
A URALCHEM fabrica fertilizantes. No. 1 na Rússia - para a produção de nitrato de amônio, por exemplo, está entre os 3 principais produtores domésticos de fertilizantes de amônia, ureia e nitrogênio. Ácidos sulfúricos, fertilizantes de dois ou três componentes, fosfatos e muito mais são produzidos. Tudo isso cria ambientes agressivos nos quais os sensores falham.
Construímos o Data Lake e, ao mesmo tempo, buscamos os sensores que congelam, falham, começam a fornecer dados falsos e geralmente se comportam de maneira diferente do que as fontes de informação deveriam se comportar. E o "truque" é que é impossível construir modelos matemáticos e gêmeos digitais com base em dados "ruins": eles simplesmente não resolverão o problema corretamente e darão um efeito comercial.
Mas as fábricas modernas precisam de Data Lakes para cientistas de dados. Em 95% dos casos, os dados "brutos" não são coletados de forma alguma, mas apenas os agregados no sistema de controle de processo são levados em consideração, que são armazenados por dois meses e os pontos de "mudança na dinâmica" do indicador são armazenados, que são calculados por um algoritmo especialmente estabelecido, que para os cientistas de dados reduz a qualidade dos dados, porque ., talvez, pode perder as "rajadas" do indicador ... Na verdade, algo assim aconteceu no URALCHEM. Foi necessário criar um armazém de dados de produção, recolher as fontes nas lojas e nos sistemas MES / ERP. Em primeiro lugar, isso é necessário para começar a coletar história para a ciência de dados. Em segundo lugar, para que os cientistas de dados tenham uma plataforma para seus cálculos e uma sandbox para testar hipóteses, e não carreguem a mesma onde o sistema de controle de processo está girando.Os cientistas de dados tentaram analisar os dados disponíveis, mas isso não foi suficiente. Os dados eram armazenados dizimados, com perdas, muitas vezes inconsistentes com o sensor. Não foi possível obter um conjunto de dados rapidamente e também não havia onde trabalhar com ele.
Agora vamos voltar ao que fazer se o sensor "acionar".
Quando você constrói um lago
Não basta apenas construir algo assim:
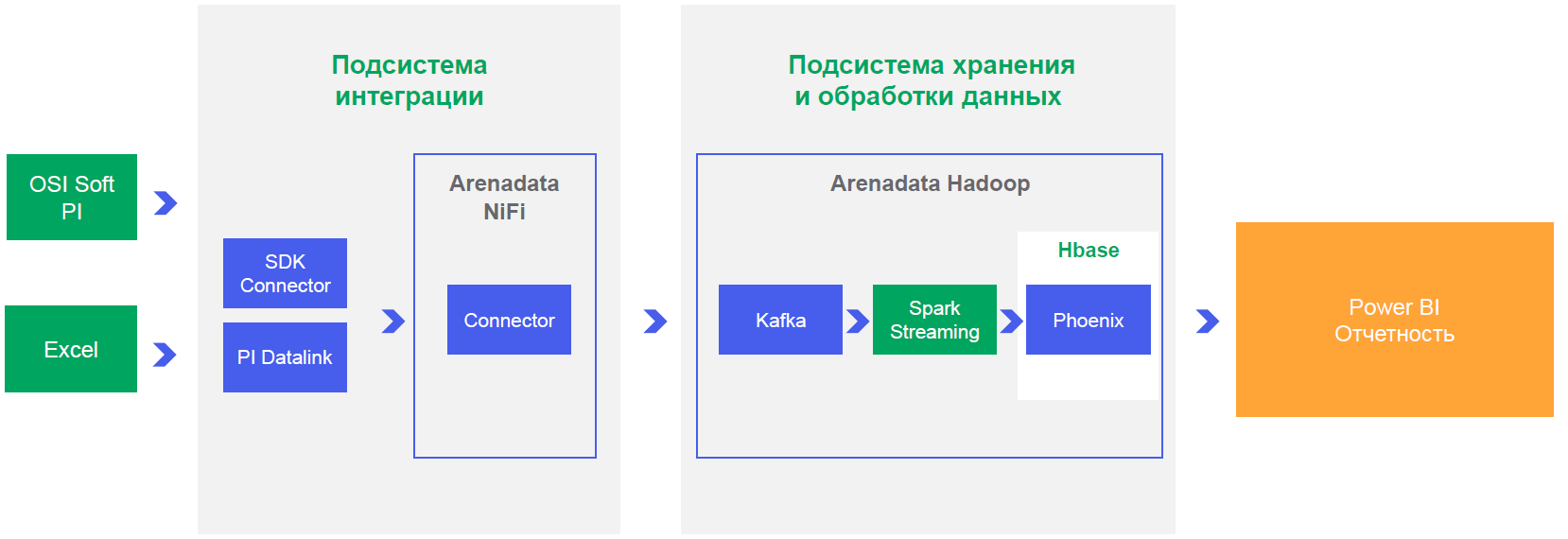
você também precisa provar para a empresa que tudo funciona e mostrar um exemplo de um projeto concluído. É claro que fazer um projeto em tal colheitadeira é sobre como construir o comunismo em um único país, mas as condições são exatamente essas. Pegamos um microscópio e provamos que eles podem cravar um prego.
