
Sua empresa deseja coletar e analisar dados para estudar tendências sem sacrificar a privacidade? Ou talvez você já utilize várias ferramentas para preservá-lo e queira aprofundar seus conhecimentos ou compartilhar sua experiência? Em qualquer caso, este material é para você.
O que nos levou a iniciar esta série de artigos? O NIST (Instituto Nacional de Padrões e Tecnologia) lançou o Espaço de Colaboração para Engenharia de Privacidade no ano passado- uma plataforma de cooperação, que contém ferramentas de código aberto, bem como soluções e descrições de processos necessários para o desenho da confidencialidade dos sistemas e gestão de riscos. Como moderadores deste espaço, ajudamos o NIST a coletar ferramentas de privacidade diferenciadas disponíveis na área de anonimato. O NIST também publicou a Estrutura de privacidade: uma ferramenta para melhorar a privacidade por meio do gerenciamento de riscos corporativos e um plano de ação que descreve uma série de questões de privacidade, incluindo anonimato. Agora queremos ajudar o Collaboration Space a atingir os objetivos definidos no plano de anonimato (desidentificação). Em última análise, ajude o NIST a desenvolver esta série de publicações em um guia mais profundo para privacidade diferencial.
Cada artigo começará com conceitos básicos e exemplos de aplicativos para ajudar os profissionais - como proprietários de processos de negócios ou responsáveis pela privacidade de dados - a aprender o suficiente para se tornarem perigosos (brincadeira). Depois de revisar os fundamentos, analisaremos as ferramentas disponíveis e as abordagens utilizadas nelas, que já serão úteis para aqueles que estão trabalhando em implementações específicas.
Começaremos nosso primeiro artigo descrevendo os principais conceitos e conceitos de privacidade diferencial, que usaremos em artigos subsequentes.
Formulação do problema
Como você pode estudar os dados populacionais sem afetar membros específicos da população? Vamos tentar responder a duas perguntas:
- Quantas pessoas vivem em Vermont?
- Quantas pessoas chamadas Joe Near vivem em Vermont?
A primeira questão diz respeito às propriedades de toda a população, e a segunda revela informações sobre uma pessoa específica. Precisamos ser capazes de descobrir tendências para toda a população, embora não permitindo informações sobre um indivíduo específico.
Mas como podemos responder à pergunta "quantas pessoas vivem em Vermont?" - que posteriormente chamaremos de "inquérito" - sem responder à segunda pergunta "Quantas pessoas com o nome Joe Nier vivem em Vermont?" A solução mais comum é a desidentificação (ou anonimato), que consiste em remover todas as informações de identificação do conjunto de dados (doravante, acreditamos que nosso conjunto de dados contém informações sobre pessoas específicas). Outra abordagem é permitir apenas consultas agregadas, por exemplo, com uma média. Infelizmente, agora já sabemos que nenhuma das abordagens fornece a proteção de privacidade necessária. Dados anônimos são o alvo de ataques que estabelecem links com outros bancos de dados. A agregação protege a privacidade apenas quando o tamanho do grupo amostrado égrande o suficiente. Mas mesmo nesses casos, ataques bem-sucedidos são possíveis [1, 2, 3, 4].
Privacidade diferencial
A privacidade diferencial [5, 6] é uma definição matemática do conceito de “ter privacidade”. Não é um processo específico, mas sim uma propriedade que um processo pode possuir. Por exemplo, você pode calcular (provar) que um determinado processo atende aos princípios de privacidade diferencial.
Simplificando, para cada pessoa cujos dados estão incluídos no conjunto de dados sendo analisado, a privacidade diferencial garante que o resultado da análise de privacidade diferencial será virtualmente indistinguível, independentemente de seus dados estarem ou não no conjunto de dados . A análise de privacidade diferencial é muitas vezes referida como um mecanismo , e iremos nos referir a ela como...
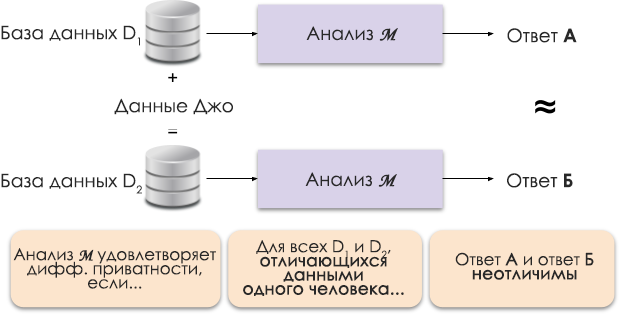
Figura 1: Representação esquemática da privacidade diferencial.
