
Em outubro, tradicionalmente, o GPT-3 está novamente no centro das atenções. Existem várias novidades relacionadas ao modelo da OpenAI - boas e não tão boas.
OpenAI e Microsoft negociam
Teremos que começar com um menos agradável - a Microsoft assumiu os direitos exclusivos do GPT-3. O acordo previsivelmente provocou indignação - Elon Musk, o fundador da OpenAI e agora um ex-membro do conselho de diretores da empresa, disse que a Microsoft havia efetivamente adquirido a OpenAI.
O fato é que a OpenAI foi originalmente criada como uma organização sem fins lucrativos com uma grande missão - não permitir que a inteligência artificial ficasse nas mãos de um estado ou corporação separada. Os fundadores da organização defendem a abertura das pesquisas nesta área, para que a tecnologia trabalhe em benefício de toda a humanidade.
A Microsoft, em sua defesa, diz que não vai restringir o acesso à API do modelo. Assim, na verdade, nada mudou - antes que a OpenAI também não publicasse o código, mas se antes mesmo as empresas parceiras podiam trabalhar com GPT-3 apenas por meio da API, agora a Microsoft tem direitos exclusivos de uso.
ruGPT3 de Sberbank
Agora, para notícias mais agradáveis - pesquisadores do Sberbank publicaram um modelo em acesso aberto que repete a arquitetura GPT-3 e é baseado no código GPT-2 e, o mais importante, é treinado no corpus da língua russa.
Uma coleção de literatura russa, dados da Wikipedia, instantâneos de sites de notícias e perguntas e respostas, materiais dos portais Pikabu, 22century.ru banki.ru, Omnia Russica foram usados como um conjunto de dados para treinamento. Os desenvolvedores também incluíram dados do GitHub e StackOverflow para ensinar como gerar e programar código. A quantidade total de dados limpos é superior a 600 GB.
As notícias são definitivamente boas, mas há algumas advertências. Este modelo é semelhante ao GPT-3, mas não é. Os próprios autores admitemque é 230 vezes menor que a maior versão do GPT-3, que tem 175 bilhões de pesos, o que significa que não pode repetir exatamente os resultados do benchmark. Ou seja, não espere que esse modelo escreva textos indistinguíveis de textos jornalísticos.
Também vale a pena considerar que a arquitetura GPT-3 descrita pode ser diferente da implementação real. Você pode dizer com certeza apenas depois de ler os parâmetros de treinamento, e se antes os pesos foram publicados com atraso, então à luz dos eventos recentes eles não podem ser esperados.
O fato é que o orçamento do projeto depende do número de parâmetros de treinamento e, de acordo com especialistas, o treinamento do GPT-3 custou pelo menos US $ 10 milhões. Assim, apenas grandes empresas com fortes especialistas em ML e poderosos recursos de computação podem reproduzir o trabalho do OpenAI.
Relatório do Estado do AI 2020
Todos os itens acima confirmam as conclusões do terceiro relatório anual de aprendizado de máquina de última geração. Nathan Benaich e Ian Hogarth, investidores especializados em startups de IA, publicaram uma apresentação detalhada que cobre tecnologia, recursos humanos, aplicações industriais e complexidades jurídicas.
Curiosamente, até 85% das pesquisas são publicadas sem código-fonte. Se as organizações comerciais podem ser justificadas pelo fato de que o código é frequentemente tecido na infraestrutura de projetos, o que dizer das instituições de pesquisa e empresas sem fins lucrativos como DeepMind e OpenAI?
Também é dito que um aumento nos conjuntos de dados e modelos leva a um aumento nos orçamentos e, dado que o campo do aprendizado de máquina está estagnado, cada novo avanço requer orçamentos desproporcionalmente grandes (compare o tamanho do GPT-2 e GPT-3), o que significa que eles podem pagá-lo apenas grandes corporações.
Aconselhamos a leitura deste documento, pois está redigido de forma concisa, clara e bem ilustrada. Além disso, quatro previsões para 2020 do último relatório já se tornaram realidade.
Não vamos exagerar mais, ainda há boas histórias, caso contrário essa coleção não existiria.
Abra modelos multilíngues do Google e do Facebook
mT5
O Google publicou o código-fonte e o conjunto de dados da família T5 de modelos multilíngues. Devido ao hype associado ao OpenAI, esta notícia passou quase despercebida, apesar da escala impressionante - o maior modelo tem 13 bilhões de parâmetros.
Para o treinamento, um conjunto de dados de 101 idiomas foi usado, entre os quais o russo está em segundo lugar. Isso pode ser explicado pelo fato de que nosso grande e poderoso é o segundo lugar mais popular da web.
M2M-100
O Facebook também não ficou para trás e lançou um modelo multilíngue , que, segundo suas declarações, permite traduzir diretamente pares de idiomas 100x100 sem um idioma intermediário.