Globalmente, a URALCHEM tem a tarefa de digitalizar a produção. Como parte de toda esta ação, em primeiro lugar, fazer um sandbox para testar hipóteses, melhorar a eficiência do processo de produção, bem como desenvolver modelos preditivos de falhas de equipamentos, sistemas de apoio à decisão e, assim, reduzir o número de paradas e melhorar a qualidade dos processos de produção. É quando você sabe com antecedência que algo está prestes a falhar e pode consertar uma semana antes que a máquina comece a destruir tudo ao seu redor. Benefício - na redução do custo de produção e melhoria da qualidade do produto.
Assim surgiram os critérios da plataforma e os requisitos básicos do piloto: armazenamento de grande quantidade de informações, acesso rápido aos dados dos sistemas de business intelligence, cálculos próximos do tempo real para emitir recomendações ou notificações o mais rápido possível.
Elaboramos as opções de integração e percebemos que, para desempenho e operação no modo NRT, você só precisa trabalhar por meio de seu conector, que adicionará dados ao Kafka (um corretor de mensagens escalonável horizontalmente que permite "inscrever-se no evento" de alteração da leitura do sensor deste evento em tempo real para fazer cálculos e gerar notificações). Aliás, Artur Khismatullin, chefe do departamento de desenvolvimento de sistemas de produção, uma filial da OTSO, URALCHEM JSC, nos ajudou muito.
O que é necessário, por exemplo, para fazer um modelo preditivo de falha de equipamento?
Isso requer telemetria de cada nó em tempo real ou em fatias próximas a ele. Ou seja, não uma vez por hora um status geral, mas leituras diretamente específicas de todos os sensores para cada segundo.
Ninguém coleta ou armazena esses dados. Além disso, precisamos de dados históricos de pelo menos seis meses, e no sistema de controle de processos, como eu disse, eles ficam armazenados no máximo dos últimos três meses. Ou seja, você precisa começar com o fato de que os dados serão coletados de algum lugar, gravados em algum lugar e armazenados em algum lugar. Dados de cerca de 10 GB por nó por ano.
Além disso, você precisará trabalhar com esses dados de alguma forma. Isso requer uma instalação que permite que você faça normalmente seleções no banco de dados. E é desejável que no join'ah complexo nem tudo se levante por um dia. Especialmente mais tarde, quando a produção começa a adicionar mais problemas de previsão do casamento. Bem, para reparos preditivos, há também um relatório noturno de que a máquina pode quebrar quando quebrou meia hora atrás - caso mais ou menos.
Como resultado, o lago é necessário para cientistas de dados.
Ao contrário de outras soluções semelhantes, ainda tínhamos a tarefa de tempo real no Hadoop. Porque as próximas grandes tarefas são os dados sobre a composição do material, a análise da qualidade das substâncias, o consumo de material da produção.
Na verdade, quando construímos a própria plataforma, a próxima coisa que a empresa queria de nós era que coletássemos dados sobre a falha de sensores e construíssemos um sistema que nos permitisse enviar funcionários para trocá-los ou repará-los. E, ao mesmo tempo, marca o testemunho deles como errado na história.