O princípio da privacidade diferencial é mostrado na Figura 1. A resposta A é calculada sem os dados de Joe e a resposta B com seus dados. E argumenta-se que ambas as respostas serão indistinguíveis. Ou seja, quem olhar os resultados não será capaz de dizer em que caso os dados de Joe foram usados e em que não foram.
Nós controlamos o nível necessário de privacidade alterando o parâmetro de privacidade ε, que também é chamado de perda de privacidade ou orçamento de privacidade. Quanto menor o valor de ε, menos distinguíveis os resultados e mais seguros os dados dos indivíduos.
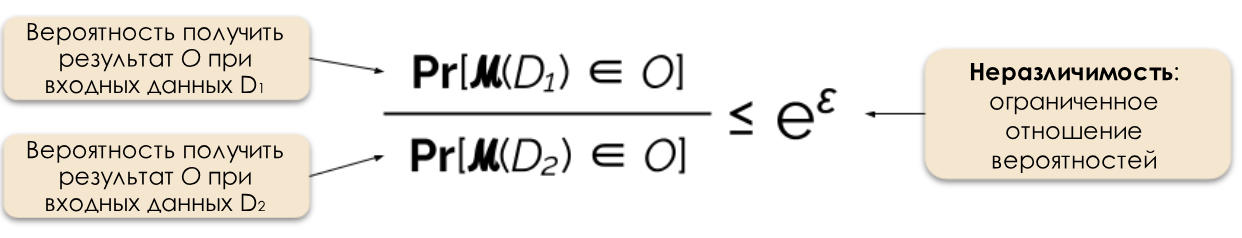
Figura 2: Definição formal de privacidade diferencial.
Frequentemente, podemos responder a uma consulta de maneira diferencial com privacidade, adicionando ruído aleatório à resposta. A dificuldade está em determinar exatamente onde e quanto ruído adicionar. Um dos mecanismos de ruído de ruído mais populares é o mecanismo de Laplace [5, 7].
O aumento das solicitações de privacidade exige mais ruído para satisfazer o valor epsilon específico da privacidade diferencial. E esse ruído adicional pode reduzir a utilidade dos resultados obtidos. Em artigos futuros, entraremos em mais detalhes sobre privacidade e o equilíbrio entre privacidade e utilidade.
Benefícios da privacidade diferencial
A privacidade diferencial tem várias vantagens importantes em relação às técnicas anteriores.
- , , ( ) .
- , .
- : , . , . , .
Devido a essas vantagens, a aplicação de métodos de privacidade diferencial na prática é preferível a alguns outros métodos. O outro lado da moeda é que essa metodologia é bastante nova e não é fácil encontrar ferramentas comprovadas, padrões e abordagens comprovadas fora da comunidade de pesquisa acadêmica. No entanto, acreditamos que a situação irá melhorar em um futuro próximo devido à crescente demanda por soluções confiáveis e simples para manter a privacidade dos dados.
Qual é o próximo?
Assine nosso blog, e em breve postaremos a tradução do próximo artigo, que fala sobre os modelos de ameaças que devem ser considerados na construção de sistemas de privacidade diferencial, além de falar sobre as diferenças entre os modelos central e local de privacidade diferencial.
Fontes
[1] Garfinkel, Simson, John M. Abowd e Christian Martindale. "Entendendo ataques de reconstrução de banco de dados em dados públicos." Communications of the ACM 62.3 (2019): 46-53.
[2] Gadotti, Andrea, et al. "Quando o sinal está no ruído: explorando o ruído pegajoso do diffix." 28º Simpósio de Segurança USENIX (USENIX Security 19). 2019.
[3] Dinur, Irit e Kobbi Nissim. "Revelar informações preservando a privacidade." Anais do vigésimo segundo simpósio ACM SIGMOD-SIGACT-SIGART sobre Princípios de sistemas de banco de dados. 2003.
[4] Sweeney, Latanya. "Dados demográficos simples geralmente identificam as pessoas de maneira única." Health (San Francisco) 671 (2000): 1-34.
[5] Dwork, Cynthia, et al. "Calibrando ruído para sensibilidade na análise de dados privados." Conferência de teoria da criptografia. Springer, Berlin, Heidelberg, 2006.
[6] Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O'Brien, Thomas Steinke e Salil Vadhan. « Privacidade diferencial: uma cartilha para um público não técnico. »Vand. J. Ent. & Tech. L. 21 (2018): 209.
[7] Dwork, Cynthia e Aaron Roth. "Os fundamentos algorítmicos da privacidade diferencial." Fundamentos e tendências em ciência da computação teórica 9, no. 3-4 (2014): 211-407.