Bob Steagall deu recentemente uma palestra na CppCon 2020 intitulada " Adventures in SIMD-thinking ", onde, entre outras coisas, ele falou sobre sua experiência de usar AVX512 para filtragem mediana com janela 7. Essa palestra me causou dois sentimentos: por um lado, é legal , e é considerado quase 20x mais rápido do que a implementação de STL "mais burra"; por outro lado, em uma passagem do algoritmo de 16 amostras de entrada, resultou apenas 2 saídas, embora os dados de entrada fossem suficientes para 10, e alguns detalhes de implementação me fizeram querer tentar melhorá-los. Pensei, pensei e tive uma ideia, depois outra, depois experimentei "no software" e percebi que tinha algo para compartilhar :) Então este artigo acabou.
Implementação básica
Descreverei resumidamente como isso foi feito por Bob (na verdade, uma breve releitura da parte correspondente de sua história, junto com suas próprias fotos). Ele fez as seguintes primitivas usando AVX512 (irei omitir aquelas das primitivas descritas por ele que correspondem diretamente à única operação do AVX512):
girar: girar os elementos no registro AVX-512 em um círculo

troca com transporte : troca de itens de um registrador, substituindo itens de um segundo registrador
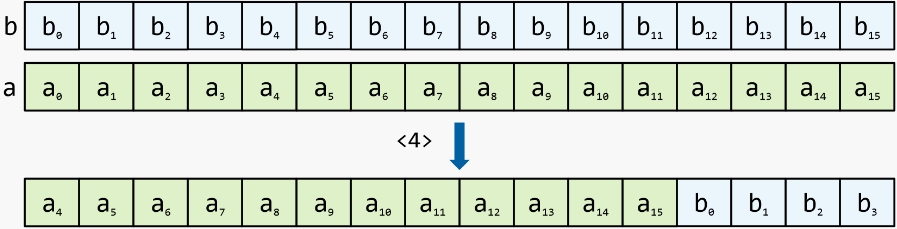
no lugar, mude com transporte : como mudança com transporte, mas os registros de entrada são passados por referência e o resultado da mudança permanece neles
compare com troca : classificação paralela até 8 pares de elementos em um registro

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
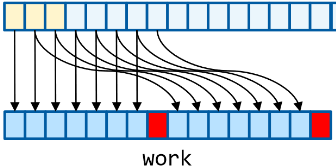
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
Acontece que nem tudo está perdido - a primeira etapa de otimização também pode ser aplicada a esta variante! É necessário coletar 32 arestas de X, é necessário confundir os dados para classificação, os dados classificados também precisam ser permutados, etc., mas apesar de todos esses gestos, o speedup é 1,27x vezes.
Não tentei fazer os passos 2 e 3, porque obviamente serão mais lentos. É bem possível que para o caso com, digamos, a janela 11, eles funcionem em um plus (mas não sei se alguém precisa de um filtro 1D-mediano rápido com janelas grandes).