No campo da tradução automática, é comum criar e treinar modelos para cada idioma e tarefa individual. Mas, no caso do Facebook, essa abordagem não pode ser dimensionada de forma eficaz, pois os usuários da rede social publicam conteúdo em mais de 160 idiomas.
Normalmente, os sistemas multilíngues que lidam com vários idiomas ao mesmo tempo dependem do inglês. A tradução é mediada e imprecisa. É difícil preencher a lacuna entre os idiomas de origem e de destino devido à falta de dados, pois pode ser muito difícil encontrar uma tradução do chinês para o francês e vice-versa. Para fazer isso, os criadores tiveram que gerar dados sintéticos por tradução reversa.
O artigo fornece benchmarks, o modelo lida com tradução melhor do que análogos que dependem do inglês, bem como um link para o conjunto de dados .

Avanços na videoconferência
Em outubro, algumas notícias interessantes da Nvidia apareceram imediatamente.
StyleGAN2
Primeiro, postamos atualizações para StyleGAN2 . A arquitetura do modelo de poucos recursos agora oferece melhor desempenho em conjuntos de dados com menos de 30.000 imagens. A nova versão apresenta suporte para precisão mista: treinamento acelerado ~ 1,6x vezes, inferência ~ 1,3x vezes, consumo de GPU diminuído ~ 1,5x vezes. Também adicionamos uma seleção automática de hiperparâmetros de modelo: soluções prontas para conjuntos de dados de diferentes resoluções e um número diferente de processadores gráficos disponíveis.
NeMo
Módulos neurais é um kit de ferramentas de software livre que ajuda a criar, treinar e ajustar modelos conversacionais rapidamente. NeMo consiste em um núcleo que fornece uma única "aparência e comportamento" para todos os modelos e coleções, consistindo em módulos agrupados por escopo.
Maxine
Outro produto anunciado provavelmente usará ambas as tecnologias acima internamente. A plataforma de videochamada Maxine combina todo um zoológico de algoritmos de ML. Isso inclui a já conhecida melhoria da resolução, eliminação de ruído, remoção do fundo, mas também correção de olhares e sombras, restauração da imagem por características faciais principais (ou seja, deepfakes), geração de legendas e tradução da fala para outros idiomas em tempo real. Ou seja, quase tudo que conhecia separadamente, a Nvidia combinada em um produto digital. Agora você pode solicitar acesso antecipado.
Novos desenvolvimentos do Google
Devido à quarentena, este ano há uma verdadeira corrida pela liderança na área de videoconferência. O Google Meet compartilhou um estudo de caso de criação de seu algoritmo para remoção de fundo de alta qualidade com base na estrutura do Mediapipe (que pode rastrear o movimento dos olhos, cabeça e mãos).
O Google também lançou um novo recurso para o serviço YouTube Stories no iOS que melhora a qualidade da voz. Este é um caso interessante , porque muitas vezes mais realçadores estão disponíveis para vídeo do que para áudio. Este algoritmo rastreia e captura correlações entre a fala e os marcadores visuais, como expressões faciais, movimentos labiais, que então usa para separar a fala dos sons de fundo, incluindo vozes de outros alto-falantes.
A empresa também apresentou uma nova tentativano domínio do reconhecimento da linguagem gestual.
Por falar em software de videoconferência, também vale a pena mencionar os novos algoritmos deepfake.
MakeItTalk
Recentemente, o código do algoritmo que anima a foto, contando apenas com o stream de áudio, foi publicado em acesso aberto . Isso é digno de nota, já que geralmente os algoritmos deepfake recebem o vídeo como entrada.

Inacreditável
A nova geração de algoritmos deepfake se propõe a substituir não apenas o rosto, mas também todo o corpo, incluindo a cor do cabelo, o tom da pele e a figura. Esta tecnologia vai ser aplicada principalmente na área de compras online, de forma que você possa usar fotos de mercadorias fornecidas pela própria marca, sem ter que contratar modelos individuais. Mais aplicativos podem ser vistos no vídeo de demonstração . Até agora, não parece convincente, mas logo tudo pode mudar.