Sensores
Na produção - um ambiente agressivo, os sensores funcionam de forma difícil e frequentemente falham. Idealmente, um sistema de monitoramento preditivo também é necessário para sensores, mas primeiro, pelo menos avaliações de quais mentem e quais não.
Descobriu-se que mesmo um modelo simples de determinar o que está lá com o sensor é crítico para mais uma tarefa - construir um equilíbrio matemático. Planejamento adequado do processo - quanto e o que precisa ser colocado, como aquecê-lo, como processá-lo: se o planejamento estiver errado, então não está claro quanta matéria-prima é necessária. Não serão produzidos produtos suficientes - a empresa não terá lucro. Se houver mais do que o necessário - novamente uma perda, porque você precisa armazenar. O equilíbrio correto do material só pode ser obtido a partir das informações corretas dos sensores.
Portanto, em nosso projeto piloto, o monitoramento da qualidade dos dados de produção foi escolhido.
Sentamos com os tecnólogos para os dados "brutos", examinamos as falhas de equipamento confirmadas. As duas primeiras razões são muito simples.
Aqui, o sensor repentinamente começa a mostrar dados que, em princípio, não deveriam ser:
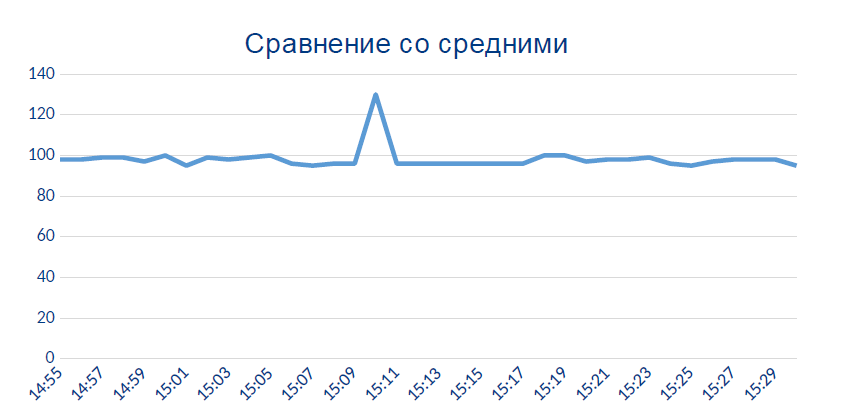
Provavelmente, este pico local é o momento em que o sensor se tornou térmico ou quimicamente ruim.
Também está indo além dos limites de medição permitidos (quando há uma quantidade física como a temperatura da água de 0 a 100). Em zero, a água não se move pelo sistema e em 200 é vapor, o que teríamos notado pela ausência de um telhado sobre a oficina.
O segundo caso também é quase trivial: os
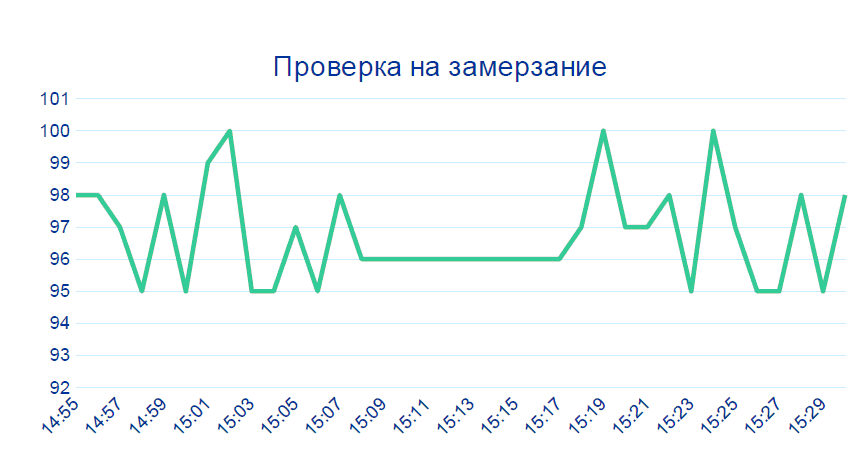
dados do sensor não mudam por vários minutos consecutivos - isso não acontece em uma produção ao vivo. Provavelmente algo com o dispositivo.
