizado é algo grande e complexo que requer a configuração do agente. Encontrar problemas pode levar mais de cinco minutos, então uma ferramenta apareceu junto com o agente e o servidor, que informa ao usuário se o agente está configurado corretamente e o que precisa ser consertado. Por exemplo, um requisito importante para um host é a existência de um registro DNS no grupo de hosts ou PTR. A ferramenta informará sobre tudo isso e muito mais ( suas funções são descritas a seguir ).
Firewall unificado
Procuramos seguir o seguinte princípio: a aplicação que configura o firewall no host deve ser a única para não obter "regras de piscar". Ou seja, se o servidor já tiver sua própria ferramenta de customização (por exemplo, se as regras forem configuradas por outro agente), então nosso aplicativo não pertence a ela. Bem, a condição oposta também se aplica: se houver nosso agente de firewall, então apenas ele define as regras - aqui está o princípio do controle total.
Firewall não é iptables
Como você sabe, iptables é apenas um utilitário de linha de comando para trabalhar com netfilter. Para portar o firewall para diferentes plataformas (Windows, sistemas BSD), o agente e o servidor trabalham com um modelo próprio. Mais sobre isso a seguir, na seção "Arquitetura" .
O agente não tenta resolver erros lógicos
Conforme afirmado acima, o agente não toma nenhuma decisão. Se você quiser fechar a porta 443, que já está rodando seu servidor HTTP, não tem problema, feche-a!
Arquitetura
É difícil propor algo novo na arquitetura de tal aplicativo.
- Temos um agente, ele configura as regras no host.
- Temos um servidor, ele dá regras definidas pelo usuário.
- Temos uma biblioteca e ferramentas.
- Temos um resolvedor de alto nível - ele muda os endereços IP para grupos de hosts / projetos e vice-versa. Mais sobre tudo isso abaixo .
O Grupo Rambler possui muitos hosts e ainda mais máquinas virtuais, e todos eles, de uma forma ou de outra, pertencem a alguma entidade:
- VLAN
- Rede
- Projeto
- Grupo de host.
O último descreve a pertença do hospedeiro ao projeto e sua função. Por exemplo, news-prod-backend-api, onde: news - project; prod - seu env, neste caso é a produção; backend - função; api é uma tag personalizada arbitrária.
Resolver
Firewall funciona na camada de rede e / ou transporte, e grupos de hosts e projetos são entidades de alto nível. Portanto, para "fazer amigos" e entender quem é o dono do host (ou máquina virtual), você precisa obter uma lista de endereços - chamamos esse componente de "Resolvedor de alto nível". Ele muda os nomes de alto nível para um conjunto de endereços (em termos do resolvedor, é "contido") e, inversamente, um endereço para o nome da entidade ("contém").
Biblioteca - Core
Para a unificação e unificação de alguns componentes, surgiu uma biblioteca, também chamada de Core. Este é um modelo de dados com seus próprios controladores e visualizações que permitem que você o preencha e leia. Essa abordagem simplifica muito o código do servidor e do agente e também ajuda a comparar as regras atuais no host com as regras recebidas do servidor.
Temos várias fontes para preencher o modelo:
- arquivos de regra (dois tipos diferentes: simplificado e que descreve completamente a regra)
- regras recebidas do servidor
- regras recebidas do próprio host.
Agent
Agent não é um binding sobre iptables, mas um aplicativo independente que funciona usando um wrapper sobre bibliotecas C libiptc, libxtables. O próprio agente não toma decisões, apenas configura as regras no host.
A função do agente é mínima: ler os arquivos de regras (incluindo os padrão), obter dados do servidor (se estiver configurado para operação remota), mesclar as regras em um conjunto, verificar se diferem do estado anterior e, se diferente, aplique.
Outra função importante do agente é não transformar o host em uma abóbora durante a instalação inicial ou ao receber uma resposta inválida do servidor. Para evitar isso, fornecemos um conjunto de regras no pacote por padrão, como ssh, monitoramento de acesso e assim por diante. Se o agente de firewall receber um código de resposta diferente do 200º código de resposta, o agente não tentará realizar nenhuma ação e sairá do estado anterior. Mas ele não protege contra erros lógicos, se você negar acesso nas portas 80, 443, o agente ainda fará seu trabalho, mesmo quando o serviço da web estiver em execução no host.
Tulza
Tulza se destina a administradores de sistema e desenvolvedores que mantêm o projeto. O objetivo é incrivelmente simples: com um clique, obtenha todos os dados sobre o trabalho do agente. O utilitário pode fornecer informações sobre:
- o daemon do agente está em execução
- há um registro PTR para o host
- .
Essas informações são suficientes para diagnosticar problemas em um estágio inicial.
Servidor
Servidor é aplicativo + banco de dados. Toda a lógica do trabalho é realizada por ele. Um recurso importante do servidor é que ele não armazena endereços IP. O servidor funciona apenas com objetos de nível superior - os nomes hostgroup, project, etc.
As regras na base são as seguintes: Ação: Aceitar Src: projeto-B, projeto-C Dst: Projeto-B Proto: tcp Portas: 80, 443.
Como o servidor entende quais regras fornecer e para quem? Decorre dos requisitos que as regras devem ser idênticas, independentemente de onde o agente está sendo executado, seja um host ou uma máquina virtual.
Uma solicitação de um agente sempre chega ao servidor com um valor - um endereço IP. É importante lembrar que cada agente pede regras para si, ou seja, é o destino.
Para facilitar a compreensão da operação do servidor, considere o processo de obtenção de regras de host que pertencem a um projeto.
O resolver entra em jogo primeiro. Sua tarefa é alterar o endereço IP para o nome do host e, em seguida, descobrir qual entidade contém esse host. O HL-Resolver responde ao servidor que o host está contido no projeto A. HL-Resolver se refere à fonte de dados (que não mencionamos antes). Datasource é uma espécie de base de conhecimento da empresa sobre servidores, projetos, grupos de hosts, etc.
Em seguida, o servidor procura todas as regras para o projeto com destino = nome do projeto. Como não temos endereços no banco de dados, precisamos renomear os nomes dos projetos para hostenyms e, em seguida, para endereços, para que a solicitação seja enviada novamente para a fonte de dados por meio do resolvedor. HL-Resoler retorna uma lista de endereços, após a qual o agente recebe uma lista pronta de regras.
Se nosso destino for um host com máquinas virtuais, o mesmo script será executado não apenas para o host, mas também para cada máquina virtual nele.
Abaixo está um diagrama que mostra um caso simples: um host (hardware ou máquina virtual) recebe as regras para o host no Projeto-A.

Lançamentos
Não é difícil adivinhar que, com um gerenciamento de firewall centralizado, você também pode quebrar tudo centralmente. Portanto, as liberações para o agente e o servidor são realizadas em etapas.
Para o servidor - teste Blue-Green + A / B
Blue-Green é uma estratégia de implantação que envolve dois grupos de hosts. E a comutação ocorre nas porções 1,3,5,10 ... 100%. portanto, se houver problemas com a nova versão, apenas uma pequena parte dos serviços será afetada.
Para um agente, Canary
Canary (ou implantação canary) é um pouco semelhante ao teste A / B. Atualizamos apenas alguns dos agentes e analisamos as métricas. Se tudo estiver bem, pegamos outra peça maior e assim por diante até 100%.
Conclusão
Como resultado, fizemos um autoatendimento para engenheiros de sistema, que permite gerenciar o acesso à rede a partir de um ponto. Assim, nós:
- HTTP-API
- .