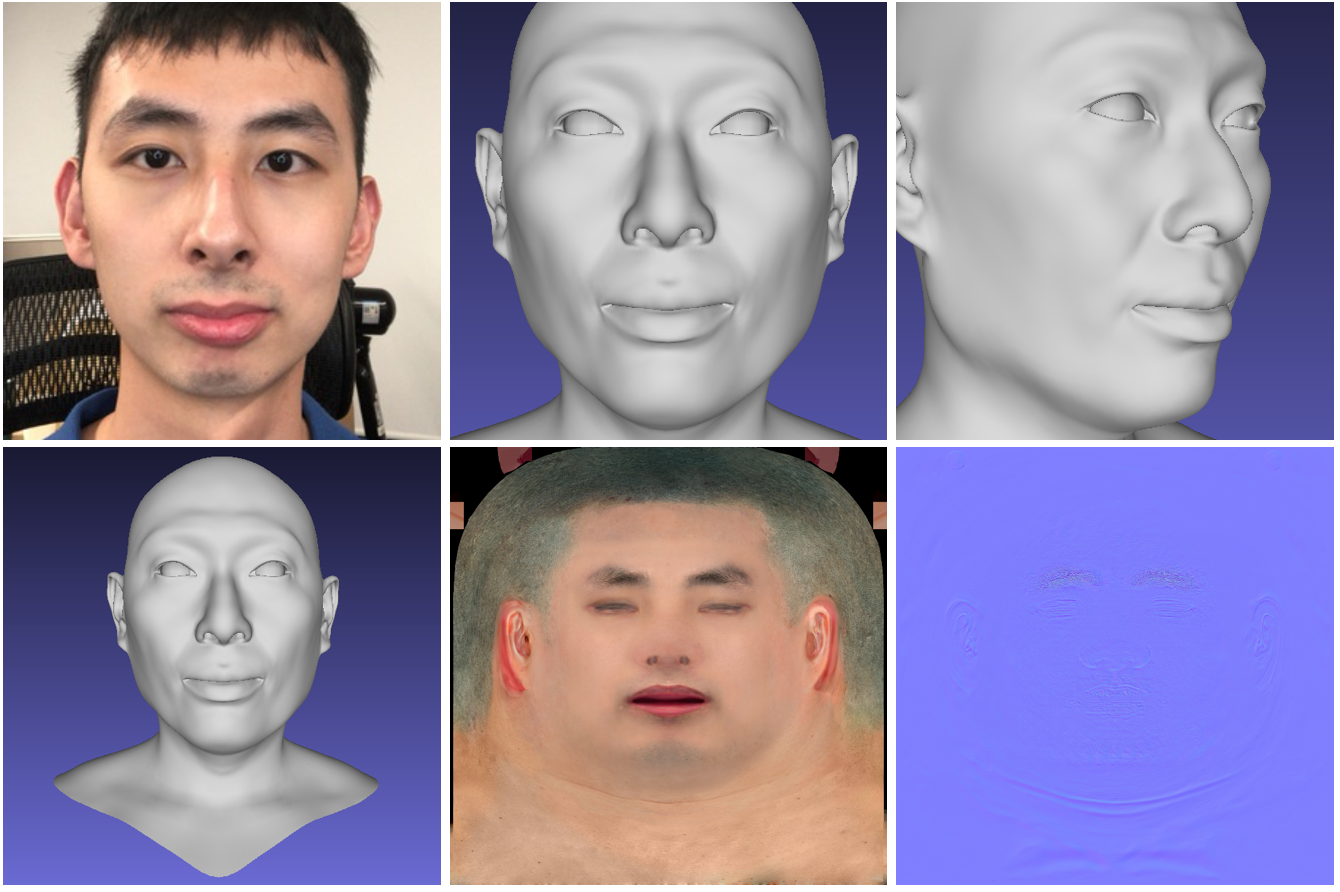
Rosto Hi-Fi 3D
A rede neural gera um modelo 3D de alta qualidade do rosto de uma pessoa a partir de fotos. O modelo recebe um vídeo curto de uma câmera RGB-D normal como entrada e, na saída, fornece um modelo 3D gerado do rosto. O código do projeto e o modelo 3DMM estão disponíveis publicamente .

SkyAR
Os autores apresentaram uma tecnologia de código aberto para substituir o céu por vídeo em tempo real, que também permite controlar os estilos. Efeitos climáticos como relâmpagos podem ser gerados no vídeo de destino.
O modelo de pipeline resolve uma série de tarefas em estágios: a grade mata o céu, rastreia objetos em movimento, envolve e redesenha a imagem para combinar com o esquema de cores do skybox.

Sea-thru
A ferramenta resolve a extraordinária tarefa de restaurar cores verdadeiras em imagens subaquáticas. Ou seja, o algoritmo leva em consideração a profundidade e a distância dos objetos para restaurar a iluminação e remover a água das imagens. Até agora, apenas conjuntos de dados estão disponíveis.
Modelo do MIT para diagnosticar Covid-19
Em conclusão, vamos compartilhar um caso interessante sobre um tópico relevante - pesquisadores do MIT desenvolveram um modelo que distingue pacientes assintomáticos com infecção por coronavírus de pessoas saudáveis usando registros de tosse forçada.
O modelo foi treinado em dezenas de milhares de fitas de áudio de amostras de tosse. De acordo com o MIT , o algoritmo identifica pessoas que foram confirmadas para ter Covid-19 com uma precisão de 98,5%.
Autoridades governamentais já aprovaram a criação do aplicativo. O usuário poderá baixar uma gravação em áudio de sua tosse e, com base no resultado, determinar se é necessário fazer uma análise completa em laboratório.
Isso é tudo, obrigado pela atenção!