80% dos problemas são resolvidos rastreando esses padrões sem qualquer Big Data, correlações e histórico de dados. Mas, para precisão acima de 99%, precisamos adicionar outra comparação com outros sensores em nós vizinhos, em particular, antes e depois da seção de onde vem a telemetria duvidosa: A
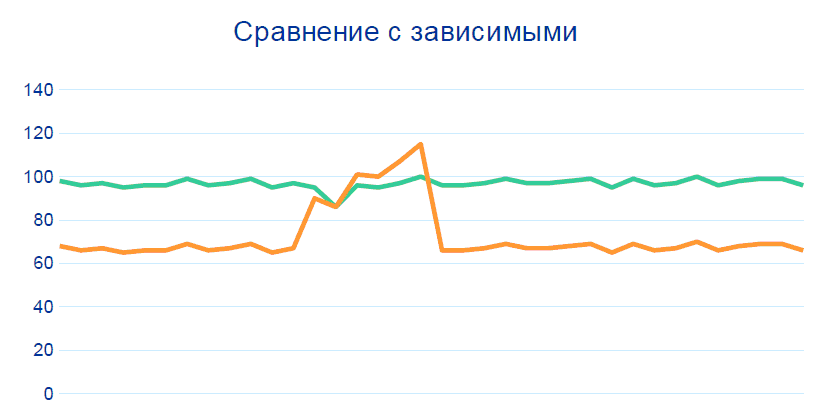
produção é um sistema equilibrado: se um indicador muda, o outro também deve mudar. No âmbito do projeto, foram formadas regras sobre a relação dos indicadores, e essas relações foram "normalizadas" pelos tecnólogos. Com base nessas diretrizes, um sistema baseado em Hadoop pode identificar sensores potencialmente inoperantes.
Os operadores da planta ficaram felizes com o fato de os sensores estarem sendo detectados corretamente, pois isso significava que eles poderiam enviar um reparador rapidamente ou simplesmente limpar o sensor desejado.
Na verdade, o piloto acabou listando sensores potencialmente inoperantes na loja que mostram informações incorretas.
Você pode perguntar como a resposta às condições de emergência e pré-emergência foi implementada antes e como ficou depois do projeto. Responderei que a reação a um acidente não diminui, porque em tal situação vários sensores mostram o problema ao mesmo tempo.
O técnico ou o chefe do departamento são responsáveis pela eficiência da instalação (e ações em caso de acidentes). Eles entendem perfeitamente o que e como está acontecendo com seus equipamentos e sabem como ignorar alguns dos sensores. Os sistemas de controle de processo que acompanham a instalação são responsáveis pela qualidade dos dados. Normalmente, quando o sensor está danificado, ele não é colocado no modo de não funcionamento. Para o tecnólogo, ele continua sendo um trabalhador, o tecnólogo deve reagir. O tecnólogo verifica o evento e descobre que nada aconteceu. É assim: “Analisamos apenas a dinâmica, não olhamos o absoluto, sabemos que estão incorretos, precisamos ajustar o sensor”. “Destacamos” aos especialistas do sistema de controle automatizado de processos que o sensor está errado e onde está errado. Agora, em vez de uma rodada formal planejada, ele primeiro conserta dispositivos específicos de maneira direcionada e, em seguida, faz as rondas, sem confiar na tecnologia.
Para deixar mais claro quanto tempo leva uma caminhada planejada, direi simplesmente que existem de três a cinco mil sensores em cada um dos locais. Fornecemos uma ferramenta analítica abrangente que fornece dados processados, com base nos quais um especialista precisa tomar uma decisão sobre a verificação. Com base em sua experiência, “destacamos” exatamente o que é necessário. Você não precisa mais verificar manualmente cada sensor, e a probabilidade de que algo seja perdido é reduzida.
Qual é o resultado
Recebida confirmação de negócios de que a pilha pode ser usada para resolver problemas de produção. Armazenamos e processamos dados do site. A empresa agora deve escolher os seguintes processos para os cientistas de dados operarem. Enquanto eles designam uma pessoa responsável pelo controle de qualidade dos dados, redigir regulamentos para ele e implementá-los em seu processo de produção.
É assim que implementamos este caso: Os
painéis têm a seguinte aparência : Eles são exibidos
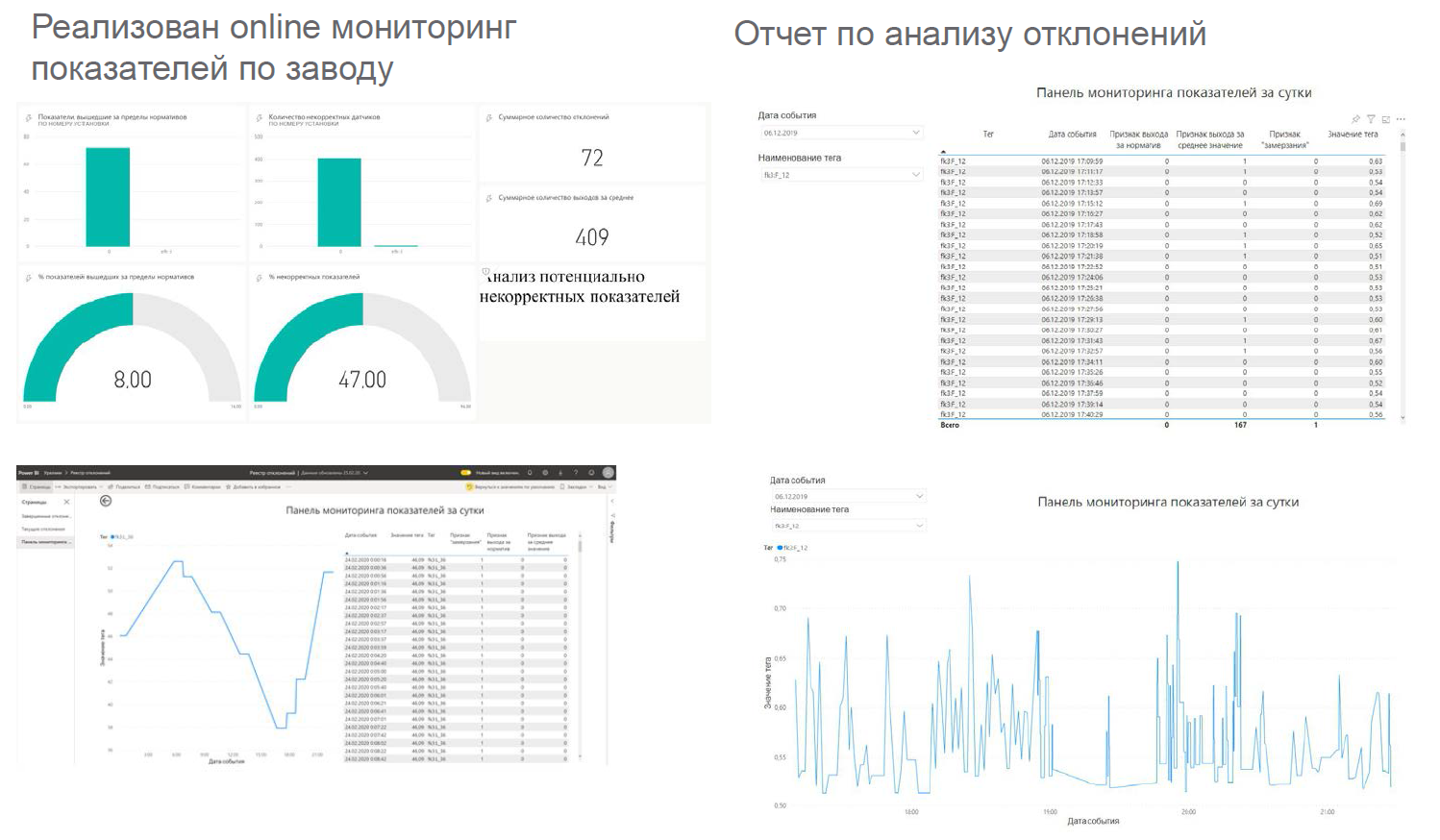
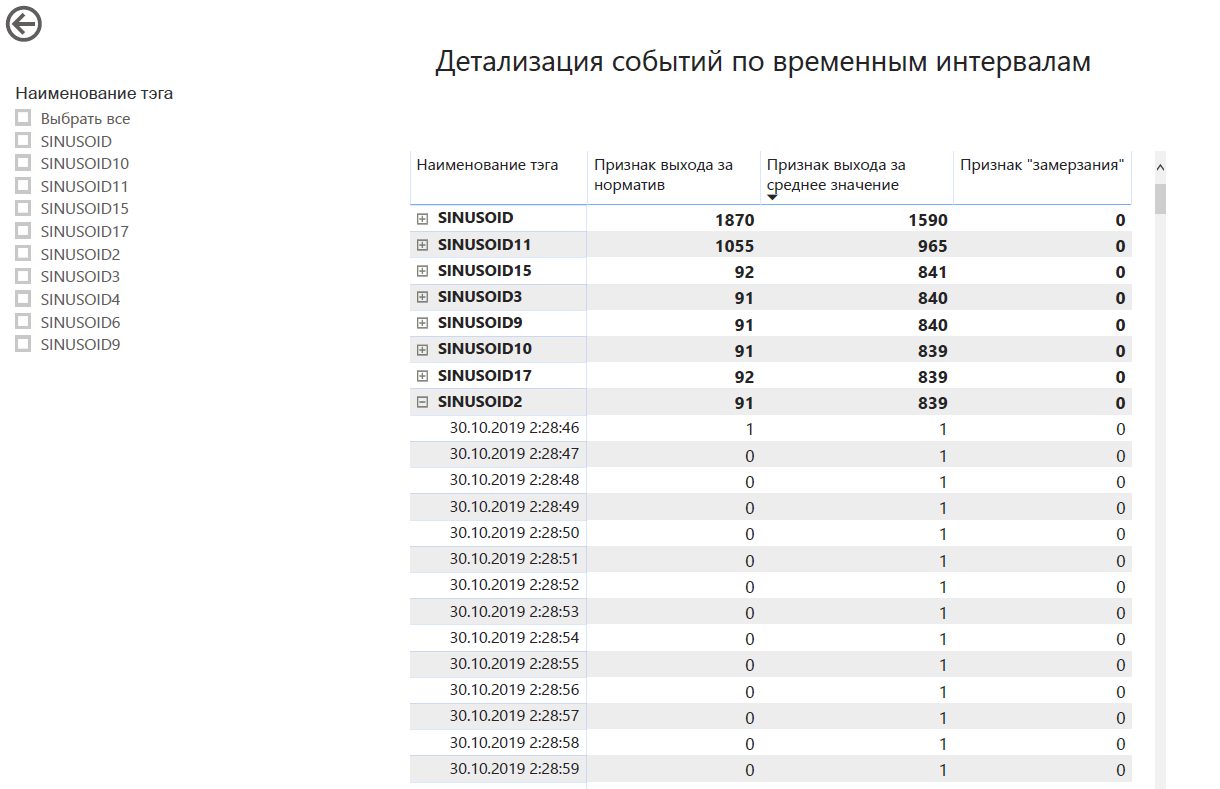
nos locais:

O que temos:
- foi criado um espaço de informação em nível tecnológico para trabalhar com leituras de sensores de equipamentos;
- verificou a capacidade de armazenar e processar dados com base na tecnologia de Big Data;
- testou a capacidade dos sistemas de business intelligence (por exemplo, Power BI) de trabalhar com um data lake construído na plataforma Arenadata Hadoop;
- foi introduzido um armazenamento analítico unificado para coletar informações de produção dos sensores dos equipamentos com a possibilidade de armazenamento de informações de longo prazo (o volume planejado de dados acumulados para o ano é de cerca de dois terabytes);
- mecanismos e métodos para obter dados em um modo quase em tempo real foram desenvolvidos;
- foi desenvolvido um algoritmo para determinar desvios e operação incorreta de sensores no modo de tempo quase real (cálculo - uma vez por minuto);
- foram realizados testes de funcionamento do sistema e possibilidade de geração de relatórios na ferramenta BI.
O resultado final é que resolvemos um problema completamente de produção - automatizamos um processo de rotina. Distribuímos uma ferramenta de previsão e liberamos tempo para que os tecnólogos resolvam problemas mais inteligentes.
E se você ainda tiver perguntas que não sejam para comentários, aqui está o e-mail - chemical@croc.ru